1. Generation-based MRC
문제 정의

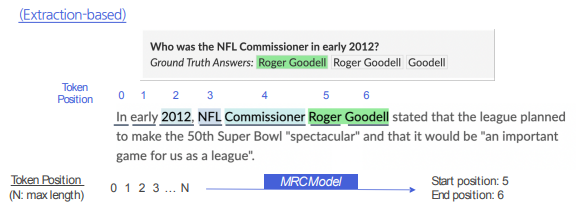
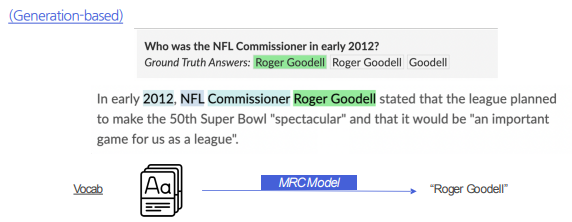
Extraction은 Generation 모델로 치환할 수 있다. 단지 치환을 하면 되므로, 다만 Generation은 Extraction으로 치환할 수 없다. 특히 답변이 없는 경우는 더더욱 그렇다.
평가 방법
보통 Extraction과 같이 EM이나 F1 Score를 사용하기도 하지만, 조금 더 생성문제와 일반적으로 비슷하게 접근하기 위해서는 BLEU 같은 스코어를 사용하기도 한다.
Overview
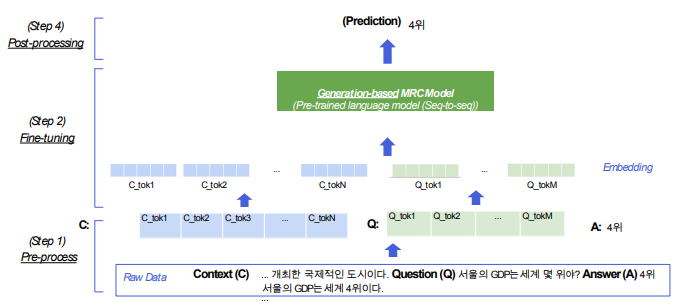
Input쪽은 Extraction과 동일하다. Context와 Question을 Tokenize한 다음에 Embedding으로 넘겨서 MRC-Model에 입력하게 된다. 다른 점은 Extraction의 경우 Output으로 나오는 Encoder Embedding을 점수로 바꾸어서 Start와 End를 예측했다면 Generation의 경우는 정답까지 생성하게 된다.
일종의 seq-to-seq 모델로 볼 수 있다. 모든 Pretrained model이 seq-to-seq을 할 수 있는 것은 아니다. 버트의 경우 인코더만 있고 디코더는 없기 때문에 generation 모델로서 활용할 수 없다. 강의에서는 간단하게 어떤 모델들을 활용할 수 있는지 알아보려고 한다.
Genertaion vs Extraction
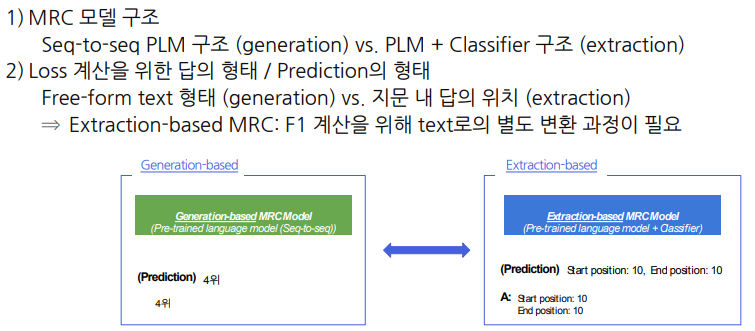
Genertaion의 경우 주로 Teacher Forcing의 방법으로 학습을 하게 된다.
2. Pre-processing
데이터
Generation의 전처리는 Extraction보다 간단하다. Extraction의 경우, 정답의 위치를 정확히 특정해야 했는데 Generation의 경우 그럴 필요가 없다. 정답 그대로 넘겨주면 된다.
