Wide & Deep Learning for Recommender Systems (DLRS 2016)

Introduction
- Ranking problem에서 memorization과 generalization을 달성해야 함
- Memorization
- Learning frequent co-occurrence of items or features
- Generalization
* based on transitivity of correlation and explores new feature combinations (never occured in the past)
- Generalization은 memorization에 비해 다양성이 높음
- Memorization 모델은 (Logistic Regression) 간단하고 확장 가능하지만, feature engineering이 필요하고 이전에 나오지 않은 경우에는 잘 작동하지 못함
- FM, DNN 등 generalization 모델은 더 미세한 패턴, 적은 feature engineering에서 강점을 가지나 과한 일반화 등에서 약점을 가짐
- 우리는 두 지점을 통합한 Wide & Deep 모델을 구현 함!
Recommender System Overview
- app recommender system에서 item은 너무나 많기에 모든 query를 다 구하는 것은 비효율 적
- Rule-based + ML algorithm으로 candidate를 추출한 뒤 ranking model로 추천할 아이템을 선정하는 방식
Wide & Deep Learning
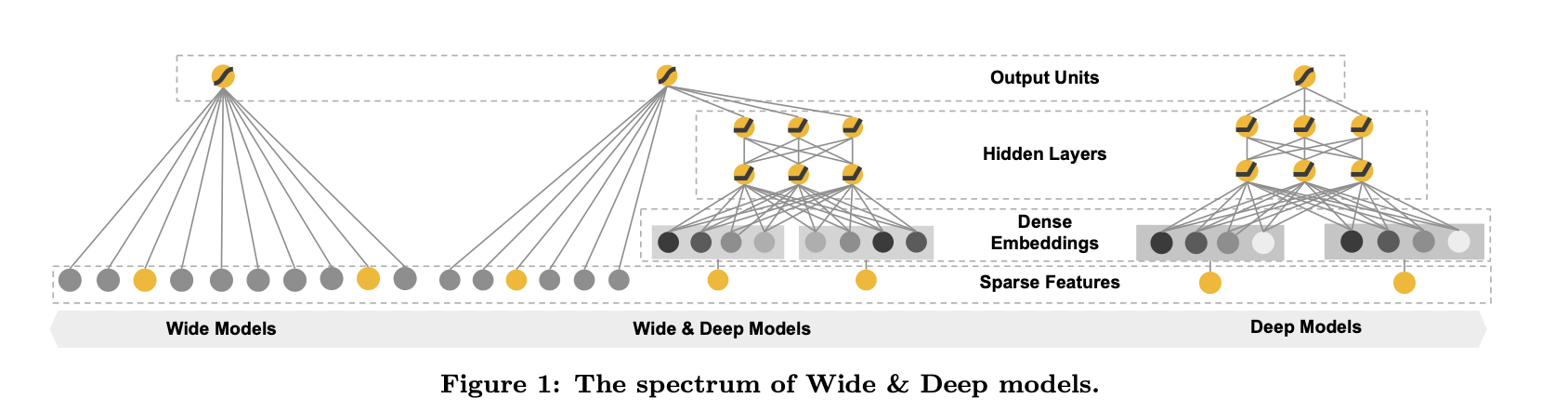
The Wide Component
- wide component는 일반화 가법 모형
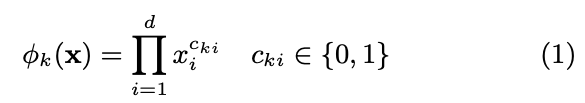
- 다음과 같은 cross-product term을 통해 interaction을 binary하게 포착하고자 함
- cki∈0,1 if i-th feature and k-th feature is 1
The Deep Component
- Deep Component는 Feed forward neural network
- wide component에서 one-hot vector를 사용한 것과 달리 low-dimension으로 embedding하여
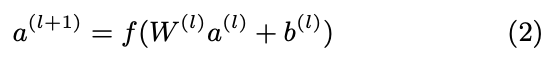
- 다음 FFNN을 통과하게 됨
Joint Training of Wide & Deep Model
- Wide, Deep Component는 output log odds를 weighted sum 하여 predict 하게 됨
- 이는 ensemble과 달리, 모든 parameter는 서로의 존재를 알기에 이를 고려하여 최적화가 발생함
- Wide part와 Deep part는 서로의 단점을 보완하는 방향으로 학습될 것
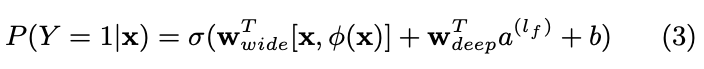
- Combined model은 다음과 같으며, wide part는 FTRL algorithm을 사용, deep part는 adagrad 를 사용해 optimize 하였음
System Implementation
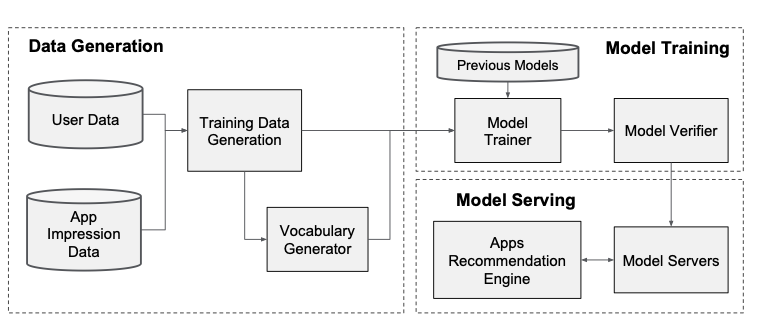
Data Generation
- 특정 시간동안 사용자와 앱 노출 데이터를 이용해 훈련 데이터를 생성
- 레이블은 app acquisition으로, 1이면 노출된 앱이 설치되었음을 의미
- 범주형 피처 문자열을 정수 ID로 매핑하는 테이블인 Vocabularies도 이 단계에서 생성
Model Training
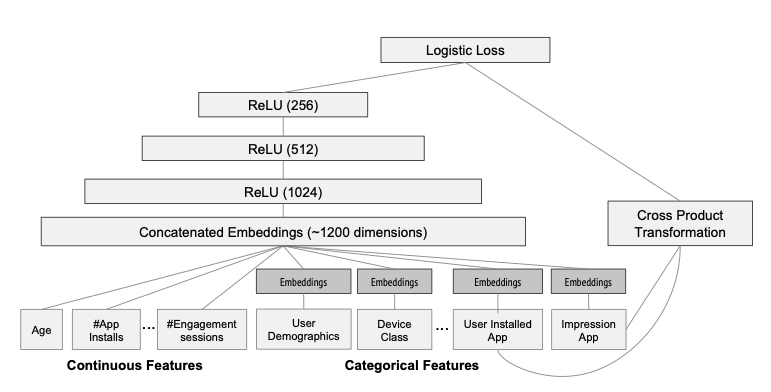
- 훈련 데이터와 Vocab을 가져와 레이블과 함께 Sparse, Dense Matrix를 생성
- Wide Component는 설채된 앱의 사용자, 노출 앱 들의 cross product transformation으로 구성
- Deep Component는 32 차원의 임베딩 벡터로 구성
Model Serving
- 모델이 훈련되고 검증된 후 Model Serving
- 각 요청을 10ms 단위로 처리하기 위해 모든 후보 앱에서 점수를 매기는 것이 아닌, 작은 배치를 병렬로 실행하여 성능을 최적화

훌륭한 글이네요. 감사합니다.