Multi-Cycle
Concept
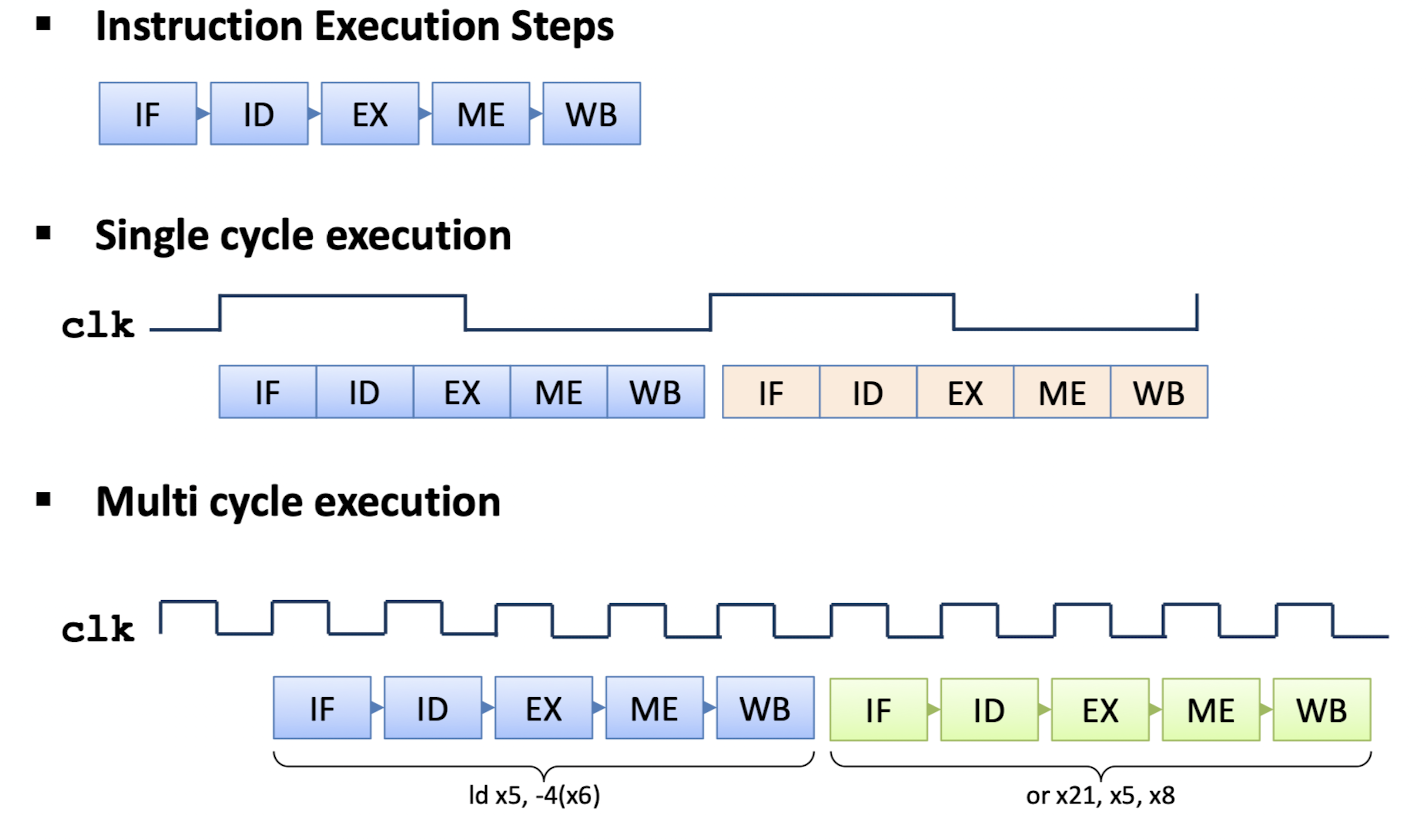
- Single Cycle의 경우 명령어 하나가 완전히 끝나면 다음 명령어가 실행된다. 즉 CPI는 1로 1 Instruction 당 1 Cycle을 가지고 있으며, 다음의 Clock Rising Edge가 나온 후 state가 변경된다.
- CPI는 1 이지만 Clock Cycle Time이 길다. (가장 긴 명령어를 기준으로 맞춰야 하기 때문에)
- Multi Cycle의 경우 1 Instruction 당 n Cycle을 가지고 있다.
- Clock Edge가 자주 일어나기 때문에 중간 중간에 데이터를 담아둘 temporary register가 필요
- Control Signal이 복잡
- 그러나 Pipeline을 구성하기에 용이
- CPI는 1이 아니지만, Clock Cycle Time이 짧다.
RISC-V Pipeline
- RISC-V Instruction은 일반적으로 five steps를 가진다.
- 각 step은 pipeline stage 또는 pipeline segment라고 불린다.
- Pipeline은 여러 intruction에 대한 여러 steps를 overlap 하여 실행시킨다.
