목차
- Introduce
- Latency Time Performance (시간 기반 퍼포먼스 측정)
- Throughput Rate Performance (횟수 기반 퍼포먼스 측정)
- Ratio Performance (비율 기반 퍼포먼스 측정)
- Summarize Performance Results (퍼포먼스 결과를 요약하는 방법)
* Ratio 여러 숫자 혹은 집단과의 관계 비교
* Rate 특정 대상에게 발생한 횟수
Introduce
Importance of performance measurement
아키텍처 설계는 반복적인 작업
- 가능한 설계 영역 탐색
- 선택하기
- 선택한 항목을 평가
→ 선택을 적절히 평가하기 위해서는 좋은 측정 방법론 또는 도구가 필요!!
→ 비용과 퍼포먼스 분석을 통해 Mediocre ideas인지 Bad ideas인지 알 수 있다.
Little’s Law
리틀의 법칙(Little's law)은 정지 상태의 시스템에서 고객의 장기 평균 수 L은 고객이 시스템에 머무르는 평균 시간 W와 고객의 장기 평균 도착률 λ의 곱과 같다는 것을 나타내는 존 리틀의 정리이다.
안정 상태에서 두 개를 고정하면 세 번째가 결정됩니다.
L: 머물고 있는 시스템의 고객 수 → 중복 작업 수
λ: 시스템에 도착하는 비율 → 처리량
W: 시스템에서의 대기 시간(응답 시간) → 지연(또는 응답 시간)
T: 생각 시간(처리 사이의 간격 즉, 응답) → 일반적으로 0으로 가정
Performance Type
- Time (Latency) : 시작과 끝날 때 까지의 시간이 얼마나 걸리는지
- Execution TIme (Response time, latency)
- Interest to users (or client)
- Rate (Thorughput) : 얼마나 많은 과제를 정해진 시간 안에 완료하는지
- Ratiol: 퍼포먼스 간의 관계(~이 ~보다 몇 배 더 빠르다)
(Latency) Time Performance (시간 기반 퍼포먼스 측정)
Method 1. Wall-Clock, response time (latency), or elapsed time
: 일을 수행하는데 걸리는 실제 시간 (실제 세계)
부정확, 불예측성 → 외부 요인이 너무나도 많기 때문..
- CPU time for other programs as well as for itself
- Memory and disk access time
- Communication channel delay
- Operating system overhead …
⇒ 하지만 사용자경험(UX) 측면에서 매우 중요. 하지만 정확하지 않다. (외부 요인이 너무 많기 때문에)
Method 2. CPU Execution Time
- 프로그램이 실행되는 동안 걸리는 CPU 시간
- User CPU Time + System CPU Time
- User CPU Time: 프로그램에서 실행되는 CPU의 시간 (Computer Architecture에서 다룰 것)
- Sysytem CPU Time: Operating System(OS)에서 실행되는 CPU의 시간
Q. 어떤 것이 사용자 입장에서 더 중요할까?
: Wall-Clock
Q. 어떤 것이 시스템 디자이너에게 더 중요할까?
: CPU Execution Time
Measuring CPU Time: Clock
- 대부분의 전가기기에는 Clock Generator가 있다.
- 내부의 약속된 시간에 동작하며 그것이 Clock
-
Clock 신호는 Quartz Crystal 에 의해 생기며, 이것은 물리적 신호이다. 물리적 신호는 Analog to Digital Converter로 신호가 디지털로 바뀐다.
