Editing Large Language Models: Problems, Methods, and Opportunities (EMNLP 2023)
Paper Review
목록 보기
48/51

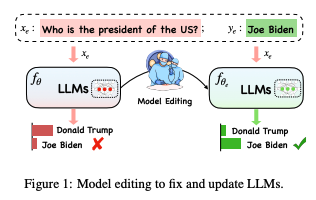
Introduction
- LLM은 놀랍지만 bug를 fix하는 데에는 아직 unexplored
- 세상이 변화함에 따라, LLM의 기존 지식을 수정하는 것은 crucial
- 기존 지식을 해치지 않는 선에서 최소한의 cost로 이루어져야 함
- 이게 바로 Knowledge Edit의 개념 - 다음 두 접근으로 나뉨
- 원래 파라미터를 변경하지 않는 접근
- 바람직하지 않은 출력을 유발하는 파라미터만 수정
- 본 연구는 문제를 확실히 정의하고, 각 방법론의 장점 및 단점을 분석하고자 함
- 체계적인 평가를 통해 각 KE 방법론의 효과에 대한 통찰을 제공하고자 함
Problem Definition
- 초기 베이스 모델에서, 다른 Input에는 영향을 미치지 않고 수정이 필요한 답변을 효율적으로 조정 하는 것
- 우리는 이 수정이 필요한 답변을 Editing scope이라고 부름
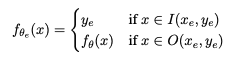
- Editing scope이내의 답변은 수정되어야 할 것이고, 나머지는 그대로여야 함
- 이 Editing Scope은 단순히 In-sample 뿐만 아니라 관련된 이웃들에 대한 정보 또한 수정될 수 있어야 함
- Edit 이후의 모델은 다음 3가지 속성을 만족해야 함
- Reliability: Target sample들이 잘 수정 되었는가 (Average Accuracy로 평가)
- Generalizaiton: 동등한 의미의 이웃들에게도 수정이 적용 되었는가 (문장의 재구성 등으로 이웃을 생성)
- Locality: Specificity로도 알려져 있으며, Edit이 국지적이어야 함을 의미 (외부의 지식은 수정되지 않아야 함)
Current Methods
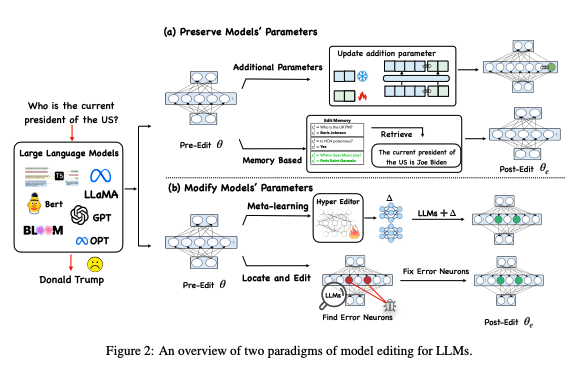
Methods for Preserving LLMs' Parameters
Memory-based Model
- Edit된 지식을 Memory에 모두 저장해둔 뒤, Retrieve하여 사실을 생성하도록 유도
- SERAC
- Scope classifier를 학습하여 새로운 input이 Edit된 사실에 적용될 likelihood를 계산하여 포함 될 경우 retrieve하도록 함
