LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking (MM 2022)
Paper Review
목록 보기
26/51

Introduction

- Document AI는 layout을 parse하고 key information을 extract
- performant multimodal pre-trained Document AI 모델은 BERT의 MLM을 사용하며, training objective에서 그 차이를 보임
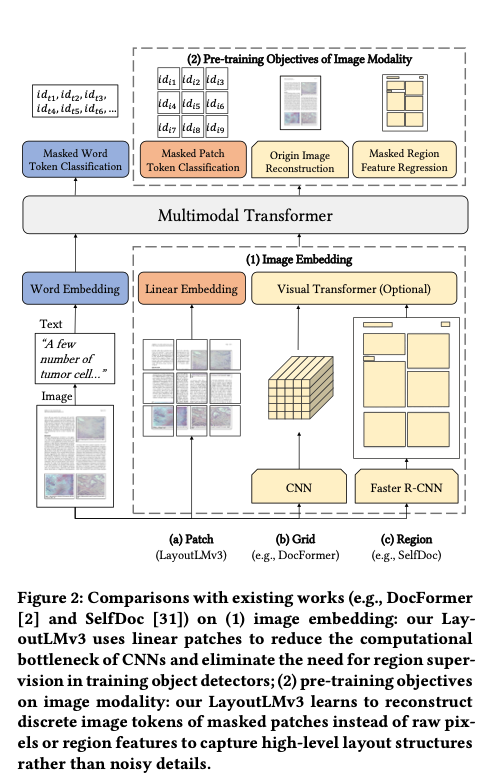
- Docformer은 CNN decoder를 통해 image pixel을 reconstruct
- high-level structure보다 noisy detail을 학습할 우려가 있음
- SelfDoc은 국소적 masking feature를 회귀
- 이산형 feature를 분류하는 것보다 noisy하고 학습에 어려움이 있을 수 있음
- 이미지, 텍스트의 세분성은 multimodal representation learning에서 가장 중요한 cross-modal alignment에 어려움을 줌
- LayoutLMv3는 이를 해결하고자 함!
- reconstruct masked word tokens of text modal (MLM)
- reconstruct masked patch tokens of image modal (MIM)
- word-patch alignment(WPA) objective to predict
- CNN을 사용하지 않아 parameter가 적고, region annotation을 제거하며, simple unified하기에 general하게 사용 가능
- form understanding, receipt understanding, document visual question answering과 같은 text-centric benchmark에서 SOTA
- document image classification, document layout analysis와 같은 image-centric benchmark에서 SOTA
- Summary
- CNN과 Faster R-CNN을 사용하지 않은 multimodal model (save parameter, eliminate region annotations
- MLM, MIM, WPA objective를 통해 discrepancy를 완화
- text centric, image centric 둘 다에서 잘 작동하는 model 개발
- SOTA 달성
LAYOUTLMV3
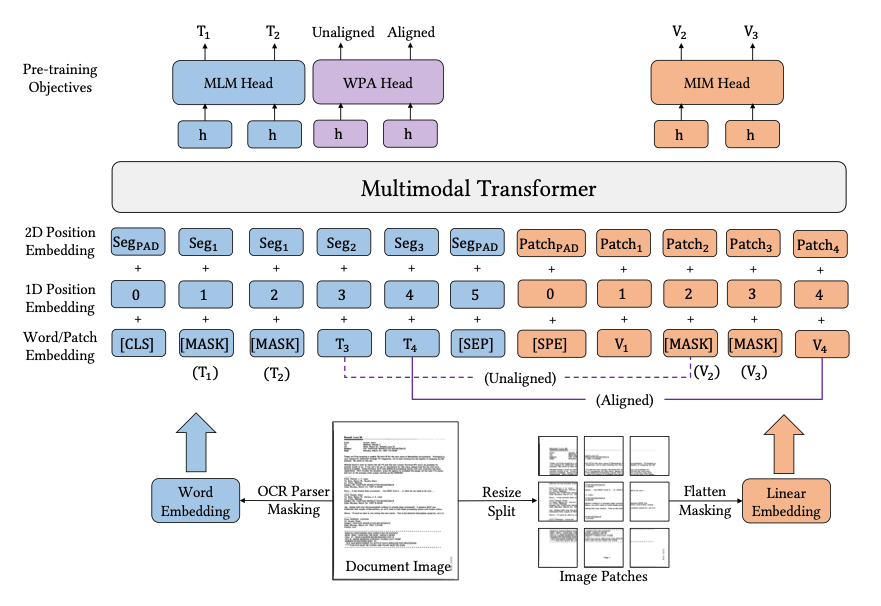
Model Architecture
- unified text-image multimodal transformer to learn corss-modal representations
- Text embedding과 image embedding을 concat하여 input으로 사용
Text Embedding
- OCR toolkit을 사용해 textual content와 2D position information 획득
- word embedding과 position embedding 진행
- word embedding은 RoBERTa로 initialize
- Positional embedding은 1D의 word position과 2D의 layout position (Bounding box coordinate)를 포함
- coordinate는 image size로 normalize, word의 position은 segment level에서 진행
- segment level에서 2D positional embedding을 구하는 것이 LayoutLMv2와 차이점
Image Embedding
- 기존 Multimodal Document AI 모델은 CNN, Faster R-CNN을 통해 region feature를 extract
- 이는 heavy computation bottleneck 등의 이슈가 존재
- 우리는 ViT, ViLT와 같이 image를 linear projection
- P X P로 split 후 각 patch를 d 차원으로 projection 후 flatten
- 이후 1D position embedding을 더해줌
Pre-training Objectives
