Random walk 기반 unsupervised representation learning은 명백한 한계가 존재
근접 정보에 크게 의존
Hyperparameter에 크게 영향 받음
근접한 노드가 유사하다는 Inductive Bias가 중복될 수 있음
mutual information을 이용해 해결하자!
mutual information을 활용해 High Demensional data를 잘 representation한 DIM을 그래프에 적용할 것
Related Work
Contrastive Methods
unsupervised learning of representations 의 key는 'real, 'fake'의 score를 벌리는 것
대부분 classification techniques를 사용하며, DGI 또한 local-global pair와 negative-sample를 classify하는 방식
Sampling Strategies
구현의 key detail은 어떻게 positive, negative sample을 뽑을지
기존에는 random walk기반 (language model's approach)
이를 개선한 연구도 존재
Predictive Coding
Contrastive Predictive coding(CPC)는 mutual information maximization으로 deep representation을 찾은 논문
Contrastive 한 것은 위의 모델들과 동일하나, 모두 predictive 하다는 점에서 차이를 보임
노드와 노드의 이웃들 끼리
노드 이웃 쌍 끼리 모두 비교 가능
global local parts를 동시에 contrast 할 수 있음
DGI Methodology
Graph-Based Unsupervised Learning
X=x1,x2,...,xN
xi∈Rf
Our obejective is to learn encoder E to make H=h1,h2,...,hN
hi∈Rf′
GCN에서 local node neighbors를 aggregate 하는 것과 같이, 우리의 hi 또한 비슷한 맥락
이를 patch representation 이라고 부를 것
Local-Global Mutual Information Maximization
local mutual information을 maximize하기 위해 graph information을 저장한 summary vector s를 찾아야 함
readout function R:RN×F→RF
Discriminator D:RF→R
D(hi,s)
probability scores to patch-summary pair
Negative Sample은 다른 graph의 patch representation hj′∈(X′,A′)을 사용
IF single Graph? corruption function을 통해 sampling (Node를 n개가 아닌 m개를 사용)
Jensen-Shannon divergence를 통해 mutual information을 maximize
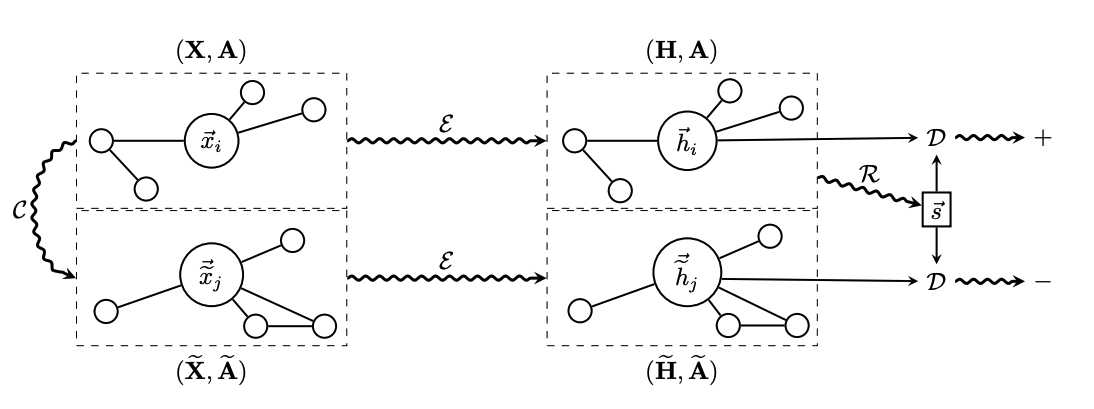
Theoretical Motivation
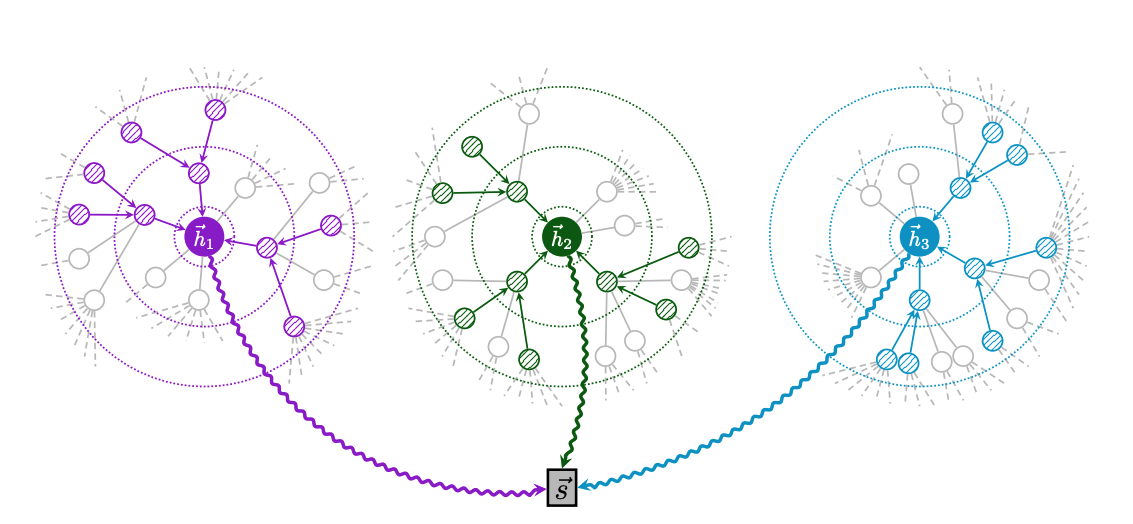
Overview of DGI
Sample negative example (X~,A~) ~ C(X,A)
Obtain Patch Representation hi for the input graph by passing it through the encoder: H=E(X,A) = {h1,h2,...,hN}
Obtain patch representation hj for the negative example by passing it through the encoder: H~=E(X,A)~ = {h1,h2,...,hN~}
summarize the input graph s=R(H)
Update Parameter E,R,D by applying gradient descent to maximize Equation 1
Classification Performance
DGI Encoder가 얼마나 좋은지 확인
