SparseVILA: Decoupling Visual Sparsity for Efficient VLM Inference
Abstract
1. 문제
VLM은 시각·텍스트 추론 통합으로 빠르게 발전했지만, 이들의 scalability는 inference latency를 지배하는 시각적 토큰 수의 증가로 인해 여전히 제한적이다.
2. 해법 — SparseVILA
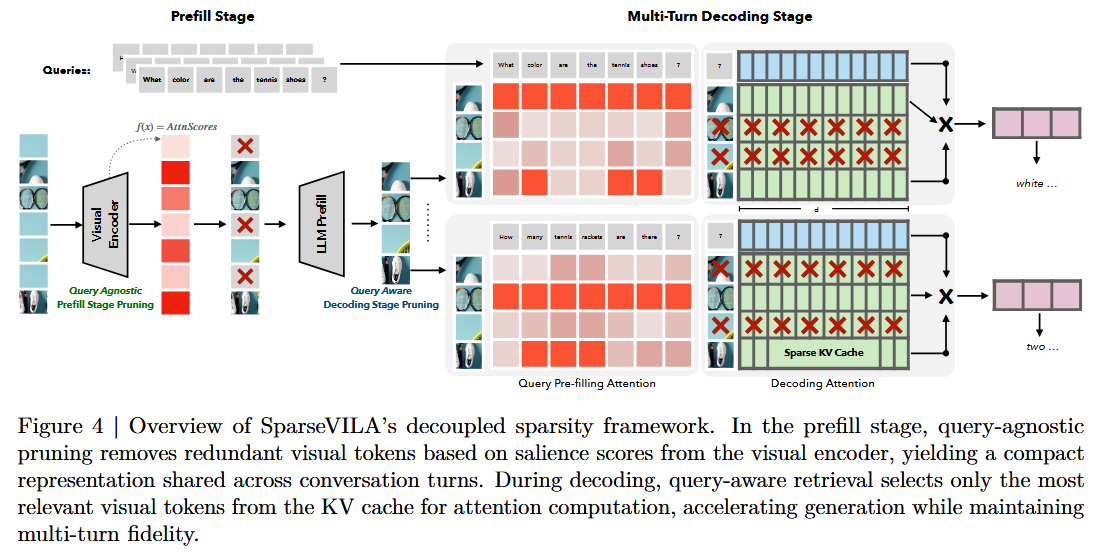
sparsity를 일괄 적용하지 않고 prefill / decode 단계별로 분산(decouple) 시킨다.
SparseVILA는 prefill 단계에서 redundant visual tokens를 pruning하고, decoding 단계에서는 query-relevant tokens만을 retrieval함으로써 sparsity를 단계별로 분산시킨다.
| 단계 | 방식 | 기준 | 토큰 처리 |
|---|---|---|---|
| Prefill | query-agnostic pruning | 시각적 중복성·salience | 실제 삭제 |
| Decoding | query-aware retrieval | 현재 query와의 관련성 | 삭제 X, 비활성화 (캐시 보존) |
3. 핵심 장점 — Decoupled Design
이러한 decoupled design은 주요 prefill pruning 방법들과 대등한 성능을 보이면서도, 시각적 캐시의 대부분을 유지하여 각 conversation round마다 query-aware tokens를 retrieval할 수 있도록 함으로써 multi-turn fidelity를 보존한다.
- 시각적 캐시를 거의 그대로 보존 → round마다 그 query에 맞는 token을 새로 retrieval 가능
- 기존 query-aware pruning은 한 번 token을 버리면 다음 turn에 복구 불가 → 누적 degradation 발생
- SparseVILA는 이 문제를 피하면서 multi-turn 정확도 유지
1. Introduction
1. 배경 — VLM의 latency 문제
VLM은 사진·문서·비디오 등 시각적 입력으로 LLM과 상호작용하는 SOTA 대화 도구로 부상했다. 그러나 추가된 visual modality는 LLM에서 visual token을 처리하는 데 드는 높은 latency·메모리 비용을 대가로 한다. 따라서 inference 시점의 효율적 배포가 여전히 난제다.
기존 비용 절감 연구들:
- model pruning (LLM / vision encoder)
- KV cache compression
- token sparsification
이들 다수는 context(prefill) 단계에서 큰 절감을 얻는다. 이 단계가 주로 compute-bound이기 때문이다.
2. context만으론 부족하다 — decoding도 봐야 함
현실 애플리케이션은 광범위한 generation을 요구한다.
- image captioning: 수백 토큰
- video captioning / 상세 기술: 수천 토큰 이상
따라서 context 단계 최적화만으로는 불충분하며, context와 decoding 단계 최적화를 모두 고려해야 한다. 그 대표적 use case가 multi-turn conversation이다.
3. 핵심 문제 — 반복적 pre-filling의 비효율
실제로 대부분의 benchmark는 본질적으로 multi-round conversation을 지원하며, 일례로 GQA dataset은 동일한 시각적 입력에 대해 90개가 넘는 질문을 포함하고 있다. 그럼에도 불구하고 대부분의 평가 benchmarks는 single-round evaluation(즉, 반복적인 pre-filling)을 실행하는데, 이는 비현실적일 뿐만 아니라 각 generation round마다 context 단계가 반복되어야 하므로 비효율적이다.
- 같은 이미지인데 round마다
이미지 + 질문을 처음부터 다시 prefill → 변하지 않는 visual token을 반복 처리하는 낭비 - 현실에서 visual 입력은 수만 개 context token에 달할 수 있음 → 반복 pre-filling은 사용자-VLM 상호작용 속도를 극적으로 저하
4. 제안 — SparseVILA
multi-turn 성능을 유지하면서 VLM inference를 가속화하는 새로운 접근.
