Editing Factual Knowledge and Explanatory Ability of Medical Large Language Models (CIKM 2024)
Paper Review
목록 보기
49/51

INTRODUCTION
- LLM4Med에서 hallucination은 매우 critical한 problem
- But fully finetuning은 매우 높은 cost가 소모됨
- 따라서 Knowledge edit이 필요
- 이를 통해 지식 기반을 수정하며, 원래 지식에는 영향을 받지 않도록 함
- General domain에서의 KE는 많이 연구가 되었지만, Med에서는 unexplored
- 크게 두 가지 유형으로 분류됨
- 명시적 Memory, Additional Parameter를 도입
- 특정 지식에 해당하는 parameter를 searching 및 수정
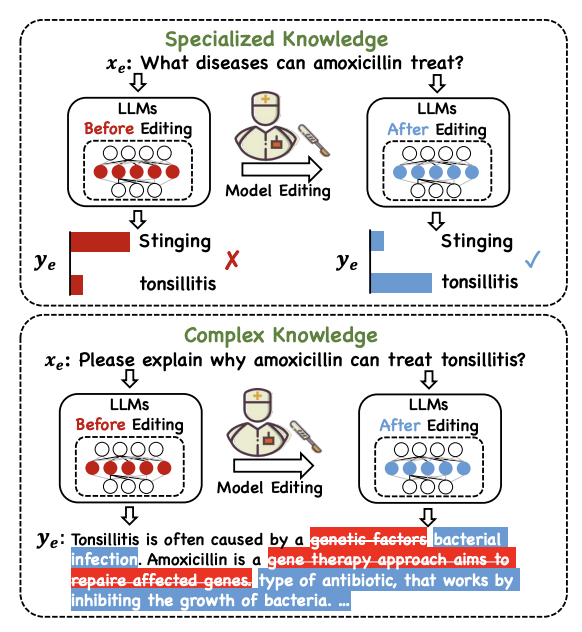
- Figure와 같이, LLM에서 환각 증상이 보임
- CoT등을 사용한다 하더라도, 원래 지식이 부족하다면 해결 불가
- Model Edit이 가능할까? 를 탐구 및 MedLaSA를 제안
- Additional Parameter와 Locate-then-edit 장점을 결합해 의료 도메인에 적용
- 가장 먼저, Locate-then-edit 패러다임과 같이 causal tracing을 통해 의료 지식과 관련된 layer를 연결
- 이후 파라미터를 조정하는 대신, additional parameter를 추가하여 adapter를 통해 학습
- 여기서 특정 레이어 에만 추가하는 것이 아닌, Soft scailing을 사용하여 scale set을 저장
- 또한 의료 지식 edit task에서 평가할 벤치마크가 부족하므로, Medical Counter Fact(MedCF) 및 Medical Fact Explanation(MedFE)라는 벤치마크를 구축 및 제안
- 이를 통해 Efficacy, Generality, Locality, Fluency를 평가
- 또한 추가적으로 Locality에 대한 comprehensive한 evaluation을 제안
- Target Distribution (TD) Edit이 GT token의 target distribution을 변경하는가?
- Entity Mapping (EM) Edit이 Head와 tail의 mapping 관계만을 학습하는가?
- Structural Similarity (SS) Edit이 유사한 그래프 구조를 가진 다른 지식에도 영향을 미치는가?
- Textual Similarity (TS) Edit이 Semantic이 비슷한 다른 지식에 영향을 미치는가?
- Consistent Topic (CT) Edit이 같은 주제의 다른 관련 없는 지식에 영향을 미치는가?