토큰화

토크나이저의 경우 WordPiece 방식으로 사용한다. 이 때 미국이나 군대같은 단어는 자주 사용되므로 단어 자체가 그대로 토큰으로 유지되지만 직위같은 경우에는 직과 위로 나뉜것을 볼 수 있다.
Special Token
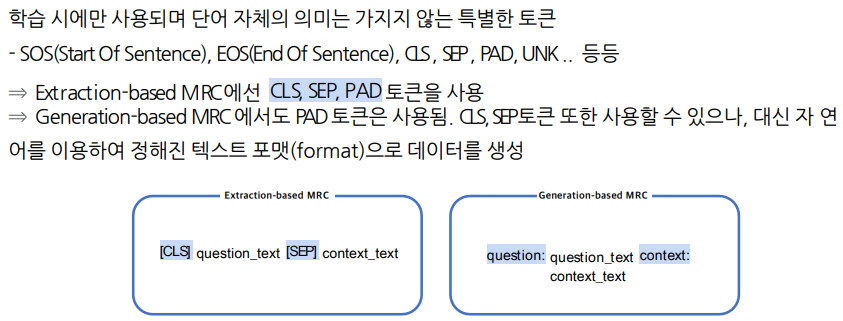
Generation에서 토큰을 사용하는지 또는 텍스트 포맷을 사용하는지는 사용하는 모듈에 달려있다. 이는 코드레벨에서 더 알아볼 것이다.
Additional information

초창기에는 이러한 정보를 Token ids같은 추가 정보를 가지고 직접적으로 구분하려고 했지만 모델은 SEP 토큰 등으로 충분히 구분할 수 있었고 그래서 모델들 중에 이러한 Token ids 항목을 제거한 모델들도 있는것으로 보인다.
출력 표현 - 정답출력
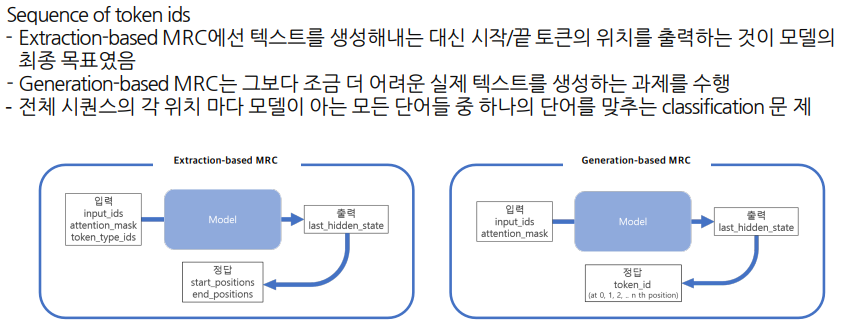
Task자체는 Extraction보다 어려울 수 있어도, Formulation 형태는 좀 더 간단하다.
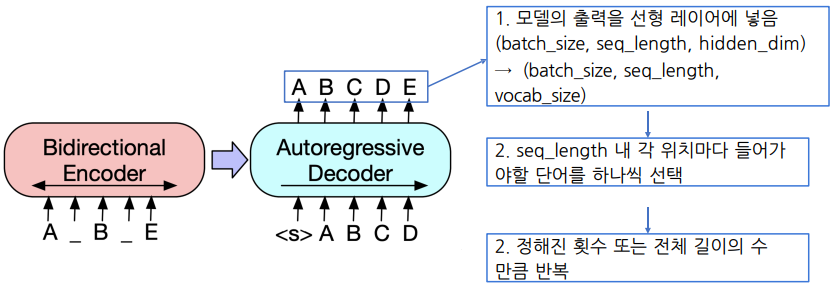
일반적인 디코딩 방법론을 사용해 Generation Task를 진행한다.