- 핵심 insight: prefill 단계의 sparsity를 decoding 단계로 마이그레이션하는 decoupled sparsity framework
- decoding 단계에서 query-aware retrieval 활용 → 질문마다 서로 다른 context token subset을 retrieval하여 multi-turn 지원
- 결과: image-centric benchmark에서 큰 성능 향상, long-context / generation scaling에서 기존 방법 능가
보충 — "context 단계가 반복된다"의 의미
| single-round (기존 평가) | multi-turn (SparseVILA) | |
|---|---|---|
| Turn-1 | 이미지 + Q1 prefill | 이미지 1회 prefill + Q1 |
| Turn-2 | 이미지 + Q2 다시 prefill | 보존된 visual KV cache 재사용 + Q2 retrieval |
- 이미지 visual token(수천~수만 개)은 turn마다 변하지 않는데도 매 round 다시 prefill되는 게 핵심 낭비
- 질문 토큰은 수십 개 수준이라 부차적 → 반복되는 진짜 비용은 이미지 prefill
- (참고) 4.1절: 캐시 재사용 시 information leakage 방지를 위해 round 종료 후 이전 질문·답변 KV entry만 제거(partial eviction)하고 이미지 cache는 유지
2. Preliminaries
Query-Agnostic Sparsity
Query-agnostic 방법이란?
텍스트 입력(query)에 의존하지 않고, 오직 시각적 context(redundancy·salience)만으로 visual token을 pruning하는 방법.
대표 방법
- PruMerge: 최종 레이어 attention score로 정보량 적은 토큰을 클러스터링 후 폐기
- VisionZip: ToMe와 유사한 token merging module로 중복 시각 정보를 압축
단점
- 미세 정보 손실 — fine-grained 시각적 세부 사항을 희생, 특히 high sparsity에서 성능 저하
- query 적응 불가 — 입력 query에 맞춰 토큰 선택을 조정할 수 없어, task-relevant 정보가 드물게 분산된 경우 suboptimal
- 중요 정보 폐기 위험 — 모든 토큰을 일률 처리 → 정확한 추론에 필요한 핵심 정보까지 버릴 수 있음
Query-Aware Sparsity
Query-aware 방법이란?
텍스트 query와 시각적 representation 간의 관계를 명시적으로 모델링하여 visual token을 선택하는 방법. (= query를 보고 그 질문에 중요한 토큰을 고름)
대표 방법
- FastV: 초기 LLM 레이어의 attention map을 salience indicator로 활용 → prefill 단계에서 토큰 pruning
- SparseVLM: query-to-vision attention으로 덜 관련된 시각적 토큰을 폐기
단점
- 영구적 정보 손실 — 초기 query 기준 pruning 결정이 후속 질문에 중요한 시각 정보를 영구 제거
- multi-turn 성능 저하 — round가 거듭될수록 accuracy 급락, 종종 query-agnostic baseline보다도 낮음
- 복구 불가 — 일단 정보량 많은 토큰이 제거되면 이후 turn에서 되살릴 수 없음
Oracle 실험 (한계의 근본 원인 입증)
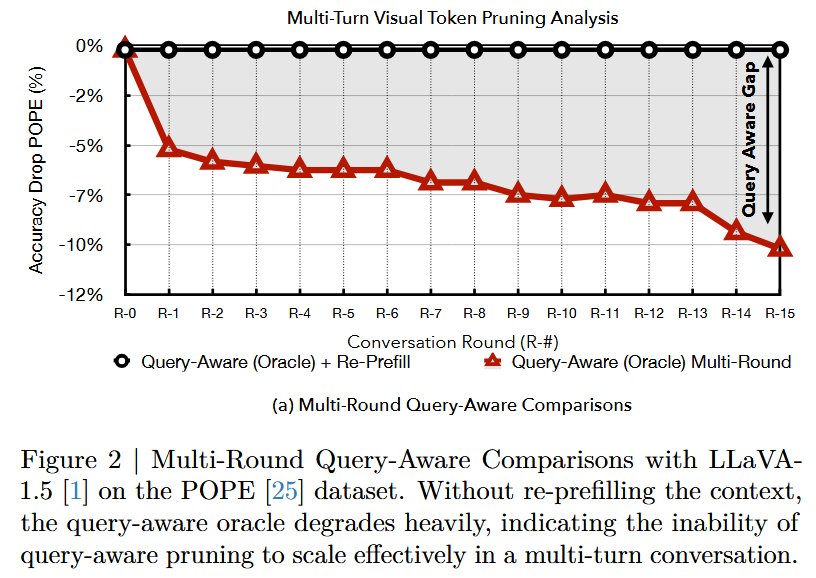
- query-aware oracle: 현재 query뿐 아니라 ground-truth 응답(정답)까지 보고, unpruned 모델의 답과 가장 잘 일치하는 token subset을 탐욕적으로 선택 → 현실 불가능한 치트, 모든 query-aware 방법의 이론적 upper bound
- 결과: 정답까지 본 oracle조차 연속 round에서 성능 저하 (Fig.2)
- 시사점: token 선택을 아무리 잘해도 안 됨 → prefill에서 토큰을 영구 삭제하는 구조 자체가 근본 한계
3. SparseVILA: Best of Both Worlds
- SparseVILA: prefill에선 가벼운 query-agnostic pruning으로 커버리지 손실 없이 redundancy를 줄이고, 질문을 아는 decode에선 공격적인 query-aware retrieval을 적용해 두 방식의 장점을 결합한다.
