1. 연관 사상 캐시
1-1. 종류
-
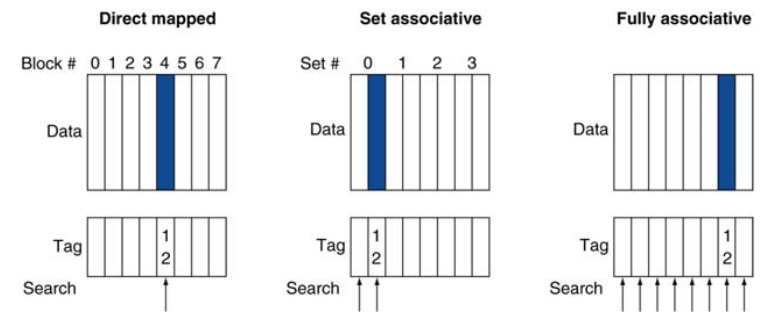
완전 연관 사상 : 블럭이 아무 캐시 엔트리에나 저장될 수 있다. 엔트리마다 comparator가 필요해 비싸다
-
n-way 집합 연관 사상 : 각 집합은 n개의 엔트리를 가지고, 블럭 인덱스로 집합 결정
n개의 comparator를 가져 집합 내 모든 엔트리에서 동시에 찾는다

1-2. 연관 사상 예시
- 4-블럭 캐시

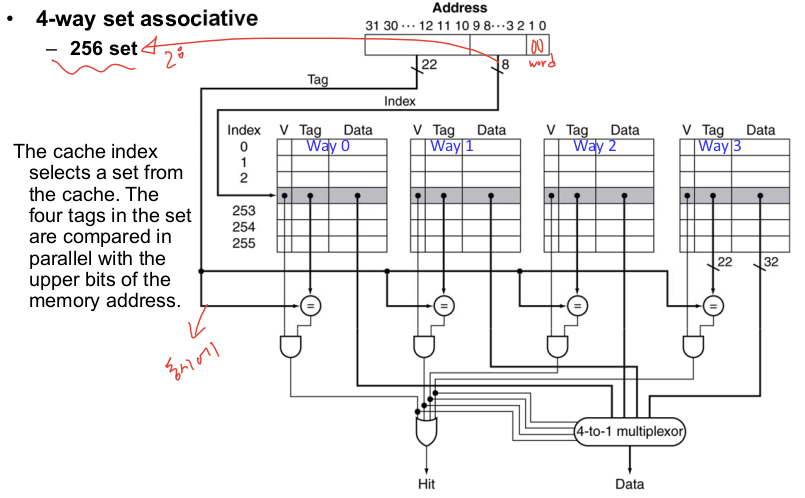
1-3. 집합 연관 캐시
- index : 집합을 선택
- tag : 집합 내 태그와 비교
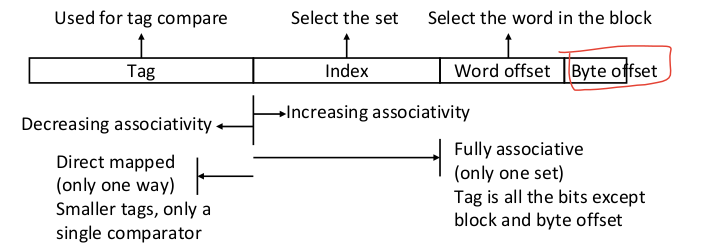
- 크기가 고정된 캐시 내에서 연관성을 높이면 인덱스가 1비트 줄어 집합의 수는 절반이 되고 집합 내 블럭의 수는 2배가 된다.
- n-way 집합 연관 캐시의 비용 : n comparators, MUX delay, set selection
2. 교체 정책
- 미스 발생 시 어떤 블럭을 갱신할 것인가?