3. Model
BART
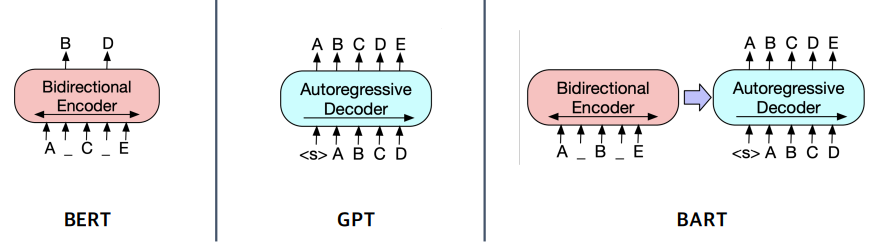
바트의 인코더는 버트의 인코더와는 조금 차이가 있다. 버트는 원래 문장에서 몇개의 토큰들을 마스킹한 다음 이 단어를 알아맞히는 방식으로 학습이 진행된다. 반면, 바트는 버트처럼 마스킹을 진행하지만 원래 단어를 알아맞히는 방식보다는 이 단어를 생성하는 방식으로 학습이 진행된다.
또, GPT와 달리 Noise를 주입하고 Noise가 없는 원래 문장을 re-construction 하는 문제로 보기 때문에 Denoising AutoEncoder 라는 표현도 많이 쓴다.
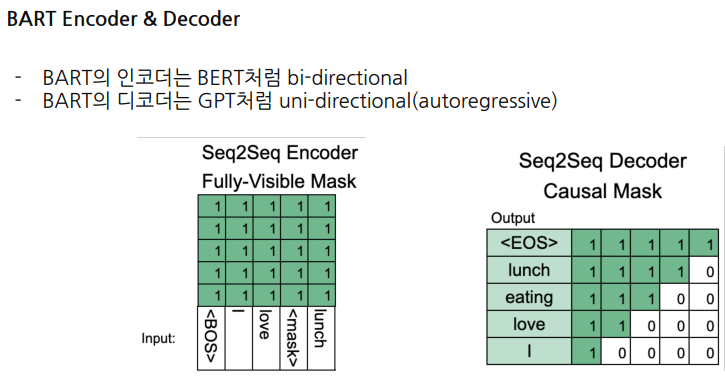
BART Encoder & Decoder
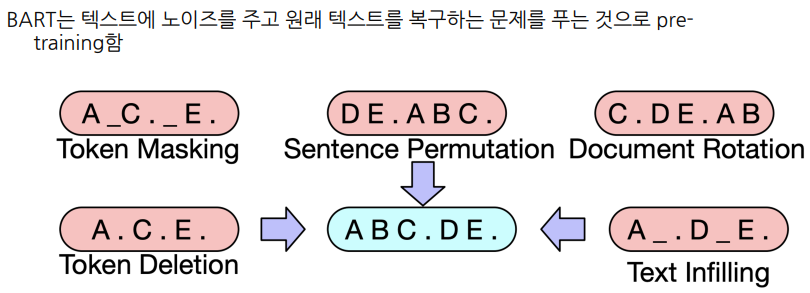
Pre-training BART
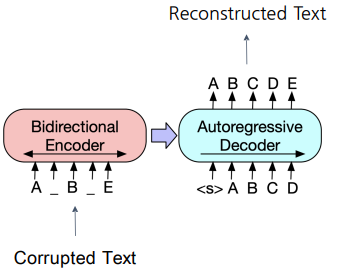
4. Post-processing
Searching
바트의 경우 이전 Output이 다음 포지션의 Input이 되는 방법을 사용한다.보통 맨처음 토큰은 SOS로 시작하여 모델이 디코딩을 시작하도록 유도한다.
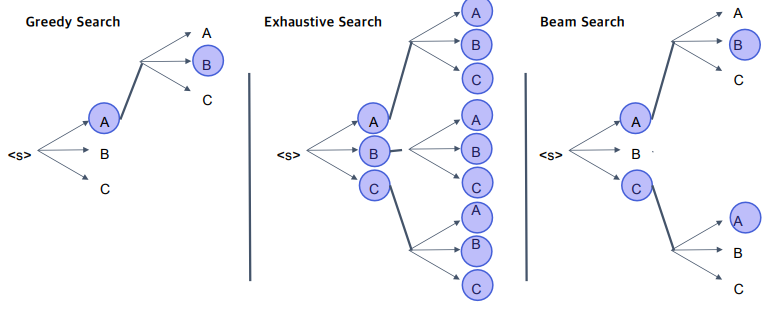
탐색 방법에는 위와 같은 것들이 있다.
