Evaluating Large Language Models as Generative User Simulators for Conversational Recommendation (NAACL 2024)
Paper Review
목록 보기
45/51

Introduction
- Conversation을 통한 추천은 이제 일상적
- CRS는 이를 target한 task
- Core challenge는 evaluation
- 이상적으로는 real user의 interaction이 필요하지만, 이는 cost가 매우 높음
- Offline evaluation은 non-interactive mode로 single-turn assessments만이 가능
- Binary response, role-playing game 등의 user simulator가 존재했지만, 이는 generative가 아닌 static이라는 한계를 뛰어넘지 못함
- 최근 LLM이 human behavior를 잘 모방할 수 있다는 연구가 등장
- Profile과 memory를 통해 LLM은 generative할 수 있음
- RS에서도 user simulator가 작동하는 것이 알려짐
- simulator가 얼마나 human을 represent 하는지가 key point
- General human behavior에 대한 evaluation protocol은 존재하지만, context of recommendation에 대한 protocol은 존재하지 않음
- simulator가 얼마나 human을 represent 하는지가 key point
- CRS에서 user simulator는 general-purpose human simulator와 다름
- goal은 simulate population of users, with distinct preferences
- Real user preference는 파편화, 다양화, 개인의 특성 및 interaction history, 상황에 따라 다른 형태를 띔
- 따라서 여타 domain의 evaluation protocol은 CRS에 적합하지 않음
- 우리의 new evaluation protocol은 LLM-based simulator가 CRS에서 user를 represent하게 함
- 새로운 challenge가 등장
- Demographic과 같은 input을 mapping할 수 있는 GT output의 부재
- Outcome은 free form text로 이전 연구와 같이 수치화하여 비교할 수 없음
- 무한한 가능성의 conversation 방향은 Ground Truth의 의미를 모호하게 함
- 우리는 위 challenge를 해결하기 위해 user simulator가 증명해야 하는 5가지 independent task로 decompose
- 위 task가 simulator가 perfect함을 보증할 수 없지만, 오히려 일종의 distortion이 존재함을 밝힘
- 우리는 simulator가 popular item을 favor하고, human preference와 little correlate하며 lack of personalization 함과 동시에 incoherent feedback을 제공함을 발견
- 그와 동시에 이 gap을 줄일 method를 제안
- 이를 통해 더 realistic한 user simulator를 future research에 활용할 수 있을 것
Evaluation Tasks
ItemTalk:
- Choosing items to talk about
- User가 추천에 대해 대화할 때, 그들은 item을 mention
- Context는 매우 다양
- Request similar items
- express preference on certain items
- simply chat about item
- 우리는 simulator와 real user가 mention한 item의 dstn을 비교할 것
BinPref
- Expressing binary preference
