Towards Understanding Best Practices for Quantization of Vision-Language Models
VLM Quantization에 대한 내용.
Abstract
ViT 와 LLM 은 parameter size의 상당한 차이에도 불구하고 모델 성능에서 유사한 중요성을 보임.
LLM 의 lower-bit quantization은 줄어든 bits per weight(bpw) 에서도 높은 accuracy 를 달성함.
1. Introduction
MLLMs(Multimodal Large Language Models)는 multimodal retrieval, captioning, 그리고 question-answering tasks 에서 인상적인 성능을 제공하지만, 모델 크기 및 latency가 너무 큼.
- Multimodal retrieval:
이미지와 텍스트 간 유사도를 측정하여 주어진 텍스트 쿼리에 가장 관련된 이미지를 찾거나, 반대로 이미지에 맞는 텍스트를 찾는 태스크.- Captioning:
입력 이미지를 설명하는 자연어 문장을 생성하는 태스크.- Question-answering:
이미지와 관련된 질문을 텍스트로 받아 정답을 텍스트로 출력하는 태스크.
Weights를 균일하게 quantize하면, model 성능이 bit-width 감소에 따라 어느 정도 linear한 correlation을 갖고 감소할 것으로 예상함.
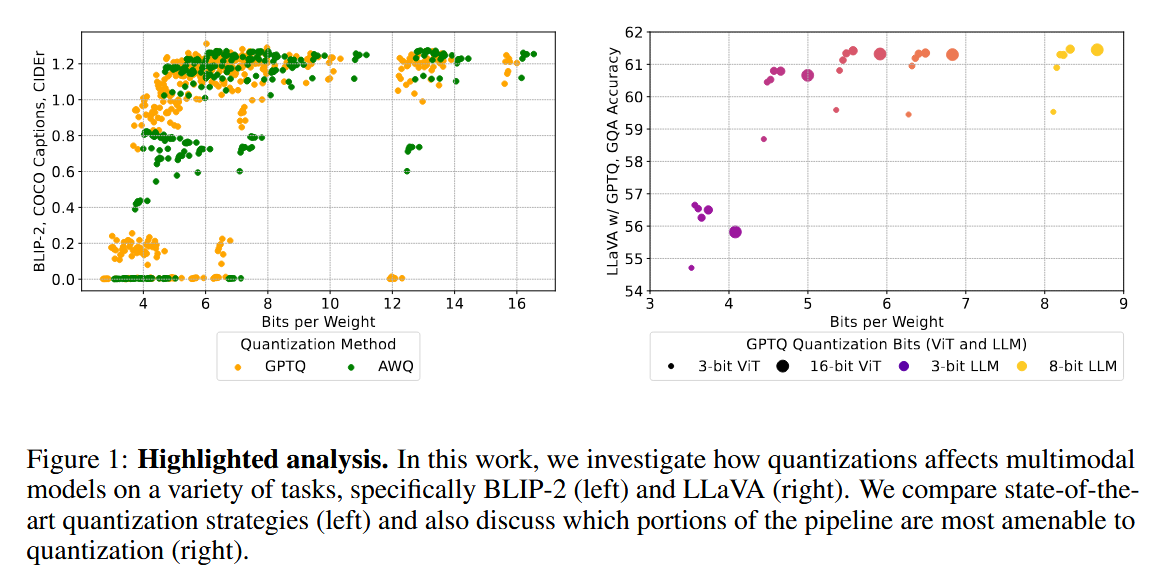
그러나 Figure 1에서 볼 수 있듯이, 실제로는 어느 컴포넌트를 양자화하느냐, 그리고 어떤 방법을 선택하느냐에 따라 성능이 크게 달라진다.
좌측 그래프에서 동일한 저비트 구간(4–6 bpw)에서도 GPTQ와 AWQ의 CIDEr 값이 뚜렷하게 갈리며, 우측 그래프에서는 16-bit ViT와 3-bit ViT 간 accuracy 차이는 작은 반면 3-bit LLM은 급격한 성능 저하를 보인다.