- 본 Evaluation protocol을 통해 MedLaSA의 우수한 성능을 검증함
RELATED WORK
- 두 접근법 모두 장 단점을 보유
- Locate-then-edit의 경우 Causal 측면에서 강점을 가지지만, 지나친 최적화로 인해 관련 없는 지식에 부정적인 영향을 미칠 수 있음
- 추가 파라미터 도입은 관련 없는 지식에 미치는 영향은 적지만, Causal 측면에서 단점을 가짐
- 우리의 MedLaSA는 두 접근법의 장점을 결합함으로써 지식의 연관성 식별 및, Adapter를 통해 관련 없는 지식의 영향을 최소화하며 정확한 Edit을 가능케 함
METHODOLOGY
Preliminaries
- 편집 이전 model 및 input output
- 이후
- 편집 이후에는 다음 네 가지 속성을 만족해야 함
- Efficacy Edit 이후의 input-output은 edit된 지식을 인지해야 함
- Average Accuracy로 계산
- Generality 의미가 유사한 input에 대하여서도 edit된 지식을 보유해야 함
- Locality 관련 없는 지식에 대하여서는 이전 출력을 유지해야 함
- Fluency Edit이후 생성 능력 및 유창성을 유지해야 함
- bi, tri-gram entropies로 계산
- Efficacy Edit 이후의 input-output은 edit된 지식을 인지해야 함
Causal Tracing
- 인과 추적을 통해 사실을 예측할 때, 어떤 뉴런이 활성화 되는지 포착
Clean run
- Query가 입력되고, 답변 y의 probability를 계산
Corrupted run
- Query embedding에 가우시안 noise를 추가하여 답변 probability를 계산
Corrupted-with-restoration run.
- Corrupted run으로 시작해, 각 layer의 hidden embedding에 대해서 clean run의 hidden embedding과 교체
- 정답 복원 확률이 높은 경우, 그 layer의 embedding이 특정 지식과 관련있다고 간주 됨
MedLaSA
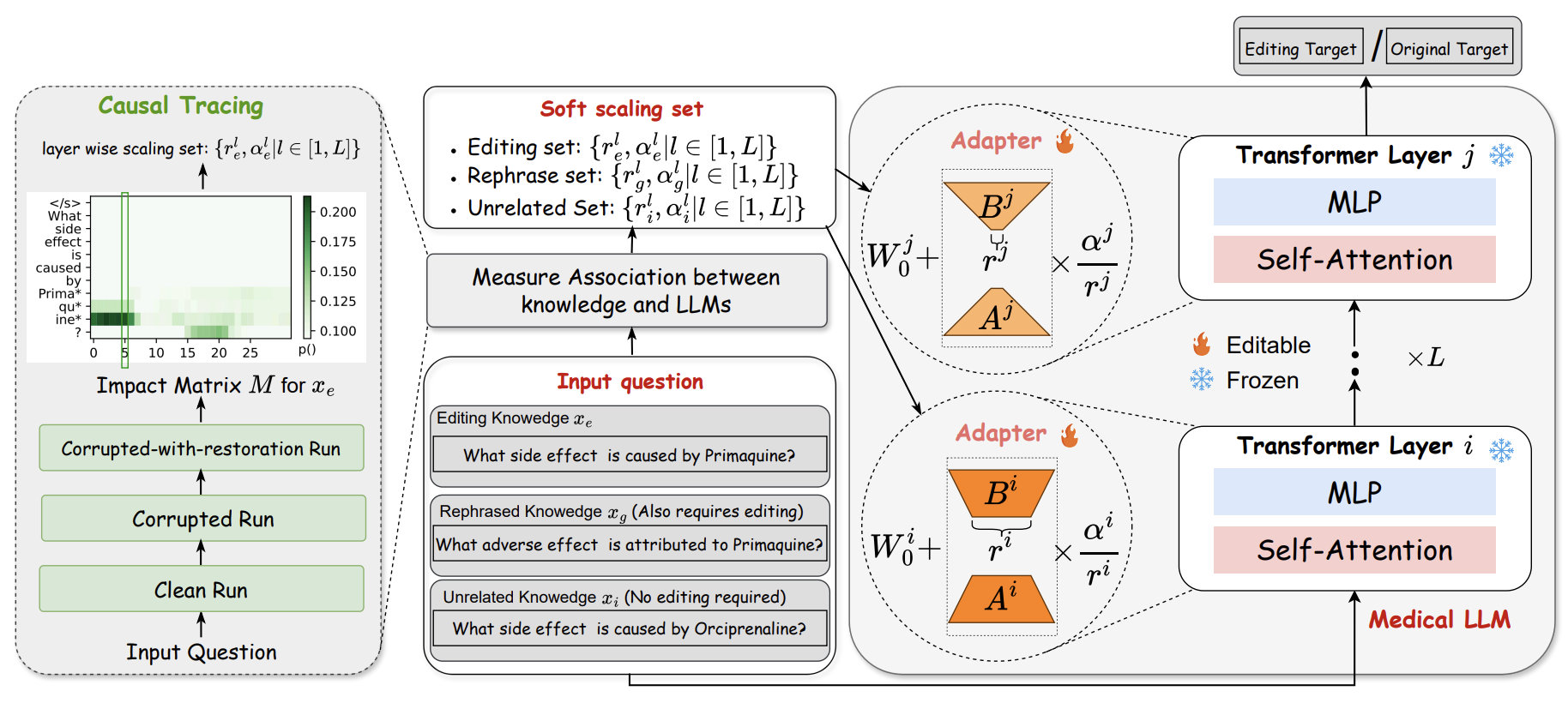
