BoostCamp-MRC
1.(3강) Generation-based MRC
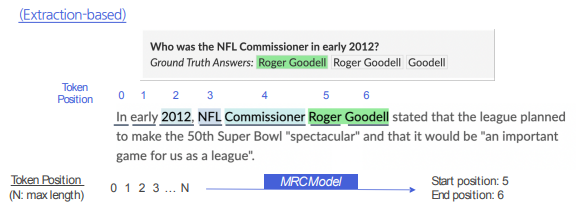
Extraction은 Generation 모델로 치환할 수 있다. 단지 치환을 하면 되므로, 다만 Generation은 Extraction으로 치환할 수 없다. 특히 답변이 없는 경우는 더더욱 그렇다.보통 Extraction과 같이 EM이나 F1 Score를 사용하기도
2.(4강) Passage Retrieval - Sparse Embedding
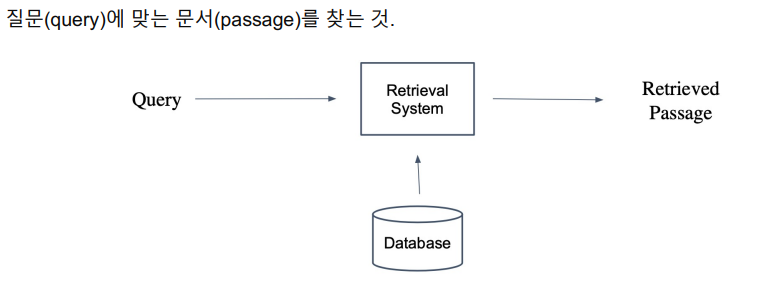
우리 대회에서는 위키피디아가 해당되겠지만 일반적인 경우는 웹 사이트가 해당될 것이다.이런 시스템이 왜 필요할까? 1~3강에서 배웠던 MRC 시스템과 연동하면 Open Domain System이 될 수 있기 때문이다.이 때 모델은 주어진 질문에 관한 도메인을 데이터베이스
3.(5강) Passage Retrieval - Dense Embedding

목표는 어떠한 Passage를 벡터화 하는 것이며 이 중 우리는 Sparse Embedding을 사용했다.Bag of Words론을 택하기 때문에 특정 단어에 해당하는 벡터의 차원만이 non-zero가 된다. 사실상 90% 이상이 zero인 sparse matrix가
4.(6강) Scaling up with FAISS
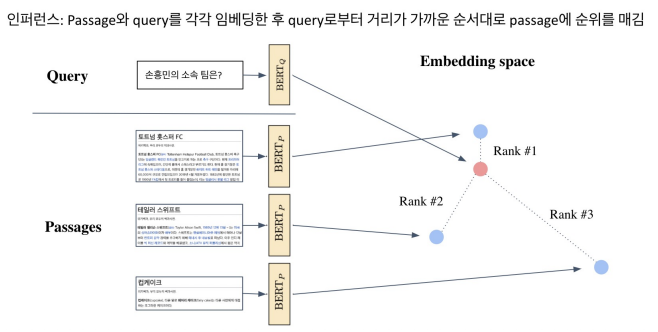
Passage가 많아질수록 아무리 내적이라 할지라도 연산량이 부담될 수 밖에 없으며 6강에서는 어떻게 가장 가까운 Passage를 효율적으로 찾을까에 대해 이야기한다.Nearest Neighbor와 같은 L2 Distance를 측정하는 것보다 두 개의 벡터의 dot p
5.(7강) Linking MRC and Retrieval
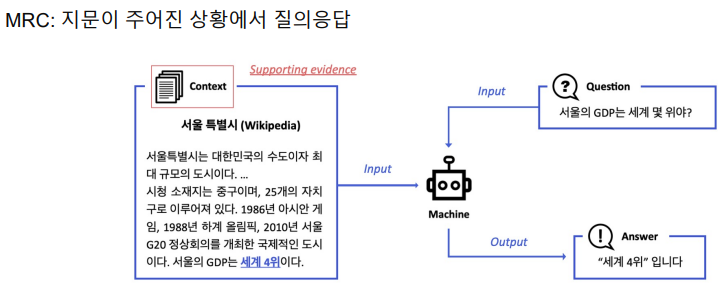
input과 output은 비슷하다. 단지 지문을 참고해야 하는 수가 다르다. ODQA는 엄청난 양의 passage를 read해야한다.최근에 구글 등의 검색 엔진 사이트는 검색어에 대한 연관문서 뿐만 아니라 질문의 답을 같이 제공한다.이는 예전에도 한번 다뤄졌던 주제이