- Greedy Search : 효율적으로 빠르게 문장을 생성하는 방법이다. 속도 자체는 매우 빠르지만, 초기에 최적의 답이 후기에는 최적의 답으로 향하는 선택이 아닐 수도 있기 때문에 상당히 안좋은 Output을 낼 수 있다. 다시 말해, Dicision Making을 Very Early Step에서 하게 되는 경우 나중에 나쁜 결과가 나올 수도 있는 것
- Exhaustive Search : 문장의 길이가 조금씩 길어져도 지수함수로 경우의 수가 증가하기 때문에 사실 상 불가능한 방법이다. 또 사전의 크기가 조금만 커져도 또 불가능한 방법이다.
- Beam Search : 그래서 주로 사용하는 방법이 이 방법이다. Exhaustive Search와 같이 현재 step에서 고려할 수 있는 모든 경우의 수를 따져보되, 이 중 k개 만큼만 가지를 뻗는 방식이다. 그래서 매 step마다 reranking을 하고 ranking 순으로 k개의 노드만을 유지하는 방법이다.
실습
라이브러리
!pip install datasets==1.4.1
!pip install transformers==4.4.2
!pip install sentencepiece==0.1.95
!pip install nltk다음의 라이브러리를 사용한다.
- huggingface에서 제공하는 datasets과 transforers
- 단어를 나눌 때 사용하는 sentencepiece
- 언어처리와 관련된 일반적인 툴 nltk
요즘에는 덜 쓰이지만 예전에는 정말 자주 쓰였던 nltk에 있는 토크나이저를 다운로드 한다.
import nltk
nltk.download('punkt')데이터 및 평가 지표 불러오기
from datasets import load_dataset
datasets = load_dataset("squad_kor_v1")from datasets import load_metric
metric = load_metric('squad')EM과 F1위주의 metric을 사용할 것이다.
Pre-trained 모델 및 토크나이저 불러오기
from transformers import (
AutoConfig,
AutoModelForSeq2SeqLM,
AutoTokenizer
)오토모델 시리즈는 모델을 불러올 때 상당히 편리하게 활용할 수 있다.
model_name = "google/mt5-small"바트와 용도는 비슷한 모델이며, 성능이나 자세한 구성요소는 조금 다르다. seq2seq, text를 input으로 해서 output으로 text를 반환하는 generation 모델이다.
원래, Original 모델의 이름은 t5 인데 multilinqual을 의미하는 m이 추가적으로 붙었다. 비교적 작은 사이즈를 사용할 것이다.
config = AutoConfig.from_pretrained(
model_name,
cache_dir=None,
)
tokenizer = AutoTokenizer.from_pretrained(
model_name,
cache_dir=None,
use_fast=True,
)
model = AutoModelForSeq2SeqLM.from_pretrained(
model_name,
config=config,
cache_dir=None,
)특정 언어만 사용하면 모델의 크기가 좀 더 줄어들 수 있다. 여기서는 m모델을 사용하기 때문에 좀 더 다운받는데 시간이 더 걸린다.
설정하기
max_source_length = 1024
max_target_length = 128
padding = False
preprocessing_num_workers=12
num_beams = 2
max_train_samples = 16
max_val_samples = 16
num_train_epochs = 3디코딩을 위한 max_target_length와 beam search를 위한 num_beams를 설정해준다.
전처리하기
def preprocess_function(examples):
inputs = [f'question: {q} context: {c} </s>' for q, c in zip(examples['question'], examples['context'])]
targets = [f'{a["text"][0]} </s>' for a in examples['answers']]
model_inputs = tokenizer(inputs, max_length=max_source_length, padding=padding, truncation=True)
# Setup the tokenizer for targets
with tokenizer.as_target_tokenizer():
labels = tokenizer(targets, max_length=max_target_length, padding=padding, truncation=True)
model_inputs["labels"] = labels["input_ids"]
model_inputs["example_id"] = []
for i in range(len(model_inputs["labels"])):
model_inputs["example_id"].append(examples["id"][i])
return model_inputs인풋을 토크나이징 하고 이 결과를 모델의 입력 키로 지정해주는 것이 전부이다. Extraction에 비해 간단해진 이유는 위치를 특정하는 Logic이 있느냐 없느냐의 차이이다. 모델 자체는 좀 더 복잡한 task를 한다고 볼 수 있지만 유저 입장에서 모델은 블랙박스의 개념이므로 좀 더 간단하게 느껴질 수 있다.