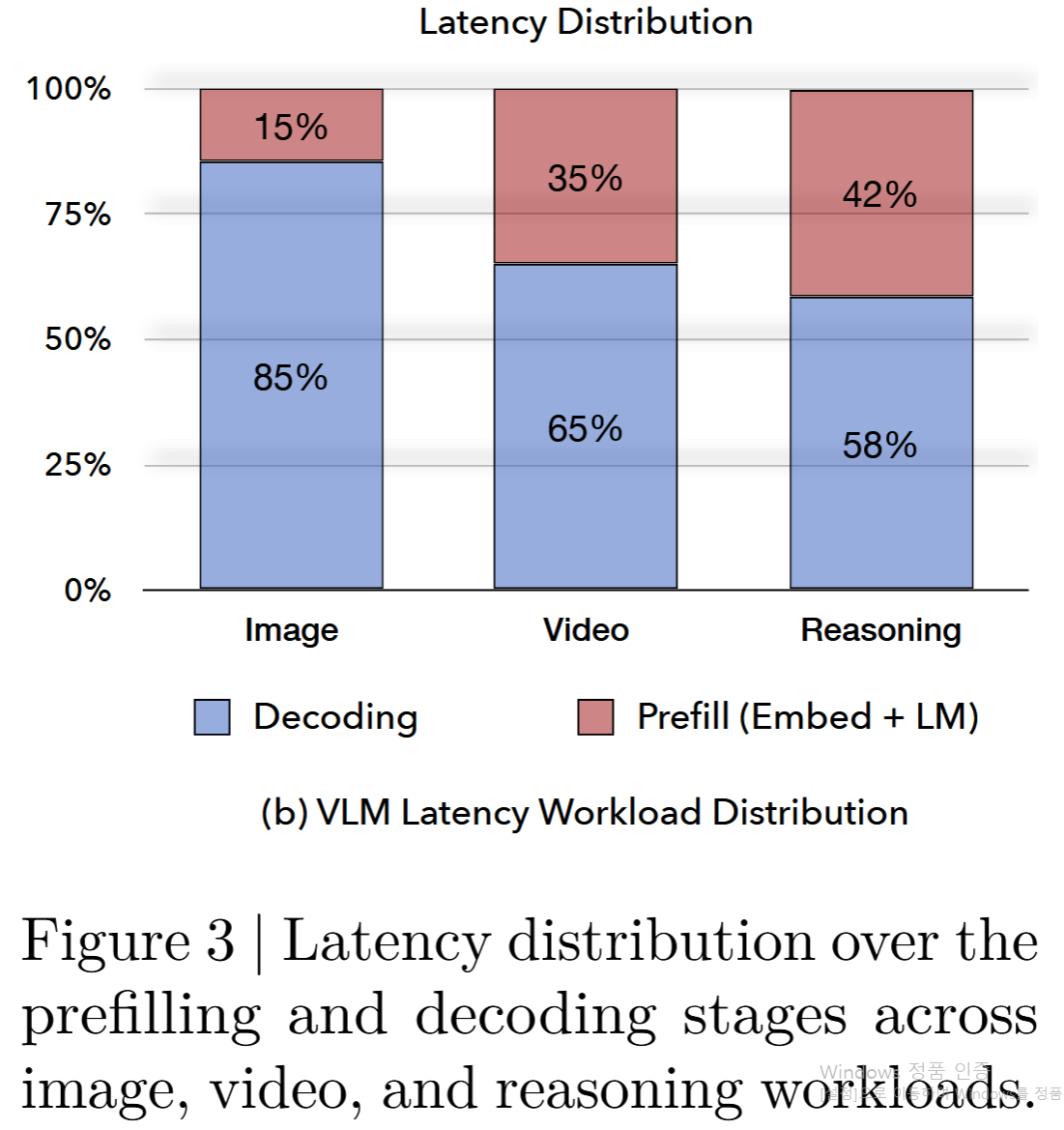
- Figure 3: 현대 VLM은 latency가 decoding에 집중되는 decoding-heavy 프로필이므로, 공격적 sparsity를 decode 단계에 배치하는 이 설계가 실제 latency 구조와 잘 맞는다.
3.1. Prefill Phase: Query-Agnostic Pruning
1. 기본 아이디어 (한 줄)
Prefill 단계에서 텍스트 query에 의존하지 않고 오직 시각적 redundancy/salience만으로 vision token을 pruning하여, 시각적 context를 한 번 계산해 여러 대화 turns 내내 안정적으로 재사용함.
핵심 제약: pruning은 엄격한 query-agnostic 상태를 유지해야 함 → 중복 정보는 최소화하되, 향후 queries를 위한 충분한 커버리지는 보존해야 함.
