An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ICLR 2021)
Paper Review
목록 보기
32/51

INTRODUCTION
- Transformer base의 pretrained model인 BERT는 dominant in NLP
- Image에선, CNN이 여전히 dominant
- Transformer architecture를 vision에 적용시키기 위해, 우리는 Image를 patch로 쪼갠 뒤 linear layer를 통과시켜 NLP의 token과 같은 embedding을 얻음
- Large scale data에서 ViT가 SOTA임을 확인
RELATED WORK
- NLP는 transformer architecture를 기반으로 한 BERT, GPT가 dominant
- Vision에서는 모든 pixel 기반 attention, locally attention, Sparse transformer 등
- 높은 Cost, require complex engineering 등 한계가 여전히 존재
- 우리는 2x2 ViT 모델과 굉장히 유사하나, 더 큰 스케일, medium-resolution 등으로 확장
METHOD
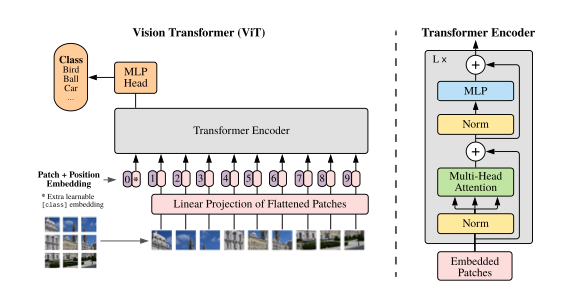
VISION TRANSFORMER (ViT)
- Standard transformer는 1D sequence of token embedding을 input으로 받음
- 우리는 을 으로 전환하여 input으로 사용
- 는 input channel이며, 는 image patch의 resolution
- 로 patch의 개수이며, transformer input dimension인 D차원으로 linear projection 시켜줌
- BERT의 cls token과 같이 을 생성하고, 이는 encoder를 통과해 image representation으로 사용됨
- 우리는 2D-aware positional embedding이 효과를 보지 못해, 1D position embedding을 사용
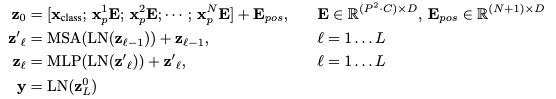
- Encoder는 MSA(multi-head self attention), MLP, LN block으로 구성
Inductive bias
- CNN이 image에 specific하게 inductive bias를 포함하지만, ViT는 MLP layer만 local이며 다른 것은 global하게 판단함
- 2D-neighborhood structure는 매우 적게 사용됨
Hybrid Architecture
- 다른 방법으로, raw image patch의 feature map을 CNN으로 추출할 수 있음
- 이를 통한 hybrid architecture를 구성 가능
FINE-TUNING AND HIGHER RESOLUTION
- 우리는 Large Dataset에 ViT를 pretraining하고, prediction layer를 zero-initialize함으로써 downstream task에 fine-tuning
- higher resolution에서, 우리는 patch size를 그대로 유지한 뒤 sequence length를 증가시킴
- ViT는 임의의 sequence length를 조작할 수 있으나, 이 경우에 positional embedding은 의미가 없어짐
- pre-trained position embedding의 2D interpolation을 통해 이를 해결
EXPERIMENTS
- ResNet, ViT, Hybrid를 비교
SETUP
Datasets
- 방대한 데이터 셋 ..