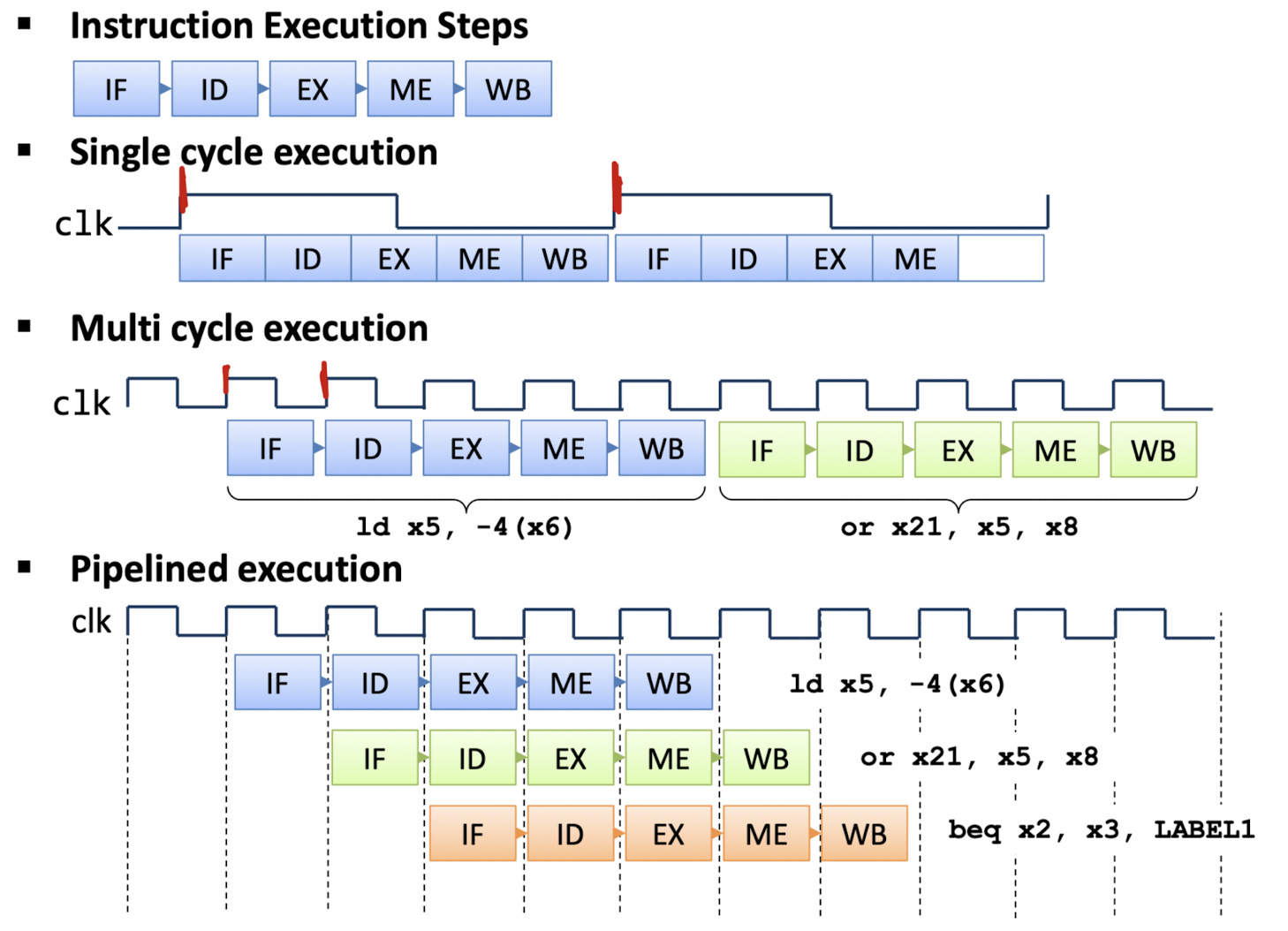
Pipeline Performance
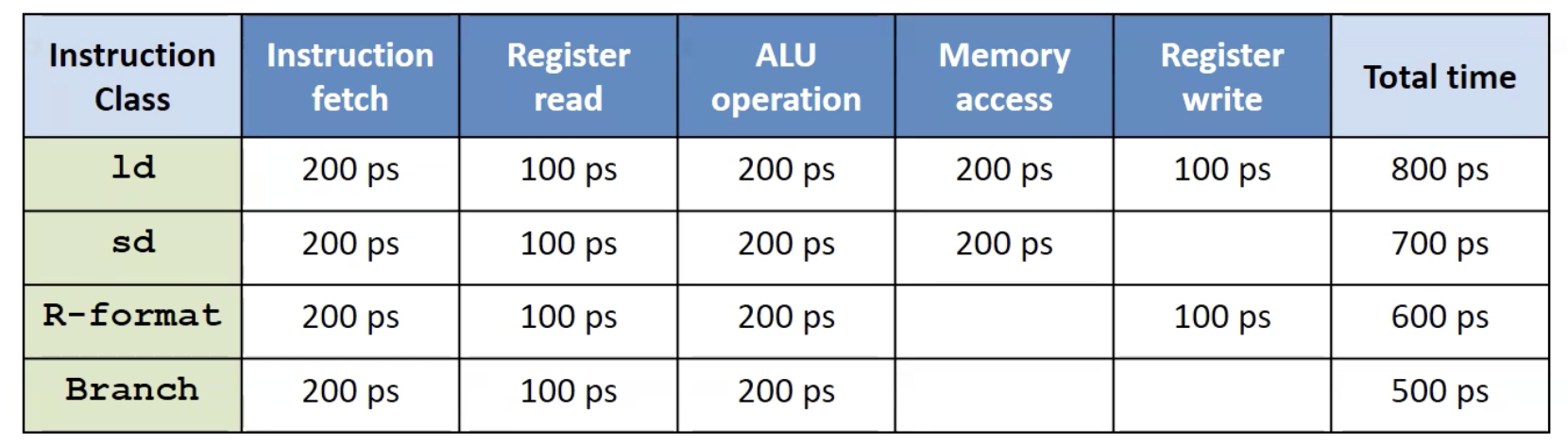
- 만약 single cycle일 경우, total time이 가장 긴 800 ps를 Clock Cycle Time으로 잡아야 한다.
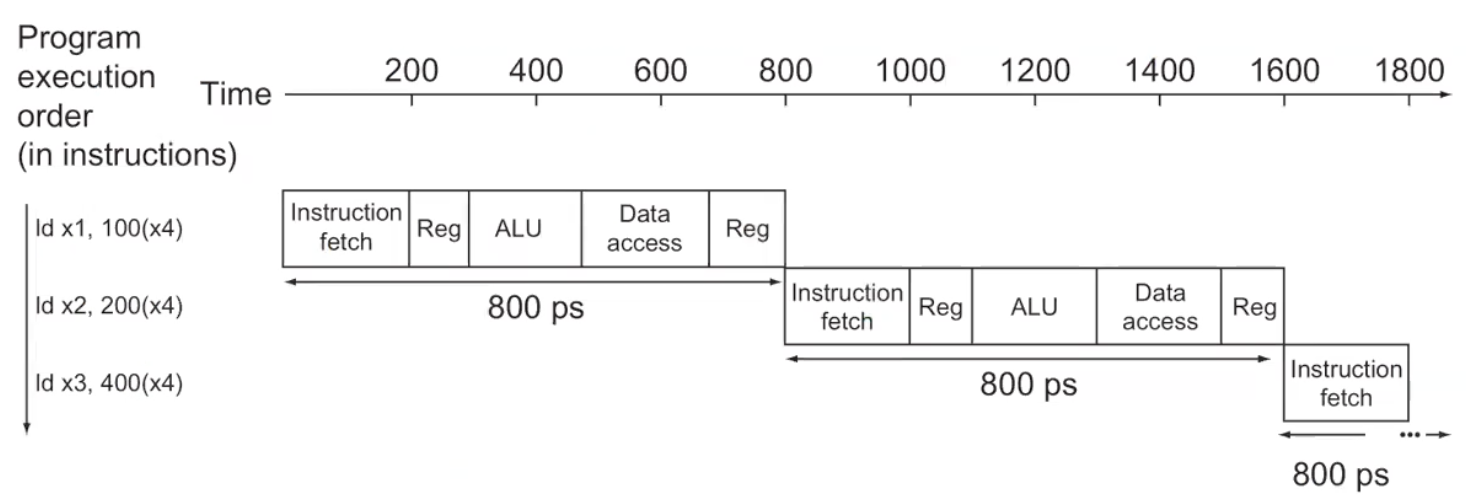
- 만약 multi cycle일 경우, 모든 step 중 가장 긴 step을 Clock Cycle Time으로 잡아야한다.