2. 토큰 중요도(Salience) 추정 방식 — 인코더 유형별
기본 원리: visual encoder의 self-attention map에서 토큰 중요도를 직접 추정 → query-independent salience 측정값 확보. attention 시그널을 집계해 각 토큰의 전체 representation 기여도를 정량화하고, 집계 salience가 가장 낮은 토큰을 pruning함.
| 인코더 유형 | 예시 모델 | Salience 정의 방식 |
|---|---|---|
| 단일 요약 토큰 | CLIP | 각 토큰이 global embedding(요약 토큰)에 기여하는 attention 값 |
| 다중 요약 토큰 | RADIO | 여러 요약 토큰들로 향하는 평균 attention (동일한 global aggregation 동작을 캡처) |
| 요약 토큰 없음 | SigLIP, QwenVL | 모든 토큰에 걸친 intra-visual attention을 평균화하여 중요도 추정 |
3. 커널 (Efficient Implementation)
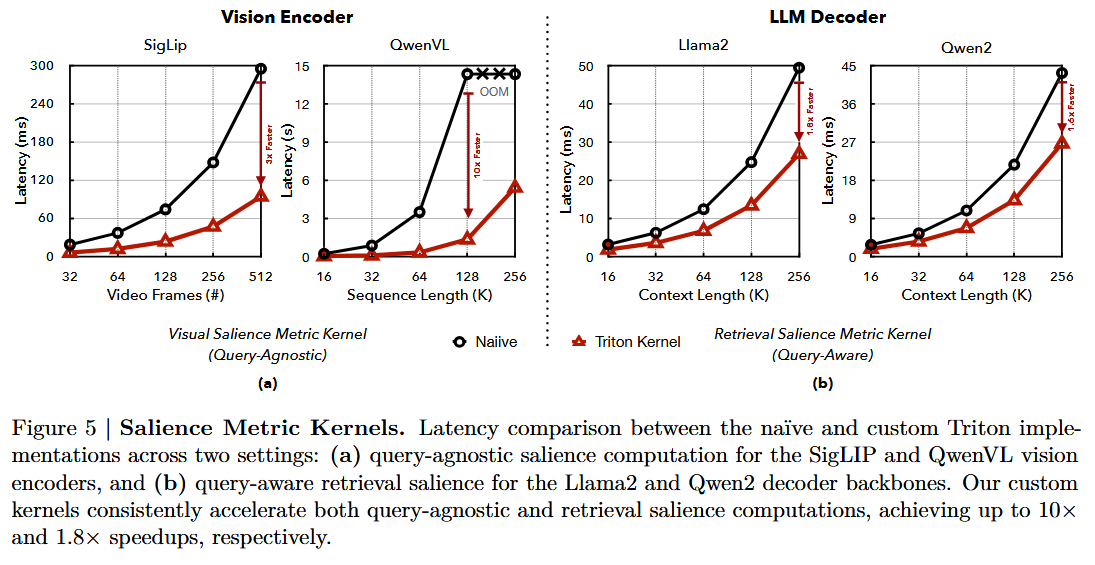
- 문제: 비디오 등 long-context 입력에서는 attention 기반 salience 추정이 메모리·latency 집약적임.
- 해결: 전체 attention 행렬을 명시적으로 만들지 않고 softmax 정규화 + salience 축적을 스트리밍하는 커스텀 Triton 커널 구현.
- 효과: 수십만 개 토큰 규모에서도 효율적인 salience 계산 가능.
- 성능 (Figure 5a):
- SigLIP 스타일 인코더: 최대 3배 가속
- QwenVL 스타일 인코더: 최대 10배 가속
- 의미: SparseVILA의 확장 가능한(scalable) prefill pruning을 위한 연산 기반(computational foundation)을 형성함.
3.2. Decode Phase: Query-Aware Retrieval
1. 기본 아이디어 (한 줄)
Decode 단계는 memory-bound 상황이므로, KV cache에 모든 vision token을 보존하되 현재 query에 관련성 높은 subset만 활성화하여 attention을 좁힘으로써, context를 영구 폐기하지 않고 효율을 높이고 multi-turn 유연성을 유지함.
2. 왜 효율적인가 — Memory-bound + Bandwidth
- Decode는 매 토큰 생성 시 FLOPs는 적고 KV cache 전체를 DRAM→연산기로 읽는 메모리 대역폭이 병목임.
- SparseVILA는 토큰을 삭제(eviction)하지 않고 비활성화(deactivation) → 미래 turn 대비.
- 현재 query에 필요한 subset만 로드 → 읽는 양 감소 → latency 개선.
- Densely packed (연속 메모리 패킹): 선택된 KV 항목을 contiguous memory로 모아 불규칙 sparse access를 방지 → coalesced access로 대역폭 효율까지 확보.
- 결과: "읽는 양 ↓ + 읽는 패턴 효율 ↑" 두 효과 동시 달성.
3. Query-Aware Token Selection
- Query embeddings = 현재 turn의 사용자 텍스트 query (text token).
- 동작: 텍스트 query를 Query, KV cache 내 vision token을 Key로 두고 둘 사이 집계된 attention 강도를 측정.
- 점수 높은 토큰 → 활성화(decode에 유지) / 점수 낮은 토큰 → cached but deactivated.
- 같은 이미지라도 query 내용에 따라 활성화되는 vision subset이 달라짐 = query-conditioned sparsity.
- 구현: prefill의 Triton 커널을 확장, query↔cached vision token 관련성 연산을 스트리밍.
- FlashAttention2 경로와 동시 실행 → naïve 대비 최대 1.5배 가속 (Figure 5b).
- 선택된 KV 항목은 연속 메모리로 dense packing.
3.3. Decoupled Prefill–Decode Visual Sparsity
실험 근거 (Table 1, RoboVQA)
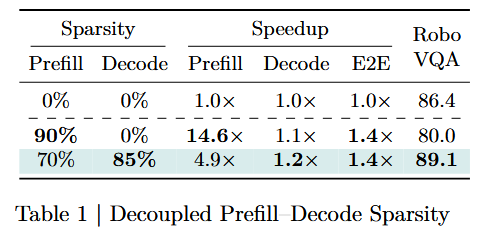
동일 E2E speedup 기준으로 비교 시, sparsity를 decode 쪽으로 재할당하면 task 성능이 일관되게 향상됨.