또한 LLM 양자화는 ViT 양자화보다 전체 모델 크기(bpw)에 훨씬 큰 영향을 미친다.
결국 모든 컴포넌트가 정밀도 감소에 동일하게 민감하지 않으며, 핵심 컴포넌트의 정보 손실을 최소화하는 방향으로 양자화 전략을 설계해야 모델 크기와 태스크 성능 간의 최적 트레이드오프를 달성할 수 있다.
핵심 원칙
-
VLM의 구성 요소의 quantization 민감도는 architecture 전반에 걸쳐 상당히 다름.
LLM은 일반적으로 parameter 수에 관계없이, ViT보다 더 높은 precision을 요구함. -
GPTQ, AWQ와 같은 SOTA 방법들은 uniform quantization에 비해, 상당히 낮은 bit-width (3.5 - 4.5 bpw)에서도 model 성능을 효과적으로 보존.
-
Task에 따라 최적의 bit allocation이 다름.
Reasoning task에서는 LLM precision을 크게 하는 것이 좋음. Visual-textual alignment tasks는 더 균형 잡힌 allocation이 좋음. -
Quantizaiton 방법의 선택은 VLM 구성 요소의 중요성을 재구성하게 함.
AWQ는 LLM 보존에 집중함. GPTQ는 중요성을 더 고르게 분산시킴.
AWQ의 "LLM 보존 집중"과 GPTQ의 "중요성 균등 분산"
"AWQ가 LLM 보존에 집중한다"는 말은 비트폭 할당의 문제가 아닙니다. AWQ와 GPTQ 모두 동일한 비트폭으로 양자화하되, 양자화 오류를 보정하는 방식이 다릅니다.
AWQ는 activation 크기가 큰 채널을 salient하다고 판단하는데, LLM의 대형 가중치 행렬에서 이런 채널이 압도적으로 많이 발견됩니다. 따라서 AWQ의 오류 보정 자원이 자연스럽게 LLM 쪽에 집중되고, 결과적으로 LLM의 정밀도 손실이 최소화되는 반면 ViT는 상대적으로 덜 보호됩니다.
"GPTQ의 중요성 균등 분산"에서 중요성이란 각 컴포넌트가 최종 성능에 기여하는 정도입니다. GPTQ는 Hessian 기반으로 모든 가중치의 오류를 순차적으로 보정하기 때문에 ViT와 LLM 양쪽의 정밀도가 비교적 고르게 유지되고, 따라서 두 컴포넌트의 성능 기여도가 Table 1의 COCO 결과처럼 50:50에 가깝게 나타납니다.
- Architectural dependency는 독립적인 구성 요소 평가보다는 전체적인 pipeline analysis를 피요로하는 상호작용 효과를 생성함.
"Holistic pipeline analysis" 이해
구체적으로는, 컴포넌트를 독립적으로 평가할 때 최적으로 보이는 양자화 설정이, 전체 파이프라인에서는 최적이 아닐 수 있다는 뜻입니다. Figure 6에서 ViT와 LLM을 각각 단독으로 저비트 양자화했을 때보다, 둘을 동시에 양자화했을 때 성능 저하가 훨씬 크게 나타나는 것이 그 근거입니다. ViT의 오류가 Q-Former를 거쳐 LLM으로 전파되는 순차적 구조 때문에, 각 컴포넌트의 오류가 단순히 더해지는 것이 아니라 증폭됩니다.
2. Related Work
2.1. VLM
일반적으로 retrieval과 같은 tasks를 위해 이미지와 텍스트의 embeddings를 생성하는 데 집중하는 이러한 VLMs와,
특정 이미지에 대한 복잡한 질문에 대한 답변과 같은 언어 출력을 생성하기 위해 일반적으로 이미지 및 텍스트 입력을 소비하는 vision large language models (VLLMs)를 구분함.