- pipeline 구조에서 한 step이 실행되는 동안 다른 step도 실행되기 때문이다.
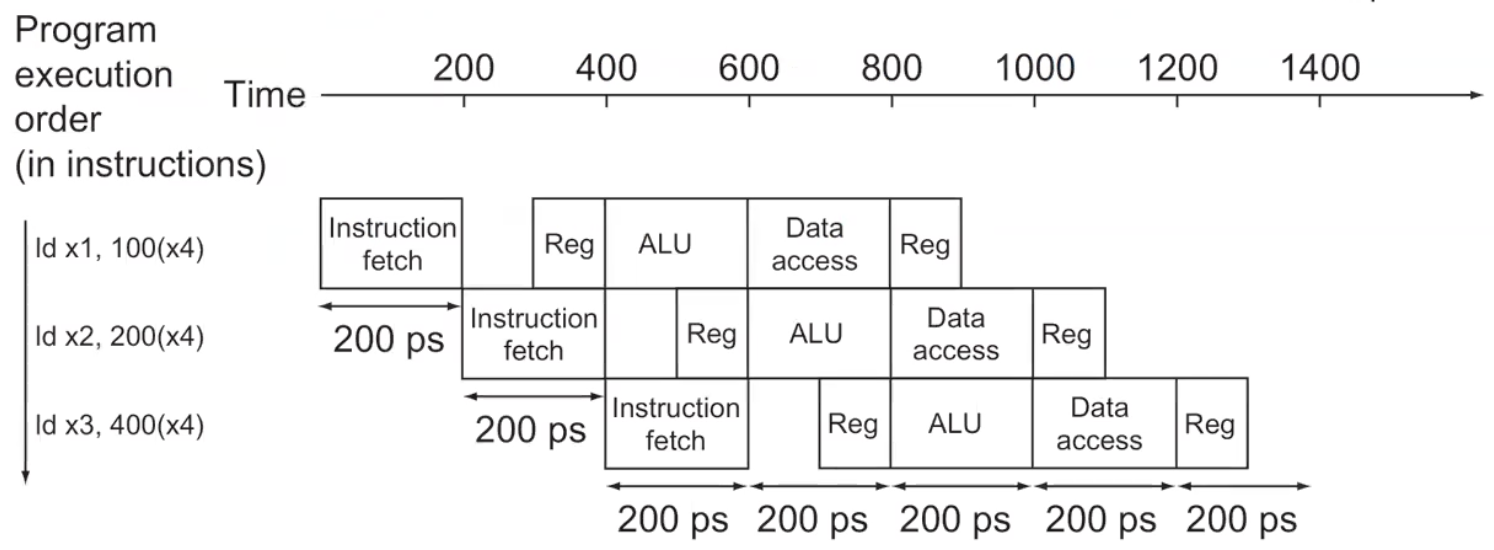
- pipeline 구조에서 한 step이 실행되는 동안 다른 step도 실행되기 때문이다.
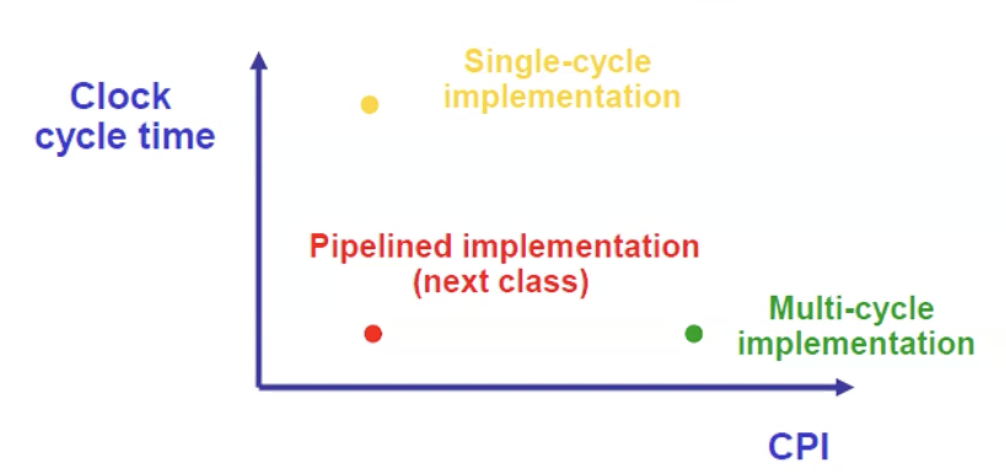
Pipeline Speedup
- 하나의 Instruction을 수행하는 시간이 줄어드는 것 X (오히려 늘어남)
- 특정 time interval 안에 수행되는 instruction의 갯수가 늘어나는 것
- Latency가 아닌 Throughput 관점에서 성능 개선
- Pipelining을 효과적으로 수행하기 위해서는 각 Execution unit의 수행 시간을 동일하게 해줌으로써 정확하게 하나의 cycle 안에서 overlapping 할 수 있다.
-> All stages are balanced.
Major Hudles of Pipelining
Hazard
- 다음 명령어를 다음 사이클에서 시작하지 못하게 하는 상황으로, 하나 이상의 stall(or wait) cycle이 발생할 수 있다.
- Hazard는 Pipelining으로 얻을 수 있는 이상적인 Speedup(increase CPI > 1)을 감소시킨다.