- Prefill은 context 무결성 유지에 충분한 토큰 보유.
- Decode sparsity가 지배적 latency 소스를 직접 타겟팅.
4. Analysis — Retrieval 토큰의 두 기능적 역할
decoding에서 retrieval되는 토큰은 query 축 기준으로 두 종류로 나뉨:
| 역할 | 동작 | 의미 |
|---|---|---|
| Visual Attention Sinks | queries 전반에 걸쳐 안정적 활성화 (쿼리 바뀌어도 계속 선택) | cross-modal attention을 안정화하는 지속적 attractor / scene 이해의 anchor |
| Visual Retrieval Tokens | query 콘텐츠에 따라 동적 변화 | task-specific 관련성 캡처 |
※ 분류 기준은 query 축(쿼리 바뀔 때 안정 vs 변동)임. "레이어별 차이"는 별개 관찰(4.6/Fig.8: sink는 shallow layer 우세, retrieval은 deep layer에서 emerge).
- 이 분리 덕분에 SparseVILA는 효율적·query-adaptive retrieval을 하면서도 contextual grounding을 유지함.
- VisionZip, VAR(Visual Attention Redistribution)의 관찰과 일치 (4.6 정성 분석이 뒷받침).
4. Experiments
4.1. Setup
1. Multi-Turn 평가에서의 정보 누출(information leakage) 처리
- 문제: 같은 이미지의 질문들을 multi-turn으로 묶으면, 이전 질문이 다음 질문의 답을 흘릴 수 있음.
- 예 (GQA): Q1 "하늘 앞 사람이 뭐 하나?" → Q2 "그 사람은 무엇 앞에 있나?" → Q1이 Q2 답을 이미 노출 → 모델이 이미지 없이도 정답 가능.
- 해결 — partial KV cache eviction: 각 라운드 종료 후 직전 질문·답변(Q&A)에 해당하는 KV 항목만 제거.
- 효과: 시각적 KV cache 재사용의 효율은 유지하면서, turn 간 의도치 않은 context 이월(carryover)은 차단.
한 줄: "이전 turn의 질문·답변 KV만 지워서 누출은 막고, 시각 KV 재사용 이득은 살린다."
2. Baseline 분류
| 범주 | 정의 | 포함 방법 |
|---|---|---|
| Query-agnostic | 텍스트 입력 참조 없이 중복 시각 토큰 pruning | VisionZip, PruMerge, HIRED |
| Query-aware | 언어 context 기반으로 토큰 선택 적응 | FastV, PDrop, SparseVLM |
3. Chunked 방식 ↔ attention map 실체화(materialize) 관계
- baseline 대부분은 attention weights로 salience 추정 → visual encoder에서 메모리·latency 집약적, 긴 context에서 GPU 한계 초과.
- Chunked 방식 = 전체 attention map을 한 번에 만들지 않고 조각(chunk)으로 나눠 계산하여 메모리 제약 내에 맞추는 것.
- 즉 질문대로, baseline은 (조각 단위로라도) attention map을 실체화(materialize)해야 함.
- 대조 — SparseVILA: fused Triton 커널로 전체 attention map 자체를 실체화하지 않고 salience 계산 (Fig.5) → 메모리·속도 우위.
4. Inference Setting
- 파이프라인: TinyChat 기반 최적화.
- 양자화:
- Visual encoder → W8A8 (SmoothQuant)
- LLM → W4A16 (AWQ)
- 양자화 버전이 vanilla 대비 E2E 2.4× 가속 (accuracy 저하 무시 가능); 이후 모든 결과는 이 양자화 버전 기준.
- 하드웨어/디코딩: 단일 NVIDIA A6000, batch size 1, greedy decoding (별도 명시 없으면).
- Latency 측정 (E2E): visual encoder(E) + LM prefill(P) + decoding(D). E2E = prefill 시간 + 토큰당 decoding 시간.
- multi-turn이므로 라운드별 query의 chunked prefill 비용을 초기 이미지 prefill로 amortize.
- 라운드 수 = 데이터셋 평균 turn 수.
- 디코딩 길이: 이미지 50 tokens/round, 비디오 250 tokens/round, reasoning(single-turn) 1,500 tokens (prefill+decode 합).
- Sparsity ratio 정책: LLM 이전 일정한 prefill sparsity + 모든 레이어 균일한 decoding sparsity.
- layer-wise / head-aware 같은 세부 전략은 추가 최적화 여지 있으나 복잡성·튜닝 overhead 때문에 미채택 → 단순성·일반화 우선, future work로 남김.