- In-Context 모델
- 모델 자체가 컨텍스트를 제공 받으면 해당 지식에 맞는 정보를 출력할 수 있도록 학습
- MemPrompt, IKE, MeLLo 등
Additional Parameters
- 언어 모델에 추가로 학습 가능한 파라미터를 도입
- T-Patcher
- 모델의 FFN 마지막 레이어의 하나의 패치를 추가하여 특정 잘못된 정보에서만 작동하도록 함
- CaliNet
- 여러 Edit case를 처리하기 위해 여러 패치를 추가
- GRACE
- Discrete codebook을 adapter로 추가하여, add 및 update를 통해 새로운 지식을 저장
Methods for Modifying LLM's Parameters
- 모델 파라미터의 일부를 Matrix를 통해 update
Locate-Then-Edit
- 특정 지식에 해당하는 Parameter를 포착한 뒤, 그 파라미터를 업데이트
- Knowledge Neuron (KN)
- 특정 지식에 해당하는 Key-value 쌍을 찾아낸 뒤, 이 파라미터를 업데이터
- ROME
- Causal meditation analysis (인과 매개 분석)을 통해 Edit해야 할 파라미터를 찾은 뒤, 해당 지식 뉴런을 수정하는 대신 전체 matrix를 update
- Edit을 선형 제약이 있는 Least square로 보고, Lagrange multiplier를 사용하여 solve
- MEMIT
- KN과 ROME은 한 번에 하나의 사실 관계만을 edit할 수 있음
- ROME의 설정을 확장하여 여러 사례를 동시에 Edit
- PMET
- MEMIT을 확장하여, Attention을 추가해 더 나은 성능을 확보
Meta-learning
- Hyper Network를 사용하여 LLM edit에 필요한 matrix를 학습
- Knowledge Editor (KE)
- Bi-LSTM으로 이루어진 hyper network를 학습하여 각 데이터 포인트에 대한 가중치 업데이트를 예측
- 이를 통해 타겟 지식을 edit하면서, 다른 지식을 방해하지 않는 제약 최적화를 수행
- 그러나 LLM에 적용할 때에는 실패할 경우가 종종 생김
- Model Editor Networks with Gradient Decomposition (MEND)
- 앞서 말한 문제를 해결하기 위해 등장
