논문 리뷰
1.On-Device Training Under 256KB Memory
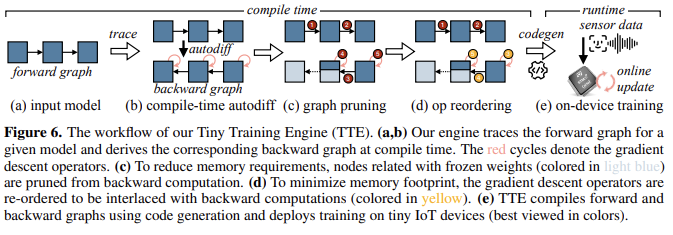
On-Device Training Under 256KB Memory 논문에 대하여 ...
2.Edge AI: On-Demand Accelerating Deep Neural Network Inference via Edge Computing
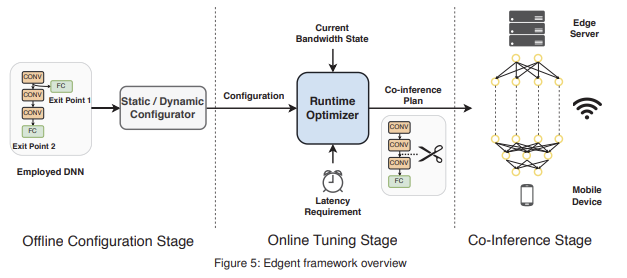
Edge AI: On-Demand Accelerating Deep Neural Network Inference via Edge Computing 논문에 대하여...
3.Group Normalization
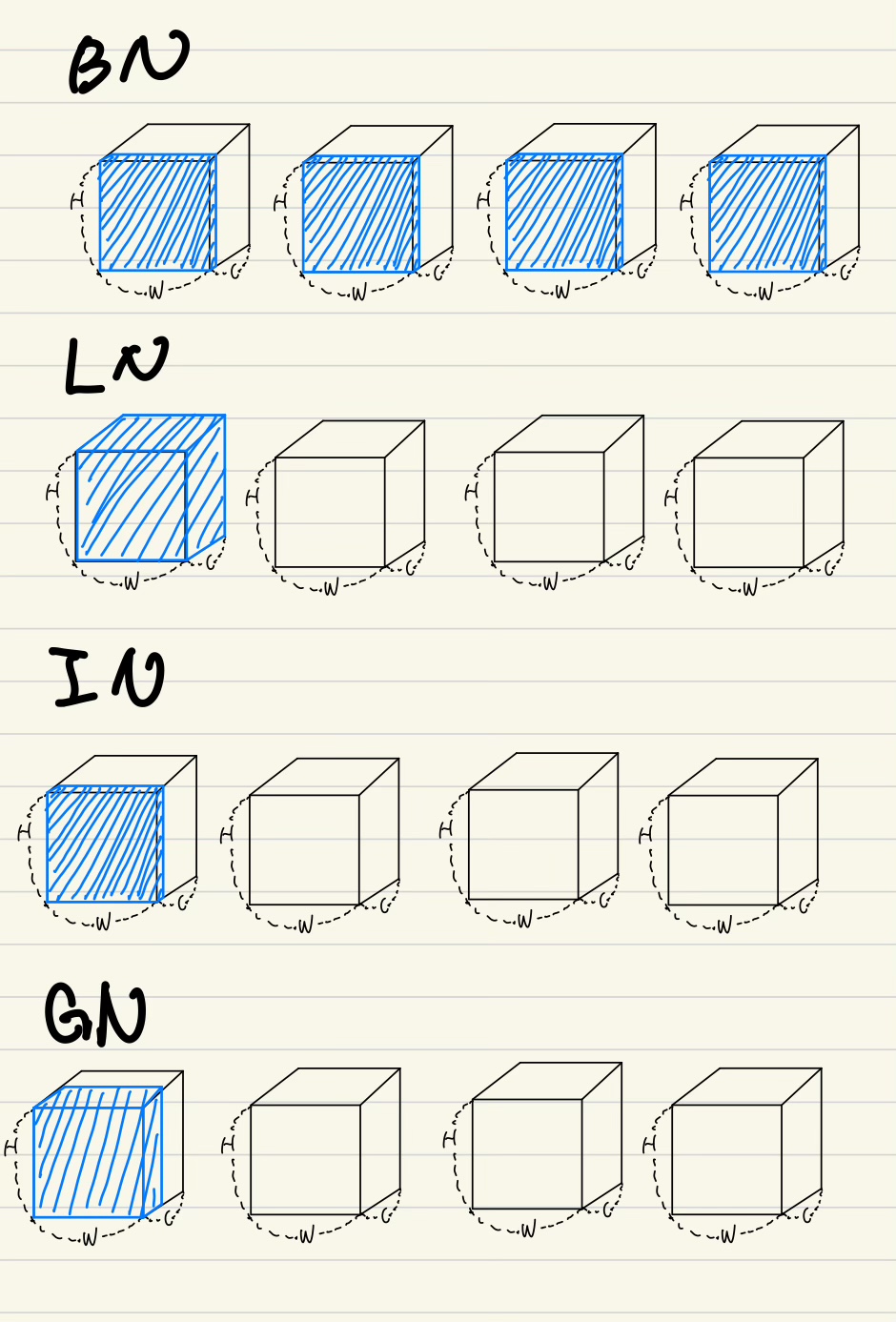
Group Normalization 논문에 대하여...
4.TinyTL

TinyTL 논문에 관하여...
5.LLM-QAT: Data-Free Quantization Aware Training for Large Language Models
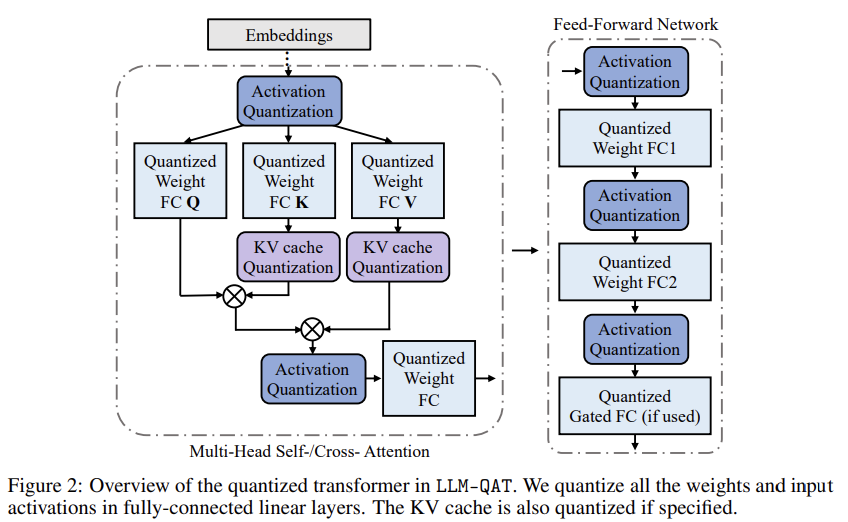
LLM-QAT: Data-Free Quantization Aware Training for Large Language Models 논문에 대하여...
6.SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
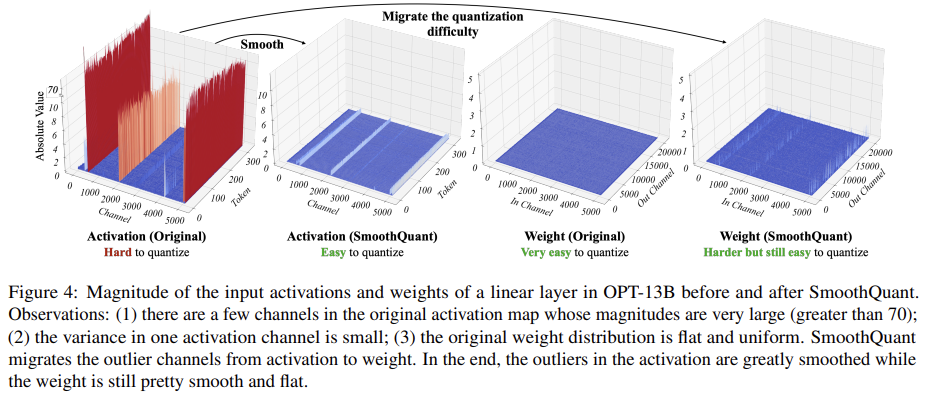
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models 논문에 대하여...