-
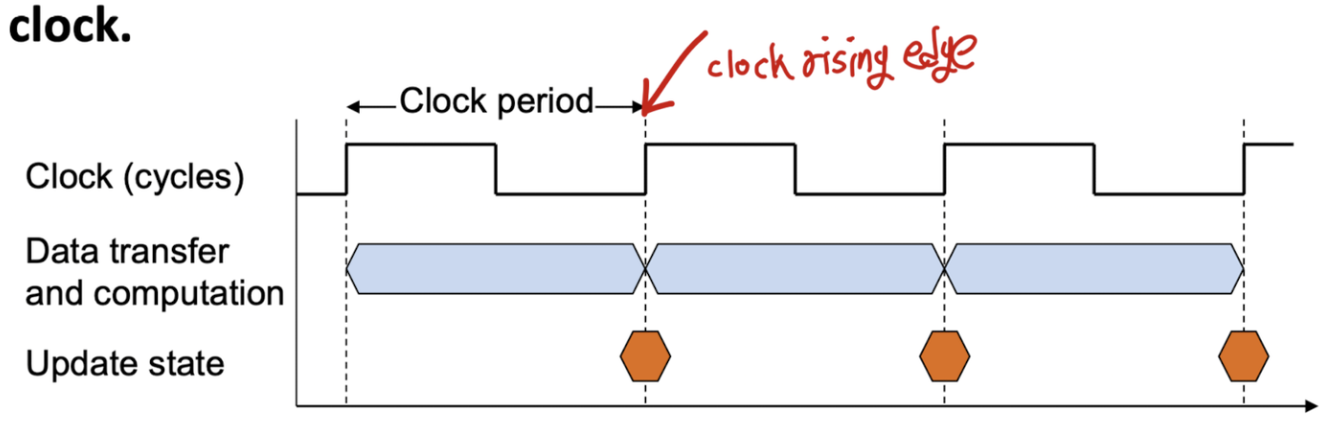
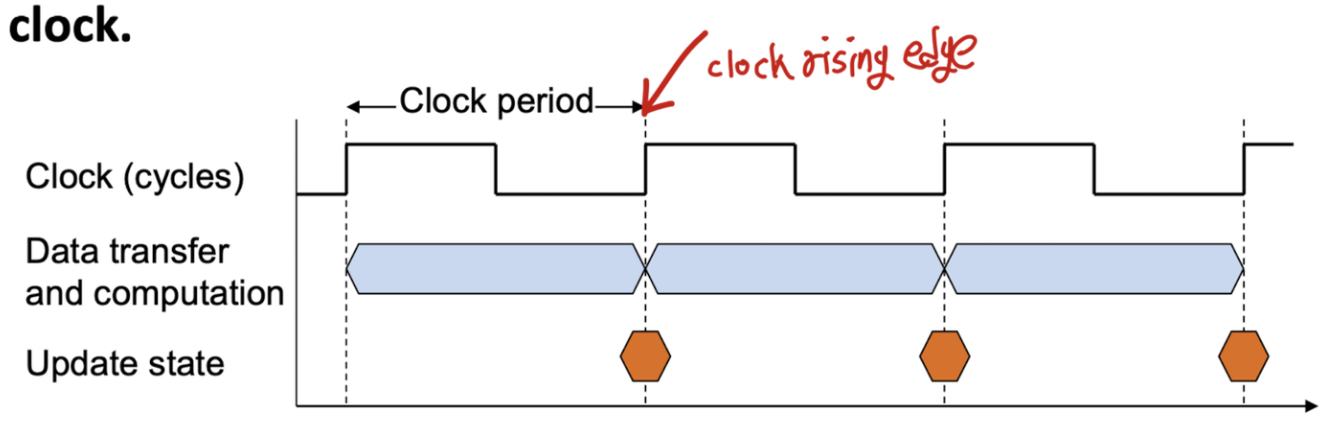
컴퓨터(전자기기)의 모든(또는 대부분) 작업은 일정한 속도로 실행되는 클럭(Clock)에 의해 제어된다.
- 클럭 신호(Clock Signals)는 물리적 레이아웃인 석영 결정에 의해 생성된다.
- 클럭 주기(Clock Cycles), 틱(Ticks), 클럭 틱(Clock Ticks), 주기(Cycle)…
-
컴퓨터의 작업은 내부 클럭과 동기화되어야 한다.
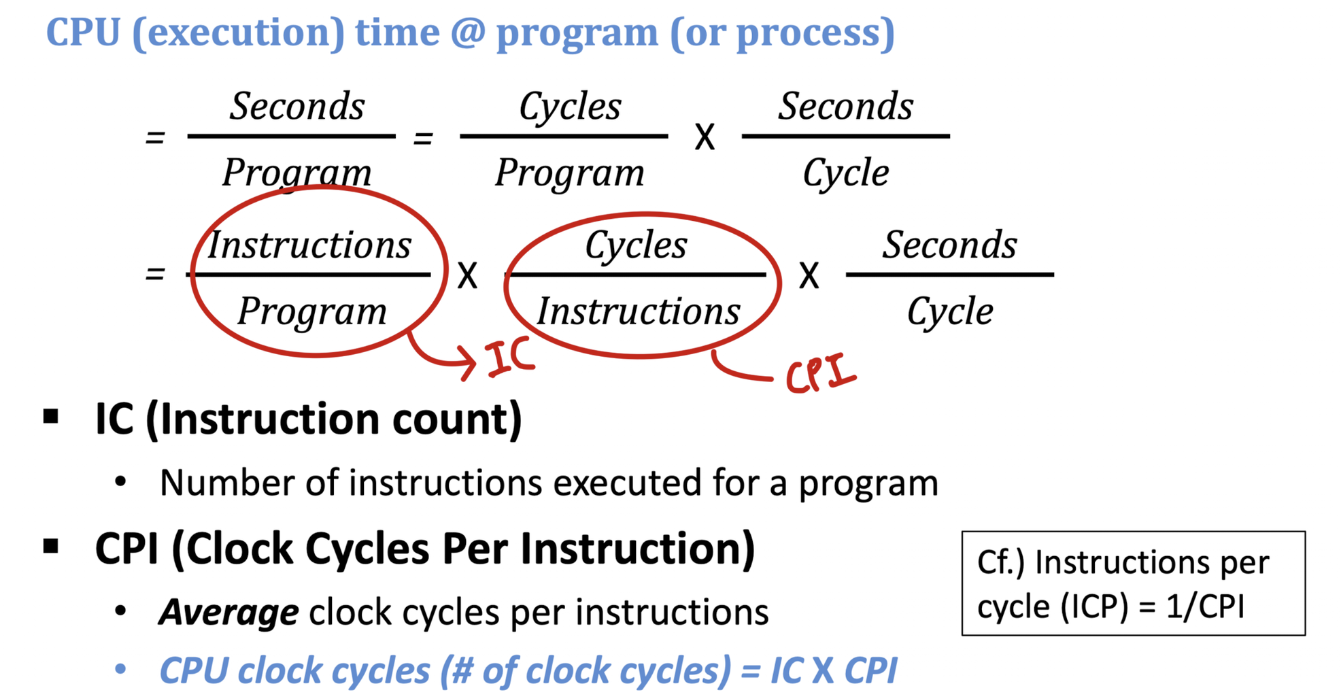
- Clock Period( = Clock Cycle Time): 한 클럭 사이클이 시작하고 끝나는데 걸리는 시간
- Clock Frequency( = Clock Rate): 초당 클럭 사이클의 수 (Hz)
- 4.0GHz = 4000MHz = 4.0 * 10^9Hz
- Clock Cycle Time = 1 / Clock Rate
Measuring CPU Time: Executing 1 Instruction
대부분의 프로세서의 명령어(Instructions)는 완료되기 위해 여러개의 클럭 사이클이 필요하다.
<명령어 한 개가 실행하는데 걸리는 시간을 구하는 방법>
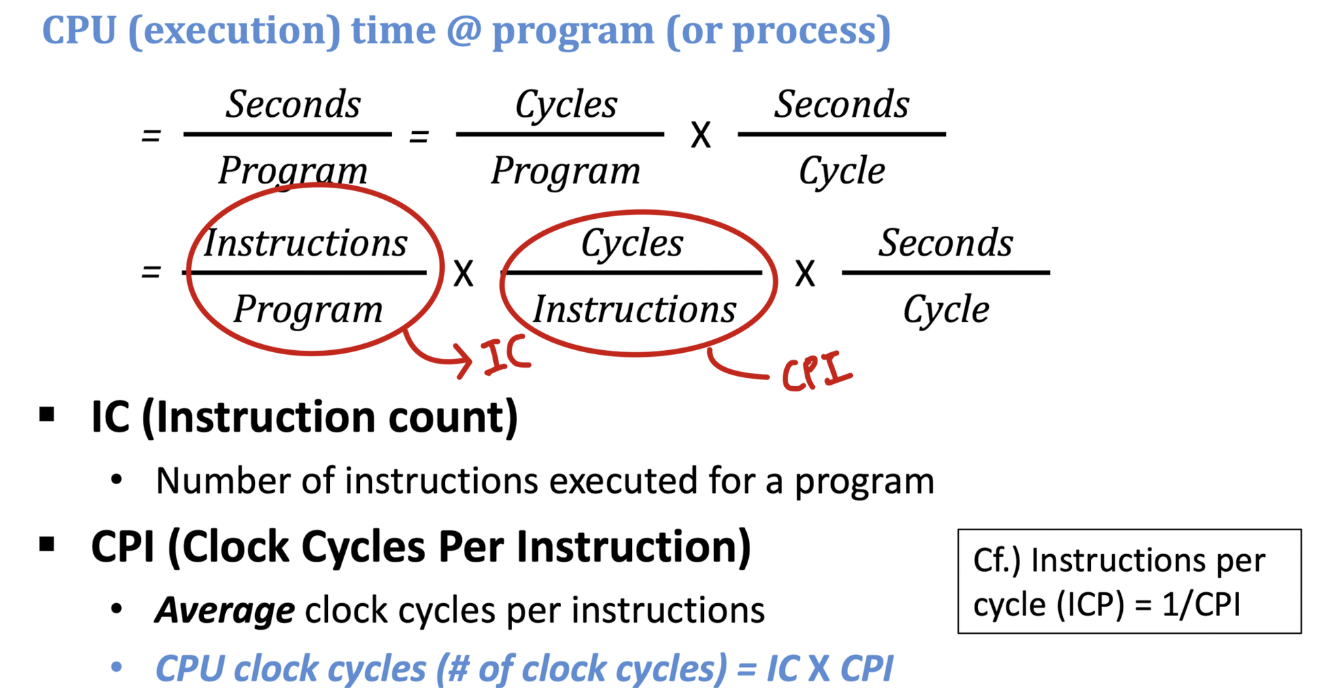
Average (or effective, overall) CPI