Model Variants
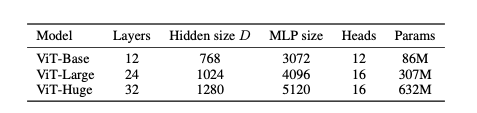
- BERT 세팅을 가져옴
- Huge setting은 독자적인 구조
Training & Fine-tuning
- Apendix에 상세히 설명
Metrics
- few-shot, fine-tuning accuracy를 비교
COMPARISON TO STATE OF THE ART
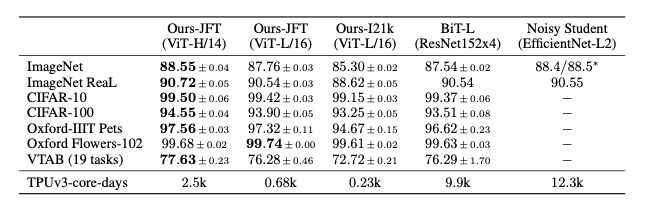
- Ours가 SOTA 달성
PRE-TRAINING DATA REQUIREMENTS
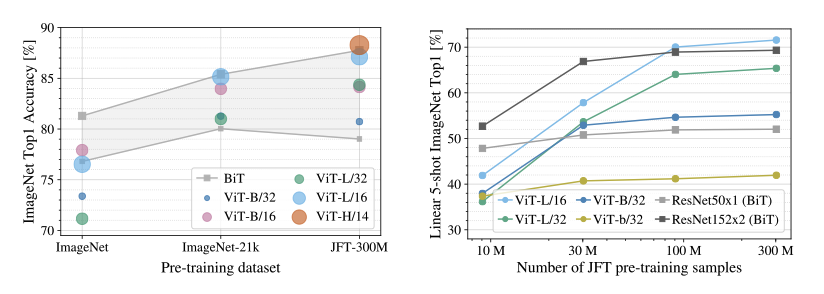
- ViT는 Large JFT-300M dataset으로 pretrain시, 잘 작동함
- Fewer inductive biases than Resnet일 때, Data scale이 얼마나 중요한지 실험 진행
- Dataset이 작을 땐, ViT-Base model이 가장 좋은 성능을 보여주나, 데이터 셋이 증가함에 따라 larger model이 full benefit을 얻음
SCAILING STUDY
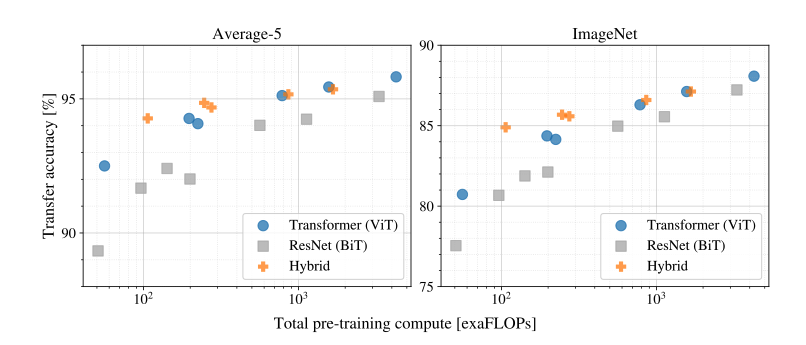
- ViT가 computational cost, performance trade-off에서 resnet을 dominate
- hybrid가 small computational budget에선 ViT를 근소하게 앞지르지만, larger model에서는 이 차이가 사라짐
INSPECTING VISION TRANSFORMER
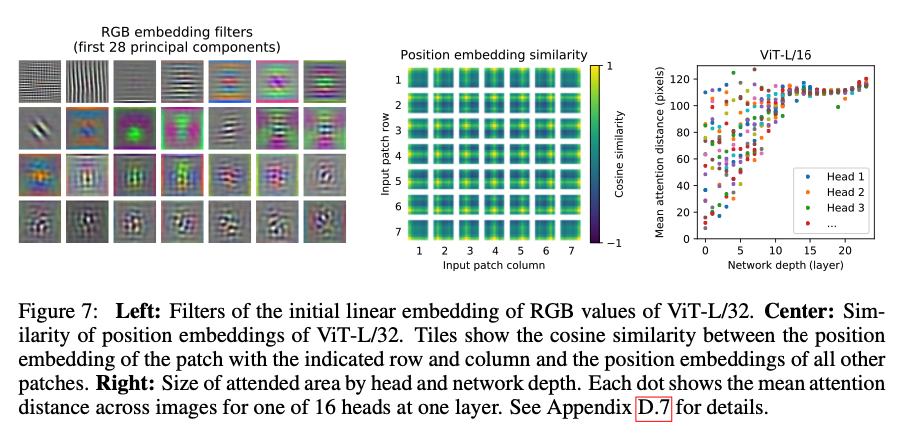
- Initial linear embedding은 basis feature를 학습
- positin embedding은 동일한 row, column 끼리 유사하게 학습 됨
- 2D positional embedding을 자동으로 학습
- mean attention distance는 CNN에서 receptive에 해당
- 몇몇 head는 Lowest layer부터 높은 attention distance를 갖지만, 몇몇은 그렇지 못함
- layer depth가 커질수록, 모든 head가 높은 attention distance를 가짐

- 최종적으로 classfication에 relevant한 region만 포착할 수 있게됨
SELF-SUPERVISION
- NLP에서 Transformer의 성공은 scalability와 self-supervised pre-training에 기반을 둠
- masked patch를 predicting하는 pretraining은 꽤나 높은 성능을 보여주지만, supervised 보다는 낮은 성능
- 추후 constrastive하게 학습할 예정
CONCLUSION
- Image Recognition에서 Transformer의 direct application
- self-attention을 사용하는 컴퓨터 비전의 이전 연구와 달리 image-specific inductive bias를 이용하지 않음
- 대신 image를 sequence of patch로 구성하여 Encoder를 통과시킴
- SOTA를 달성
- detection, segmentation, self-supervised 등 다양한 future work가 존재