Hazard의 3가지 유형
1. Structual Hazard
2. Data Hazard
3. Control Hazard
Structual Hazard
하드웨어 자원 충돌로 인해 발생 (필요한 자원이 사용 중인 경우)
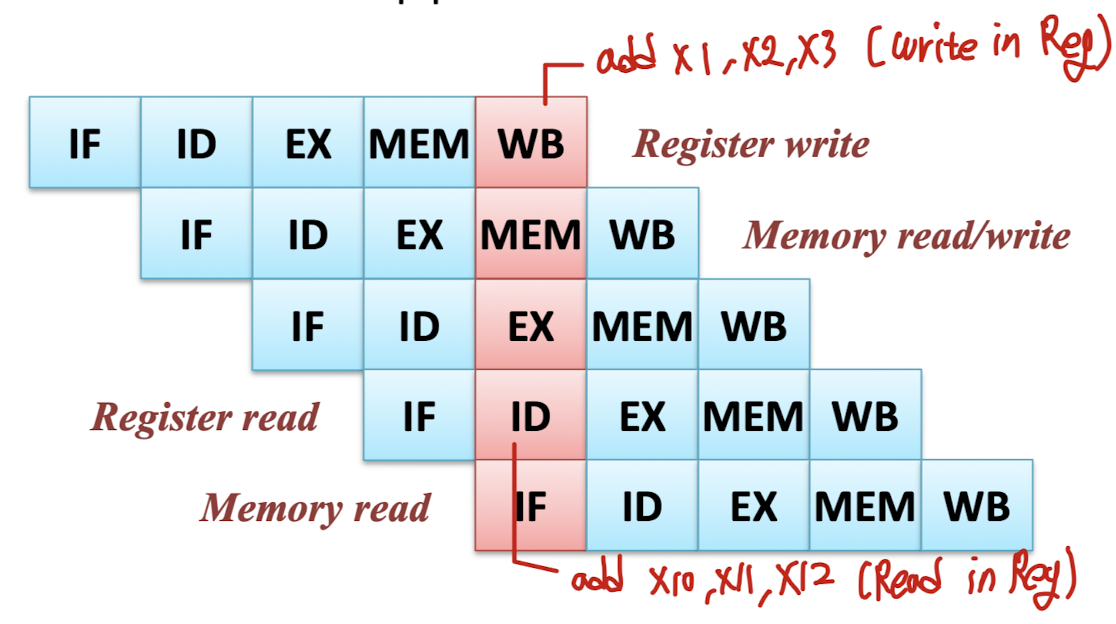
- Register 읽기와 쓰기 작업이 동시에 실행될 때 충돌이 일어남.
- Memory 읽기와 쓰기 작업이 동시에 실행될 때 충돌이 일어남.
Solution 1)
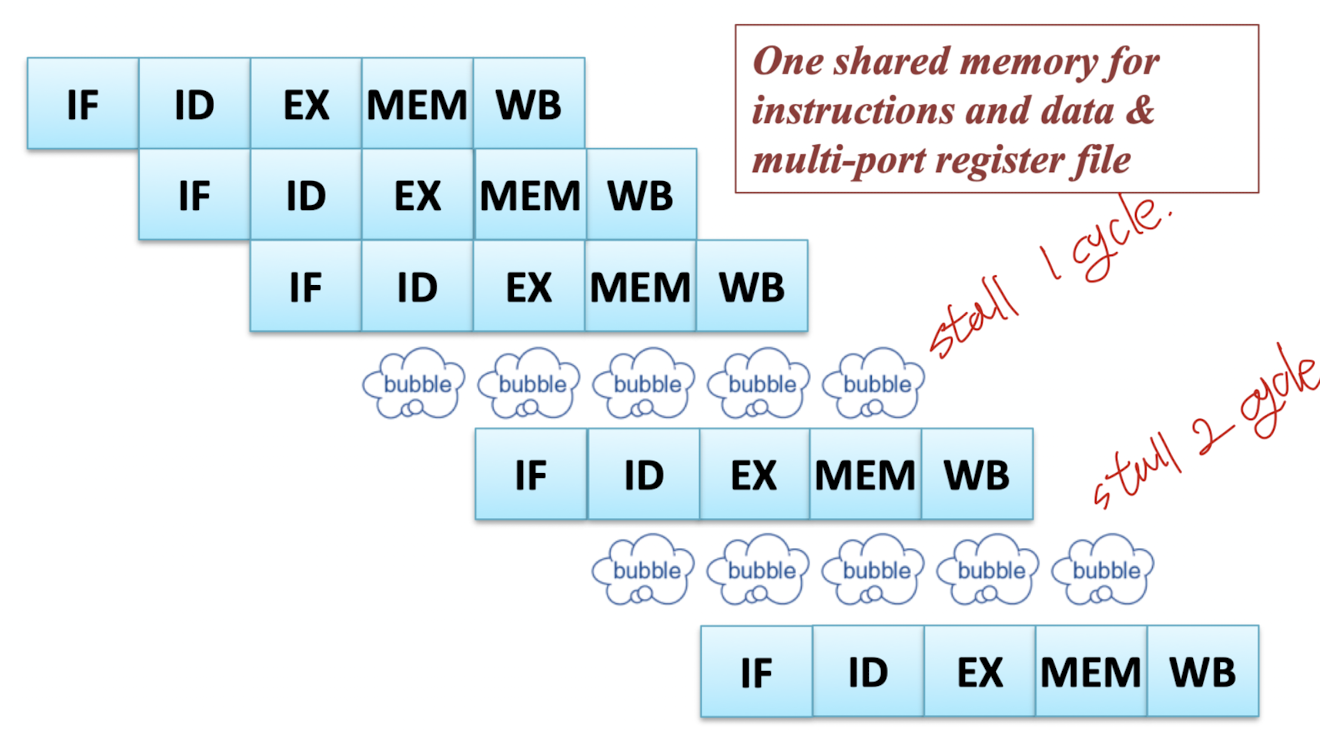
- 다음과 같이 충돌이 일나지 않도록 빈 공간을 둘 수 있음 (이걸 stall이라고 부른다)
Solution2) Resource duplication
- Seperate Instruction memory and Data memory
- Time-multiplexed (multi-port register file → read register / write register)
Data Hazard
명령어가 이전 명령어의 결과에 의존할 때 발생
- 위 사진 처럼 앞의 연산의 결과가 뒤에서 연산할 때 사용할 경우 문제가 발생한다.
- 다음 문제를 해결하는 방법은 3가지가 있다.
