ChartReader: A Unified Framework for Chart Derendering and Comprehension without Heuristic Rules (2023)
Paper Review
목록 보기
31/51

Introduction

- Chart-to-Table task는 chart를 machine이 이해할 수 있는 table로 변환하는 task
- ChartQA와 Chart-to-Text는 question과 chart summarizing이 필요
- 최근 연구에서, chart comprehension은 상대적으로 저 평가 되어 있음
- 현존하는 chart comprehension methods는 2가지 한계
- domain knowledge에 의존하는 heuristic rule로 formulate가 어려움
- ChartOCR이 정확히 그 예시
- 특정 Chart에만 적용할 수 있는 모델이 있지만, unkown categorie에는 대응 어려움
- 따라서 MatCha와 같이 table을 거치지 않고 바로 answer에 돌입하는 model이 최근 연구됨
- OCR 혹은 pre-extracted table에 크게 의존함
- Chart Derendering을 black box로 사용시, chart의 visual, structural information을 담아낼 수 없음
- 따라서 suboptimal result
- 또한 OCR을 사용하면 Chart-to-Table이 chart comprehension에 정확히 도달할 수 없음
- domain knowledge에 의존하는 heuristic rule로 formulate가 어려움
- 이러한 문제를 해결하기 위해 visually-situated language model인 pix2struct 등장
- OCR을 surpass했지만, chart derendering에는 적합하지 않음
- MatCha는 이러한 문제를 해결하기 위해 등장했지만, Pix2Struct가 base이기에 better visual-language model이 필요함
- 그럼에도 불구하고 두 시도는 heuristic rule과 OCR에서 벗어난 모델임
- 우리의 ChartReader는 chart derendering과 comprehension을 가능케 한 모델
- Rule-free chart component detection
- extended pre-trained vision-language model for Chart-to-X task
- 두 task를 결합!
- Summary
- Chart Derendering과 comprehension을 동시에 달성한 우리 모델
- chart의 rule을 automatic하게 학습한 transformer를 base로 rule-free component detection module 개발
- pre-trained LLM embedding을 확장하고 cross-task learning에 적합한 변수 교체 technique을 제안
- 우리의 모델의 강점을 실험을 통해 검증
Related Works
Chart Derendering
- Chart-to-Table
- 이전 연구
- Hand-designed Rules (DNN X)
- object detection, text recognition 기반 (ChartOCR 등)
- pre-trained LLMs을 plot-to-table task에 활용 (DePlot)
- chart의 구조와 component는 활용하지 않음
- Flagship method는 사실상 ChartOCR인데 human rule에 너무 의존!
- 우리는 heuristic rule을 eliminate
Chart Question-Answering
- Chart와 관련된 질문을 답변
- 이전 연구
- dynamic encoding을 통한 relation network 기반
- visual, text information을 capture할 수 있는 transformer 기반
- pre-trained LLM을 사용 (MatCha, ChartQA)
- Chart Characteristic을 무시하고 ground-truth table에 의존