VLMs와 VLLMs의 차이
VLLMs도 내부적으로는 이미지와 텍스트를 embedding으로 변환합니다. 그러나 핵심 차이는 최종 출력의 형태와 목적에 있습니다.
VLMs는 이미지와 텍스트를 공유 임베딩 공간(shared embedding space) 에 정렬시키는 것이 목표입니다. 즉 출력이 embedding 벡터이며, 이를 이용해 이미지-텍스트 간 유사도를 측정하는 retrieval이 주된 태스크입니다.
VLLMs는 embedding 생성이 중간 과정일 뿐이고, 최종 출력은 자연어 텍스트입니다. 즉 이미지를 이해한 뒤 그것을 바탕으로 문장을 생성하거나 질문에 답하는 것이 목표입니다.
한 줄로 요약하면, VLMs는 "얼마나 비슷한가"를 숫자로 출력하고, VLLMs는 "무엇인가"를 언어로 출력합니다.
2.2. Model Compression
생략
3. Optimizing Performance
3.1. Building Intuitions
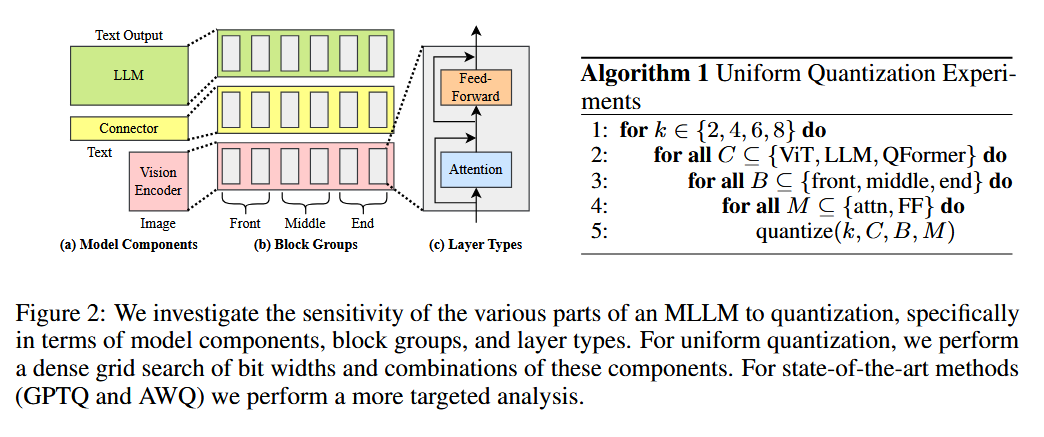
위 Algorithm 1을 적용한 결과
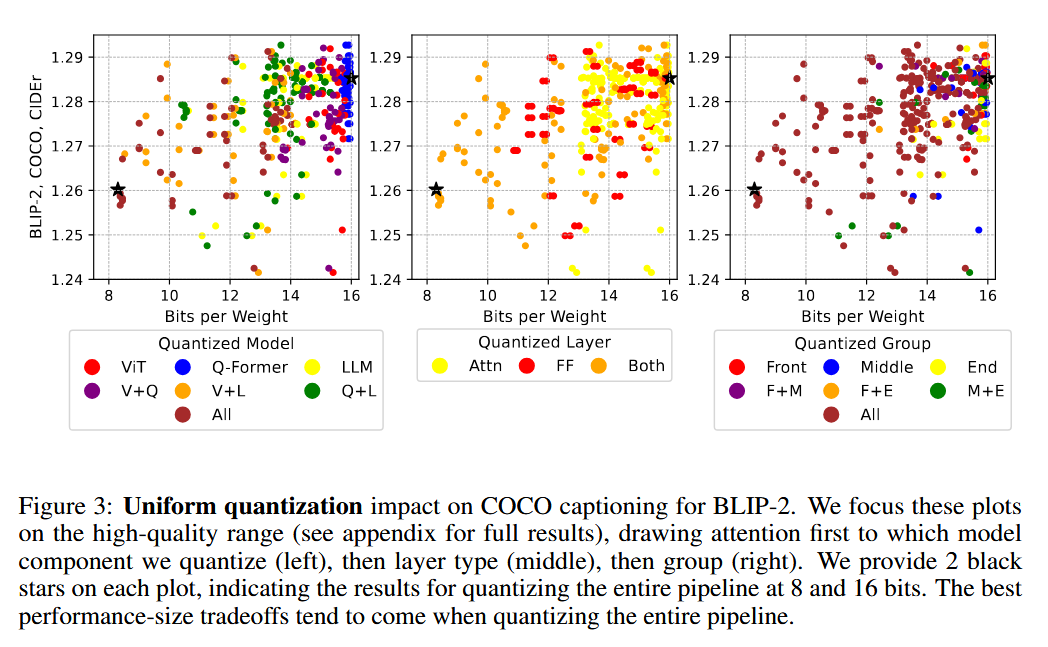
⇒ Layer types나 block groups에 대해 크기-성능 사이에 유의미한 상관관계를 관찰하지 못함.