- 직접 사상 : 선택 x
- 집합 연관 사상 : 빈 엔트리가 있다면 사용, 없으면 집합 내 엔트리 중 선택
2-1. Least-Recently Used (LRU)
- 하드웨어가 접근 기록을 저장
- 가장 오랫동안 접근 안된 엔트리를 선택
- 2-way, 4-way까지는 쓸 수 있지만, 뒤로는 매우 어려워서 사용 x
2-2. Random
- 랜덤으로 선택, 연관성이 높을 때 LRU와 거의 같은 성능 제공
2-3. Pseudo LRU
- replacement pointer를 가지고 해당 엔트리에 접근 시 포인터를 다음 엔트리로 이동
3. 멀티레벨 캐시
3-1. 연관성과 멀티레벨 캐시
- 미스율을 낮추려면 캐시 크기를 키우거나(비쌈) 연관성을 증가 시킬 수 있다
- 연관성을 높이면 미스율이 낮아짐, 하지만 그 효율은 점점 감소한다
- 64kb D-cache, 16-word blocks 예시

- 캐시의 크기와 속도로 계층을 구성해서 미스 시 페널티를 줄일 수 있다.
3-2. 멀티레벨 캐시 예시
-
Base CPI = 1, Clock rate = 4Ghz = 0.25ns/cycle
Miss rate/inst = 2%, Main mem access time = 100ns -
캐시가 하나 일 때
Miss panelty = 100ns/0.25ns = 400 cycles
CPI = 1 + (0.02*400) = 1 + 8 = 9 -
L2 캐시
접근 시간 = 5ns, 글로벌 미스율 = 0.5%, L1 미스 L2 히트 페널티 = 5ns/0.25ns = 20 cycles
CPI = 1 + 2%*20 + 0.5%*400 = 3.4
3-3. 캐시 설계 공간
캐시 설계 시 고려할 사항들
- 캐시 크기
- 블럭 크기
- 연관성
- 교체 정책
- write-through vs. write-back
- write-allocation
- 최적의 선택은 접근 성격이나 비용 등에 따라 다름
- 간단한 방법을 사용하는게 최적일 때도 많음
4. 가상 메모리
메인 메모리를 디스크의 캐시로 이용하는 것
-
CPU 하드웨어와 OS에서 합동 관리한다
i. 가상 주소를 물리 주소로 변환
ii. 메모리 보호와 공유