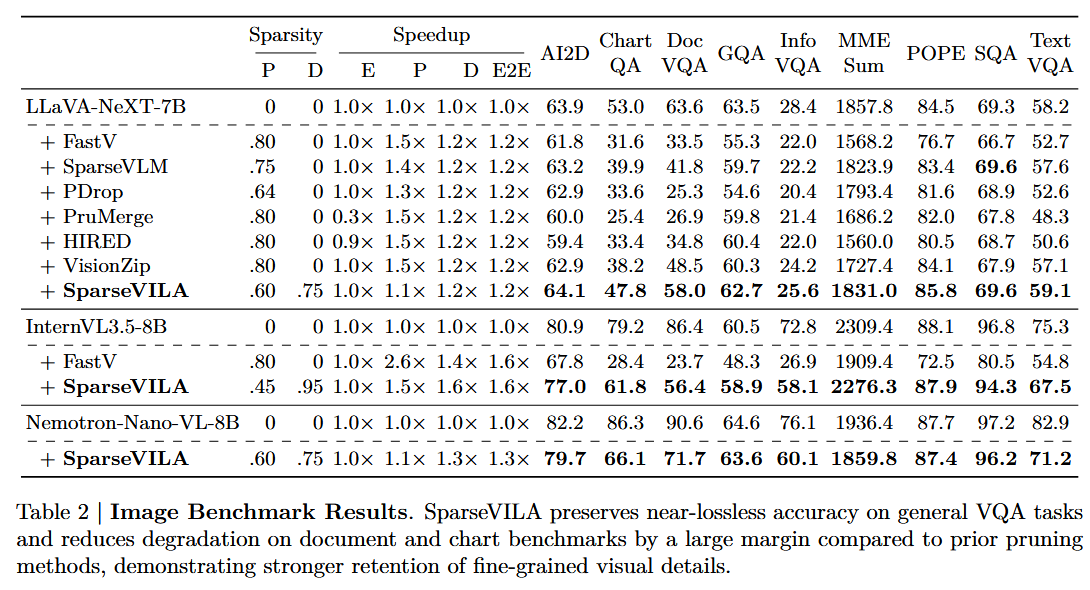
4.2. Image Benchmark Results
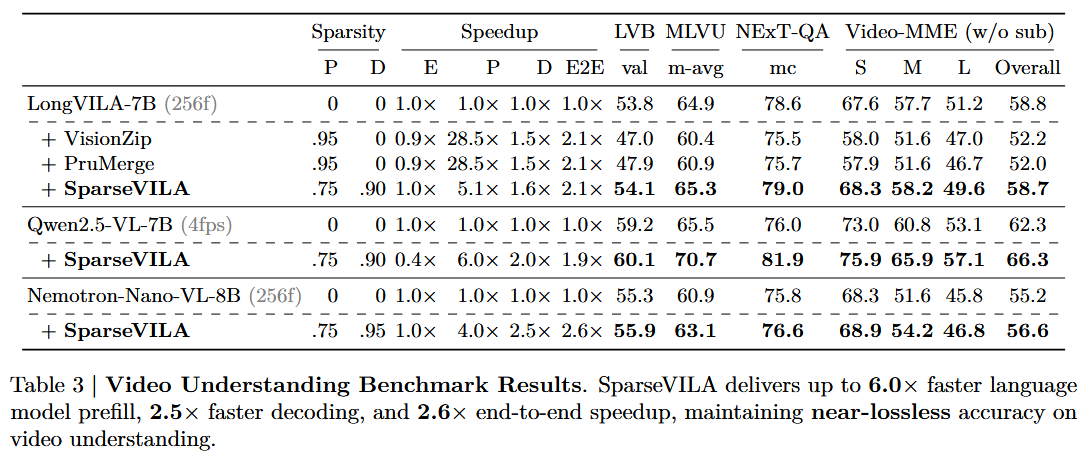
4.3. Video Benchmark Results
4.3.1. Video Understanding
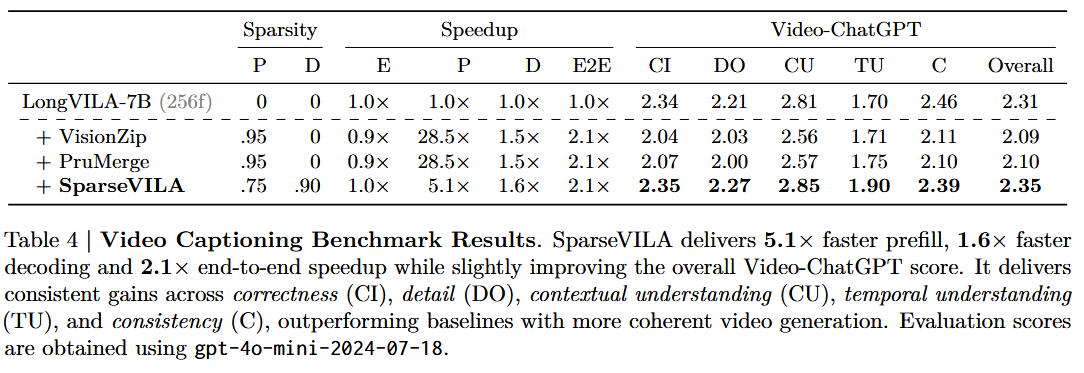
4.3.2. Video Captioning
4.3.3. Visual Retrieval
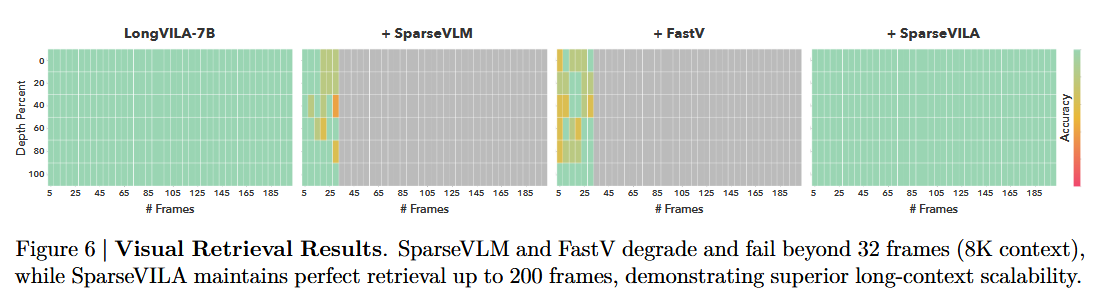
4.4. Reasoing Benchmark Results
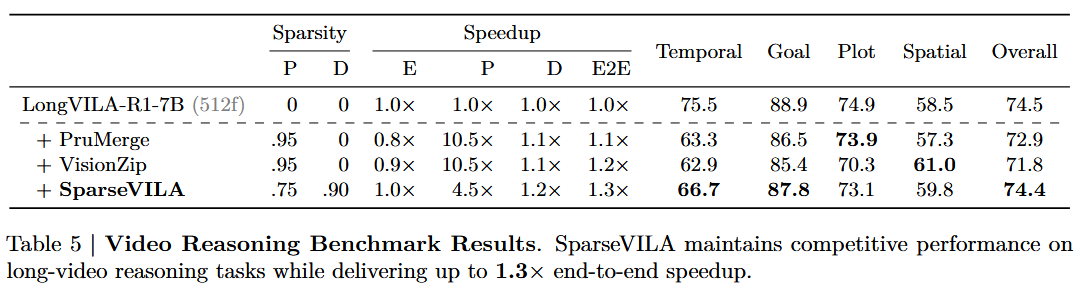
4.4.1. Video Reasoning
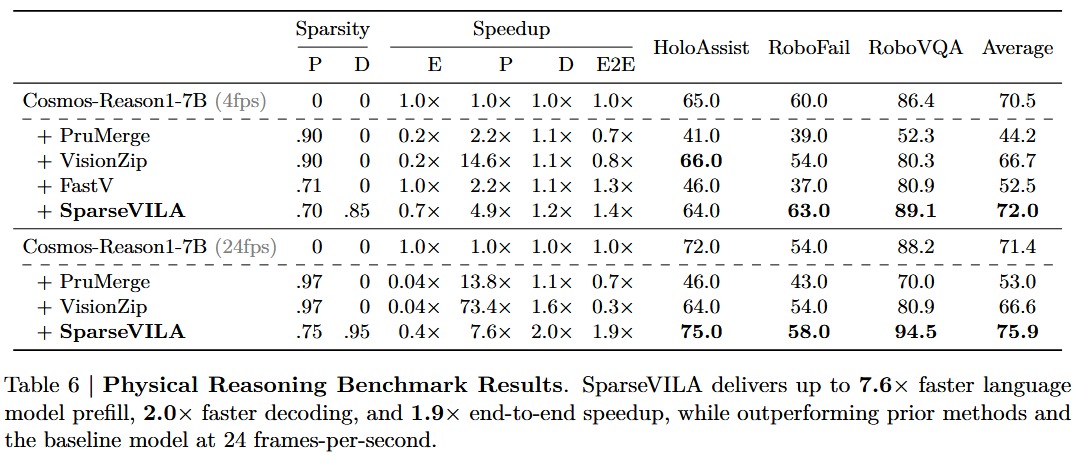
4.4.2. Physical Reasoning
4.5. Efficiency Analysis
SparseVILA — 커널(Kernel) 최적화 3종 정리
한 줄 요약
SparseVILA는 prefill·decode 두 단계에 걸쳐 세 종류의 custom 커널로 inference를 가속함. prefill 쪽 두 개는 salience(중요도) 계산을 빠르게 하는 게 목적이고, decode 쪽 하나는 유효 KV cache를 줄여 메모리 이동 자체를 줄이는 게 목적임.
3종 커널 비교
| 커널 | 단계 | 최적화 핵심 | 속도 향상 |
|---|---|---|---|