- Fine-tuned LLM의 Gradient를 low-rank decomposition하여 변환하는 방법을 학습
- 기존 보다 높은 성능
Preliminary Experiments
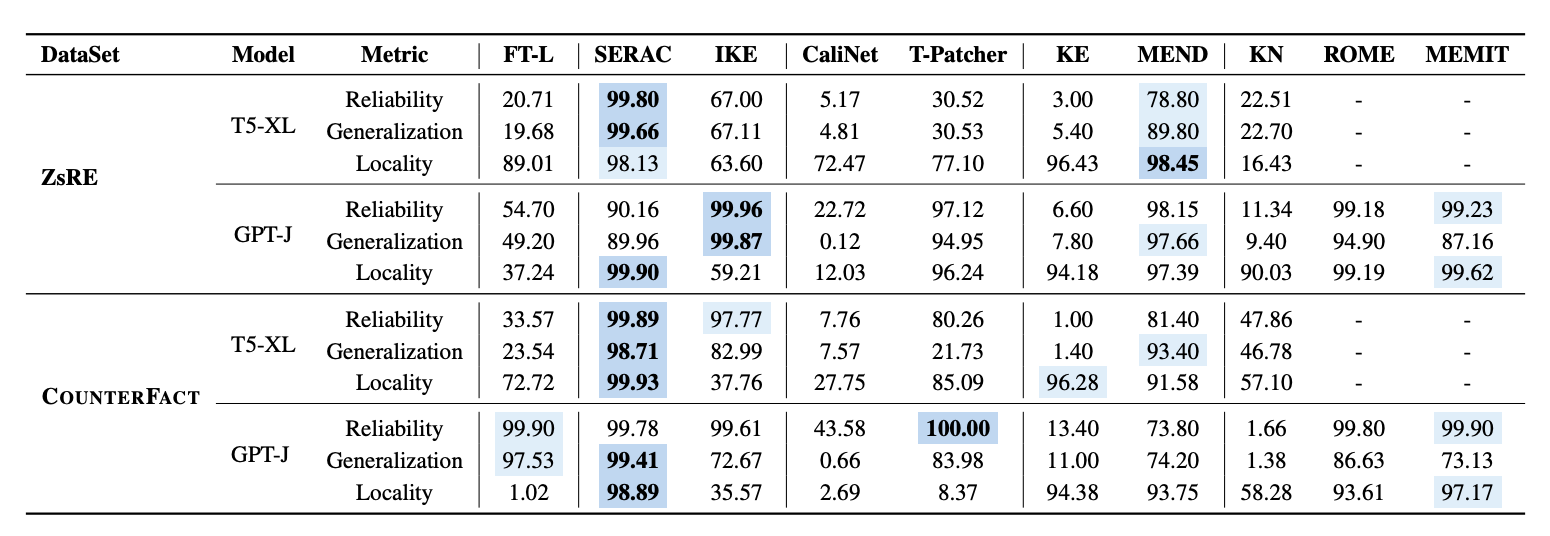
- 기존 데이터셋 및 연구를 기반으로 comparison baseline으로 선정
Experimental Setting
- ZsRE와 COUNTERFACT를 사용
- 기존 연구는 BERT와 같은 small model에 적용되었음
- T5-XL(3B), OPT-J(6B) 등 거대한 모델을 통해 성능 확인 (각각은 encoder-decoder구조와 decoder only 구조를 대표)
- 모델 update를 위한 기본적인 approach인 fine-tuning의 경우 ROME이 식별한 Layer에 대해 파인튜닝 하였고, 이를 FT-L로 표기
Experiment Results
Basic Model
- SERAC와 ROME이 우수한 성능
- MEMIT은 generalization에서 부족하지만, reliabilty, locality에서 높은 성능
- KE, CaliNET, KN은 작은 모델에서는 acceptable 한 반면, Large model에서는 낮은 성능
- MEND는 좋은 성능을 보이지만 SERAC과 ROME 만큼 인상적이지 못함
- T-Patcher
- T5에서는 generalizaiton이 아쉬움
- GPT-J에서는 locality가 아쉬움
- 이러한 불안정성은 모델 아키텍쳐에 기인하며, T-patcher는 마지막 디코더 레이어에 뉴런을 추가하는데, Encoder-decoder 구조인 T5는 이러한 점을 잘 대응함
- 인코더는 이전 지식을 보유하고 있기에 locality(기존 지식을 방해하지 않는가)는 잘 작동하지만, 이 때문에 generalizaiton이 아쉬워 짐
- FT-L은 대체적으로 낮은 성능이며, COUNTERFACT + GPT-J의 경우 ROME과 comparable
- 그러나 locality가 낮아져 기존 지식이 침해받을 수 있음을 의미함
- IKE는 Reliability는 좋으나, 나머지가 아쉬움
- In-context 방법론은 context meditation failure 문제 (컨텍스트 조정 실패)를 겪을 수 있기 때문
- 사전 훈련된 언어 모델이 프롬프트와 일치하는 텍스트를 일관되지 못하게 생성하는 현상
- In-context 방법론은 context meditation failure 문제 (컨텍스트 조정 실패)를 겪을 수 있기 때문