Solution 1) Freezing the pipeline
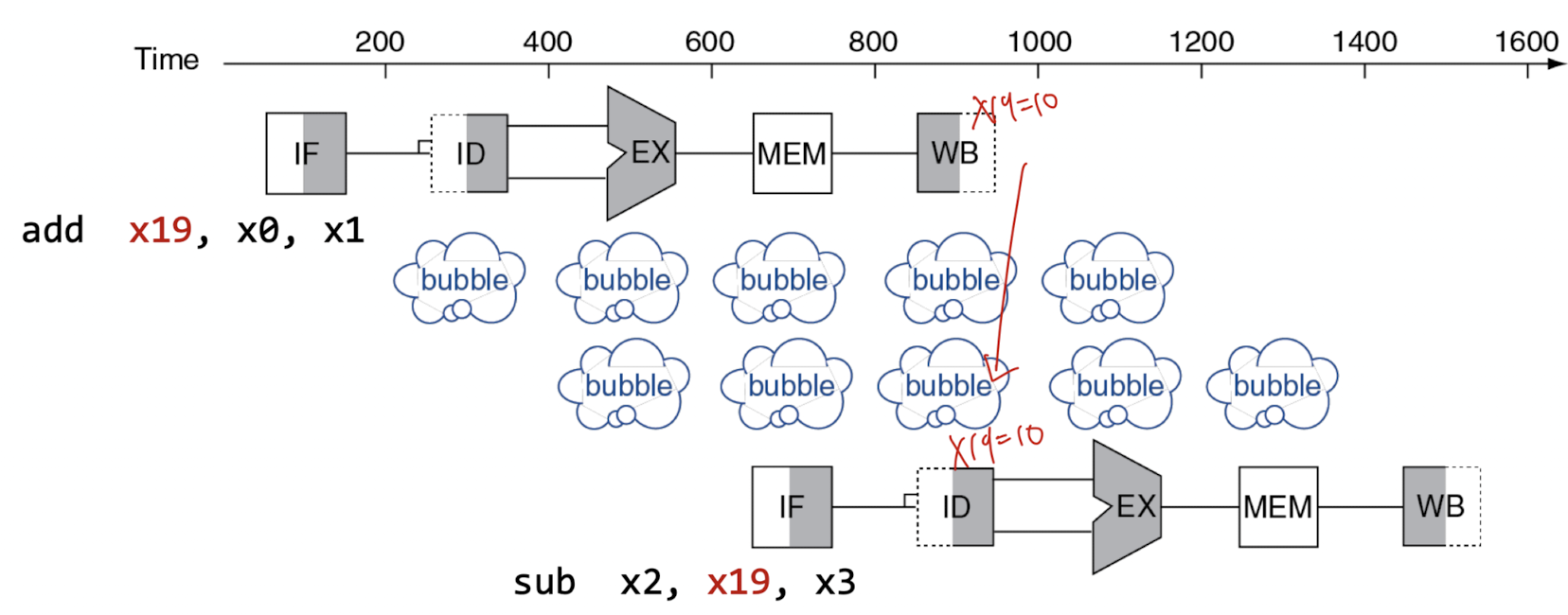
- 위 사진처럼 stall을 만들어 일시적으로 Pipeline을 freezing한다. 하지만 Stall이 생겼다는 것은 성능이 많이 줄어든다는 것을 것을 명심하자.
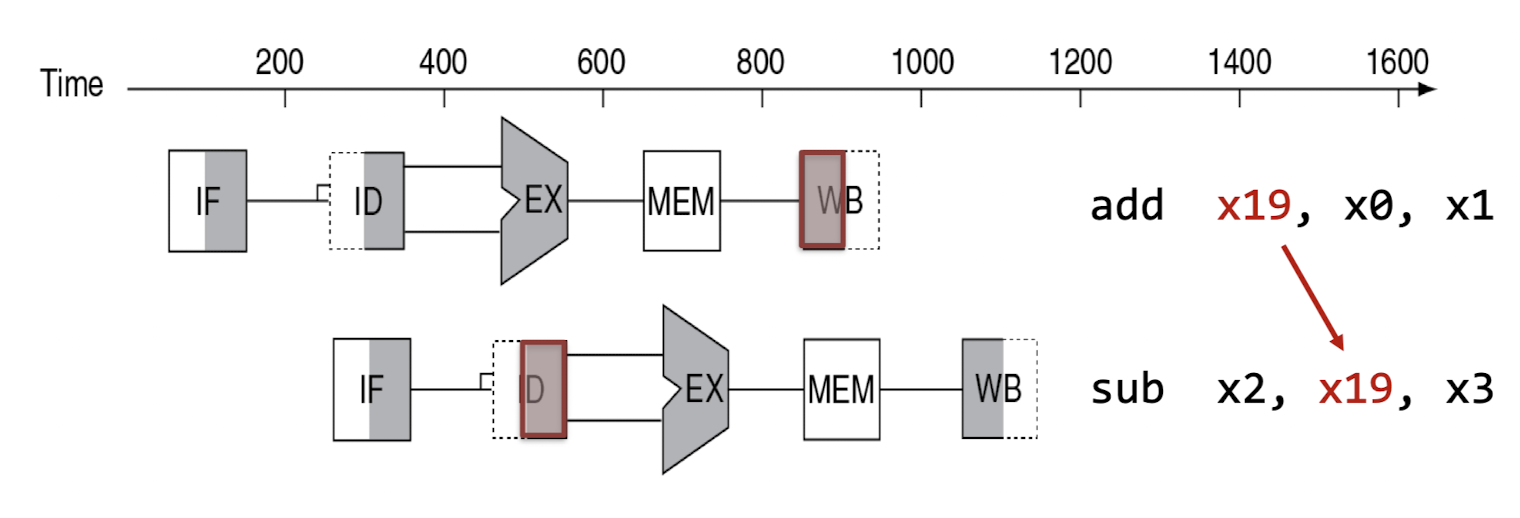
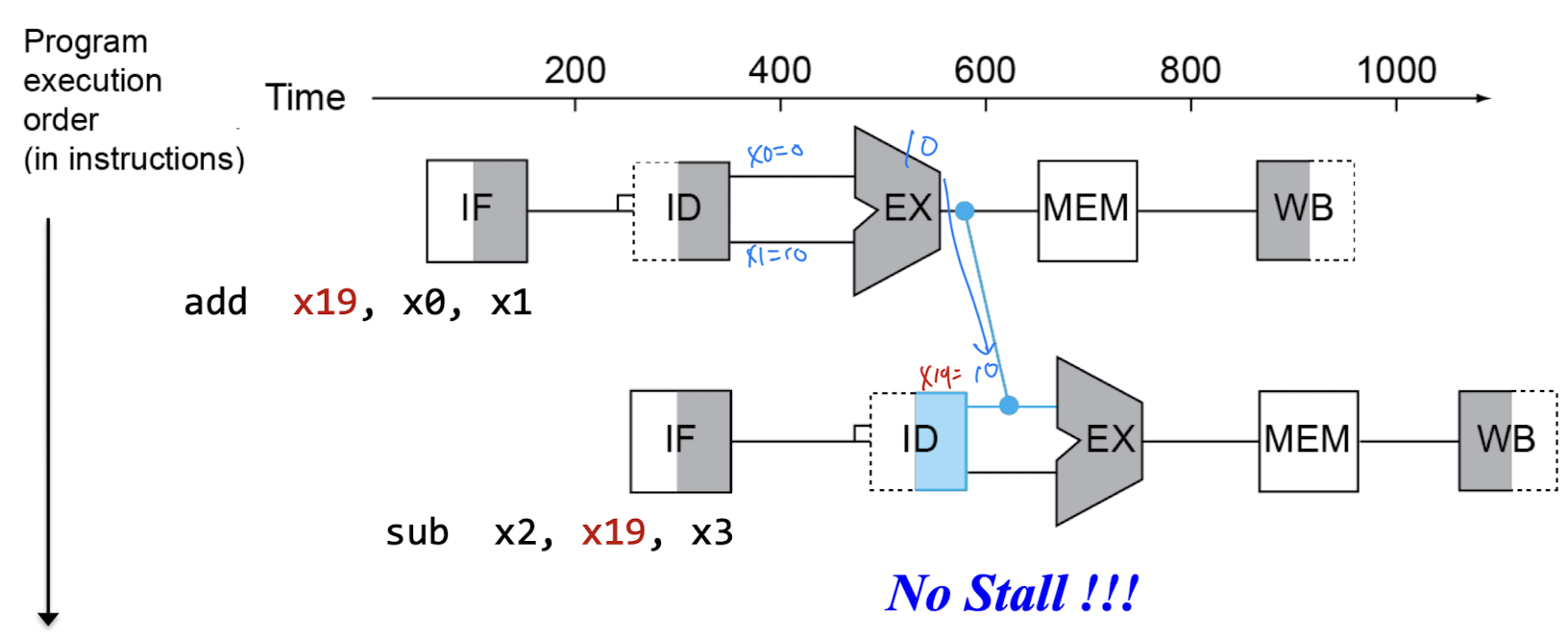
Solution 2) (Internal) Forwarding (or Bypassing)