- answer는 binary가 아니어도 되지만, 원할한 비교를 위해 답을 binary로 고정
OpenPref
- Expressing open-ended preference
- Open-ended utterence는 유저가 detail한 preference를 표현하게 함
- Movie의 casting은 좋았지만, plot은 심심하였음 등
- 우리는 siumulator가 aspect of item을 잘 표현하는지와 함께 그 aspect와 preference가 real user와 유사한 지 조사
RecRequest
- Requesting Recommendations
- 추천에 대한 요구는 verbalized됨
- Vastness of taste와 Circumstance로 request는 매우 variety
- Simulator가 생성한 요청이 real user처럼 다양한 지 실험
Feedback
- Giving feedback
- CRS를 평가하기 위해, simulator는 final feedback을 제공하여야 함
- 만약 추천과 설명이 요청 및 선호와 관련이 있다면, accept하여야 함
- Simulator가 feedback generation에서 coherent pattern을 보이는 지를 조사
Methods
- Simulator는 black-box
* free-form NL을 input으로 language를 생성 - 앞서 말했듯, 우리는 user의 population을 고려할 것
- 단지 fixed pool of user를 replicate하는 것이 아닌, new group of user를 생성하는 것
- Task는 zero-shot 이어야 하며, simulator는 train되어 있지 않고 evaluation metric에 대해 무지한 상태여야 함
- 이를 통해 simulator가 generic situation에 잘 perform하도록 함
Dataset
- 우리는 real-world dataset을 통해 simulator와 human output을 compare
ReDial
- Movie seeker와 recommender로 role-play 한 dataset
- seeker side를 사용
- User는 request를 post하고 other user가 comment
MovieLens
- Movie rating dataset
IMDB
- IMDB의 movie review dataset
Baselines
- prompt based simulators (GPT3.5, GPT4, text-davinci-003)
Vanilla LLM
- runs without any special prompts
- relise solely on the inherent variability of LLM
DI
- Demographic Information
- Gender와 Racial diversity를 부여
- Mr, Ms 등 5 racial group에서 가장 흔한 500 surname을 부여
DI+PP
- Pickiness Personality
- 인구 통계에 성격 특성을 추가
- 각 simulator에게 not picky, moderately picky, extremely picky를 부여
IH
- Interaction history
- 상호작용 이력을 일부 부여하고, user처럼 act하도록 함
Execution and evaluation
- ItemTalk prompt
- Mentioned Item의 dstn을 비교
- Diversity of dstn은 entropy로 summarize
- BinPref prompt
- Simulator가 Movie에 대해 binary preference를 답하도록 요구
- Frequent와 infreqeunt, random sample로 나누어서 진행
- average rating과 positive rate를 비교
- OpenPref prompt
- Simulator가 movie에 대한 설명을 하도록 요구
- PyABSA를 통해 감정 분석 후, human과 simulator의 dstn을 비교
- RecRequest prompt