Model Scailing
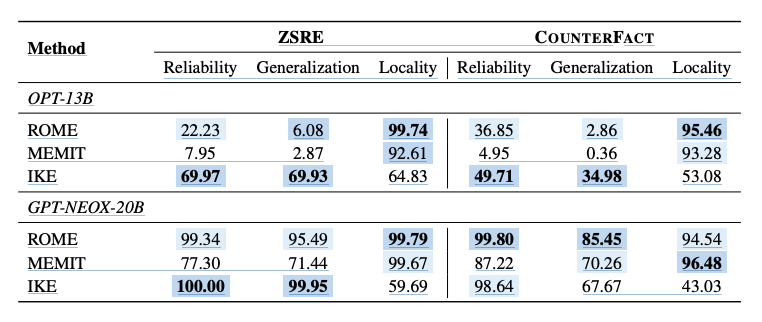
- IKE, ROME, MEMIT를 OPT-13B와 GPT-NEOX-20B로 실험
- ROME, MEMIT
- GPT-NEOX-20B에서는 좋은 성능을 보였으나, OPT-13B에서는 성능이 낮음
- 두 방법론 모두 역행렬 연산에 의존하나, OPT의 경우 non-invertible한 경우가 발생하여 생긴 것으로 보임
- 특히 MEMIT은 multi-layer matrix computation에 의존하기에 성능 저하가 더 심함
- IKE
- 모델 성능 자체가 In-context 학습 능력에 영향을 받음
- OPT가 GPT보다 낮은 이유는, 이러한 차이에서 기인되었을 확률이 높음
Batch Editing

- 여러 연구가 단일 사실, 혹은 적은 사실만을 edit하는데 집중
- 그러나 실제로는 여러 지식을 동시에 수정해야 하는 경우가 많음
- Figure에 이러한 실험 결과를 제시
- MEMIT은 대규모로 지식을 edit할 수 있으며, 최소한의 시간 및 메모리 비용으로 수천개의 동시 edit 가능
- Reliability 및 Genelization은 1000개 까지 견고하지만, Locality는 이 수준에서 감소
- FT-L, SERAC, MEND는 batch edit을 지원하지만 더 많은 사례를 처리하려면 많은 메모리가 요구됨
- SERAC는 100까지 완벽히 수행 가능
- MEND, FT-L은 batch edit에서 성능이 그리 좋지 않으며, edit 수 증가에 따라 모델 성능이 급격히 감소
Sequential Editing
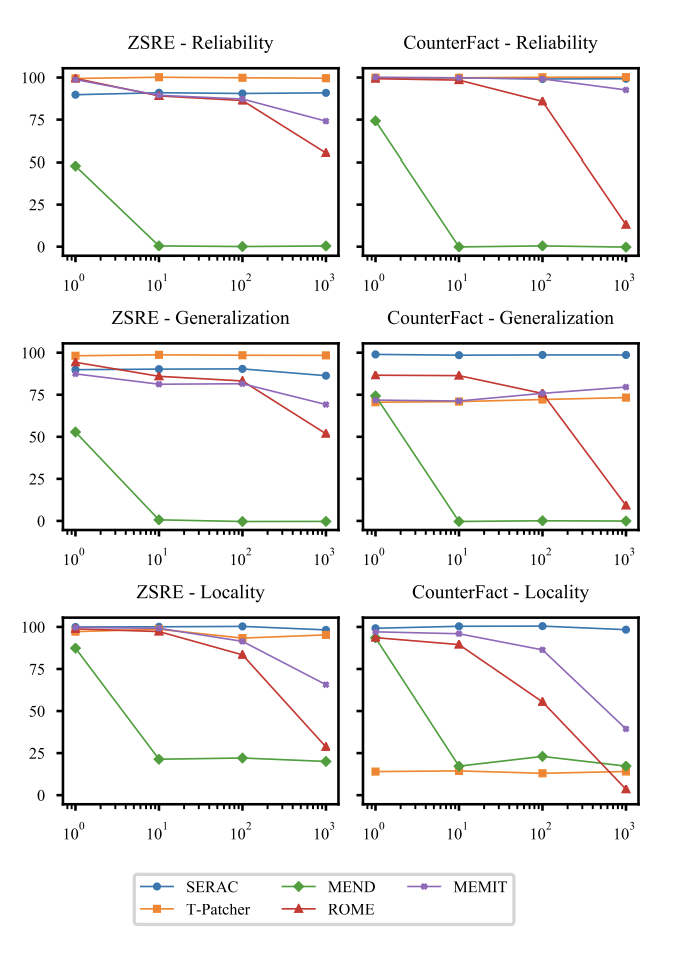
- 기존 Edit은 단일 지식 update 이후 평가 및 업데이트를 롤백하여 다시 edit을 진행
- 실제 시나리오에서는 이전 사항을 유지하며 지속적으로 update해야 함
- 이러한 연속적 edit은 매우 crucial
- 단일 edit 성능이 높은 모델을 선정해 이를 평가
- SERAC, T-Patcher 등 모델 파라미터를 freeze하는 경우 일반적으로 안정된 성능을 보임
- 파라미터 자체를 수정하는 경우 급격한 성능 저하를 보임
- ROME은 100개 sample에서 성능이 저하
- MEMIT 또한 감소하지만, ROME보다는 나은 성능
- MEND는 10개 이상부터 성능 저하
