
Introduction
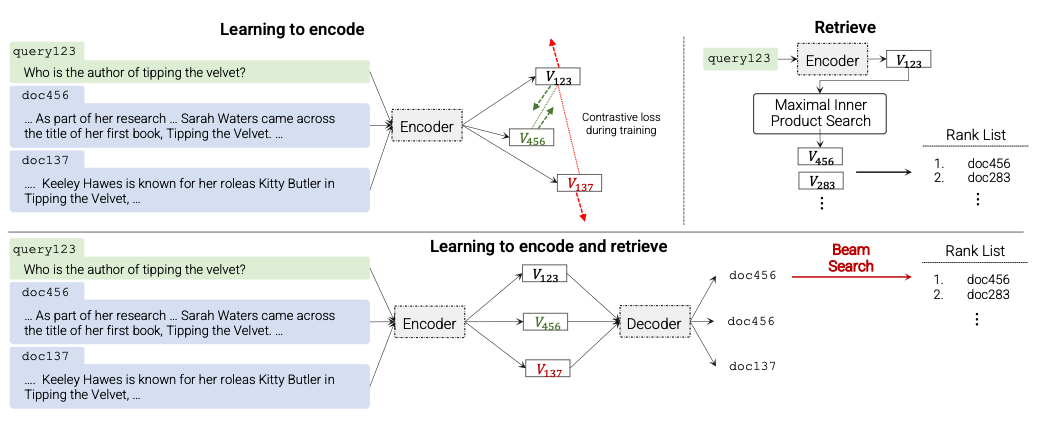
- Information retrieval (IR) system은 query를 받아 relevant한 document의 ID (docids)를 ranked list로 제공하는 것
- 기존 알고리즘에서 dual encoder(DE)를 사용한 모델이 현재까지 SOTA
- 이 paper는 seq2seq기반 architecture를 통해 큰 성능 향상을 이루어냈으며, 이를 differentiable search index (DSI)라고 명명
- 이 architecture에서 모든 corpus의 정보는 parameter로 encoding 됨
- 추론 시, model은 text query 를 input으로 받아 docid 를 output으로 생성
- 필요 시, beam search로 ranked list를 추출할 수 있음
- 성능 뿐만 아니라, DSI architecture는 DE보다 간소화 된 구조
- 우리는 다음과 같은 variation의 DSI architecture를 탐구
- Document representation
- naive representation과 bag of word representaion
- Docid representation
- 단순 text string의 integer와 unstructured atomic docids
- Indexing
- docid와 document를 matching (이해시키는) 방법론
- Effects of model and corpus size
- Large LM, Large corpus에서의 실험
- Document representation
Differentiable Search Index
- Core Idea는 기존 multi-stage retrieve-then-rank pipeline을 하나의 neural model로 fully parameterize하는 것
- 이를 위해, 두 기본적인 mode에 적용이 필요
- Indexing
- DSI model은 docid 와 document 가 대응됨을 이해해야 함
- Retrieval
- Input query를 받았을 때, DSI model은 candidate docids를 return할 수 있어야 함
Indexing Strategies
- 다양한 indexing strategies를 실험
Indexing Method
Inputs2Target
- Document로부터 docid를 generate
- docid가 loss function 근처에 있는 것이 advantage
- 우리의 최종적인 목적은 docid를 generate하는 것인데, 이와 비슷한 formular인 것 또한 advantage
- 그러나, document token은 noise가 없기에 general pre-training이 없다는 것이 weakness
Target2Inputs
- 위와 반대로, docid를 통해 autoregressive하게 document를 생성
Bidirectional
- 둘 다 해버리기
Span Corruption
- docid를 prefix로 document token과 concatenate하여 randomly masking 해 objective 생성
- general pre-training during indexing (1)과 achieving a good balance of docids as denosing targets and inputs (2)의 advantages가 존재