Objective 1: Masked Languagfe Modeling (MLM)
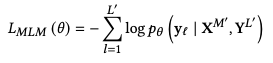
- BERT의 그것
- 30% text token을 span masking strategy를 이용하여 masking
Objective 2: Masked Image Modeling (MIM)
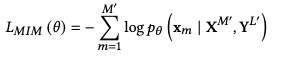
- BEiT의 그것
- image token의 label은 dense image pixel을 visual vocabulary에서 discrete token으로 바꾼 것
- 이를 통해 noisy low level detail 대비 high level layout structure를 학습할 수 있음
Objective 3: Word-Patch Alignment (WPA)
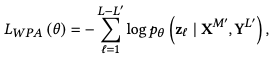
- Image patch와 text word를 align하는 objective
- mask된 text word와 image patch가 일치하는 지
- masked text token은 loss calulating 시 제외
- masked text와 image patch가 align 되는 것을 방지하도록
EXPERIMENTS
Model Configurations
- 기존 LayoutLM, LayoutLMv2 size를 follow
- 속도를 위한 분산 학습
- CovView와 유사한 방식으로 attention product 수식을 수정
Pre-training LayoutLMv3
- IITCDIP Test Collection dataset 사용
- No augmentation
- RoBERTa로 text embedding, DiT로 image tokenizing
Fine-tuning on Multimodal Tasks
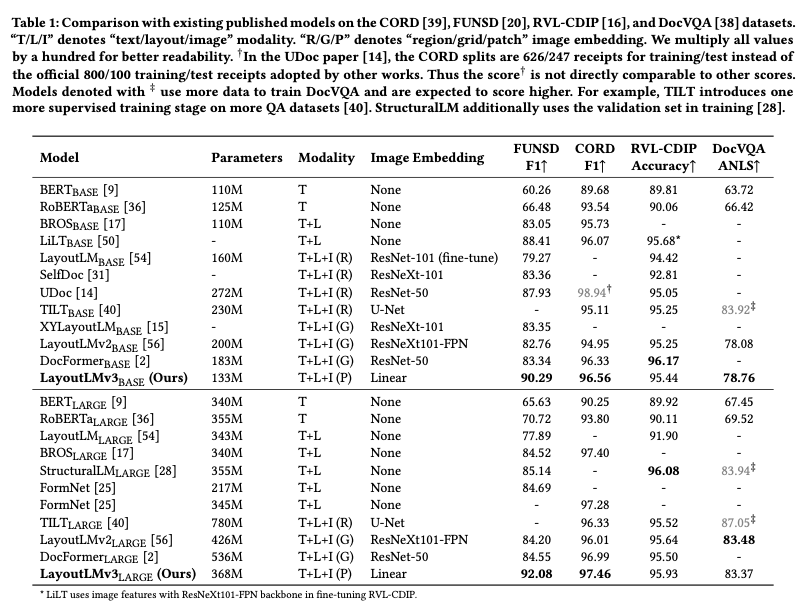
- LayoutLMv3와 typical한 self-supervised pre-training approach 비교
T+L+I (P) text, layout, and image modalities with linear patch features
- LayoutLMv3는 CNN backbone을 simple linear embedding을 통해 image patch를 encoding
Task 1: Form and Receipt for Understanding
- form과 receipts의 textual content를 이해하고 추출할 수 있어야 함
- each word와 label을 예측하는 sequence labeling process
- FUNSD, CORD 데이터셋 사용
- SOTA 달성
Task 2: Document Image Classification
- document image의 category를 predict
- image-centric task에서도 인상 깊은 결과를 도출
Task 3: Document Visual Question Answering
- Document image와 question을 input으로 받아 output을 도출
Fine-tuning on a Vision Task
- Generality를 확인하기 위해 document layout analysis task로 전환
- Detecting layout of unstructured digital documents
- Object Detection problem으로 치환
- LayoutLMv3를 feature backbone으로 사용하는 것
- 평가지표는 IOU에 따른 MAP를 사용
Ablation Study
- Image embedding이 없을 때 더 좋은 성능을 보이는 경우가 있음
- 그러나 Image embedding 없이는 image-centric Document AI task를 수행하지 못한다는 한계 존재
- 이는 추후 개선 필요
CONCLUSION AND FUTURE WORK
- CNN, Faster R-CNN에 의존하지 않는 multimodal model LayoutLMv3를 제안
- MLM, MIM, WPA objective를 통해 multimodal representation을 학습
- Simple Architecture로 image-centric, text-centric 둘 다에서 SOTA 달성