3.2. SOTA Quantization Preliminaries
- AWQ: 작고 대표적인 calibration set 의 activation distribution을 참조하여 중요한 weight channels 를 식별하는 LLMs 용 weight-only PTQ technique 입니다. 더 큰 activation magnitudes를 생성하는 weights는 더 중요한 features에 해당하며 더 중요한 것으로 간주됩니다. AWQ 는 per-channel scaling factor 를 통해 단 1% 의 중요한 weights 만 보존함으로써 quantization error 를 줄입니다.
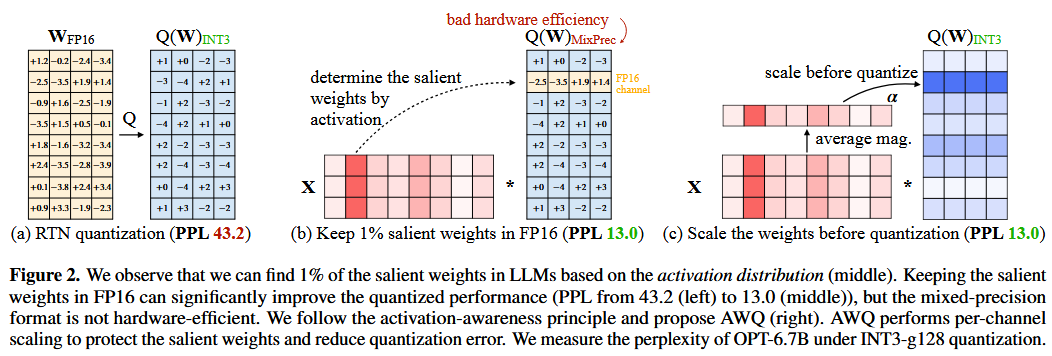
- GPTQ: LLMs 를 위한 또 다른 weight-only PTQ technique 이지만, activation 정보 대신 inverse Hessian에서 유도된 근사적인 second-order information 을 활용합니다. weights 가 순차적으로 처리되고 양자화됨에 따라, 남은 양자화되지 않은 weights는 작은 calibration set 으로 계산된 quantization error 를 보상하도록 조정됩니다.