- 위 사진처럼 저장할 때까지 기다리는 것이 아닌 하드웨어 기술적으로 연결하여 값을 전달하는 방식
- 위 방식을 사용하면 stall이 없어짐. 그러나 모든 instruction에 대해서는 적용 불가능
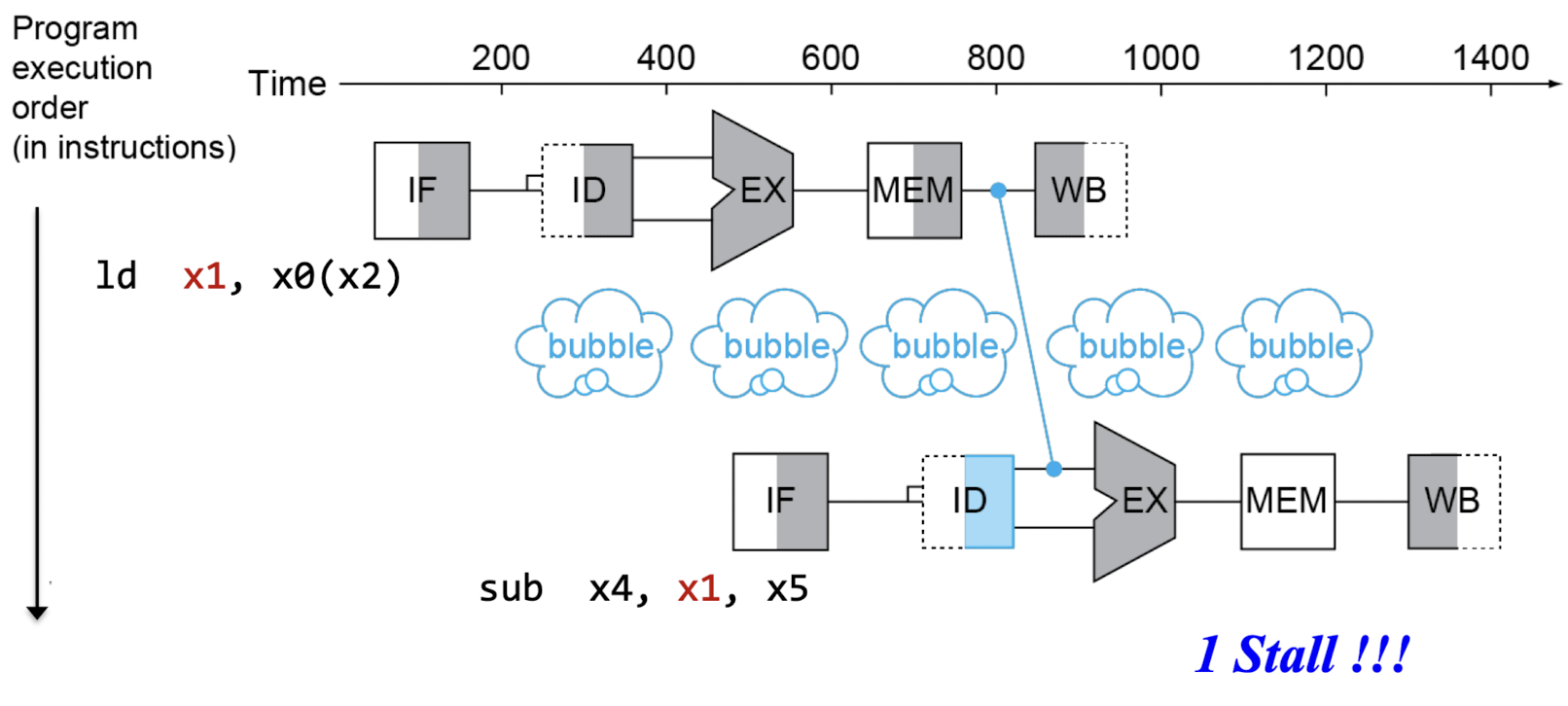
- 다음처럼 레지스터가 아닌 메모리 접근의 경우(Load/Write) 1 Stall이 발생
- ALU 연산만 할 경우 사용가능하나, Load/Write Instruction을 사용할 경우 무조건 Stall이 발생한다!