- 가장 먼저, Med subject token에 인과 추적 적용
- 이는 ROME을 통해 중요 인과 관계를 포착하는데 유용하다고 알려짐
- 그러나 ROME은 MLP 가중치를 직접 수정하는 반면, 저자들은 LLM의 원래 능력을 보존하려면 Adapter를 추가하는 것이 효과적이라고 주장
- 이는 ROME을 통해 중요 인과 관계를 포착하는데 유용하다고 알려짐
- 저자들은 서로 다른 지식이 다른 scale을 가진다고 주장
- 이에 따라서, Edit이 필요한 data에 경우 scale을 layer i에서 증가 및 layer j에서 감소 시킴으로써 지식 update가 ith layer에서 발생하도록 활성화
- 반면 관련 없는 data의 경우 j 번째 layer에서 활성화하고, i 번째 layer에서 영향을 줄임
- 또한 LoRA에서 영감을 받아 Adapter는 A,B의 low-rank decomposition된 layer
- 다음과 같은 수식을 가지며 은 , 을 통해 trainable한 parameter를 조정
Scaling
- Parameter 는 original network와 adapter의 weight를 결정
- 의 경우 Subject token의 index 집합
Scaling Rank
- 의 경우 새로운 지식을 업데이트 하는데 필요한 파라미터 수를 제어하는데 사용
- , 을 통해 scale을 계산함으로써 figure 2와 같이 edit, rephreased, unrelated knowledge에 대한 Layerwise scale 집합을 생성 가능
- 추가적으로, Transformer block을 통해 (특히 attention module)을 통해 인과 추적을 별도로 분석 가능
Medical Model Editing Benchmarks

- Med에서 LLM의 환각 증상 및 논리적인 사고 과정을 볼 수 있는 설명 능력을 평가하기 위해 다음 두 벤치마크 설계
- Medical Counter Fact (MedCF) - 의료 지식 edit
- Medical Fact Explanation (MedFE) - 설명 능력 edit
- Edit은 이전에 설명한 것과 같이 Efficacy, Generality, Locality, Fluency를 충족해야 함