7.A Survey of Quantization Methods for Efficient Neural Network Inference

A Survey of Quantization Methods for Efficient Neural Network Inference 논문에 대하여...
8.BinaryViT: Pushing Binary Vision Transformers Towards Convolutional Models
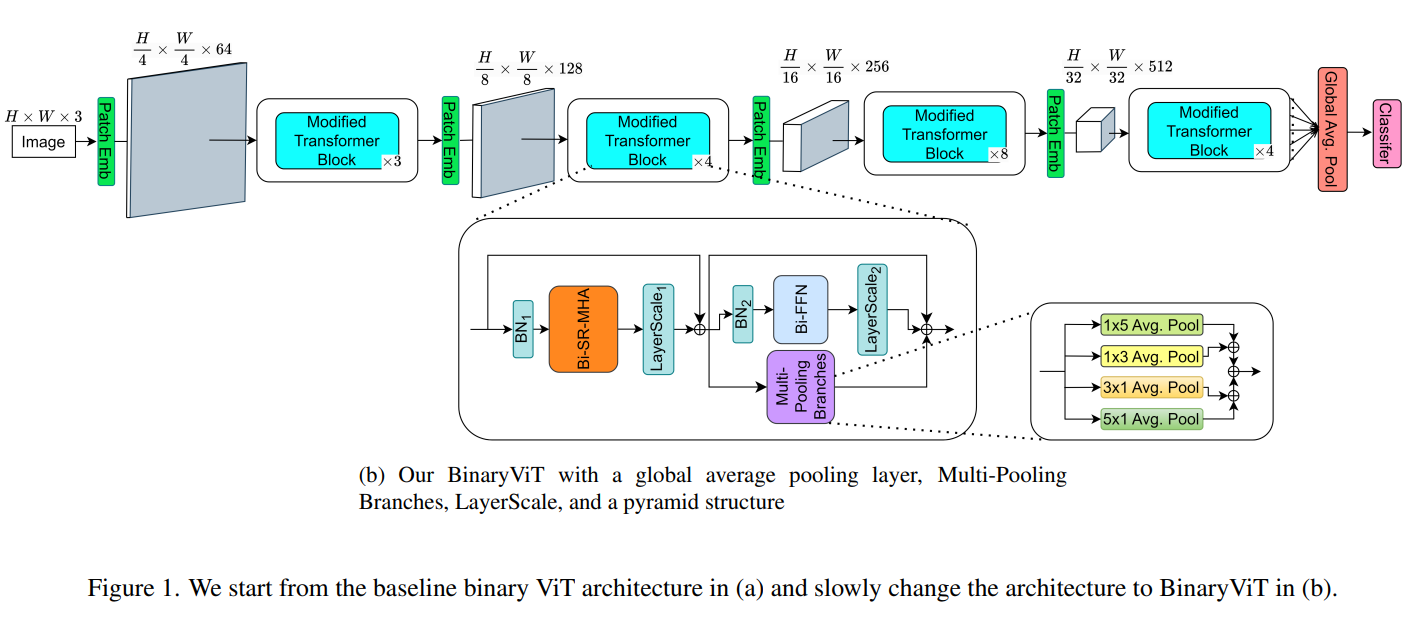
BinaryViT: Pushing Binary Vision Transformers Towards Convolutional Models 논문에 대하여...
9.SpecEE: Accelerating Large Language Model Inference with Speculative Early Exiting
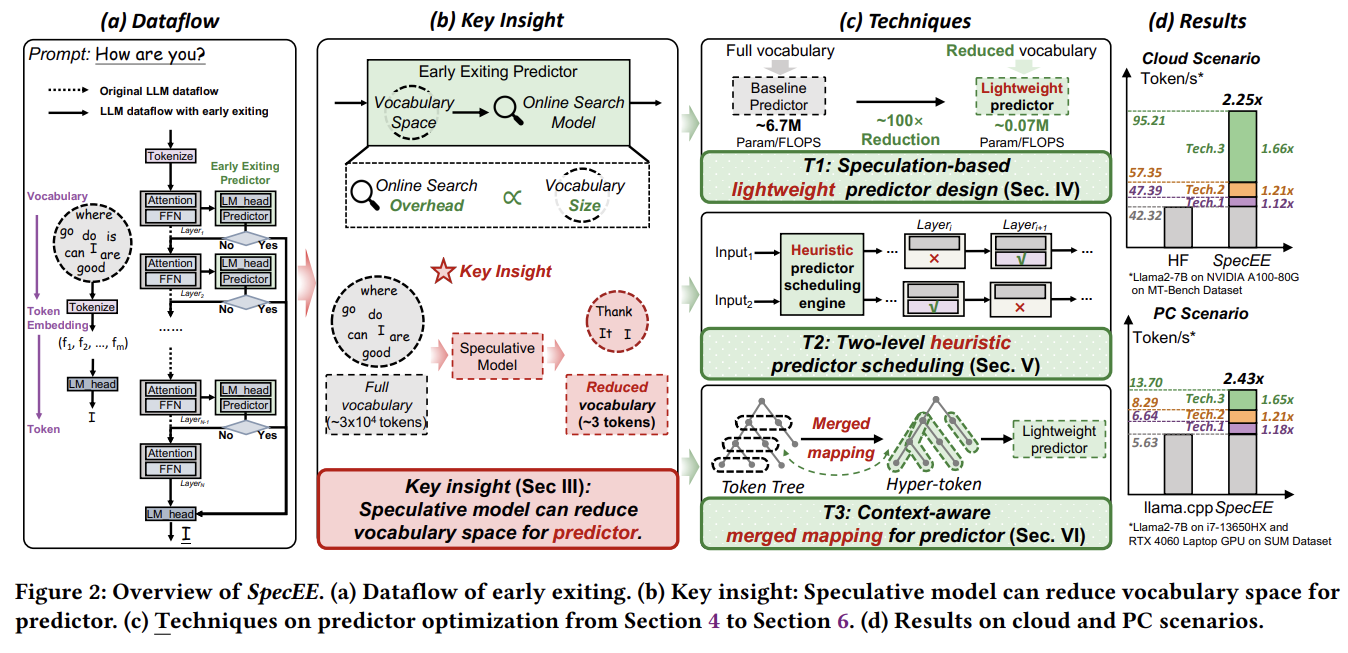
SpecEE: Accelerating Large Language Model Inference with Speculative Early Exiting 논문에 대하여...
10.Mix-QViT: Mixed-Precision Vision Transformer Quantization Driven by Layer Importance and Quantization Sensitivity
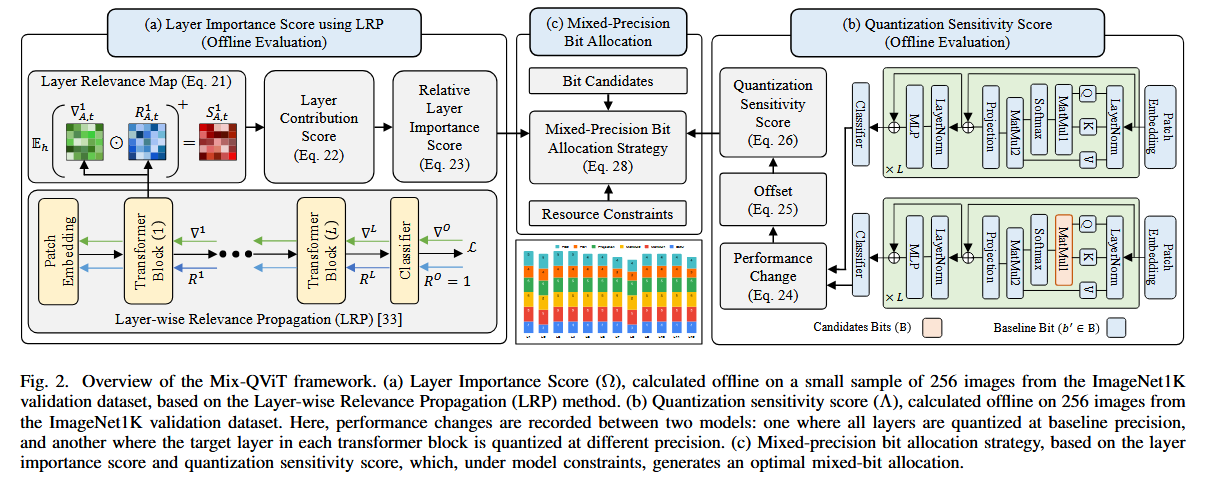
Mix-QViT: Mixed-Precision Vision Transformer Quantization Driven by Layer Importance and Quantization Sensitivity 논문에 대하여...