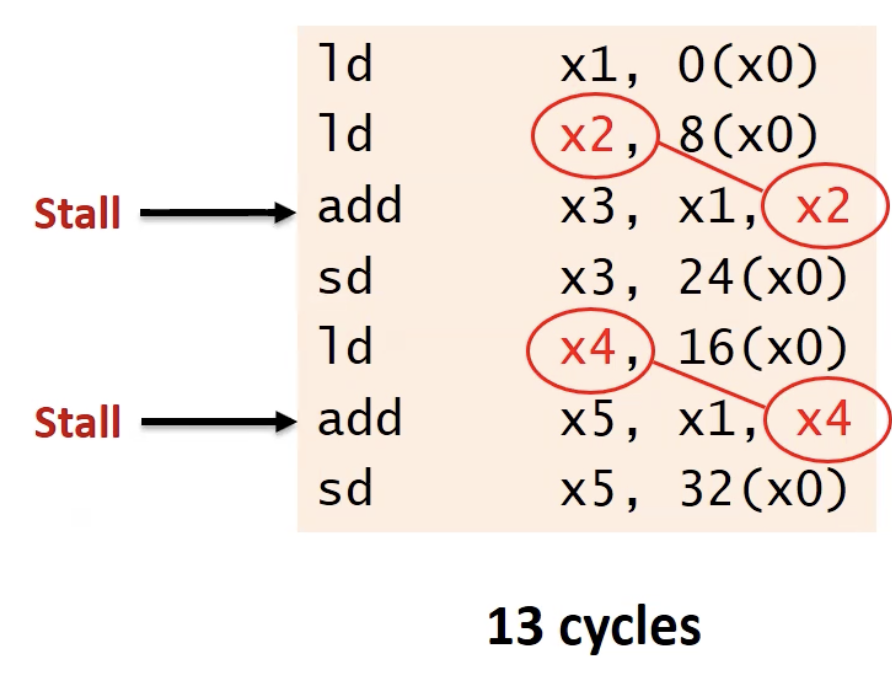
Solution 3) Compiler Scheduling
- 위 사진에서 Forwarding만 적용한다고 했을 때, Stall이 2번 발생하고 총 13cycle이다.
- 4(처음 시작 시 4step) + 7(Instruction 수) + 2(Stall 수) = 13
- 다음처럼 ld를 위로 올리며, ld 해서 가져온 레지스터와 ALU 연산 명령어 간격을 한 칸 이상 둠으로써 Stall을 없앰 - > Compiler Scheduling 방식!!
Data Hazard가 주로 발생하는 경우
- RAW (read after write) : in-order pipelining에서 발생하는 문제
- WAW (write after write) : 순서대로 pipelining을 하는 in-order pipelining에서는 발생하지 않는다.
- WAR (write after read) : 순서대로 pipelining을 하는 in-order pipelining에서는 발생하지 않는다.
- RAR (read after read) : no hazard

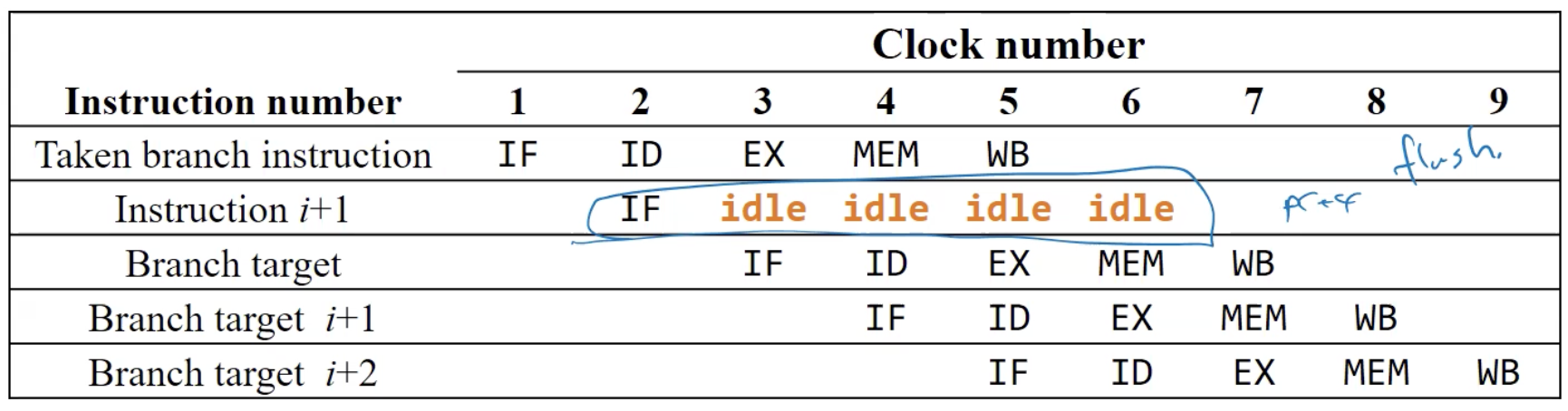
Control Hazard
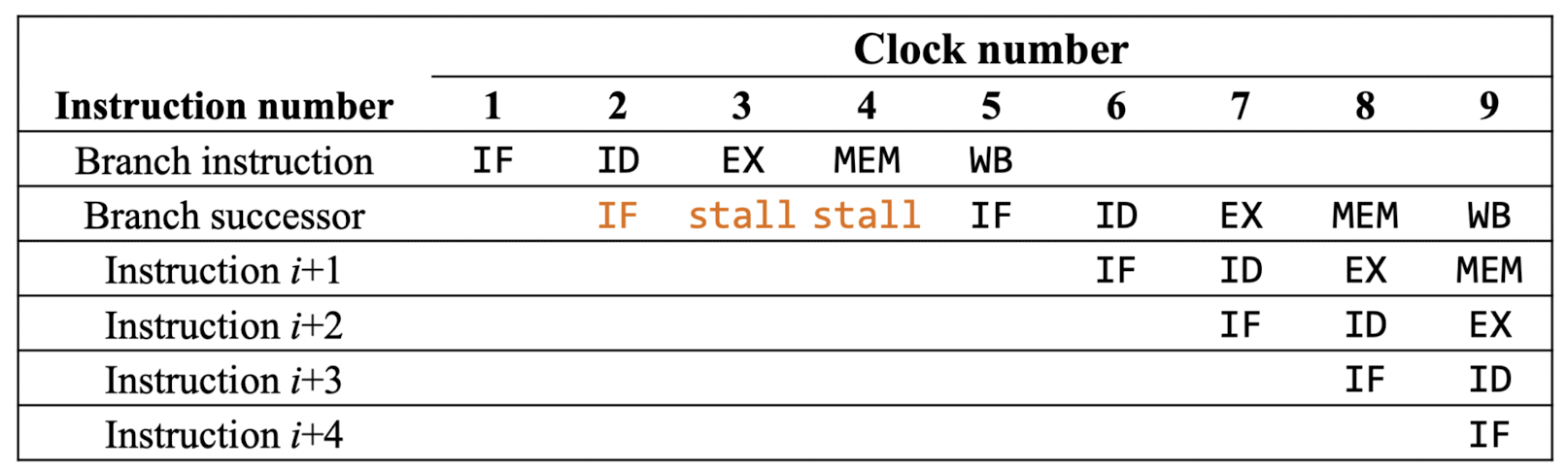
Conditional Branches와 기타 명령어의 Pipeline으로 인해 발생합니다.
ex) Branch 명령어 사용 시 발생 (다음으로 어떤 Instruction을 실행해야하지?)
