DEPLOT: One-shot visual language reasoning by plot-to-table translation (ACL 2023)
Paper Review
목록 보기
25/51

Introduction

- Multimodal reasoning on visual language is complex!
- QA와 같은 downstream을 위해서는 model은 image에서 정보를 추출하고 이를 적절히 조합할 수 있어야 함
- MatCha와 같은 End-to-End solution이 존재하지만, 방대한 fine tuning 과정이 필요함
- GPT-3, PaLM은 few-shot learning에서 annotation 없이 탁월함을 보여줌
- 우리는 multimodal visual language reasoning을 다음과 같은 task로 분리하려 함
- convert input plot image to a linearized table
- passing table to LLMs for one shot learning
- Key method는 모달리티 전환이기에, 우리는 DEPLOT이라고 명명
- 현재 통합된, 강건한, 정확한 chart information extraction framework는 존재하지 않음
- 우리의 DEPLOT은 plot-to-table translation을 통해 학습된 end-to-end image-to-text transformer 모델임
- image를 text로 변환한 후 LLM의 query로 집어넣어 answer을 계산
- CoT, SC, PoT 등 프롬프트 테크닉을 사용
- Summary
- Standardize plot-to-table task
- propose modality conversion model DEPLOT that translate multimodal task into language only task
- Achieve SOTA at ChartQA
Background
Plug-and-play of multimodal pretrained models
- Large pretrained model 들은 cross-modal(CLIP), single-modal(GPT-3)에 관계 없이 좋은 성능을 보여줌
- 특히 높은 zero/few-shot 성능을 보임
- 이러한 Large pretrained model을 leverage하여 좋은 성능을 얻어낸 연구가 많음
- 그러나 지금까지 visual information은 그저 object type 등에 불과함
- Visual language reasoning에서는 정확하고 상세한 정보 추출과 강력한 수치 해석 능력이 필요함
- fully end-to-end model이 answering에 어려움을 겪는 반면, DEPLOT과 LLM을 합친 모델은 간단하게 SOTA보다 높은 성능을 얻음
- 두 개의 pretrained model을 결합하여 좋은 성능을 획득!
Zero & few-shot reasoning over tables
- table reasoning task는 end-to-end neural model이 지배했었음
- GPT-3를 통한 zero-shot downstream QA 만으로 거의 SOTA에 도달
- Prompt engineering을 사용하면 SOTA를 뛰어넘을 수 있음
Information extraction from plots and charts
- 기존 IE는 OCR, Rule based, object detection 등이 주류
- DEPLOT은 ChartOCR에 비해 훨씬 좋은 성능
- 방법을 제외하고도, plot data extraction 평가 지표 또한 ununified
- 우리는 더 나은 table comparison metric을 제안함
Standardizing the Plot-to-table Task
- Convert plot to text by DEPLOT
- linearized table to LLMs for reasoning
Task Definition
- 기존 table 유사도 측정 방법론은 한계가 존재
Realative Number Set Similarity (RNSS)
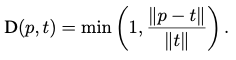
- D는 distance 계산이며, 이를 통해 matrix 생성
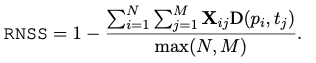
- 이는 명백한 한계가 존재
- number의 position을 고려하지 않음
- non numeric content를 고려하지 않음
- very high relative error에 credit을 부여함
- table reconstruction 시에 recall 대비 precision을 고려하지 못함
- 우리의 metric은 다음 특성을 보유할 것
- transposition에 invariant
- threshold 이상의 에러를 허가하나 penalty를 줄 것
- Preicision, recall을 동일하게 반영할 것
Relative Mapping Similarity (RMS)
- table을 set of number이 아닌, row col을 가지는 collection으로 봄
- distance between textual entries는 Normalized Levenshtein Distance로 계산 가능
- Distance between
- Distance between numeric entries
- similarity =
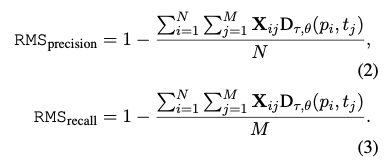
- 동일하게 minimal cost matching matrix를 구한 뒤에, 다음과 같이 RMS를 계산
- 조화 평균을 통해 을 구할 수 있음
Training Plot-to-table Conversion Models
- OCR X, object/keypoint detection X
- type specific engineering 필요 없음, Chart type에 invariant
- SOTA visual language model인 MatCha 사용
- table은 linearlized textual sequence (|로 separate, \n으로 row separate)
- DEPLOT은 Autoregressive 하게 table을 생성하도록 학습
- MatCha의 인위적인, 자연적인 데이터를 모두 학습에 사용
Human Eval of Plot-to-table Metrics
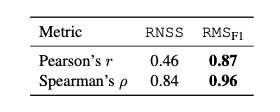
- 의 성능을 알기위해 human annotator 고용
- 모델이 over\under generate하지 않는가?
- x, y label/index, title이 맞는가?
- number이 실제 값과 동일하고 맞는 자리에 위치해있는가?
- Human score가 RMS와 높은 상관관계를 보여줌
Prompting LLMs for Reasoning
- Chain-of-Thought, Program-of-Thought, SC 등 이용
- Tabular Data에 적절하게 수정하여 prompting
- SC는 여러 답변을 생성 후 Greedy하게 답변을 채택하는 것