11.Explaining NonLinear Classification Decisions with Deep Taylor Decomposition
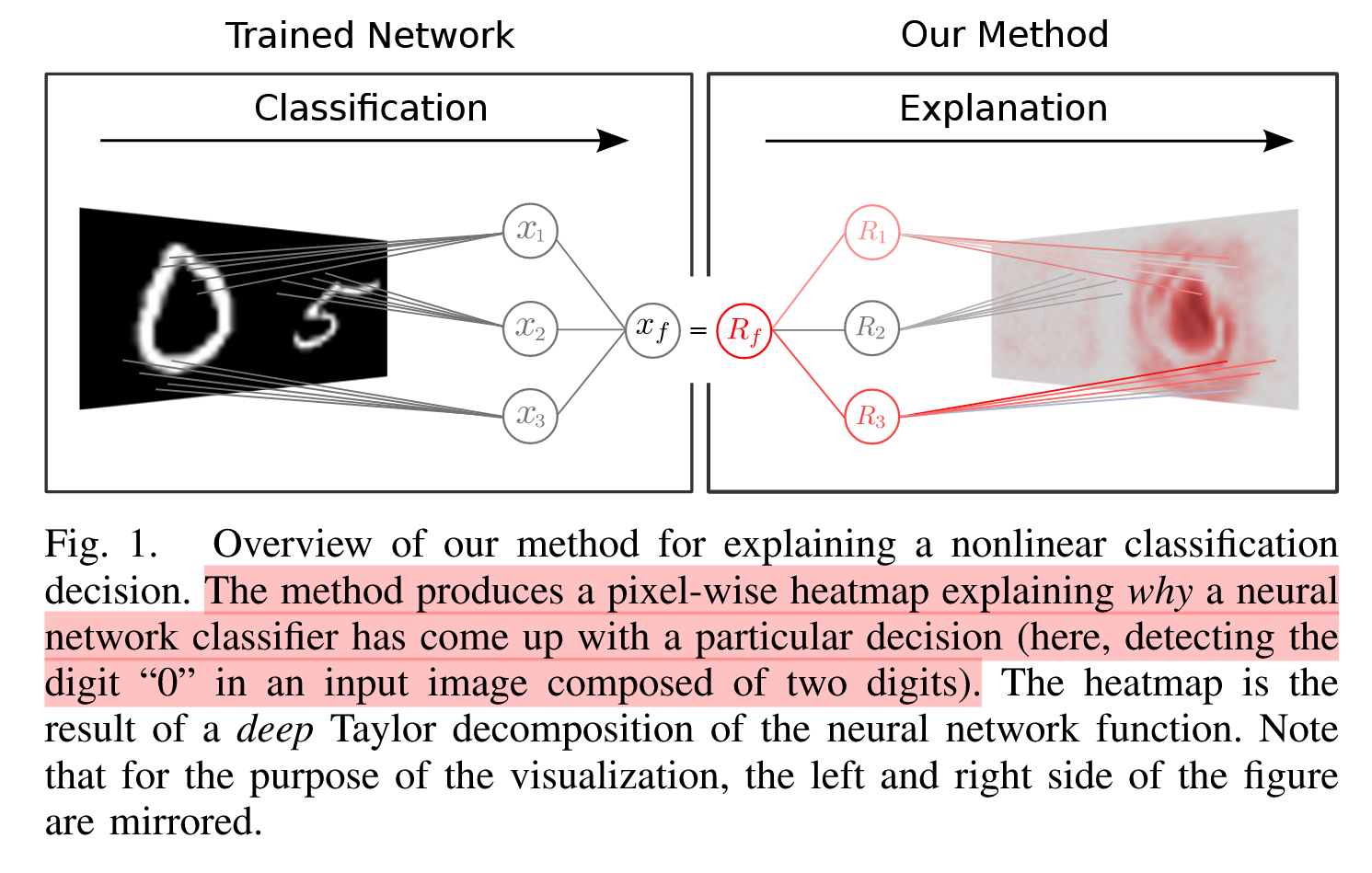
Explaining NonLinear Classification Decisions with Deep Taylor Decomposition 논문에 대하여...
12.MPQ via Learned Layer-wise Importance
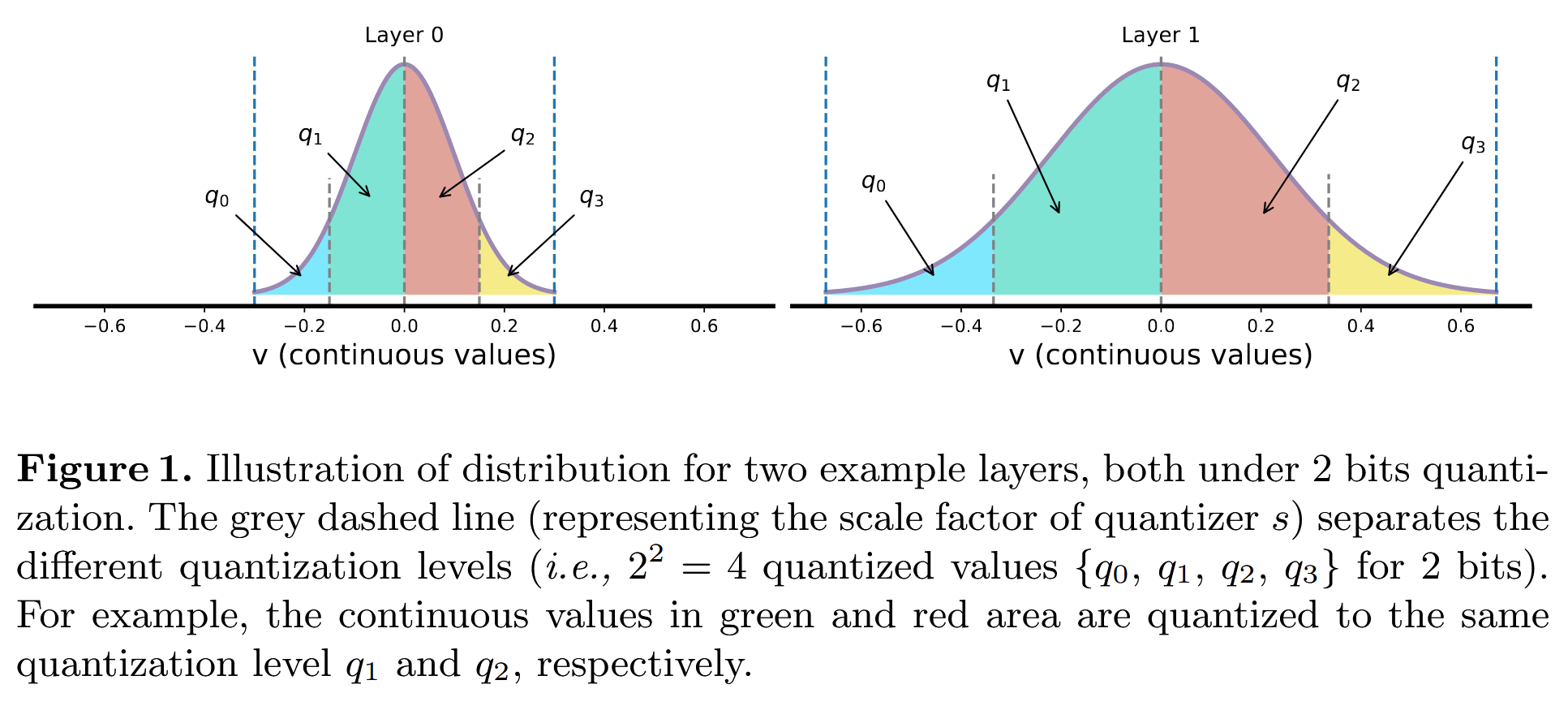
Mixed-Precision Neural Network Quantization via Learned Layer-wise Importance에 대하여...
