
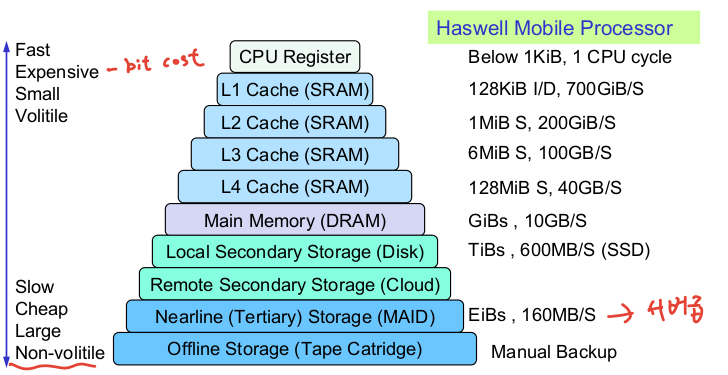
1. 메모리 계층 구조
용량, 비용, 속도를 효율적으로 사용하기 위해 메모리는 계층 구조를 가진다
2. 지역성의 원리
프로그램은 어떤 때든 주소 공간의 일부분만 접근한다
2-1. 시간적 지역성
- 최근 접근한 요소를 다시 접근할 확률이 높다
ex) loop의 induction variable
2-2. 공간적 지역성
- 최근 접근한 요소 주변에 있는 요소에 접근할 확률이 높다
ex) 절차적 명령어 접근, array
2-3. 지역성 활용하기
- 메모리 계층 구조
- 디스크에 모든 것 저장
- 최근 접근한 요소와 그 주변 요소를 DRAM으로 복사
- 더 최근에 접근한 요소와 그 주변 요소를 SRAM으로 복사
- 복사 단위 = Block
3. 메모리 기술
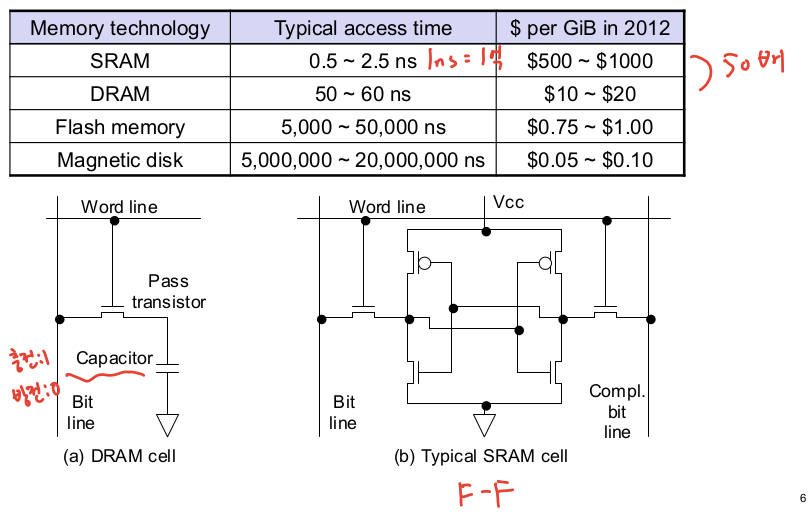
3-1. DRAM 기술
- DRAM의 bit는 2차원 배열으로 정렬
- Capacitor에 1비트 저장
- 한번에 한 row를 읽을 수 있음, row buffer 이용
- DDR = 클럭 업/다운틱에 엑세스
- capacitor의 한계로 속도 개선이 느려졌고 cpu와의 성능 차이가 심화됨
3-2. Flash Storage 기술
- 비휘발성 반도체 저장매체
- 디스크의 100~1000배 속도
- NOR flash : Random read/write acces
- NAND flash : block-at-a-time access
- 비트 10,000번 접근 후 고장
3-3. Disk Storage 기술
- 비휘발성 자기성 회전 저장매체
- 단위 = sector
- 각 sector : sector ID, Data(512B), ECC, Sync fields and gaps 기록
- sector 접근 지연시간 = 순서 대기 + 헤드를 움직여 찾기 + 회전 지연 + 데이터 전송 + 컨트롤러 오버헤드
ex) 512B sector, 15,000 rpm, 4ms seek, 100MB/s transfer, 0.2ms controller overhead
>> 평균 읽기 시간 = 4ms + (0.5)/(15,000rpm/60min) + 512B/100MB/s + 0.2ms = 6.2ms - Disk 내 캐시 포함
4. 캐시 메모리
4-1. 캐시
-