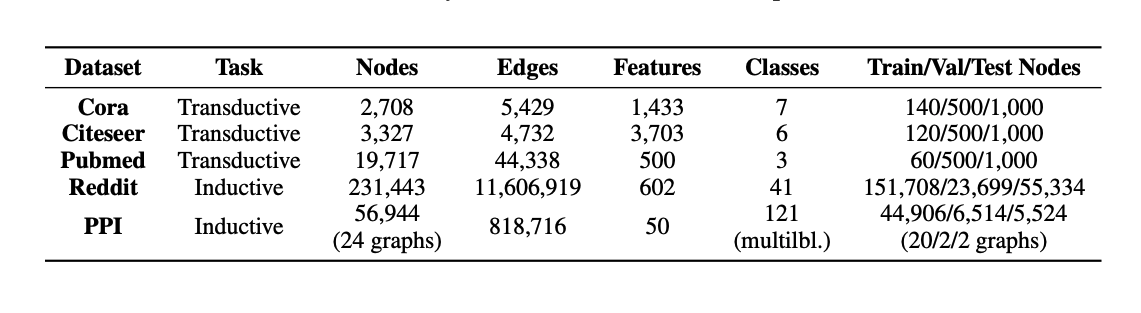
Datasets
Cora, Citeseer, Pubmed citation networks
Reddit posts
Protein-protein interaction networks
Experimental Setup
3개의 실험마다 다른 setting
transductive learning,
inductive learning on large graph,
inductive learning on multiple graphs
Transductive learning
One Layer GCN 사용
Learnable linear transformation
Negative Sample에서 (A~=A) but X~= low-wise shuffling of X
Inductive learning on large graphs
mean-pooling propagation rule (GraphSAGE-GCN) 사용
D−1^을 곱함으로써 normalized sum 효과
Adjacency Matrix와 Degree Matrix는 사실 구할 필요 없음
Reddit은 skip connection을 사용한 3-layer mean pooling 모델 사용
||는 featurewise concatenation (central node와 neighborhood는 각각 handling 됨)
Subgraph는 mini-batch에서 1개의 노드를 sampling 하고 10번, 10번, 25번 neighborhood node를 with replacement sampling 하여 총 1 + 10 + 100 + 2500 = 2611 의 sample로 subgraph 계산
첫 번째 sample node 계산만 수행 됨
이들을 통해 summary vector si를 계산
Negative Sampling 시 sampled subgraph에서 row-wise shuffle 등을 수행
central node's feature가 이웃 노드의 feature로 변경되어 negative sample의 다양성을 높일 수 있음
Inductive learning on multiple graphs
3-layer mean pooling model with skip-connection
Wskip is a learnable projection matrix
Negative Sample은 그냥 다른 그래프에서 가져오면 됨
Readout, discriminator, additional training details
Readout
simple averaging all node features
σ is logistic sigmoid nonlinearity
가장 좋은 readout function 이지만, graph size가 커지면 다른 function을 사용하는 것이 적절
Discriminator
Simple bilinear scoring function
W is learnable scoring matrix
Other
Glorot initialization
Adam with 0.001 lr (at 10^-5 on reddit)
early stop at transductive dataset (patience of 20 epochs in training loss)
Fixed Epoch in inductive dataset (150 on reddit, 20 on PPI)

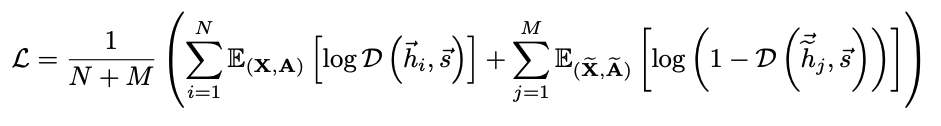
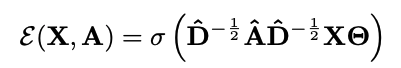
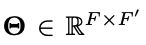
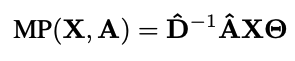
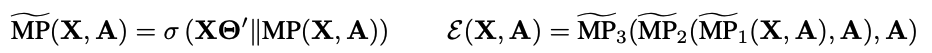
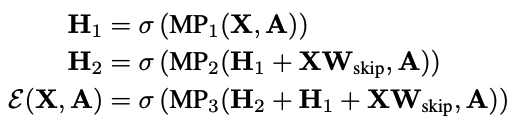
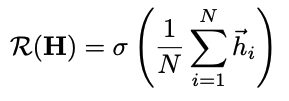
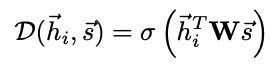

좋은 글이네요. 공유해주셔서 감사합니다.