13.PACT: PARAMETERIZED CLIPPING ACTIVATION FOR QUANTIZED NEURAL NETWORKS
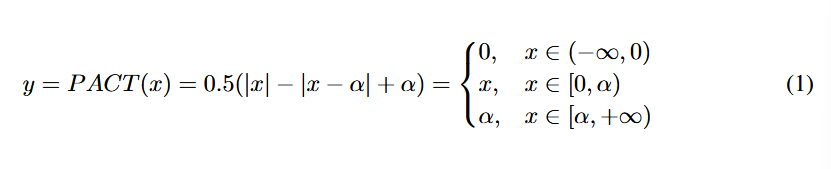
PACT에 관하여...
14.Post-Training Quantization for Vision Transformer
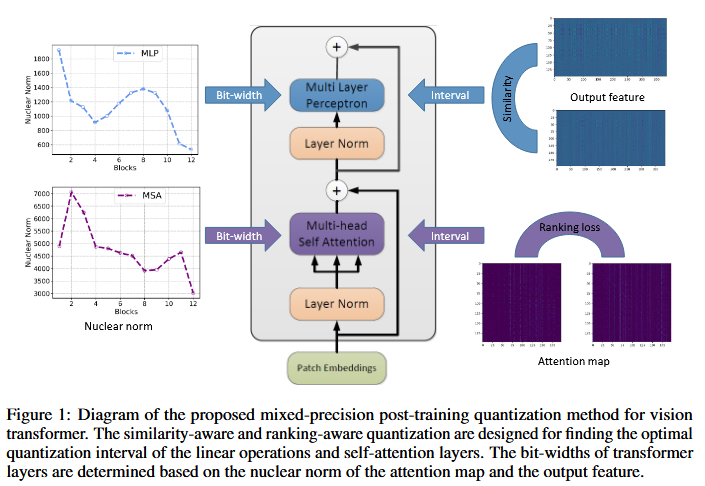
Post-Training Quantization for Vision Transformer 논문에 관하여...
15.PTQ4ViT
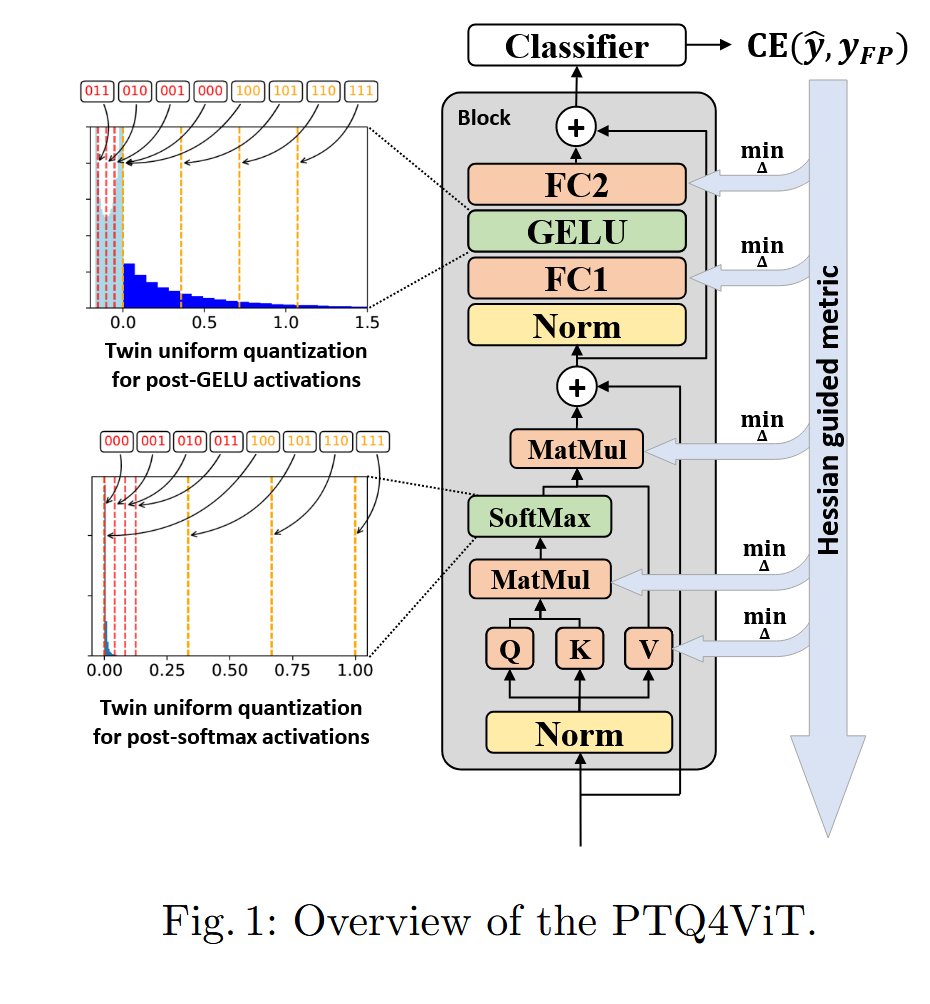
Ptq4vit: Post-training quantization for vision transformers with twin uniform quantization 논문에 관하여...
16.FQ-ViT: Post-Training Quantization for Fully Quantized Vision Transformer
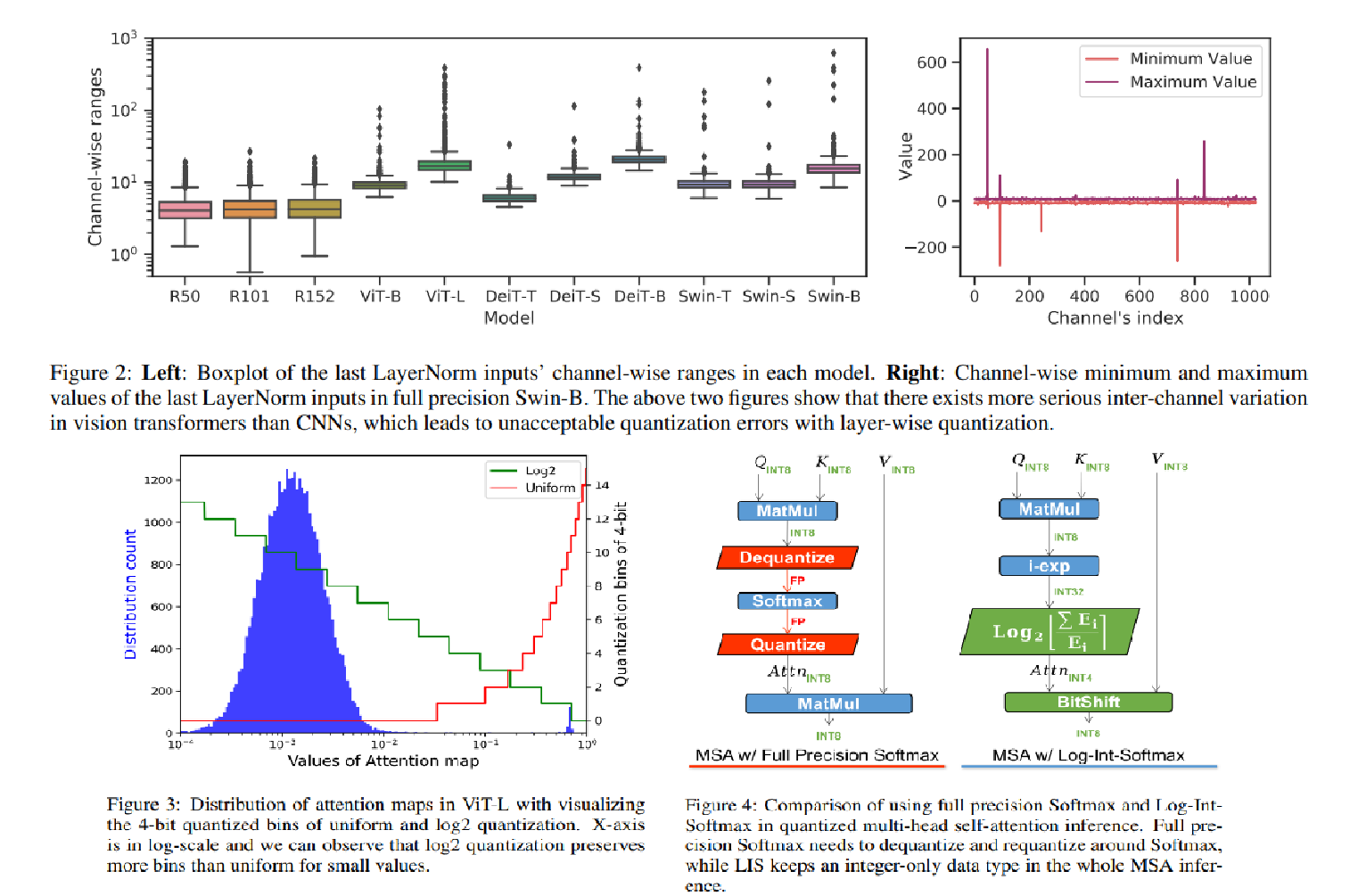
FQ-ViT: Post-Training Quantization for Fully Quantized Vision Transformer 논문에 대하여...