- set of item에 대한 추천을 requent하도록 요구
- Item과 target length는 reddit dataset을 기반
- Diversity와 Granularity를 type-token ratio로 비교
- Word2Vec 및 SBERT로 Embedding을 추출 후 Cosine diversity of embedding을 비교
- Feedback prompt
- Request-Recommendation pair를 수집
- 본 comment의 Recommendation 일 경우 Pos, random comment일 경우 Neg
- 2개의 sub task
- Simulator는 Pair를 보고 Accept/Reject를 결정
- Simulator는 positive recommendation과 negative recommendation 중 어떤 것을 더 선호하는지 선택
- Simulator는 Pair를 보고 Accept/Reject를 결정
- Simulator는 positive recommendation을 더 선호 해야만 함
Experiments
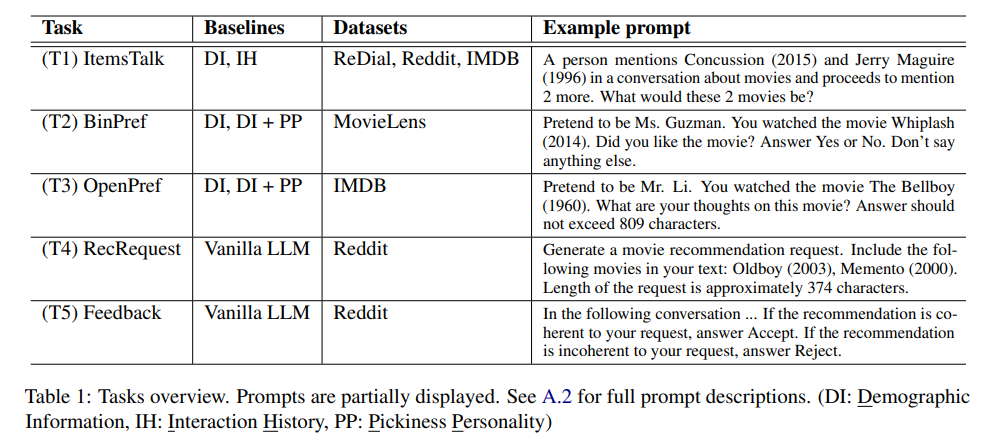
Finding 1: Simulators mention less diverse items compared to real users
- ItemTalk에서 simulator는 Pop item에 heavily skewed 되어 있음
Finding 2: Prompting with interaction history enhances item diversity
- IH는 diversity에 효과적임
- 특히 Reddit, IMDB 기반 IH는 human ReDial의 다양성을 넘기는 수준
- 즉 IH는 generate diverse item의 strong condition
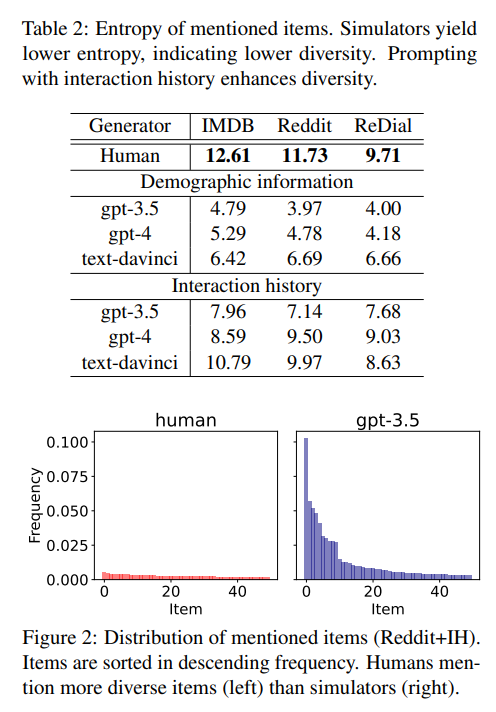
Finding 3: Simulators may poorly represent real user preferences
- BinPref
- Average rating을 decrease한 plot과 simulator의 preference rate는 GPT4+DI+PP를 제외하고 모두 동 떨어짐
- 특히 Higher item frequency (item에 대해 얼마나 잘 아는지)는 better preference alignment에 도움을 주지 않음 (더 자주 학습되었음에도 불구하고)
Finding 4: Adding pickiness personality improves preference alignment
- Picky (까다로운) simulator는 strong correlation을 보임
- 이는 picky simulator는 low-rated movie를 식별할 수 있다는 것
- Pickiness가 없는 경우, correlation은 low to moderate
- 특히 text-davinci-003 + DI의 경우 모든 answer는 yes
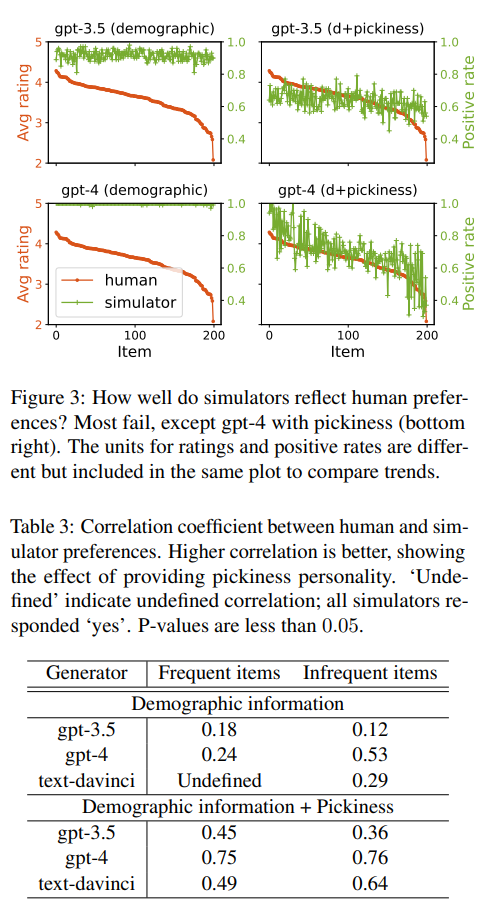
Finding 5: Simulators express preferences differently from real users. Model choice and prompting may mitigate the difference
- OpenPref
- 첫 째로, simulator는 human보다 더욱 sentiment-associated aspect를 생성
- User는 explicit aspect보다 미묘한 표현을 하는 경우가 잦음
- 둘 째로, simulator는 lower aspect entropy를 가짐
- 이는 그들이 언급할 aspect가 예측 가능하다는 뜻 (동일 혹은 유사한 aspect를 반복적으로 mention)
- 마지막으로 Simulator는 Picky user가 아닐 때, positive sentiment에 bias되어 있음
- 이는 low sentiment entropy의 이유
- GPT4+DI+PP는 human과 근접