Efficacy and Generality Data Construction

Medical Counter Fact Dataset
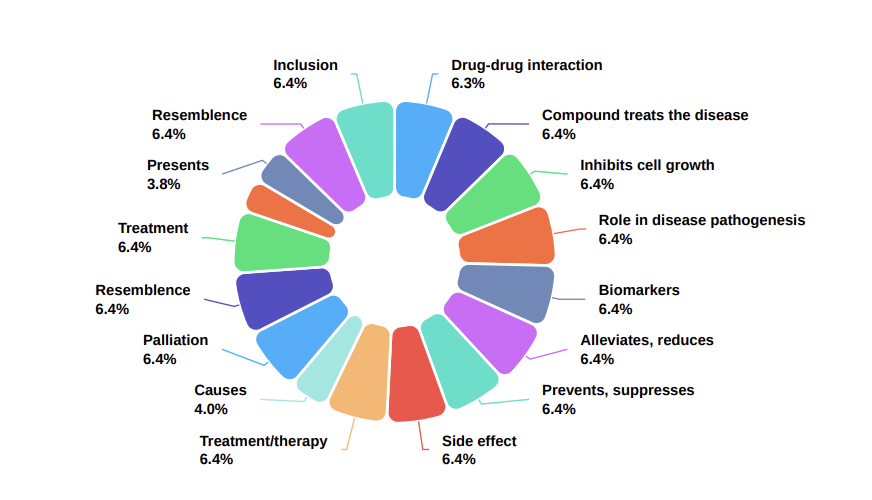
- DRKG라는 의료 지식 그래프 사용
- triplet (head, relation, tail)를 기준으로 QA 쌍을 생성
- Counterfact를 test 하기 위해 ROME의 setting을 따라하여, negative entity object를 생성
- Rephase의 경우 ChatGPT를 사용해 재구성
- 예시와 같이 head를 tail로 바꾸어서 재구성하도록 함
Medical Fact Explanation Dataset
- 의학 입학 시험 데이터셋인 MedMCQA를 활용하여 구축
- MedMCQA의 질답을 결합해 사실적 statement로 사용하고, expert's explanation을 edit target으로 설정
- 이 또한 ChatGPT를 통해 생성되며, 프롬프트 템플릿을 통해 의료 용어를 준수하면서도 질문의 원래 의미를 보존하도록 함
Locality Data Construction
- Model Edit이 관련 없는 지식에 영향을 미치는지 평가
- 이전 벤치마크 (ZsRE, CounterFact)의 경우 OOD data나 반정답 데이터에 의존
- 저자들은 앞서 말한대로, Locality에 대한 TD, EM, SS, TS, CT를 평가해야 한다고 주장
- TD의 경우 tail만 고정한채로 새로운 triplet을 sampling
- EM의 경우 head를 고정한채로 triplet sampling
- SS의 경우 KG embedding 방법론인 RotatE를 사용하여 relation embedding 학습
- TD의 경우 BioBERT를 사용하여 triplet을 text embedding으로 변화한 후, 구조 및 텍스트 유사성에 따라 유사한 triplet을 생성
- CT의 경우 MedMCQA의 source data를 사용
- 이 새로운 triplet을 QA쌍으로 변환하여 Locality를 test
EXPERIMENTS
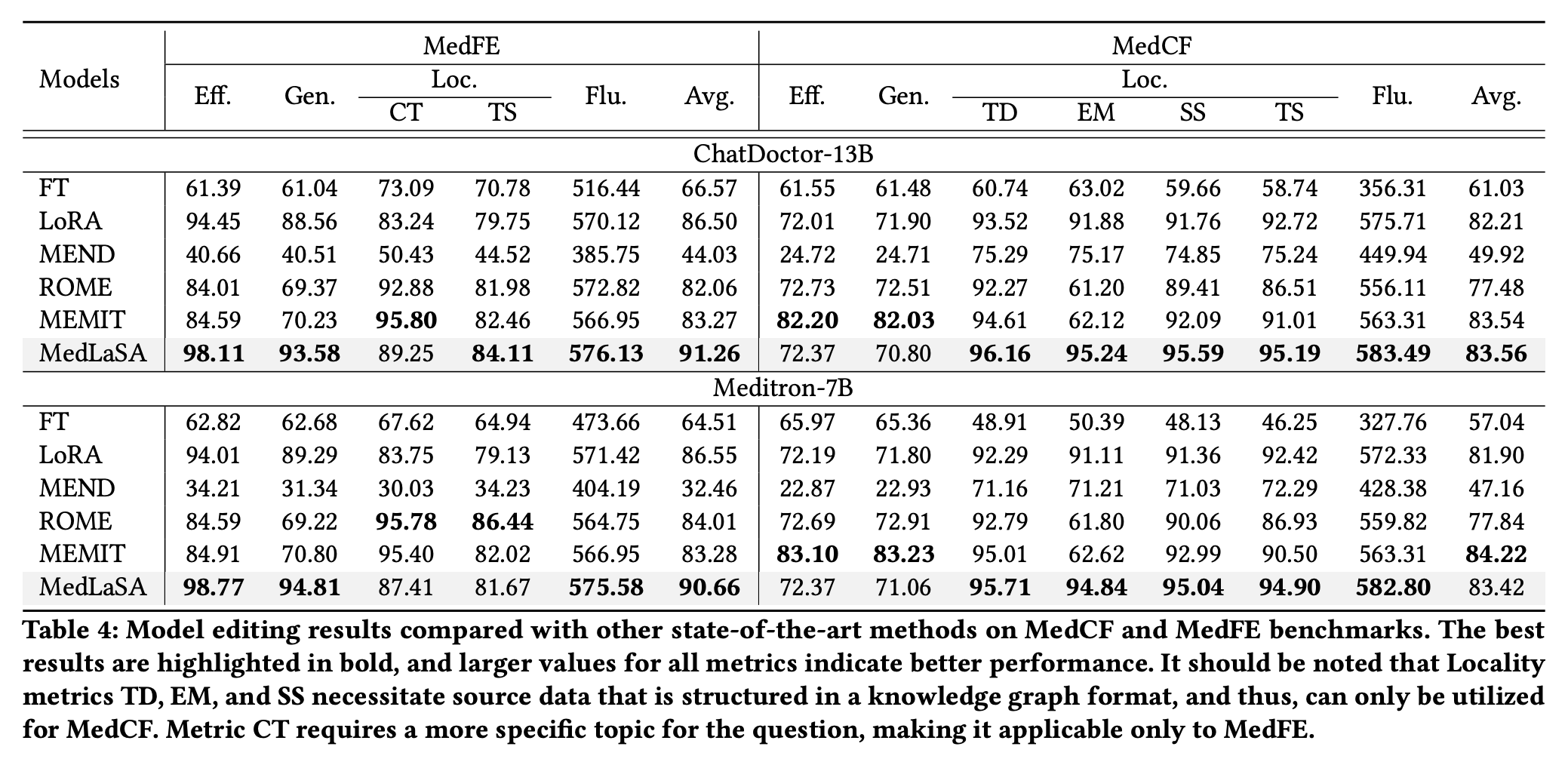
- RQ1. MedLaSA가 SOTA인가?