17.APQ-ViT: Towards Accurate Post-Training Quantization for Vision Transformer
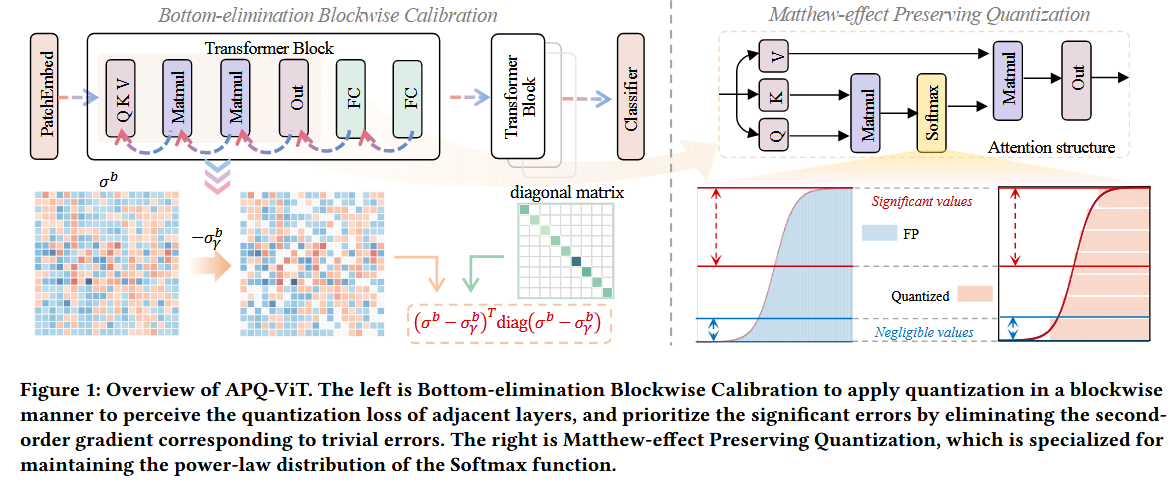
APQ-ViT: Towards Accurate Post-Training Quantization for Vision Transformer 논문에 대하여...
18.RepQ-ViT: Scale Reparameterization for Post-Training Quantization of Vision Transformers
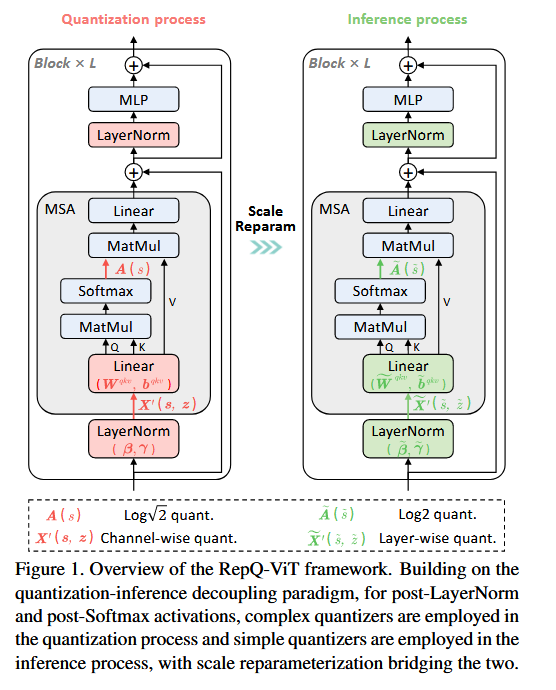
RepQ-ViT: Scale Reparameterization for Post-Training Quantization of Vision Transformers 논문에 대하여...
19.Hierarchical Reasoning Model
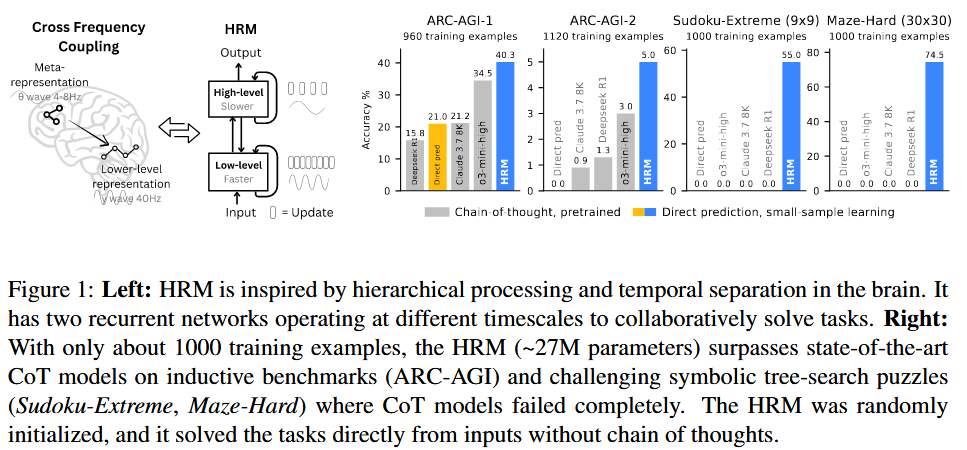
Hierarchical Reasoning Model 논문에 대하여...
20.Less is More: Recursive Reasoning with Tiny Networks
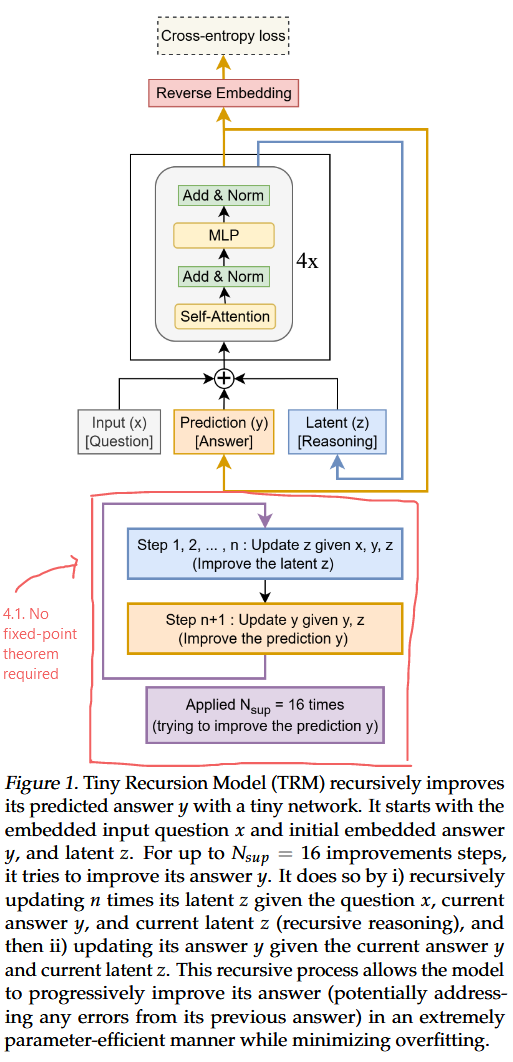
TRM에 대한 내용TRM은 HRM보다 훨씬 더 단순한 재귀적 추론 접근 방식으로, 단 2개의 레이어만 가진 하나의 초소형 네트워크를 사용하면서도 HRM보다 훨씬 더 높은 일반화 성능을 달성.HRM: 27MTRM: 7M1) recursive hierarchical rea
21.Early-Exit Deep Neural Network - A Comprehensive Survey
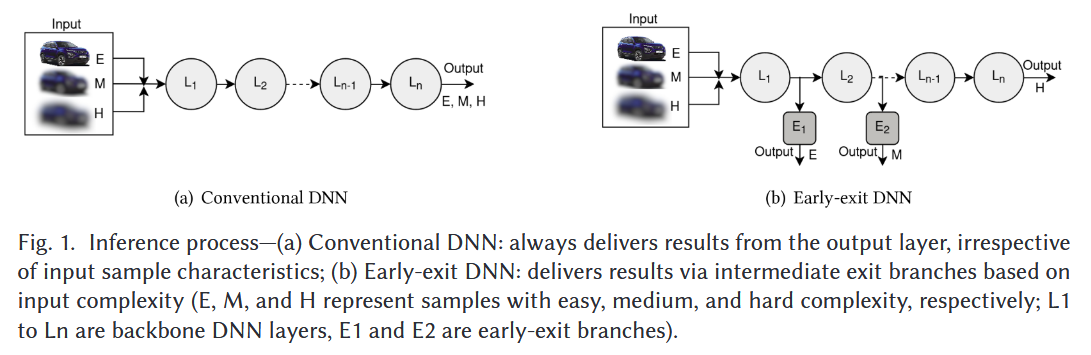
Early-Exit Deep Neural Network - A Comprehensive Survey 논문에 대하여...