- 프로그램의 모든 명령어의 모든 사이클 수 / 모든 명령어의 갯수 = 한 명령어의 평균 사이클 수
3 Component(IC, CPI, Clock Cycle Time) 측정 방법
-
IC ( Instruction Count)
- (프로그램을 실행하여) 작은 프로그램의 루프에서 실행되는 명령어 수
- 시뮬레이터(또는 소프트웨어 도구)를 사용하여 명령을 카운트
- CPU 레지스터에 맞는 하드웨어 카운터 사용
-
Average CPI
- 계산 ① 프로그램 실행 시간 / 클럭 사이클 시간 = 총 클럭 사이클(프로그램의 경우) ② 총 클럭 사이클 / 명령어 수
- 계산 ① 프로그램 실행 시간 / 클럭 사이클 시간 = 총 클럭 사이클(프로그램의 경우) ② 총 클럭 사이클 / 명령어 수
-
Clock Cycle Time
- 컴퓨터의 사양으로 알 수 있다.
- 3.2 GHz CPU..
Factors involved in the CPU Time
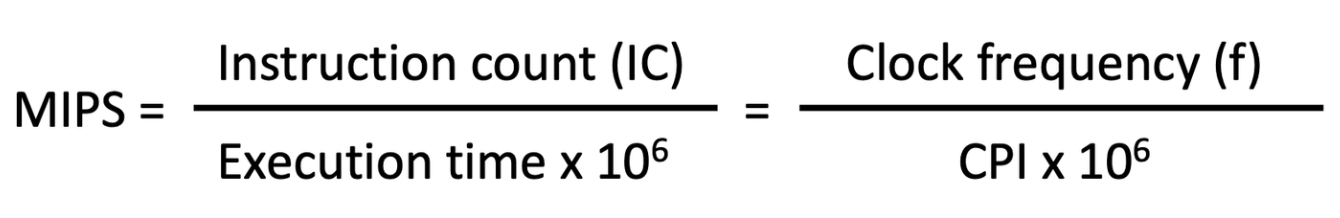
(Throughput) Rate Performance (횟수 기반 퍼포먼스 측정)
MIPS(Million Instructions Per Seconds)
- Execution time에 일반적으로는 반비례 (무조건 그렇진 않음)
- 이해하기 쉽다. MIPS가 크다는 것은 곧 더 많은 처리를 한다는 것
- 문제점
- 명령어의 기능을 고려하지 않습니다.