iii. 효율적인 메모리 사용 -
가상 메모리에서 블럭 = 페이지, 미스 = 페이지 폴트
-
물리적 메모리와 상관없이 프로세서가 메모리를 보는 방법이다
-
물리 메모리보다 큰 프로그램, 멀티 프로그래밍, 시스템 독립적 프로그램, 물리 메모리와 독립된 시스템 개발에 용이
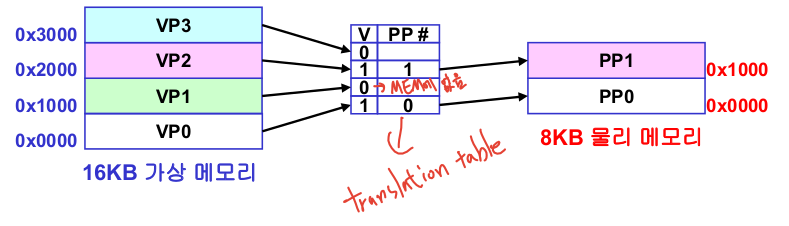
4-1. 가상 메모리 작동
-
가상 메모리와 물리 메모리는 페이지 단위로 나눠진다
-
가상 페이지를 위한 변환 테이블을 생성한다 (valid bit, physical page address)
-
작동 : 가상 주소로부터 가상 페이지 얻은 후 페이지(변환) 테이블에 접근 해 물리 메모리에 접근한다
-
페이지 테이블은 메모리에 존재한다
4-2. 가상 메모리 응용
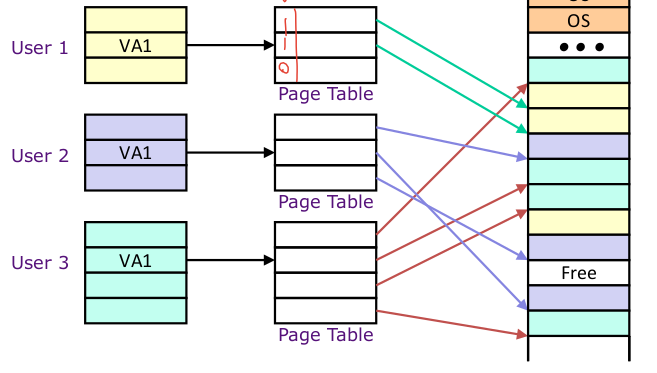
페이지 테이블로 인해 프로그램의 페이지들을 비 연속적으로 저장할 수 있다
- 프로그램 메인 메모리 공유
각각 가상 메모리 공간을 얻는다
각 가상 메모리 공간은 은닉되어 서로로부터 보호된다
각 프로그램은 페이지 테이블을 갖는다
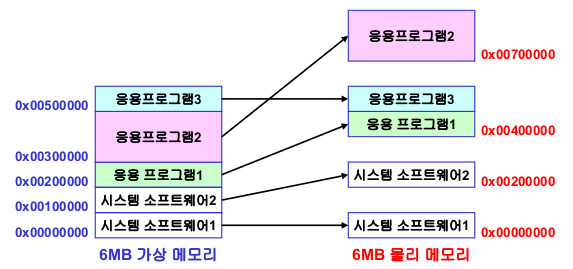
- 물리 메모리 독립적 시스템 개발
시스템과 응용프로그램이 메모리 주소 0부터 실행할 수 있도록 한다
프로그램은 물리적/설계된 메모리 구조로 로드 된다
프로그램은 주소 변환으로 접근한다
프로그램이 다른 시스템으로 포팅 될 때만 변환을 바꾼다
5. Paging Organization
-
디스크 엑세스로 인해 페이지 전송은 비용이 많이 든다
미스 페널티 또한 커서 페이지의 크기는 비교적 커야한다 (ex. 4KB)
페이지 폴트를 줄이는 것이 중요하다 (LRU의 비용을 감수하고 사용한다)
Write-through는 비용이 너무 크기에 Write-back을 사용한다 -
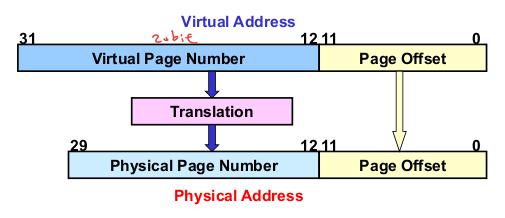
가상/물리 주소 공간 예시
가상 주소 : 32bit -> 4GB 가상 주소 공간
물리 주소 : 30bit -> 1GB 물리 주소 공간
페이지 크기 : 12bit -> 4KB