Document Representation Strategies
- 이전 chapter에서 how to index를 했다면, 이번에는 what to index (i.e., how to represent )
Direct Indexing
- first token을 가져와서 사용
Set Indexing
- document에는 중복 단어 혹은 불용어가 포함될 수 있기에, python set 연산을 통해 이를 정제 후 direct indexing
Inverted Index
- chunked document를 mapping (entire document를 한번에 말고)
Representing Docids for Retrieval
- Decoding될 Docids를 어떻게 표현할까
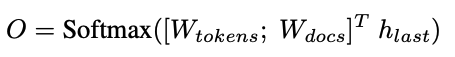
Unstructured Atomic Identifiers
- 가장 naive한 way는 임의(random) unique integer로 표현하는 것
- 우리는 이를 unstructured atomic identifier라고 명명
- 이 때 decoding formulation은 identifier의 차원의 logit distribution
- 위 figure와 같은 형태의 수식으로 표현 됨 (;는 row-wise concatenate)
- top-k document를 얻으려면, logit을 sorting한 뒤 추출
Naively Structured String Identifiers
- unique identifier를 단순 string으로 취급
- large softmax output space를 생략할 수 있음
- each individual docid의 embedding을 학습할 필요 또한 없음
- Beam search를 통해 top-k ranking을 추출
- docid space를 모두 고려하여 각 문서의 likelihood를 얻을 수 있지만, beam search로 근사하는 것과 유사한 결과
Semantically Structured Identifiers
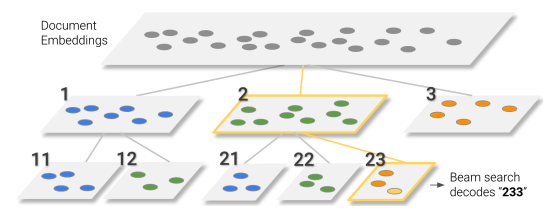

- 임의로 identifier를 구성하는 것이 아닌, 의미론적으로 구성
- 다음 두 특성을 고려해야 함
- Identifier가 Semantic information을 반영해야 함
- Decoding 이후 search space가 구조적으로 응축되어야 함
- 우리는 비지도적인 전처리 step을 통해 구조화
- future work로 end-to-end manner를 남겨둠
- 계층적 클러스터링을 통해 각 cluster 번호를 순차적으로 할당 (접두사)
- 임의 정수 C 이상의 document가 cluster에 할당될 경우, 추가적으로 클러스터링
- C-1개의 document가 만족될 경우 번호를 접미사로 할당
Training and Optimization
- Cross entropy loss, Teacher forcing 사용
- 두 가지 전략
- Memorization (Index와 document mapping) 이후 fine tuning (query를 통해 index 생성)
- 둘을 한번에 진행
- 이 경우 T5-style co-training (task prompt를 통해 differntiate)
- 후자가 더 우수한 성능, 따라서 default strategy로 선택
- 이는 기존 multi-task setup과 차이를 보임
- 기존 setup은 각 task가 학습될 수록 서로의 task에게 좋은 영향을 미침