22.Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA
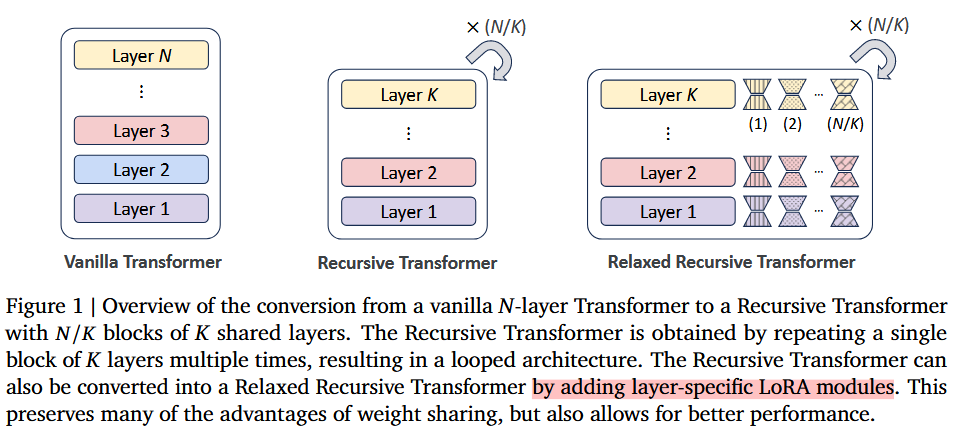
Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA Relaxed RT에 대한 내용 Abstract Contribution 기존 weight unshared model로
23.Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation
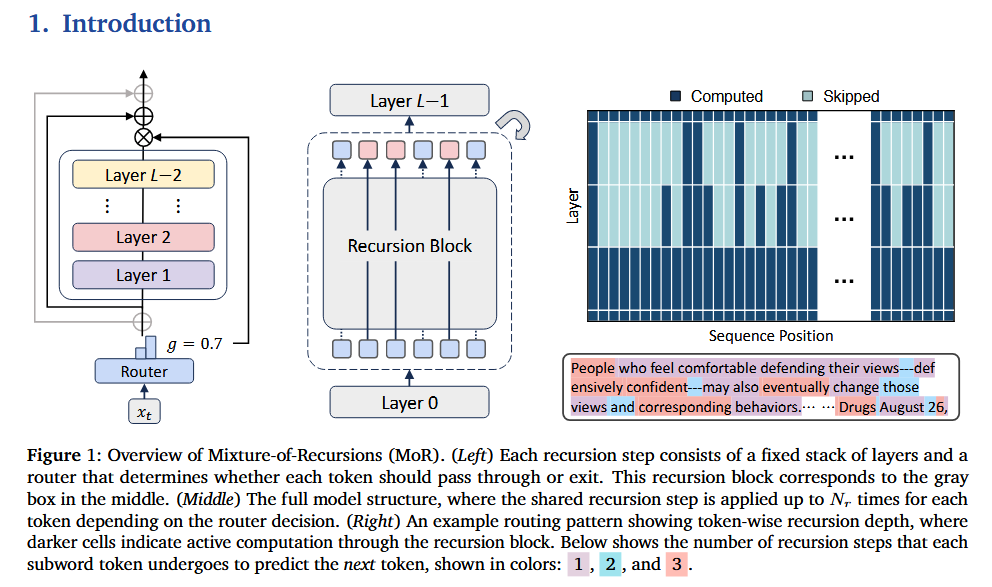
Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation 논문에 대하여...
24.DINOv3
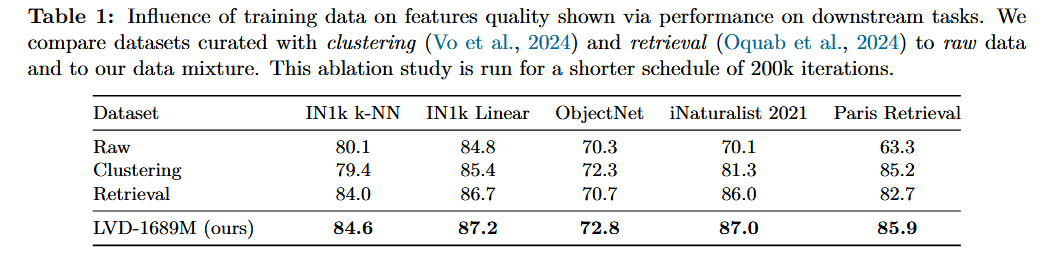
DINOv3 논문에 대하여...
25.Activation Quantization of Vision Encoders Needs Prefixing Registers
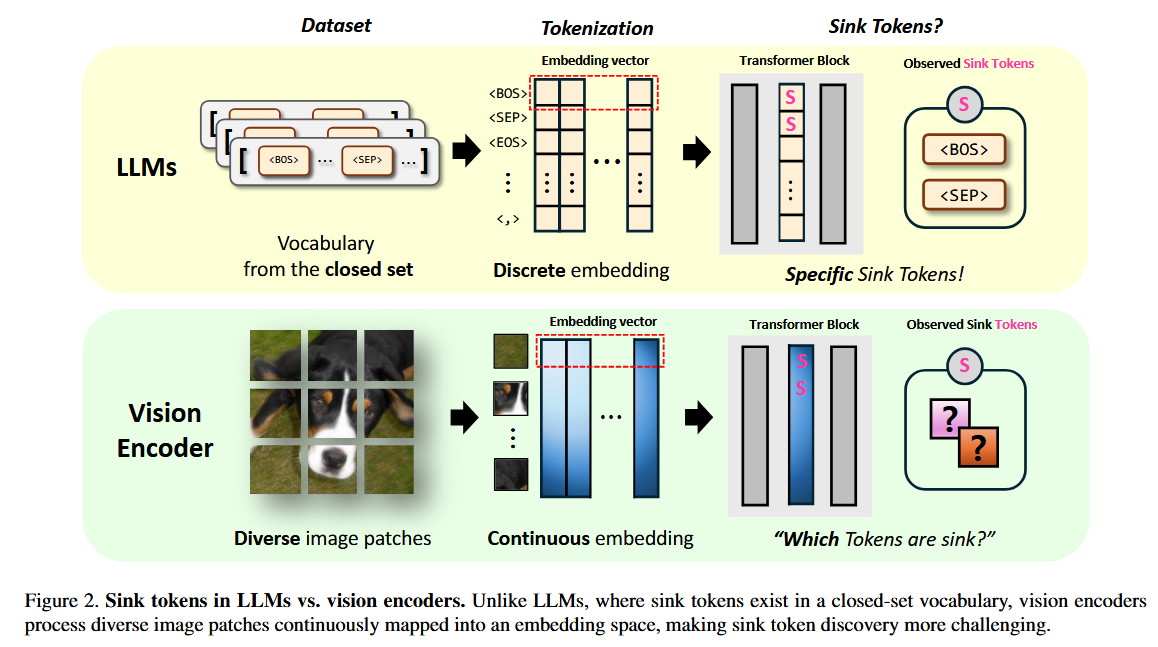
Activation Quantization of Vision Encoders Needs Prefixing Registers 논문에 대하여...