3.3. SOTA Quantization Benchmark
Retrieval 평가: BLIP-2 ViT-g
Captioning, VQA 평가: BLIP-2 ViT-g OPT 2.7B
VQA 평가: LLaVA 1.5 7B
Calibration set: 각 데이터셋에서 128개 이미지-텍스트 쌍 무작위 샘플링
평가 데이터셋: VQAv2 val2014 split 10% (21,435개) / GQA 전체 Test-Dev split
탐색 공간: bit widths ∈ {2, 3, 4, 5, 6, 8}
BLIP-2: C ⊆ {ViT, LLM, Q-Former}
LLaVA: C ⊆ {ViT, LLM}
기존과의 차별점: 일반적으로는 LLM만 양자화하지만, 본 연구는 ViT와 Connector까지 양자화 탐색 공간에 포함
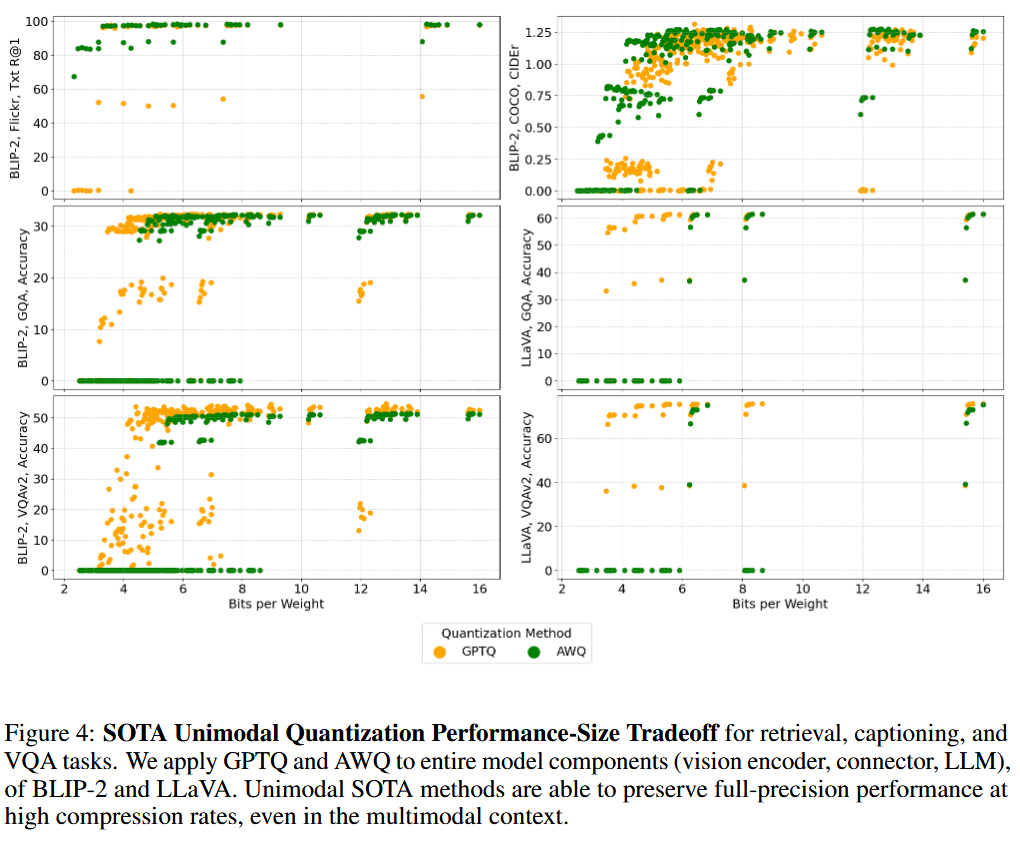
⇒
-
앞선 3.1.의 uniform quantization 보다 더 낮은 bit-width에서 성능이 좋음.