- RQ2. Layer-wise selection이 성능에 영향을 미치는가?
- RQ3. Module이 성능 향상에 어떠한 영향을 미치는가?
- RQ4. Hyperparameter setting에 따라 어떤 영향을 미치는가?
- RQ5. Different editable weight가 성능에 영향을 미치는가?
- RQ6. MedLaSA가 parameter 및 knowledge의 association을 학습할 수 있는가?
Experimental Setup
Metrics
- Efficacy = eff
- Generality = gen
- Locality = Loc
- Fluency = flu
- MedCF에 대해 TD, EM, SS, TS를 측정 및 MedFE에 대해 TS, CT 측정
- 균형을 맞추기 위해 다음 수식으로 측정
Backbone and Baselines
- MedLLM으로 ChatDoctor-13B, Meditron-7B를 사용
- Baseline으로는 FT(파인튜닝), LoRA, ROME, MEND, MEMIT 등 다양한 edit 방법론과 비교
Main Results (RQ1)
- MedLaSA가 대부분에서 SOTA 달성
- 특히 Fluency가 높아, 생성 능력을 유지할 수 있음을 입증
- FT의 경우 과도한 훈련으로 인해 생성 능력을 잃게 할 수 있음을 시사
- LoRA의 경우, 비슷한 edit 성능을 달성하지만 Locality가 떨어짐을 볼 수 있음
- MEMIT의 경우, MedLaSA와 비슷한 유형의 모델이므로 성능이 comparable함을 볼 수 있음
- 그러나 EM 성능이 크게 떨어지는 것으로 보아, MEMIT이 head와 tail의 관계만을 학습하기에, Locality prompt의 subject가 기존 prompt와 유사할 때만 잘 작동함을 알 수 있음
- 또한 긴 텍스트 출력, 복잡한 다중 지식 처리에서 한계가 있기에 MedFE에서 낮은 성능을 보임
- 이에 반해 MedLaSA는 추가 파라미터의 스케일을 동적으로 처리함으로, 이 문제를 해결
Strategies for Layer Selection (RQ2)
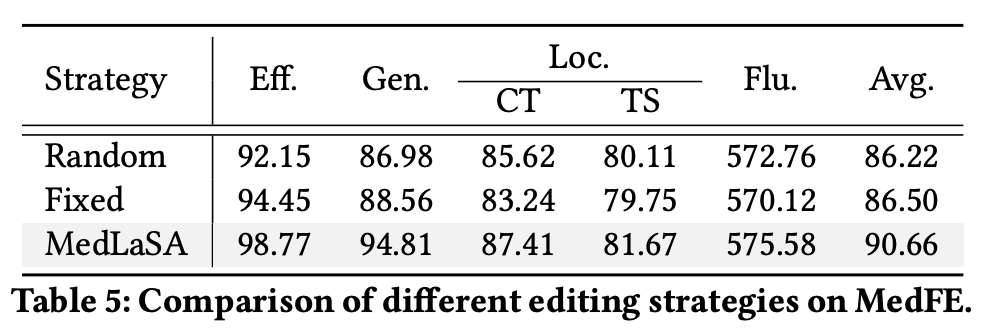
- Layer 선택에 따른 다양한 전략 평가
- Random의 경우, causal tracing 대신 모든 레이어의 를 무작위로 선택
- Fixed의 경우, 모든 레이어의 를 고정시켜둠
- 우리의 설계가 잘 작동함을 입증
Ablation Study (RQ3)
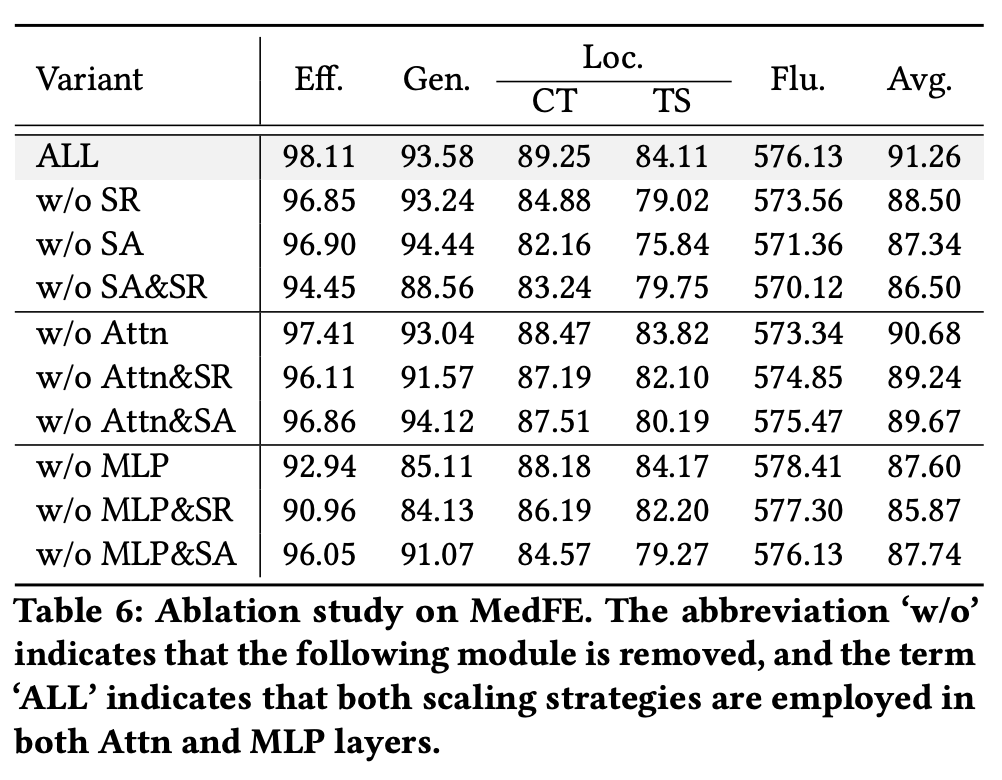