| Prefill salience (Fig.5a, query-agnostic) | prefill | 전체 attention 행렬을 미실체화(non-materialized) — softmax 정규화 + salience 축적을 streaming으로 처리 | SigLIP 3× / QwenVL 10× |
| Retrieval salience (Fig.5b, query-aware) | prefill 말미 / decode 직전 | query ↔ cached vision token 관련성 계산을 FlashAttention2 경로와 동시 실행 | 최대 1.5× (~1.8×) |
| Decoding attention (Fig.7) | decode | 유효 KV cache 축소 + 연속 메모리 dense packing → 메모리 트래픽·decoding FLOPs 동시 감소 | video 11.4× / reasoning 6.8× |
핵심 구분 포인트
- Prefill 커널의 본질 = "행렬 안 만들기": long-context에서 full attention matrix를 명시적으로 만들면 메모리·latency 폭증 → streaming으로 우회.
- Decode 커널의 본질 = "읽을 KV를 작게 + 연속으로": decode는 memory-bound라 병목이 HBM↔연산기 트래픽임. query-aware retrieval로 활성 토큰만 남기고 contiguous로 packing → 읽는 양↓ + 접근 패턴 효율↑ → 곧바로 속도로 직결.
- 즉 같은 "Triton 커널"이라도 prefill은 연산량(compute) 줄이기, decode는 메모리 이동(memory traffic) 줄이기로 목적이 다름.