- 3 Stall이 발생 (time-multiplexed register file 사용 시)
- 4 Stall 발생 (time-multiplexed register file 사용 안할 시, WB와 IF가 동시에 실행될 수 없음)
- 다음을 고려해서 생각해야할지 조건을 읽고 판단
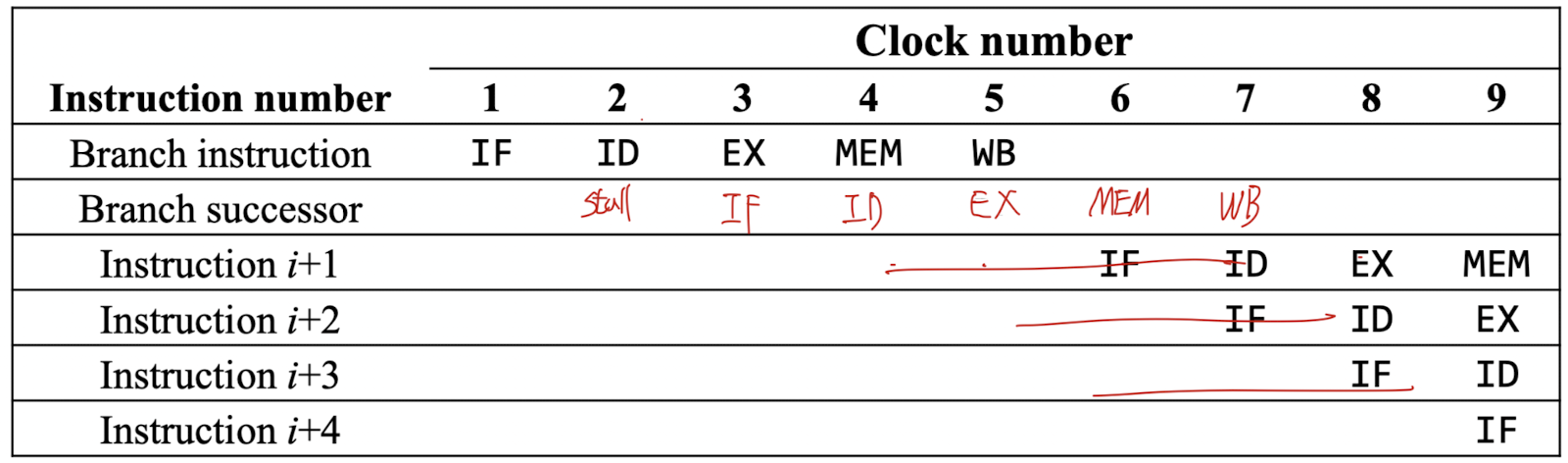
Soltuion 1) Optimized Branch Processing
- Branch가 taken인지 untaken인지, Target memory address는 어디인지 빠르게 알아내는 것이 목표
- ALU의 Zero Flag를 이용해 taken 여부를 확인한다.
-> 1 Stall을 줄일 수 있다.- Extra H/W를 통해 ID(Instruction Decode in Register) 단계에서 계산한다.
-> 2 Stall을 줄일 수 있다.
Branch Frequency를 20%로 가정하자.
- 만약 Stall이 4번 발생할 경우 (일반적인 경우)
- 만약 Stall이 3번 발생할 경우 (time-multiflexed register file 사용)
- 만약 Stall이 2번 발생할 경우 (the result of EXE is forward (to IF stage))
- 만약 Stall이 1번 발생할 경우 (use Extra H/W, ID에서 연산)
Soltuion 2) Branch Prediction
- Branch가 항상 untaken이라고 가정하고 진행
- 만약에 틀렸을 경우 1 stall을 넣어서 실행
- untaken으로 가정 -> 가정이 들어맞음
- untaken으로 가정 -> 가정이 틀림
- flush 후 1 Stall 발생 (Extra H/W가 있다고 가정)
- 만약 Extra H/W가 없고 EXE to IF일 때는 2 Stall 발생
Performance of Pipelines with Stalls
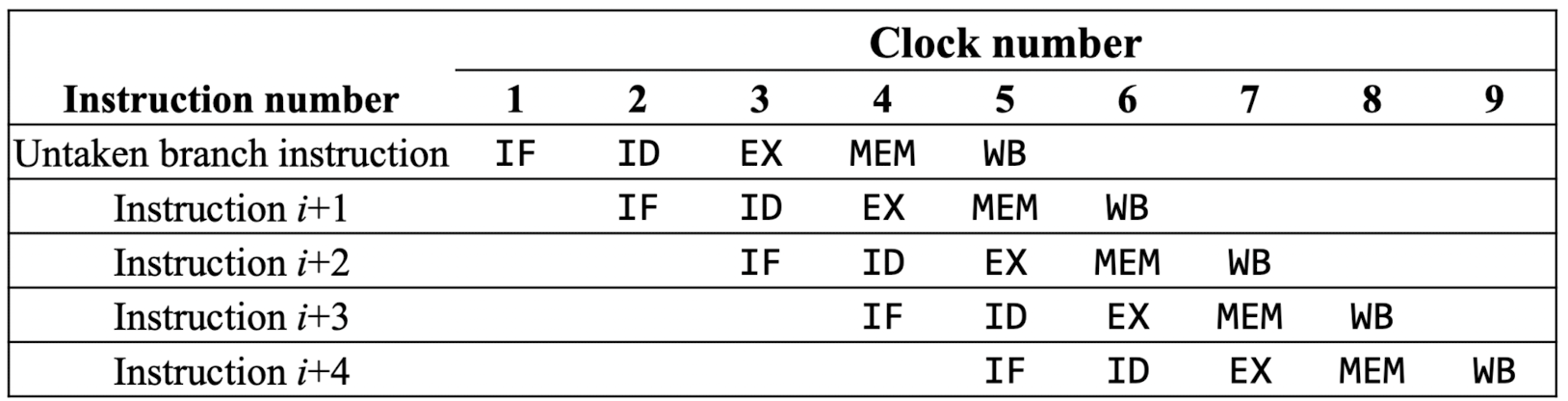
- Pipeline을 했을 때, 이상적인 CPI는 1이다. 처음 4번 마지막 4번을 제외하고는 한 cycle 마다 하나의 instruction이 실행되기 때문이다.

- Speedup을 계산해본다면, 위 처럼 계산하면 된다.


Today is flutter