- 우리는 chart summarization과 derendering task를 sequence-to-sequence를 통해 LLM에게 보내줄 것
Chart Summarization
- encoder-decoder architecture를 통해 자연어 생성이 최근 연구 트렌드
- predefined template이 base이기에 generality가 낮음
- 우리는 sequence-to-sequence이기에 더 다양한 summary를 생성 가능
Advancements in Vision-Language Research
- visually-situated language는 놀라운 발전
- Chart understanding에 specific하진 않음
Unified ChartReader Framework
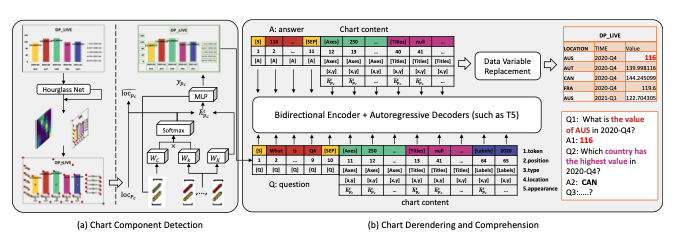
- 우리의 모델은 chart-to-table, chart-to-text, chartQA task를 모두 지원
- rule-free chart component detection과 extended pre-trained vision-language model 로 구성
Chart Component Detection
- rule에 구애받지 않는 chart component type과 location을 detecting하는 Module
- 총 3 steps
- center/keypoint detection
- center/keypoint grouping
- component position/type prediction
Overcoming Heuristics
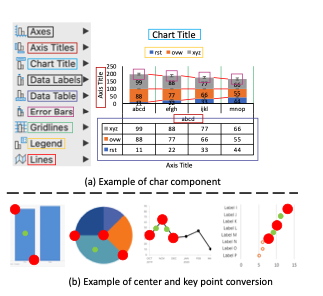
- rule-base methods를 eliminate하자
- dataset의 annotate를 processing함으로써 chart의 rule을 자동적으로 학습
- upper left와 lower right, each component의 center를 center와 keypoint로 변경
- 큰 양의 annotated data가 필요하지만 chart type별 specific rule은 필요 없음
Step-1: Center/Keypoint Detection
- center
- keypoints
- Houseglass network를 통해 학습
- location 예측치
- type 예측치
Step-2: Center/Keypoint Grouping
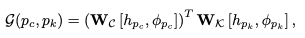
- 각각의 center, keypoint에 position에 따른 embedding feature 추출
- type token
- multi-head attention을 통해 의 weight를 obtain
- 는 center, keypoint의 hidden feature
- type token embedding에 x, y axis에 따른 사인 함수를 더한 값을 multiplication 이전 더해줌
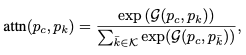
- weight를 구한 뒤 softmax하여 final grouping score를 계산
Step-3: Component Position & Type Prediction
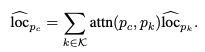
- attention에 따라 center position을 weighted average
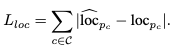
- 다음 에러 term에 따라 최적화
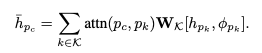
- chart component type을 predict하기 위해 다음과 같이 center embedding update
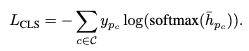
- 다음 cross-entropy loss를 통해 optimization
Chart Derendering and Comprehension
- unified chart understanding framework that handle chart-to-X tasks
Motivation & Reasoning
- 두 reason에 따라 motivated