-
Captioning 및 VQA: AWQ가 GPTQ보다 더 낮은 bit-width에서 성능이 더 가파르게 저하
-
Retrieval: GPTQ가 AWQ보다 더 낮은 bit-width에서 성능이 더 가파르게 저하
3.4. Component Impact Ablations
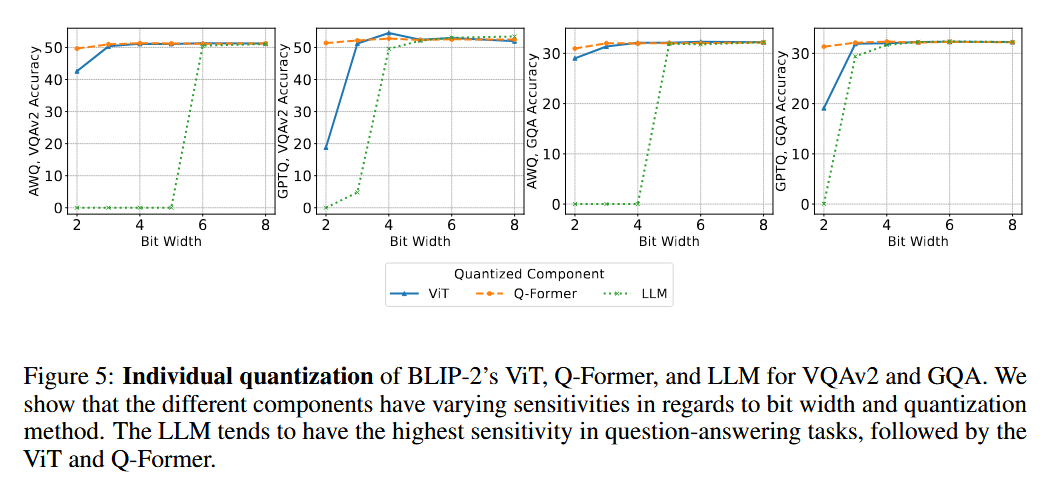
⇒
-
LLM이 가장 민감하며, ViT나 Q-Former에 비해 더 일찍 성능이 떨어짐.
-
Q-Former는 민감도가 가장 낮지만, parameter 수도 가장 적음.
-
ViT는 GPTQ에서는 큰 성능 저하를 겪지만, AWQ에서는 상대적으로 적은 저하를 보임.
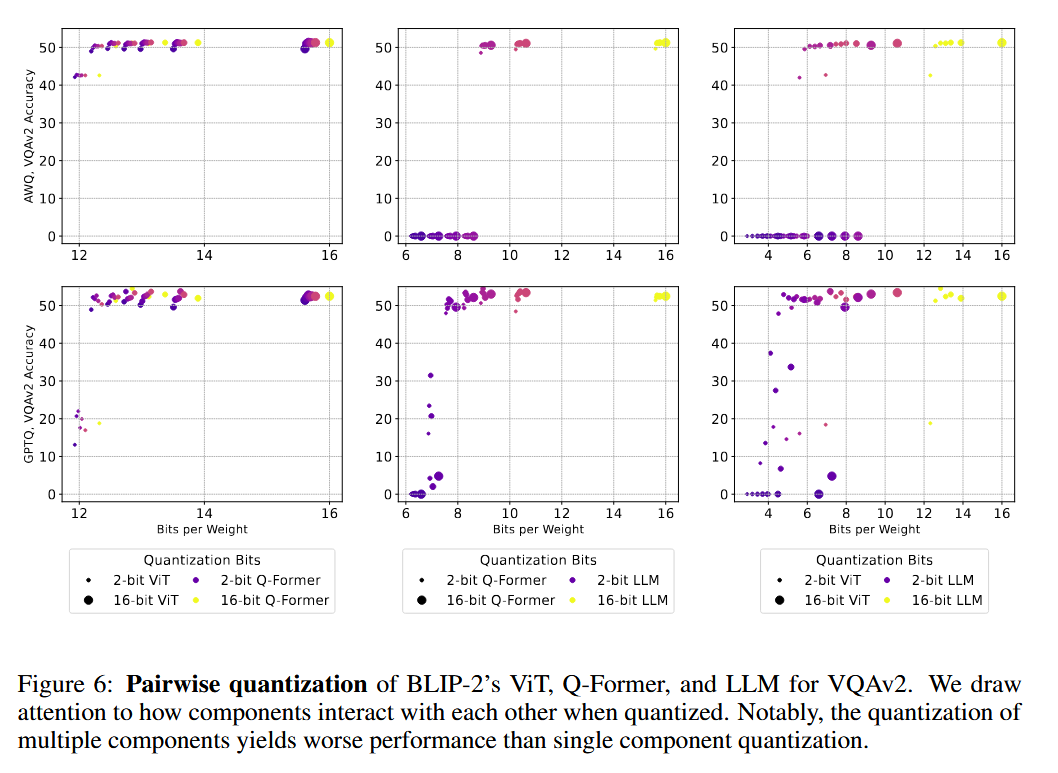
⇒
LLM을 ViT보다 낮은 bit-width로 할 때, 7 bpw 근처에서 성능이 완전히 소실 ⇒ LLM이 성능에 가장 critical 함.