- Editing이 계속되면서, 원래 parameter에서 많이 변화되기 때문에, 최적 성능을 발휘하지 못함
Comprehensive Study
- 이전 평가 지표는 model을 fuly assess하지 못함
- 우리는 Portability, Locality, Efficiency에 대한 새로운 지표를 제시
Portability - Robust Generalization
- 여러 연구는 back translation을 통해 생성된 sample로 generalization을 평가
- 그러나 이러한 문장은 단순한 어휘 변경을 포함하며, 실질적인 factual modification은 반영하지 못함
- 그러나 edit의 영향이 실제 application에서 적용될 수 있을지 평가해야 함
- 따라서 우리는 edit의 결과가 실질적인 application으로 적용 될 수 있는지 평가하는 지표인 portability를 제안
* 이는 견고한 generalization이며, 다음 세가지 측면을 고려함
Subject Replace
- 대부분 패러프레이즈 된 문장은 주어를 설명은 유지하며, 관계를 rephrase함
- 질문의 주어를 별칭 혹은 동의어로 교체하여 generalization을 테스트
- 이는 모델이 edit된 속성을 동일한 주제에 대한 다른 설명으로 일반화 할 수 있을지 평가
Reversed Relation
- 주제와 관계의 대상이 edit될 때, entity의 속성도 변경됨
- 대상 entity의 속성도 변경 되었는지 역 질문을 통해 테스트
One-hop
- 수정된 지식은 다운스트림 작업에 사용될 수 있어야 함
- ex) "Watts humphrey는 어느 학교에 다녔는가?" 라는 질문에 대한 답을 "트리니티 칼리지"에서 "미시간 대학교"로 변경했을 때
- "Watts humphrey가 대학 시절 살았던 도시는 어디인가?"라는 질문의 답은 "미시간 주"로 변경되어야 함
- 이를 평가하기 위해 추론 데이터셋을 구성
- ZsRE에 새로운 부분 지식을 통합하여 dataset 구성 및 평가
Dataset Construction
- One-hop dataset의 경우 주제 S에 대한 답변을 o에서 new_o로 변경
- GPT-4로 하여금 (new_o, r, new_o_answer)의 삼중 관계를 생성하도록 요청 및 삼중 관계와 S에 기반하여 질답을 생성하도록 함
- 모델이 이 새로운 질문에 대답할 수 있다면, 모델은 삼중 관계에 대한 사전 지식을 가지고 있음을 의미