column_names = datasets['train'].column_names
train_dataset = datasets["train"]
train_dataset = train_dataset.select(range(max_train_samples))
train_dataset = train_dataset.map(
preprocess_function,
batched=True,
num_proc=preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=False,
)실습을 위해 16개의 sample(max_train_samples)만 볼 것이다. 이 때 preprocess_function을 lambda 함수로 넣어주면서 필요한 형태의 처리를 효율적으로 하게된다. map을 사용하면 이런 효율성을 한번에 할 수 있는 장점이 있다.
eval_dataset = datasets["validation"]
eval_dataset = eval_dataset.select(range(max_val_samples))
eval_dataset = eval_dataset.map(
preprocess_function,
batched=True,
num_proc=preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=False,
)
Fine-tuning 하기
from transformers import (
DataCollatorForSeq2Seq,
Seq2SeqTrainer,
Seq2SeqTrainingArguments
)이전에 쓰던것은 트랜스포머의 인코더를 위한 trainer였고 지금은 seq2seq을 위한 trainer이다. 또한, DataCollator를 사용하면 CPU에서 병렬적으로 처리가 가능할 수 있게된다. 이 역시 seq2seq 버전으로 사용한다.
label_pad_token_id = tokenizer.pad_token_id
data_collator = DataCollatorForSeq2Seq(
tokenizer,
model=model,
label_pad_token_id=label_pad_token_id,
pad_to_multiple_of=None,
)pad_token을 무시하기 위해 따로 지정해준다.
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [label.strip() for label in labels]
preds = ["\n".join(nltk.sent_tokenize(pred)) for pred in preds]
labels = ["\n".join(nltk.sent_tokenize(label)) for label in labels]
return preds, labelspreds와 labels의 공백을 제거한 뒤 new line으로 join해서 하나의 텍스트로 만들게 된다. 개행문자를 사용한 이유는 원소들이 단어가 아닌 하나의 문장으로 이루어져있기 때문이다.
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
# decoded_labels is for rouge metric, not used for f1/em metric
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
formatted_predictions = [{"id": ex['id'], "prediction_text": decoded_preds[i]} for i, ex in enumerate(datasets["validation"].select(range(max_val_samples)))]
references = [{"id": ex["id"], "answers": ex["answers"]} for ex in datasets["validation"].select(range(max_val_samples))]
result = metric.compute(predictions=formatted_predictions, references=references)
return resultpred와 label을 불러와 전처리를 한뒤 지정된 metric으로 평가한다.
args = Seq2SeqTrainingArguments(
output_dir='outputs',
do_train=True,
do_eval=True,
predict_with_generate=True,
num_train_epochs=num_train_epochs
)
trainer = Seq2SeqTrainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)학습 방법을 지정해준다.
train_result = trainer.train(resume_from_checkpoint=None)Extraction보다 학습이 오래걸리지만 여기서는 적은 샘플로 진행하다보니 금방 끝난다. 다만, 좋은 성능이 나오지는 않을 수 있다.
평가하기
metrics = trainer.evaluate(
max_length=max_target_length, num_beams=num_beams, metric_key_prefix="eval"
)max_length를 지정해주는 것을 유의하기
metrics{'epoch': 3.0,
'eval_exact_match': 0.0,
'eval_f1': 1.5625,
'eval_loss': 31.144439697265625,
'eval_mem_cpu_alloc_delta': 2078043,
'eval_mem_cpu_peaked_delta': 234047,
'eval_mem_gpu_alloc_delta': 0,
'eval_mem_gpu_peaked_delta': 368118272,
'eval_runtime': 1.7881,
'eval_samples_per_second': 8.948}