4. Component Importance Analysis
Bit-precision과 성능의 관계가 비선형적이고 컴포넌트 간 상호작용이 복잡하여 선형 모델(R² < 0.20)로는 컴포넌트 중요도를 정량화할 수 없다.
4.1. Setup
비선형적 관계와 상호작용 효과를 효과적으로 포착할 수 있는 세 가지 보완적인 트리 기반 중요도 분석 기법들을 한 Consensus Ranking으로 묶음.
-
Random Forest Feature Importance:
-
Permutation Feature Importance:
-
SHapley Additive exPlanations (SHAP):
Consensus Ranking
위 세가지 기법의 결과를 정규화하고, 합산함.
⇒ 각 구성 요소에 대한 최종 중요도 백분율을 산출함.
4.2. Results
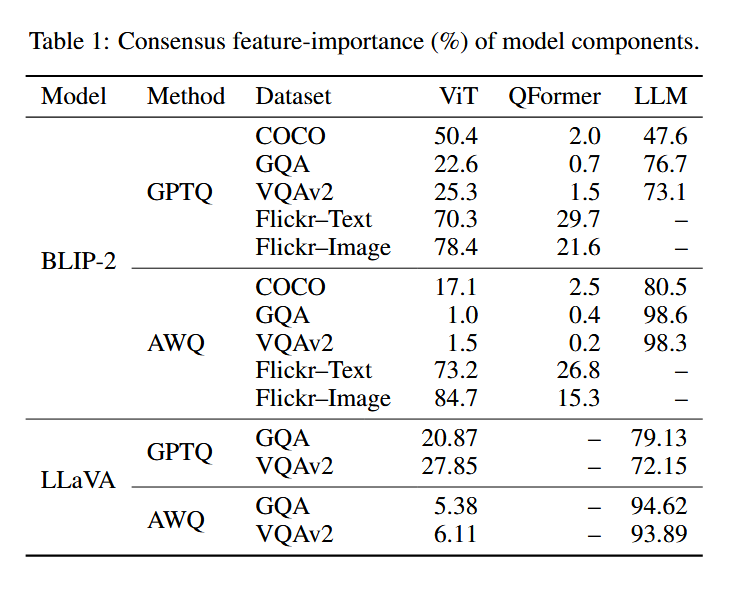
Quantization method dramatically shifts component importance.
AWQ는 LLM에 중요도가 집중되는 반면(≥73%), GPTQ는 ViT와 LLM 간 중요도를 균등하게 분산시킨다.
BLIP-2 COCO 기준
GPTQ: ViT 50.4% / LLM 47.6% (균등)
AWQ: ViT 17.1% / LLM 80.5% (LLM 편중)
LLaVA VQA 기준
GPTQ: ViT 20~28% / LLM 72~79% (상대적 균등)
AWQ: ViT 5~6% / LLM 94~95% (LLM 극단 편중)
핵심 인사이트
ViT는 전체 파라미터의 4.3%에 불과하지만 GPTQ에서 20~30% 중요도를 유지 → 중요도는 파라미터 크기에 비례하지 않음.
AWQ는 activation 기반 특성상 LLM의 대형 가중치 행렬에 보정이 집중되고, GPTQ는 Hessian 기반으로 컴포넌트 전반의 상호작용을 포착함.
따라서 비트 할당 전략은 사용하는 양자화 방법에 따라 달라져야 함.
⇒
GPTQ를 사용할 때는 ViT가 20~30%의 중요도를 유지하므로, ViT에도 상대적으로 높은 비트폭을 할당하는 전략이 합리적임.