5-1. 페이지 주소 변환

- 페이지 테이블 크기 : 2^20 entry * 24 bits = 3MB per user
- 64bit 가상 주소 공간 : 페이지 크기가 1MB여도 2^44 페이지 테이블 엔트리 필요
5-2. Two-level Paging System
- 페이지 테이블이 너무 커질때 사용
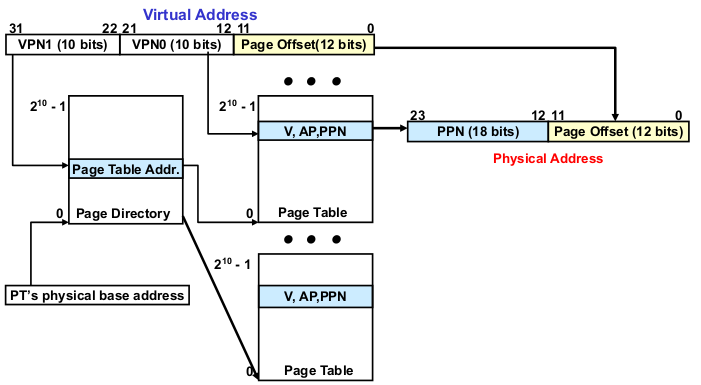
- page directory = 2^10 entry * 30bits = 3.7KB
- page table = 2^10 entry * 24bits = 3KB
5-3. 페이지 폴트 페널티와 쓰기
-
페이지 폴트 발생 시 디스크로부터 페이지를 가져와야한다
수백만 클럭 사이클 비용 발생 -
페이지 폴트율을 낮추기 위해 완전 연관 배치(페이지를 아무곳에나 배치 가능)와 LRU 사용한다
페이지 접근 시 use bit = 1, 주기적으로 OS가 0으로 비움, use bit = 0은 최근 사용 안됨 -
디스크 쓰기에 수백만 사이클 필요하다
write-through는 불가해서 write-back을 이용한다
페이지에 쓰기 할 때 dirty bit 표시된다
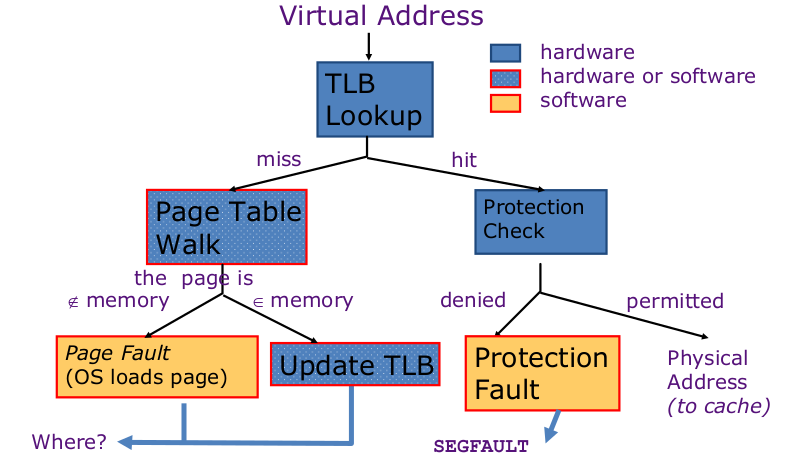
5-4. TLB를 이용한 빠른 변환
-
주소 변환은 추가적인 메모리 참조를 필요로 함 (PTE 접근 1번, 실제 메모리 접근 1번)
-
하지만 페이지 테이블 접근은 좋은 지역성을 가짐
-
CPU내 별도의 PTE들의 캐시를 사용 : Translation Look-aside Buffer(TLB)
-
16~512개 PTE 캐시, 0.5~1 cycle 히트, 10~100 cycle 미스, 미스율 = 0.01%~1%
미스는 하드/소프트웨어로 처리
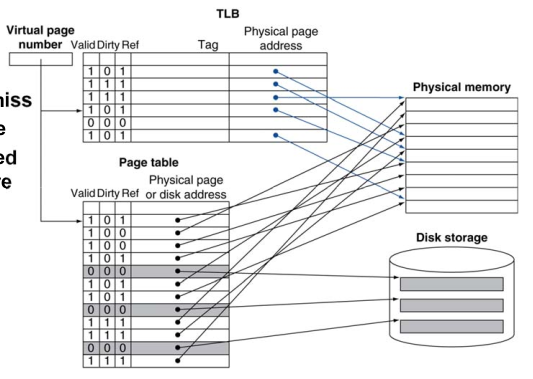
- TLB와 캐시 상호작용
캐시 tag 물리 주소 사용시 : 캐시 확인 전 변환 과정 거쳐야함. 그후 캐시 접근
>> 캐시 tag 가상 주소 사용하여 해결할 수 있지만, 다른 가상 주소가 같은 물리 주소를 가리키는 등 앨리어싱 문제 발생 가능
6. 주소 변환 정리