- 우리의 setup은 indexing (memorization) 이 필수적으로 학습 되어야만 후의 task가 meaningful
- 이는 unique하고 기존 ML community에서 unexplorede된 challenge
Experiments
Dataset
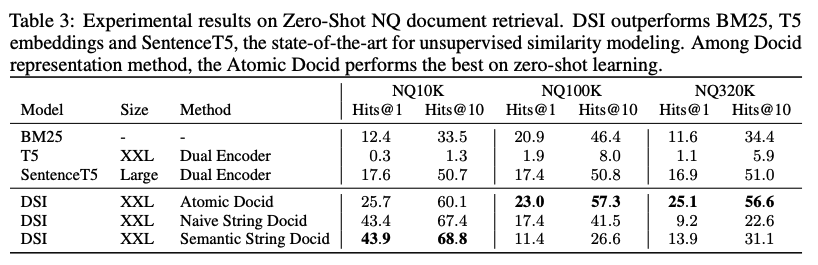
- Natural Question (NQ) dataset에서 진행
- Question과 연관된 document(wikipedia article) pair로 구성
- 기존 NQ dataset을 10K, 100K, 320K(기존 데이터셋)을 나누어서 실험
Metric
- Hit@K
Implementation Details
- T5 사용
- unstructured atomic identifier는 indexing stage에만 finetuned
- 다양한 ablation을 통해 위의 setting중 가장 성능이 우수한 Direct Indexing과 Inputs2Target starategy를 사용하여 실험
Baselines
- Supervised는 DE와, Zero-shot은 DE, BM25와 비교
Experimental Results
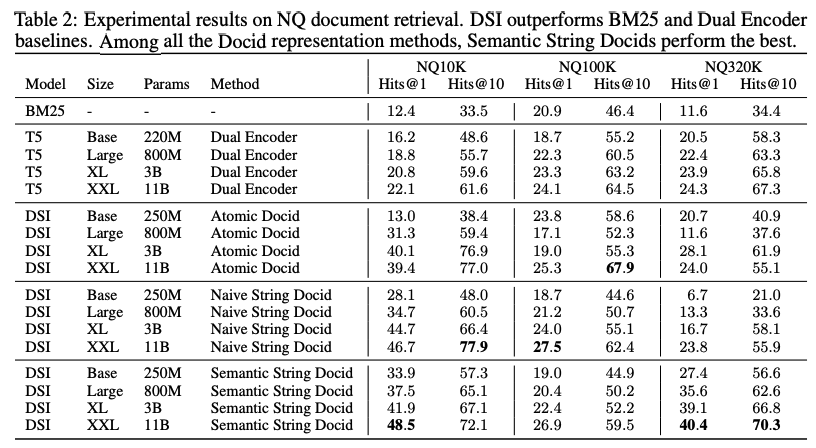
Supervised Finetuning Results
- DSI가 DE를 모든 dataset size에서 outperform
Zero-shot Results
- 모든 NQ 데이터셋에서 BM25를 outperform
- 일반적인 비지도 학습 방법은 BM25를 능가하기 힘든데, 이를 outperform한 결과는 매우 고무적
Document Identifiers
- docid를 어떻게 표현하는가?는 structured semantic identifier가 helphul함을 발견
- 그러나 zero-shot setting에서는 unstructured atomic identifer가 큰 margin으로 outperform 하였기에, 이 또한 주목할만 함
Indexing Strategies
- indexing stage 없이는 acc가 0%(직관적)
- Inputs2target, Bidirectional이 가장 우수하나, 전자가 후자보다 미세하게 좋음
- Target2Inputs + Span Corruption은 acc가 0%
- 어떤 조합을 설정하는 지에 따라서도 성능이 천차 만별임
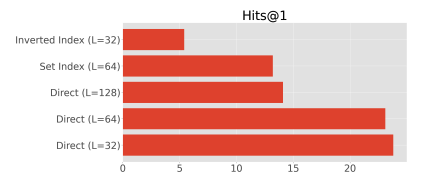
Document Representation
- Direct indexing이 best
- inverted index method는 적용하기 어려움 (docid가 반복적으로 다른 token에 노출 됨)
- 문서 길이가 너무 길어지면 memorize가 어려워짐
- 불용어처리, 중복 단어 제거등은 추가적인 성능 향상을 가져오지 않음
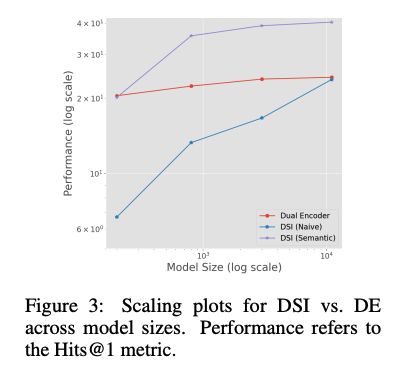
Scailing Laws
- DE는 모델 size가 커짐에따른 성능 향상이 비교적으로 적지만, DSI는 성능 향상 폭이 큼
- 위 figure 참고
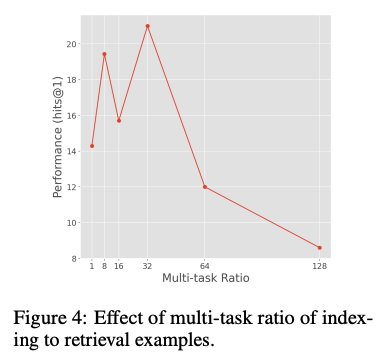
Interplay Between Indexing and Retrieval
- Memorize 후, retrieve task를 학습하는 것(sequentially)는 미미한 성능
- 동시에 학습하는 경우가 기본적으로 효과적이나, multi-task ratio에 따라 성능 차이를 보임