Decoding Attention Kernel Efficiency
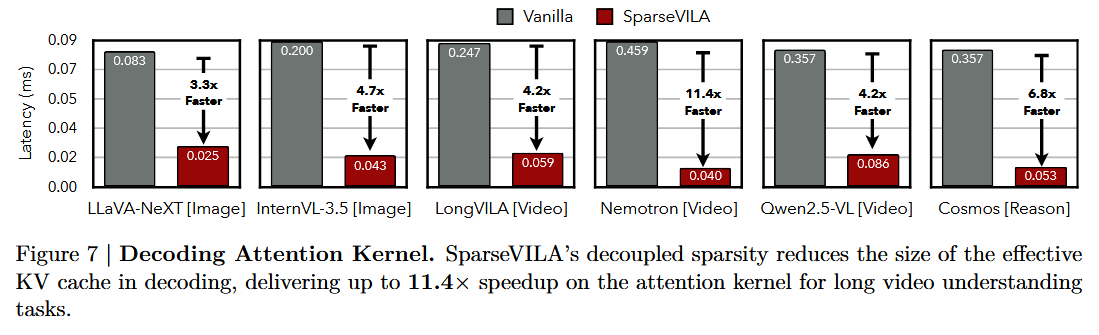
Decoding Attention Kernel Efficiency는 query-aware retrieval로 유효 KV cache가 줄어든 결과, decode attention 커널이 읽는 메모리 트래픽·FLOPs가 감소해서 빨라진 decoding attention 커널 자체의 속도를 측정한 것
Empirical vs. Theoretical Latency Analysis
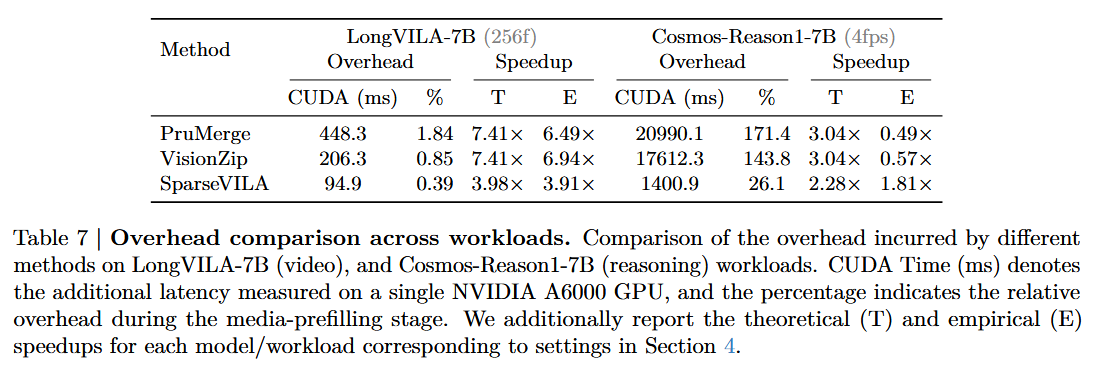
Empirical vs. Theoretical Latency Analysis는 pruning 메트릭 계산·토큰 재조직화·선택 로직에서 생기는 overhead 때문에 이론적 속도 향상(T)이 실제 실현 속도(E)만큼 나오지 못하는, 그 overhead로 인한 이론↔실제 격차를 측정한 것
4.6. Qualitative Analysis
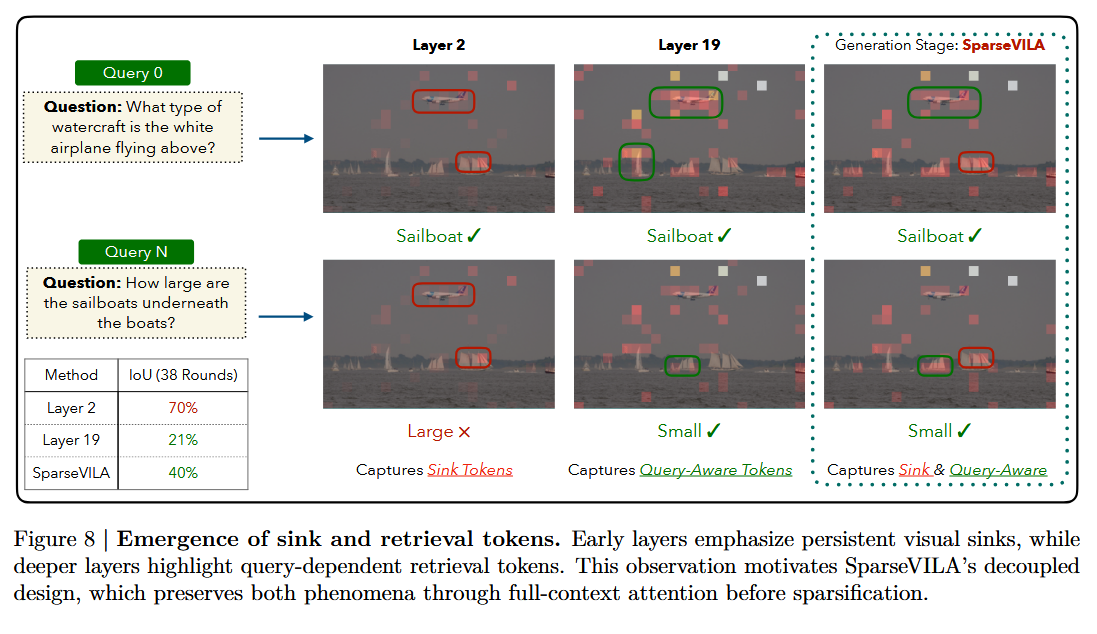
Sink vs Retrieval 토큰의 레이어별 출현 (Fig.8) — 2줄 핵심
- Sink token = 얕은 레이어(예: Layer 2): 쿼리가 바뀌어도 안정적으로 선택됨(IoU 높음, 70%) → 장면 이해의 지속적 앵커(anchor).
- Retrieval token = 깊은 레이어(예: Layer 19): 쿼리 내용에 따라 선택이 동적으로 바뀜(IoU 낮음, 21%) → query-specific 관련 영역에 집중.
깊이가 깊어질수록 query-specific 추론이 globally-salient 구조(sink)를 점진적으로 오버라이드함. sink는 계속 존재하되 강도가 약해짐.