- new_o, r을 기반으로 new_o_answer를 예측하도록 요청
- 예측에 성공한다면 사전 지식이 있다고 판정
- 마지막으로 human이 삼중 관계의 정확성 및 질문의 유창성 검증
Result
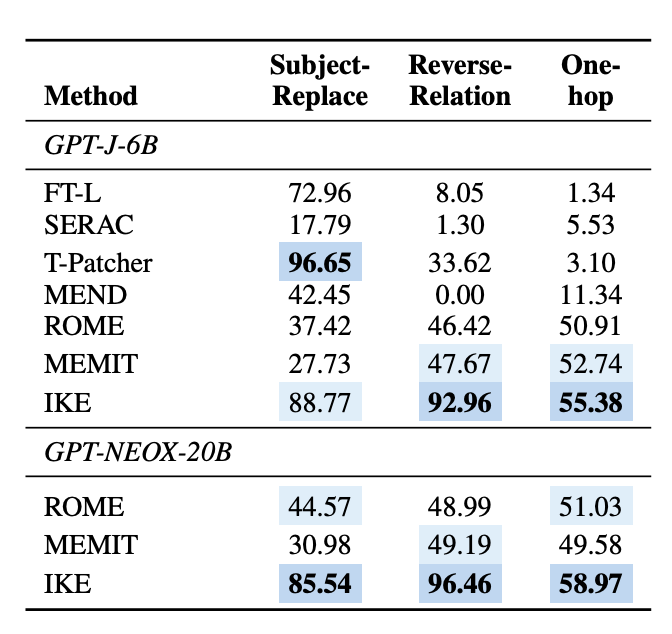
- 현재의 editing 방법론이 portability에 대해 미흡
- 특히 SERAC은 기존 탁월한 성능 대비 모두 저하된 성능
- Subject-Replace의 경우, FT-L, IKE, T-Patcher가 높은 성능
- Reverse-Relation의 경우, IKE가 독보적인 성능
- 다른 방법론의 경우, 주제 엔티티의 성능을 변경하면서도 객체 엔티티는 영향을 받지 않음
- One-hop의 경우 대부분 모델이 수정된 지식을 downstream task로 잘 전환하지 못함
- 그러나 ROME, MEMIT, IKE는 비교적 우수한 성능
- 즉 이들은 원래 case를 edit할 뿐만 아니라 일부 전이할 수 있음
- 요악하자면, IKE가 protability에서 우수한 성능을 보임
Locality - Side Effect of Model Editing
- 기존 COUNTERFACT와 ZsRE는 국지성을 다양한 관점에서 평가
- COUNTERFACT의 경우 삼중 관계를 사용
- ZsRE의 경우 Natural Question 데이터셋에서 질문을 사용
- 그러나 T-Patcher등의 모델은 두 데이터셋에서 성능 차이가 심함
- 이는 edit의 영향이 모델 측면에서 다차원적이며, 이를 완전히 이해하기 위해서는 새로운 평가 지표가 필요하다는 것을 의미
Other Relations
- Meng et al은 본질(essence)의 개념을 도입했지만, 이를 명시적으로 평가하지는 않음
- edit 이후, 업데이트된 주제의 다른 속성은 변화되지 않아야 함
Distract Neighbourhood
- 관련 연구에 따르면, edit된 지식에 과적합되어 무관한 입력에도 edit된 지식을 생성할 수 있음
- 이를 평가하도록 함
Other Tasks
- 모델 editing이 다른 Task에 부정적 영향을 미칠 수 있는지 평가
Result
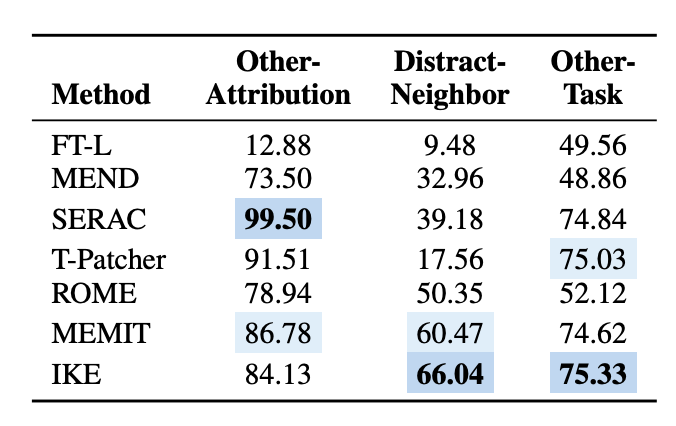
- 주목할만한 점은, 현재 편집 방법론이 Other Relation에 뛰어난 성능
- 그러나 Distract Neighbor에는 대체로 낮은 성능을 보임
- IKE는 예외적으로 준수한 성능!