- 똑같은 작업을 수행하더라도 다르게 나타날 수 있음.
- 같은 컴퓨터라도 실행되는 프로그램마다 다르게 나타날 수 있다.
- Execution time과 반비례하지 않을 수 있다.
- 명령어의 기능을 고려하지 않습니다.
MFLOPS(million floating-point operations per second)
- 연구용 응용 프로그램과 게임에 사용된다.
- 정확하지 않음.
Ratio Performance (비율 기반 퍼포먼스 측정)
Benchmarks
벤치마크(benchmark)는 특정 유형의 애플리케이션에 대해 다른 칩/시스템 아키텍처를 비교하기 위해 설계된 "프로그램"입니다.
- "workload”의 컴포넌트나 시스템을 모방한 것
- Domain Specific!!
- 일반 컴퓨터는 정수계산에 빠르고, 연구용 컴퓨터는 Floating Point, 소수점 계산에 빠름. 즉 똑같은 컴퓨터라도 성능상 차이가 발생할 수 있음. 그렇기에 밴치막이 사용되는 영역의 특성이 잘 반영되었느냐가 중요. Integer Programs , Floating-point programs.. 종류가 나옴
- Updated every few year to reflect changes in usage and technology
- 빠르게 기술이 변화하기 때문에 빠른 업데이트가 되어야 함!!!
- 벤치마크는 고급 언어로 작성되며 시간을 쉽게 측정할 수 있도록 설계되었다.