- 따라서 model choice와 prompting strategie는 simulator 선택에서 중요함
Finding 6: Simulators struggle to generate a diverse pool of personalized requests


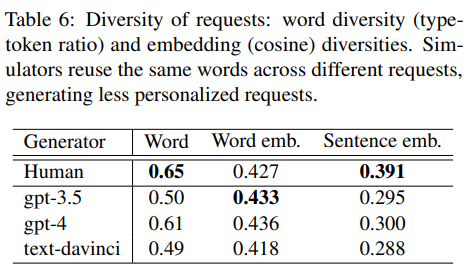
- RecRequest
- Simulator는 user보다 개인화된 추천 요구를 생성하는데 한계를 보임
- Request diversity에서 GPT4(most diverse)는 23% less diverse than human
- User와 달리 simulator는 short text로 specific request를 생성하는데 어려움이 있음
- 흥미롭게도, simulator의 word diversity는 낮지만 word embedding diversity는 높음
- 다양한 semantic의 vocab을 사용하지만, reuse 한다는 것
- 'gripping', 'mind-bending', 'compelling', 'keeps me on the edge of my seat' 등 general한 표현을 주로 사용하는 것
- 반면 Human은 finergrained preference를 통해 specific criterion을 충족하는 요청을 함
- 결론적으로, low diversity of request는 generality가 원인으로 보임
- Human이 free to be more personal, diverse in the population 할 수 있음과 달리, LLM은 일반적인 request를 생성하는 것
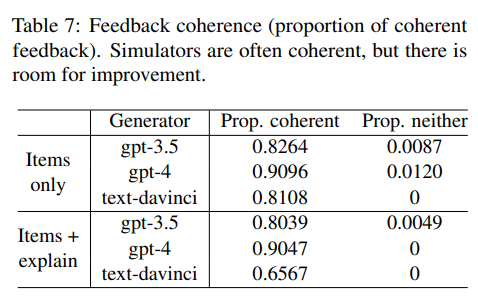
Finding 7: While Simulators often give coherent feedback, there is room for improvement
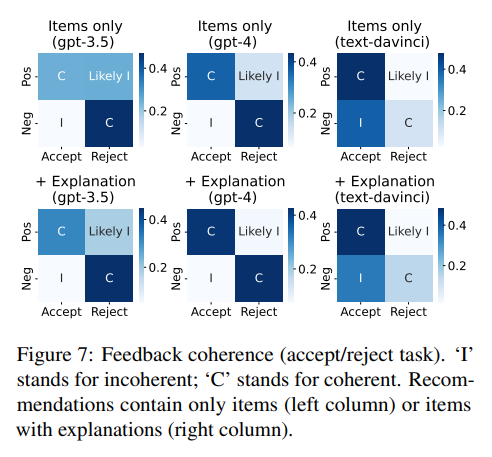
- Feedback
- Accept/Reject task에서 Positive recommendation을 accept하거나, negative recommendation을 reject하는 것은 coherent
* 그 반대는 incoherent이나, positive recommendation을 reject하는 것은 controversial- User는 external reason을 통해 relevant recommendation을 reject할 수 있음
- 우리는 이를 likely incoherent로 명명 후 clearer case에 집중함
- Simulator는 대체로 coherent하나, 때때로 incoherent
- 특히 text-davinci-003의 경우 optimistic feedback으로 편향되어 있음 (recommendation이 irrelevant인 경우에도 accept)
- Comparison task에서, simulator가 둘 다 선호하지 않는다고 답한 경우는 제외한 뒤 평가
- 대체적으로 coherent하며, neither은 무시할만한 수준
- 다만 model에 따라 coherent가 상이하고, 설명이 존재할 경우 less coherent해짐
- explanation이 negative recommendation의 persuasiveness를 강화하기에 tricky하게 작용될 수 있음 (possible reason)
Finding 8: Simulators may not capture subtle nuances in requests, and thus reject relevant recommendations

- Simulator에게 feedback의 이유를 질문
- Response는 타당하며, 사실을 기초로한 답변임
- 다만 Incoherence는 미묘한 뉘앙스를 파악하지 못해 발생
- Figure에서 simulator는 Nightcrawler가 not 'about' a loner main character이기에 reject
- 그러나 user는 loner main character가 포함된 영화를 요청