26.An Image is Worth 1/2 Tokens After Layer 2: Plug-and-PLay Acceleration for VLLM Inference

An Image is Worth 1/2 Tokens After Layer 2: Plug-and-PLay Acceleration for VLLM Inference 논문에 대하여...
27.PACT: Pruning and Clustering-Based Token Reduction for Faster Visual Language Models

PACT: Pruning and Clustering-Based Token Reduction for Faster Visual Language Models 논문에 대하여...
28.Each Complexity Deserves a Pruning Policy
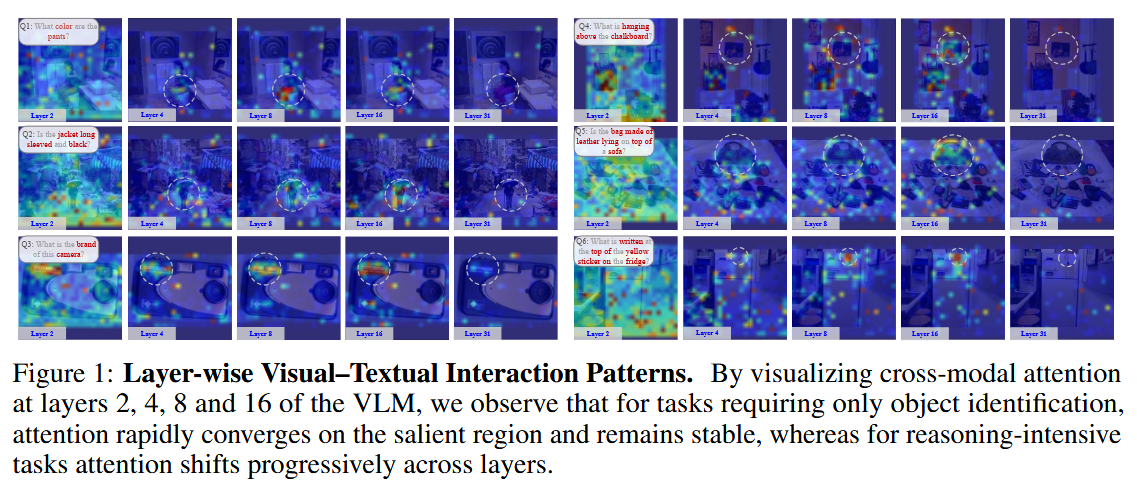
Each Complexity Deserves a Pruning Policy 논문에 대하여...
29.Focus, Don’t Prune: Identifying Instruction-Relevant Regions for Information-Rich Image Understanding
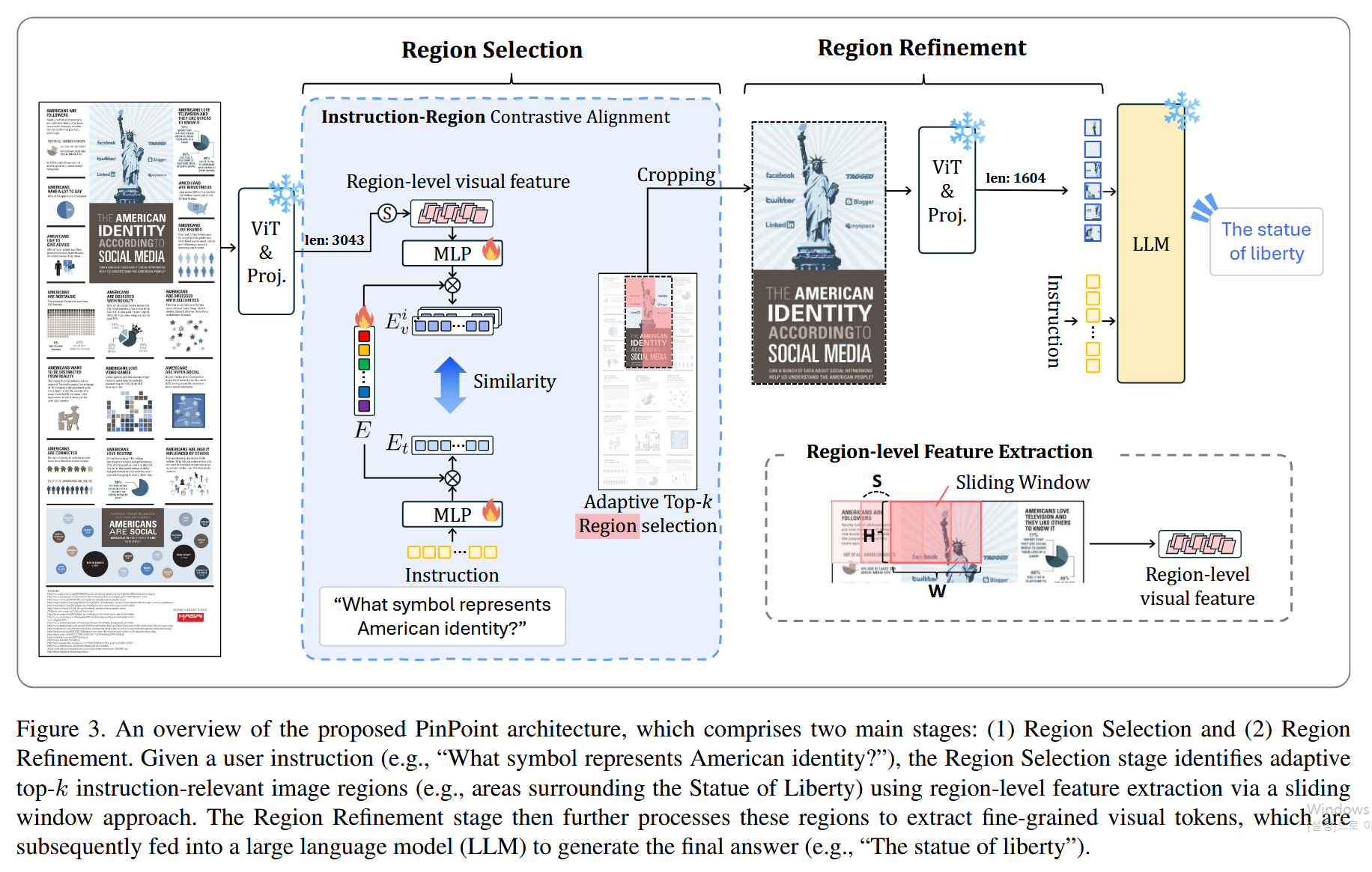
Focus, Don’t Prune: Identifying Instruction-Relevant Regions for Information-Rich Image Understanding 논문에 대하여...