- 벤치마크 속성
- 관련성: 대상 도메인 내에서 의미가 있음
- 수용성: 공급업체와 사용자들이 받아들임
- 범위: 대상 도메인의 중요한 요소를 단순화하지 않음
- 이해하기 쉽고 확장 가능
- 벤치마크의 두 가지 산업 표준
- SPEC: CPU 성능
- TPC: OLTP(온라인 트랜잭션 처리) 성능
- 이 외에도 3DMark, CrystalDiskMark, Cinebench, high-end Game(BattleGround).. 등등
SPEC (Standard Performance Evaluation Corporation)
- 설립: 1988년, 현대 컴퓨터 시스템의 성능평가를 위한 표준화된 벤치마크와 측정 항목을 설정, 유지, 지원하기 위해 설립됨
- 주요 벤치마크:
- SPEC2000 / SPEC2006 / SPEC2017 (정수 및 부동 소수점 연산에 대한 것으로, SEPCINIT2017, SPECFP2017 등 포함)
- 데스크탑 시스템 및 단일 프로세서 서버용 프로세서 벤치마킹에 유용함
- 서버용으로는 SEPCSFS 또는 SPECWeb 등이 있음
- 프로그램 및 입력값, 보고 규칙의 표준 목록 작성:
- 실제 프로그램을 기반으로하며 실제 시스템 효과를 포함함: 다중 산업 위원회에서 선택한 "현실적이고 일반적인" 공개 도메인 응용 프로그램의 집합
- 실행 및 보고 규칙을 지정함
- 어떻게 실행시켜야 하며, 어떤 규칙으로 어떤 상황에서 해야하는지.. 지정을 해뒀다는 것.
- 일정한 프로그램 집합에 대한 실행 시간 측정
- SPEC rating은 시스템이 기준 기계와 비교하여 얼마나 빠른지를 나타내며, SPEC rating이 600인 시스템은 SPEC rating이 400인 시스템보다 1.5배 빠름을 나타냄
TPC (Transaction Processing Performance Council)
- OLTP (Online Transaction Processing) benchmark
- 설립: 1988년 8월, Omri Serlin과 8개 업체에 의해 설립됨
- 주요 벤치마크:
- TPC-A: 최초 버전 (1985년)
- TPC-C: 복잡한 쿼리 환경을 시뮬레이션함 (1992년)
- TPC-H: 즉석 결정 지원 벤치마크; 쿼리들이 관련이 없으며 과거 쿼리의 지식을 사용하여 미래 쿼리를 최적화할 수 없음
- TPC-R: TPC-H와 유사하지만 쿼리의 미래에 대한 추가적인 최적화가 가능함
- TPC-W: 트랜잭션 웹 벤치마크
- 성능 측정: 초당 트랜잭션 수를 측정함 (Transaction per Second)
⇒ BenchMark는 정확하지 않다. 하지만 최소환 누구든지 성능을 평가할 수 있으며 속임수(cheat)가 불가능하다.
Summarize Performance Results (퍼포먼스 결과를 요약하는 방법)
Arithmetic mean (산술 평균)
- 측정된 값들의 평균을 계산하는 데 사용된다.
- Time-Ralated Performance에 사용된다. (Execution Time, 평균 실행 시간)
Harmonic mean (조화 평균)
- 순간적으로 변하는 값들의 평균을 구하는 데 사용된다. (평균의 평균이라고 생각하면 쉬움)
- Rate-Related Performance에 사용된다. (MIPS, MIPS 자체도 초당 몇 백만개의 명령어들이 실행되는지 나타내는 평균값이다)
- 평균 속도의 평균을 계산할 때 자주 사용된다.
- 갈 때 20km/h, 올 때 30km/h 일 때, 평균 속도는 25km/h가 아닌 1200/50 = 24km/h 이다.
Geometric mean (기하 평균)
- 비율로 표현된 데이터의 평균을 계산하는 데 사용된다.
- Ratio-Related Performance에 사용된다.
- CPU 속도를 처음에는 2배 개선되었고, 다음으로는 4배 개선되었을 때, 평균적으로는 3배 개선된 것이 아니라, 루트 8 배 개선된 것이다.
Amdahl’s Law (암달의 법칙)
여기서 P는 병렬화 가능한 부분의 비율이고, N은 병렬화된 프로세서의 수입니다. 이는 병렬화가 어떻게 전체 성능에 영향을 미치는지를 예측하는 데 사용됩니다.
Gustafson’s (or Gustafson-Barsis) Law (구스타프슨의 법칙)
여기서 P는 병렬화 가능한 부분의 비율이고, N은 병렬화된 프로세서의 수입니다. 이는 작업 부하를 늘릴 때 전체 작업 시간이 어떻게 변화하는지를 설명하는 데 사용됩니다.