- Self Attention 및 MLP layer에서 의 영향을 ablation
- 을 제거했을 때 모든 지표에서 성능이 하락하며, 특히 locality에서 큰 감소가 나타남
- 이는 rank mechanism이 무관한 지식을 처리하는데 있어서 중요한 역할을 함을 보여줌
- 를 제거햇을 경우 Generality는 오히려 상승
- 다만 이는 Locality의 희생으로 부터 기인 함
- 즉 는 locality를 보존하는데 도움을 주지만, 이과정에서 generality를 일부 trade-off함을 보임
- 둘 다 제거했을 경우에는 Efficacy, Generality에서의 성능 감소를 통해 실질적으로 가장 중요한 edit 성능이 낮아짐을 알 수 있음
Hyperparameter Analysis (RQ4)
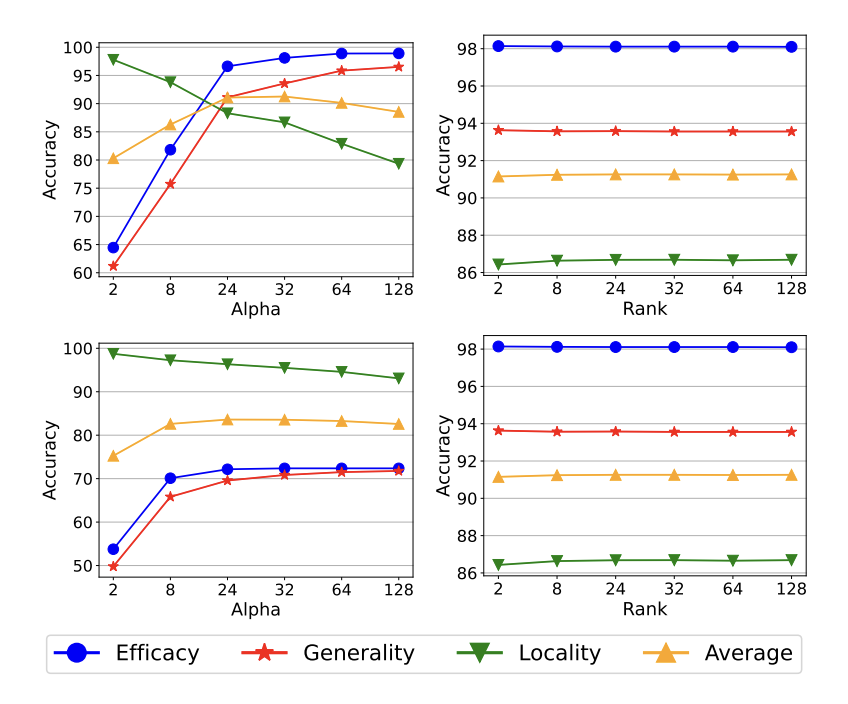
- 가 증가함에 따라 Efficacy, Generality가 증가하며, Locality가 감소
- Trade-off
- 은 매우 작은 값이 아니라면 robust
Comparison of Editable Weights (RQ5)
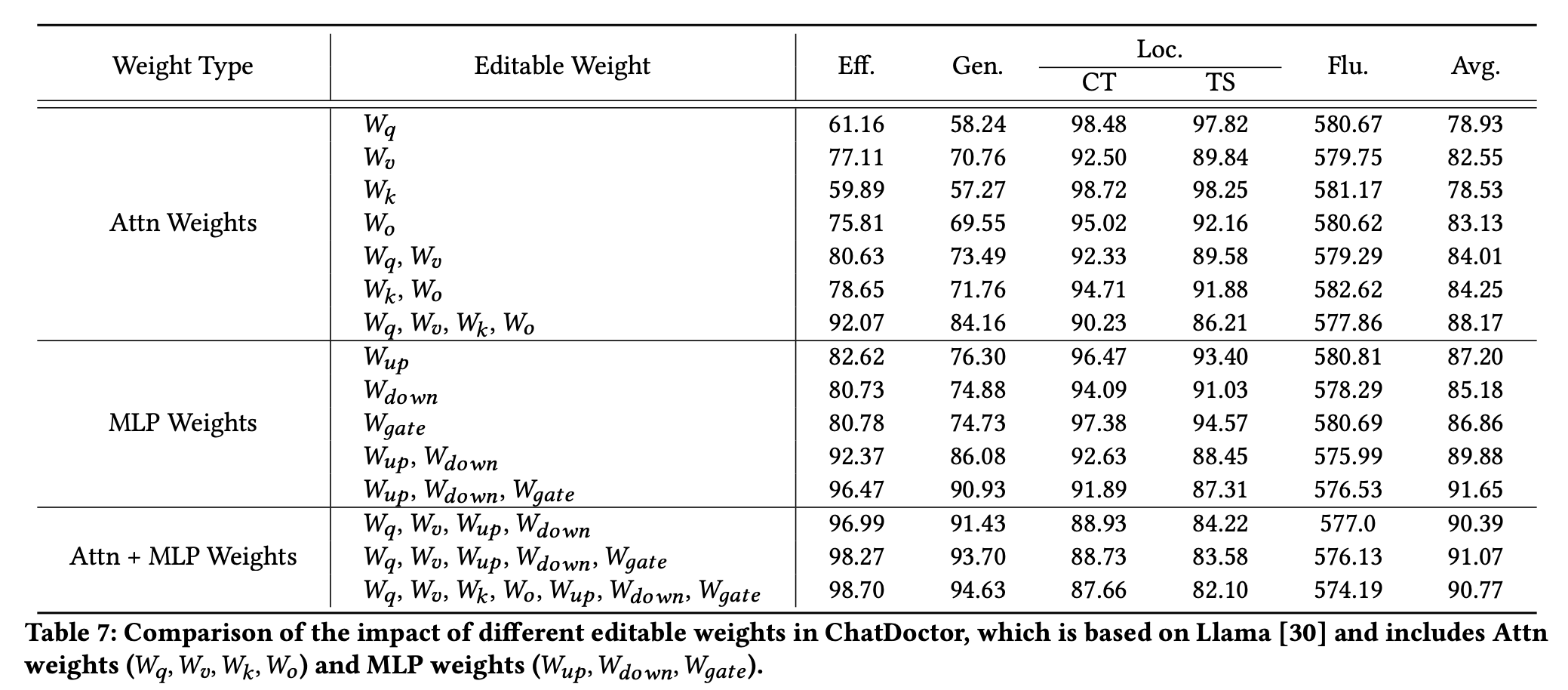
- Attn의 경우, query와 value를 edit할 때 더 나은 성능을 보여줌