30.Rethinking Token Reduction for Large Vision-Language Models
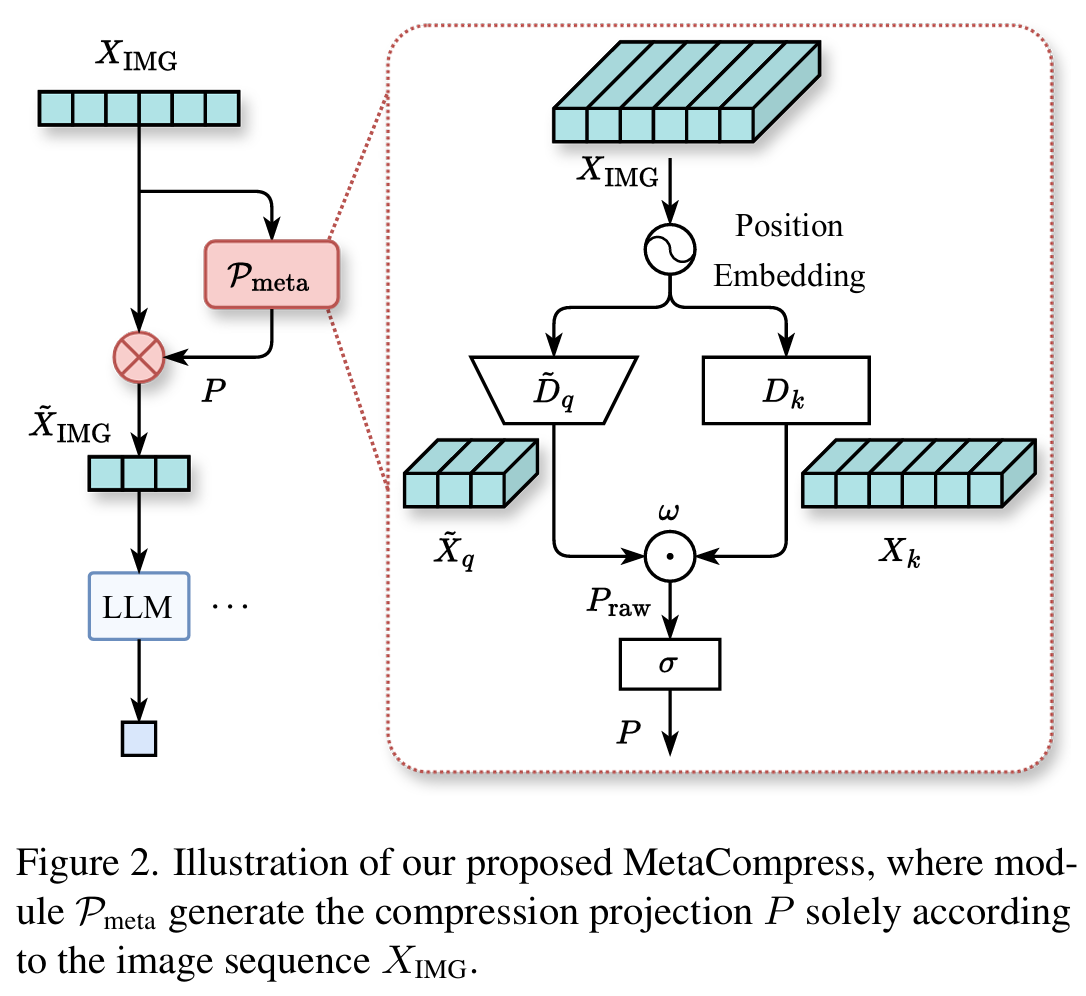
Rethinking Token Reduction for Large Vision-Language Models 논문에 대하여...
31.SparseVILA: Decoupling Visual Sparsity for Efficient VLM Inference
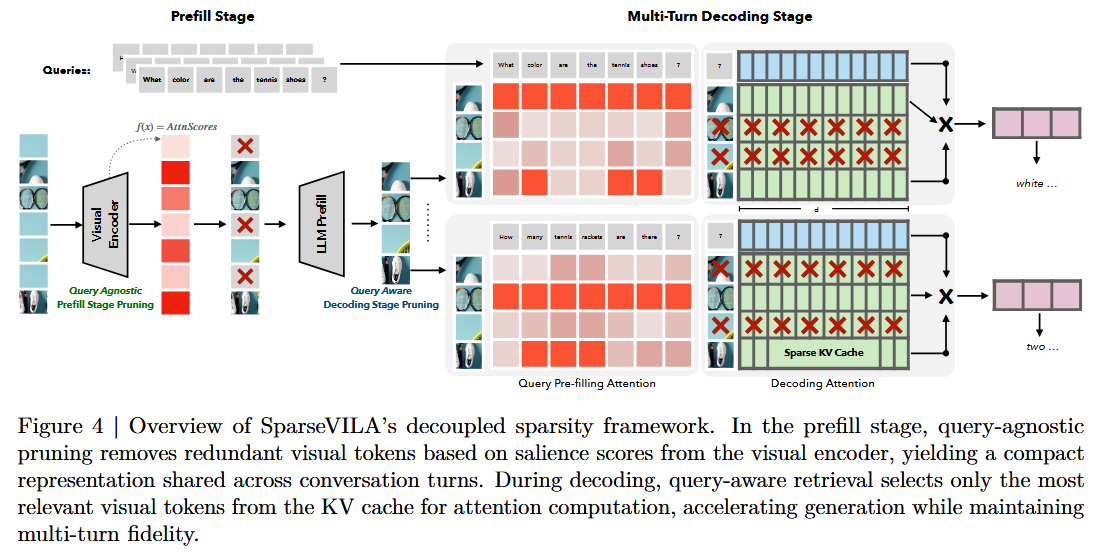
SparseVILA : Decoupling Visual Sparsity for Efficient VLM Inference 논문에 대하여...
32.VisionZip: Longer is Better but Not Necessary in Vision Language Models
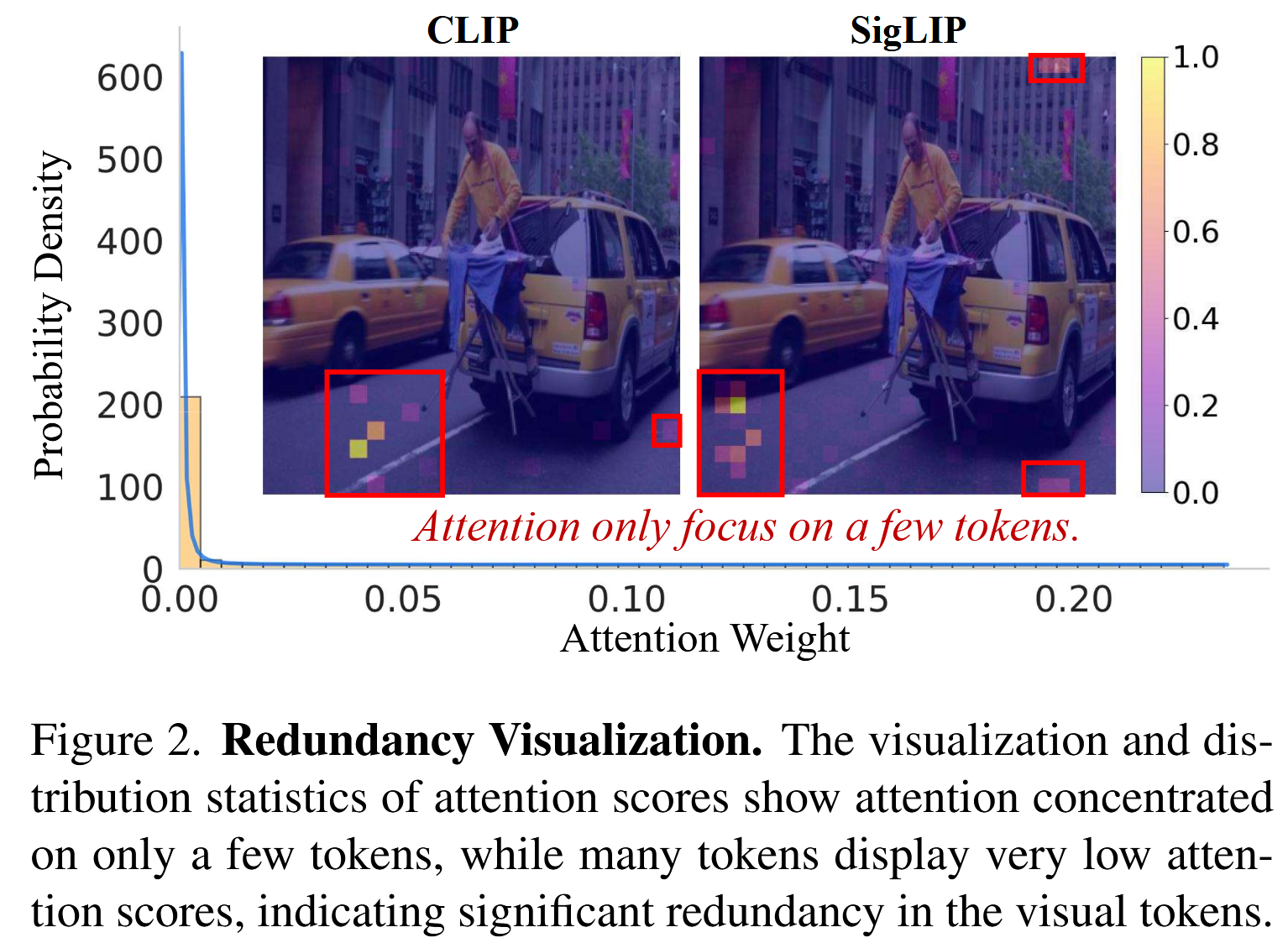
VisionZip: Longer is Better but Not Necessary in Vision Language Models 논문에 대하여...