반면 AWQ를 사용할 때는ViT의 중요도가 5~6%로 급감하므로, ViT는 과감하게 저비트로 압축하고 LLM에 높은 비트폭을 집중시키는 전략이 합리적임.
즉 동일한 모델이라도 어떤 양자화 방법을 선택하느냐에 따라 최적의 비트 할당 전략이 달라짐!
Task characteristics drive componet importance variations.
Retrieval (Flickr)
- LLM 미사용, ViT + Q-Former만으로 수행
- ViT 중요도 ≥ 70% (지배적)
- Q-Former 중요도 15~30%로 급상승 → LLM 부재 시 시각-언어 정렬을 Q-Former가 대신 담당하기 때문
VQA (VQAv2, GQA)
- 복잡한 언어적 추론이 요구되어 LLM 중요도가 압도적
- BLIP-2 GPTQ: LLM 73~77% / AWQ: LLM 98~99%
- LLaVA GPTQ: LLM 72~79% / AWQ: LLM 94~95%
핵심 인사이트
-
Q-Former는 LLM이 없을 때 시각-언어 정렬의 핵심 역할을 담당하지만, LLM이 있는 태스크에서는 중요도가 3% 미만으로 급감
-
태스크가 언어 추론을 많이 요구할수록 LLM 중요도가 높아지며, 그에 맞게 비트 할당 전략도 달라져야 함.
Architectural layout and component interplay shape quantization patterns.
생략.
요약
본 논문은 BLIP-2와 LLaVA를 대상으로 양자화 방법(GPTQ/AWQ), 태스크, 아키텍처 구조가 각 컴포넌트의 중요도에 미치는 영향을 분석하였다.
평가 데이터셋
- COCO: 이미지 캡션 생성 품질 평가 (CIDEr)
- Flickr: 이미지-텍스트 간 retrieval 성능 평가 (Recall@1)
- VQAv2: 이미지 기반 질의응답 정확도 평가 (Accuracy)
- GQA: 시각적 추론 및 구성적 질의응답 정확도 평가 (Accuracy)
양자화 방법에 따른 중요도 변화
AWQ는 LLM에 중요도를 집중시키고(≥73%), GPTQ는 ViT와 LLM 간 중요도를 균등하게 분산시킨다.
따라서 AWQ 사용 시에는 LLM에 높은 비트폭을 집중시키고, GPTQ 사용 시에는 ViT에도 상대적으로 높은 비트폭을 할당하는 전략이 합리적이다.
태스크에 따른 중요도 변화
Retrieval에서는 ViT가 지배적(≥70%)이며 Q-Former의 역할이 부각(15~30%)되고, VQA에서는 LLM이 압도적으로 중요하다(GPTQ 73~79%, AWQ 94~99%). 태스크가 언어 추론을 많이 요구할수록 LLM 중요도가 높아지며, 비트 할당 전략도 그에 맞게 달라져야 한다.
아키텍처 구조에 따른 중요도 변화
LLM 부재 시 Q-Former가 시각-언어 정렬을 대신 담당하며 중요도가 급상승한다. LLaVA에서는 connector의 용량이 제한적이어서 ViT의 역할이 파라미터 비중(4.3%) 대비 중요도(20~28%)가 높게 나타난다. 또한 ViT와 LLM을 동시에 양자화하면 순차적 오류 전파로 인해 비가산적 성능 저하가 발생한다.
느낌점
본 논문에서 비트 정밀도와 성능 간의 관계를 분석할 때, 선형 회귀로는 R² < 0.20으로 설명력이 부족하여 Random Forest, Permutation Importance, SHAP 등 비선형 기법을 추가로 활용한 점이 인상적이었다. 이는 단일 분석 방법에 의존할 경우 데이터의 복잡한 관계를 놓칠 수 있음을 보여준다. 특히 세 가지 방법을 Consensus Ranking으로 앙상블하여 방법별 편향을 상호 보완한 접근 방식은, 상관 관계 분석 시 항상 다양한 방법을 병행하여 결과의 신뢰성을 높여야 한다는 점을 시사한다.