- 그러나 query, value를 동시에 edit한다면 locality에서의 cost는 감수해야 함
* 모두 edit한다면 edit 성능이 계속 오르지만, locality는 떨어짐
- 그러나 query, value를 동시에 edit한다면 locality에서의 cost는 감수해야 함
- MLP의 경우에는 Up이 일관되게 우수한 성능
- 이는 up layer가 더 높은 지식을 유지할 수 있음을 의미
- 또한 mlp를 edit하는 것이 attn보다 더 나은 성능을 보여줌
- 일반적으로, 지식의 저장이 MLP로부터 이어진다는 이전 연구의 견해와 일치
- 둘을 함께 학습한다면 locality와 fluency가 영향을 받음
- 더 많은 adapter를 학습한다면 edit 성공률이 증가하지만, 기존 ability가 방해받을 수 있음을 의미
Case Study (RQ6)
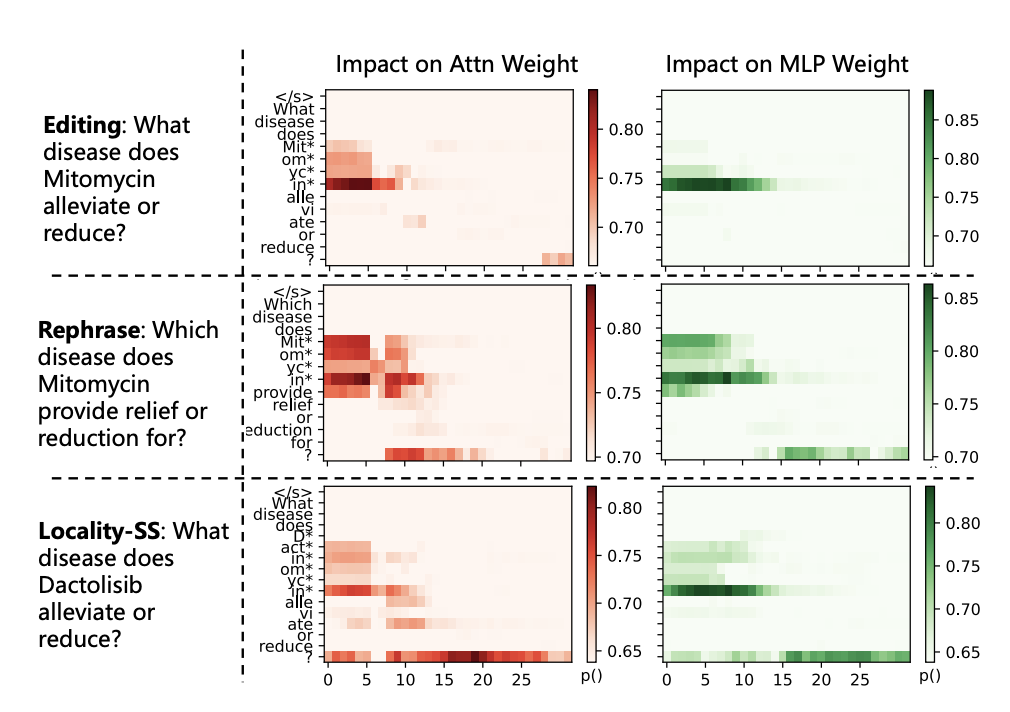
- Causal tracing의 사례
- edit과 rephrase input이 layer5-10에 강하게 연관되어 있음을 알 수 있음
- 관련 없는 지식의 경우, layer 15-20에 강하게 연관되어 있음
- 즉 MedLaSA가 유사한 지식을 비슷한 scale로 처리하고, 무관한 지식을 다른 scale로 처리할 수 있음을 의미