CPU에 가장 가까운 메모리
-
Hit : CPU 접근 데이터가 캐시에 존재할 때
-
Miss : CPU 접근 데이터가 키시에 없을 때
-
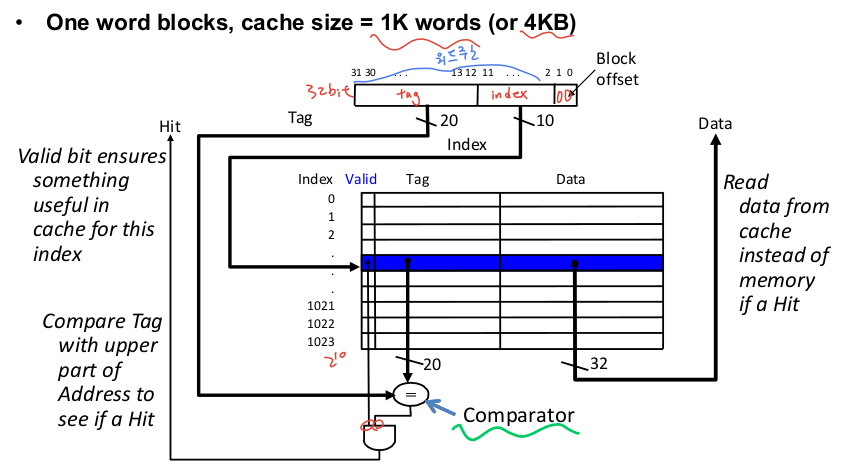
데이터의 접근은 주소로 하기 때문에 캐시도 주소 정보를 가지고 있어야함
= tag
4-2. 직접 사상 캐시
-
주소와 캐시 블럭 사이즈 모듈러 연산으로 위치 결정
-
캐시 블럭 사이즈 = 2^인덱스 비트 수
-
단일 워드 블럭 직접 사상 캐시
= 시간적 지역성 이용
-
멀티 워드 블럭 직접 사상 캐시
= 공간적 지역성 이용
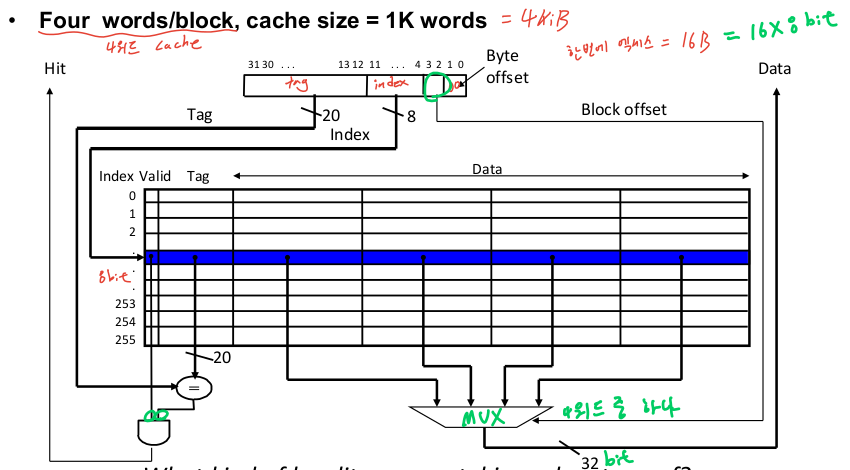
4-3. 캐시의 저장 관리
- 저장 관리를 하지 않으면 캐시와 메모리의 데이터가 모순될 수 있다
- 캐시와 메모리의 데이터가 CPU의 작성 시 일관되게 관리해야한다
4-3-1. Write Through
- 캐시에 쓸 때 메모리도 갱신한다
- 쓰기 속도가 느려진다
- write buffer를 통해 단점을 보완할 수 있다.
4-3-2. Write Back
- 캐시에만 쓰고, dirty bit으로 모순된 데이터를 표시한다
- dirty block이 다른 데이터로 대체될 때, 메모리에 쓴다
4-4. 캐시 성능
-
CPU time의 요소 : 프로그램 실행 사이클, 메모리 스톨 사이클
-
메모리 스톨 사이클 : (메모리 접근 횟수/프로그램) * 미스율 * 미스 페널티
ex) Inst-Cache miss rate = 2%, Data-Cache miss rate = 4%, CPI = 2
Miss penalty = 100 cycles, Load & Store 36% of instructions
Miss cycles per instruction : I-Cache = 0.02 * 100, D-Cache = 0.36 * 0.04 * 100
Actual CPI = 2 + 2 + 1.44 = 5.44 -
Average Memory Access Time = Hit time + Miss rate * Miss penalty
1ns clock, hit time = 1 cycle, mis penalty = 20 cycle, I-cache miss rate = 5%
1ns + 0.05 * 20ns = 2ns = 2 cycles per instruction