- 이는 Edit된 사실이 입력 전에 연결되도록 요구하는 특성 때문으로 보임
- Common-sense reasoning의 경우 파라미터를 유지하는 방법론은 대체로 좋은 성능
- 반면 파라미터 수정 방법론은 낮은 성능을 보임
- MEMIT은 예외적으로 뛰어난 국지성을 보여줌
- 종합적으로, 파라미터를 유지하는 방법론이 Locality에 좋은 영향을 보이나 파라미터를 수정하는 방법론은 잠재적인 위협이 존재함을 의미
- MEMIT은 이에 예외적이며, 추가적인 연구가 필요함
Efficiency
- Model Editing은 모델 성능 저하 없이, 시간과 메모리 비용을 최소화 해야함
Time Analysis
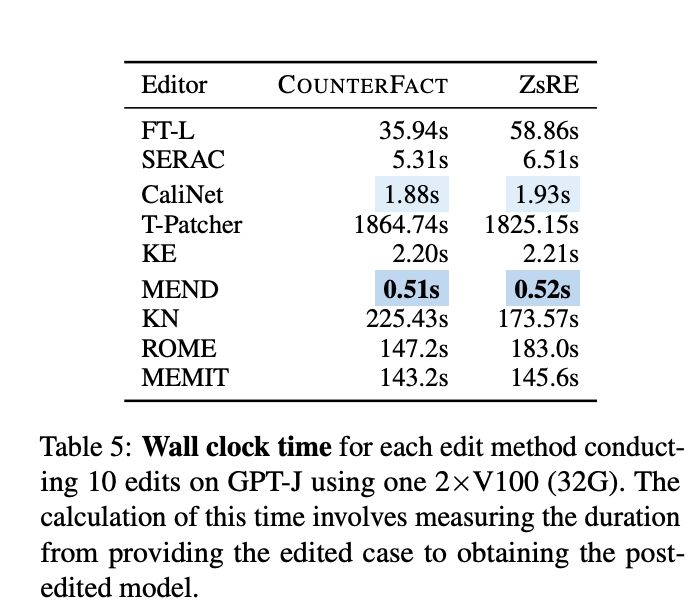
- 본 테이블은 시간 cost를 보여줌
- Hypernetwork 훈련 이후에는, KE와 MEND가 상당히 빠른 속도
- SERAC 또한 훈련 이후에는 신속한 edit이 가능
- 그러나 이들은 추가적인 훈련 및 별도 데이터셋이 필요하기에 확실히 시간을 측정할 수 없음
- 특히 MEND는 7시간 이상, SERAC는 36시간 이상이 소요
- 그러나 이들은 추가적인 훈련 및 별도 데이터셋이 필요하기에 확실히 시간을 측정할 수 없음
- 또한, ROME - MEMIT의 경우 Wikitext에 대해 covariance를 계산하는 점에서 computation이 수 일, 수시간이 걸림
- 반면 T-patcher, KN, CaliNET의 경우는 사전 계산 및 훈련이 필요 없기 때문에 훨씬 빠름
- 다만 KN, CaliNet은 Large Model에서 성능이 떨어지며, T-Patcher는 각 neuron을 계산하기에 비교적 느림
Memory Analysis
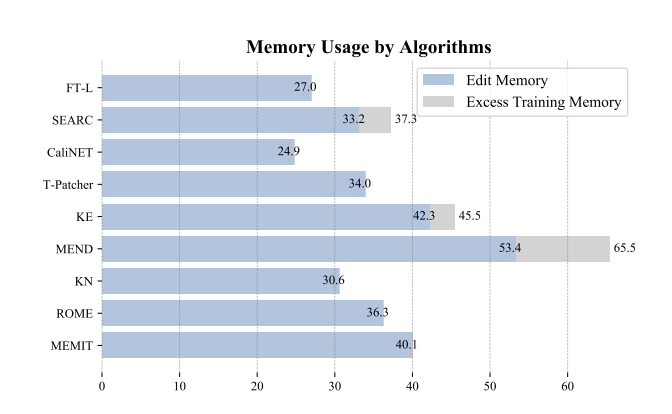
- 대부분이 유사한 Memory를 사용하나, MEND의 경우 훈련에 60GB 이상이 필요
- MEND, SERAC은 추가적인 훈련을 도입해 Overhead를 유발
- 이는 Large Model에서 효율적인 Edit 방법론이 필요함을 시사
- MEND는 강력한 성능을 제공하지만, 이는 높은 메모리 및 시간 소요를 감수해야 함
My Conclusion
Knowledge Edit을 Application에 적용하려면 중요하다고 생각되는 Property의 순위를 기반으로 Weighted Average를 구해서 가장 높은 걸 선택하는 것이 맞을 듯?
내가 적용하려고 하는 Task는 대량의 Knowledge를 수정해야 하고, 관련 지식도 모두 수정되어야 하므로 Memory-based approach보단 다른걸 우선해야 할듯 (비록 Locality가 조금 깨지더라도)