- 모든 chart-to-X task를 QA problem으로 간주
- chart-to-table에서 axis label과 legend는 question이며 component는 answer
- chart-to-text는 blank template를 generate하는 것
- Q&A 등 task 이전에 수행함으로써 효과적으로 multiple chart undestanding이 가능
- sequence-to-sequence
- pre-trained LLMs을 chart comprehension으로 extend
- 모든 chart-to-X task를 QA problem으로 간주
Positional & Input Embedding
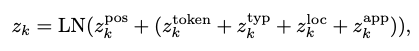
- T5와 같은 pretraining LLM에 적합하게 조정
- k-th position의 fused embedding 를 다음 식을 통해 계산
- 는 초기에 0으로 설정
- 은 dataset의 textual information
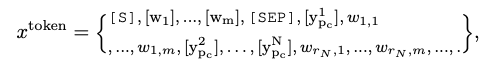
- text, type 등 다양한 information을 tokenizing
- 이외에도 여러 technique
Data Variable Replacement Technique
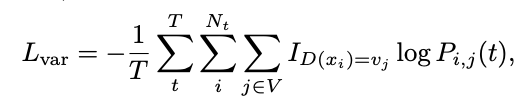
- 다음 loss function을 이용해 token과 generate token을 일치하게 하려 함
Experiments
Evaluation Tasks and Datasets
Chart-to-Text Task
- C2T dataset 사용
- Pew와 Statista로 구성
- Chart image와 human summary
- diverse set of chart styles and textual summary
Chart-to-Table Task
- Excel400K
ChartQA Task
- FQA, DVQA, PlotQA, ChartQA dataset 사용
Evaluation Metrics
- Chart-to-Table - ChartOCR의 그것들
- Chart-to-Text - BLEU4
- ChartQA - standard accuracy
Training Details for Different Tasks
- Chart-to-Table에서 bounding box를 통해 keypoint와 center를 추출
- Chart Component Detection module이 없음에도, table extraction이 수준급
State-of-the-Art Comparisons
Results of Chart-to-Text Task
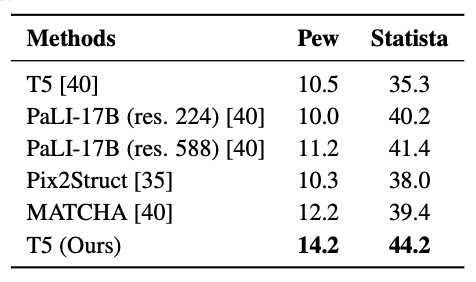
- SOTA
Results of Chart-to-Table
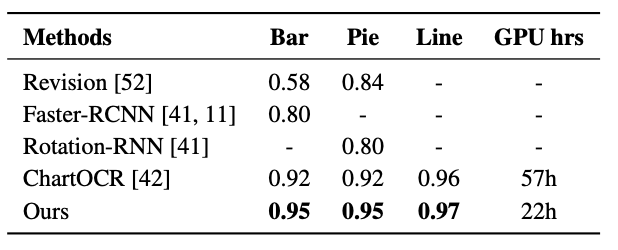
- ChartOCR을 Surpass
- 두 가지 요소가 성능 향상의 원인으로 보임
- 휴리스틱 룰을 제거 후, keypoint를 center와 grouping
- Output이 Chart-to-Table, ChartQA를 통해 학습됨으로써 semantic information 등 chart understaing을 강화함
- inference 시간 또한 짧음
Results of ChartQA Task
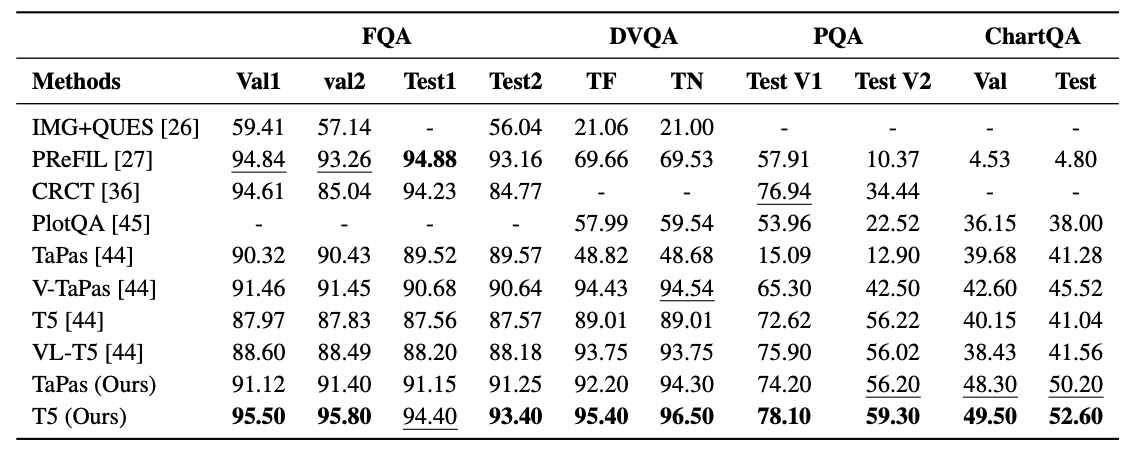
- 거의 SOTA
- Joint training이 효과적인 것으로 예상
Ablation Study
Chart Component Detection
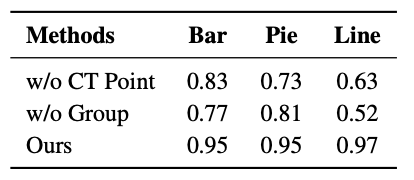
- Keypoint detection과 Grouping이 효과적임을 알 수 있음
Input Encoding
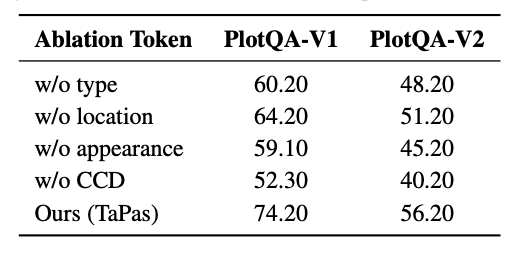
- T5의 input으로 token을 추가하는 것이 효과적임을 알 수 있음
Conclusion
- Unified framework for chart comprehension, ChartReader를 제안
- SOTA!
