Exploring the Potential of Large Language Models (LLMs) in Learning on Graphs (2023)
Paper Review
목록 보기
21/51

Leverage LLM for better GNN
Introduction
- Ubiquiotous in various task -> Graphs!
- At, TAG(test-attribted graphs) node attribute와 graph structural을 잘 catch 해야함
- 기존 Bag-of-Words, Word2Vec은 polysemous words, deficiency in semantic information 때문에 sub-optimal
- ChatGPT, GPT-4 등 LLM의 성취
- 이를 GNN에 적용하면 어떨까?
- LLM-as-Enhancers
- text data를 정제함으로써 GNN을 enhance
- LLM-as-Predictor
- LLM을 이용해 final predicton (structural and attributes is present through NL)
- LLM-as-Enhancers
Contributions
- Explore two potential pipelines that incorporate LLMs
- LLMs-as-Enhancers
- LLMs-as-Predictors
- LLMs-as-Enhancers
- 두 개의 전략을 도입함으로써, 성능 향상을 보여줌
- LLMs-as-Predictors
- LLM을 사용함으로써 structural and attribute information을 잘 utilize하는 것을 보여줌
Key Insights
- node attributes를 embedding하는 deep sentence embedding model을 통해 GNN 성능을 향상
- text level에서 node attribute를 augment함으로써 downstream performance를 향상
- LLM이 predictor로 사용될 시, 그 예비효과가 탁월하지만 부정확한 예측과 test data leakage problem을 대비해야할 필요성 제시
- Node classification에서 LLM의 성능 탁월함 제시
Preliminaries
Definition 1
- TAGs(Text-Attributed Graphs)
- adjacency matrix
- each node
- each node is associated with text attribute
Definition 2
- Node classificaton on TAGs
- we aim to predict the lables of node
- use popular citation network OGBN-ARXIV
- node is paper, edge is citation
- 각 노드는 제목과 abstract를 attribute로 가짐
GNN
- GNN을 통해 구조적인 정보를 aggregate
- 은 aggregate function
- 는 미분 가능한 function (MLP 등)
LLM
- extensive text corpora에 의해 pre-trained된 language model을 의미
- LLM의 embedding이 접근 가능 여부에 및 여러 분류 기준에 따라, 아래와 같이 LLM을 분류함
Embedding-visible LLMs
- 유저가 extract embedding을 사용할 수 있음
- BERT, Sentence-BERT, Deberta 등
Embedding-invisible LLMs
- 유저가 직접적으로 embedding에 접근 불가능
- Web, 혹은 간접적인 방법으로 model을 deploy 할 수 있음 (API)
Pre-trained Language Models
- PLMs
- 비교적 작은 LM (BERT, Deberta)
- can be fine-tuned for downstream datasets
- 엄밀히 따지면 아래 소개할 모든 LLM 또한 PLMs에 포함되지만, 본 논문에선 BERT와 같은 모델만으로 제한
Deep Sentence Embedding Models
- PLMs을 base encoder로 사용하고, bi-encoder structure를 채택한 모델
- model을 supervised, contrastive하게 pre-train
- local sentence embedding models와 online sentence embedding models로 분류 가능
- local sentence embedding model은 open-source이며, Sentence-BERT등이 해당
- online sentence embedding model은 closed-source이며, service로 사용 가능 (OpenAI의 text-ada-embedding-002 등)
Large Language Models
- PLMs에 비해 비교적으로 다수의 파라미터를 가지는 LM
- 유저가 locally하게 fine tune 할 수 있는가로 분류되지만, fine tune할 수 있더라도 본질적인 size 때문에 fine tuning이 쉽지 않음
Pipelines for LLMs in Graphs
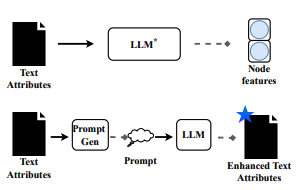
- LLMs-as-Enhancer 도식화
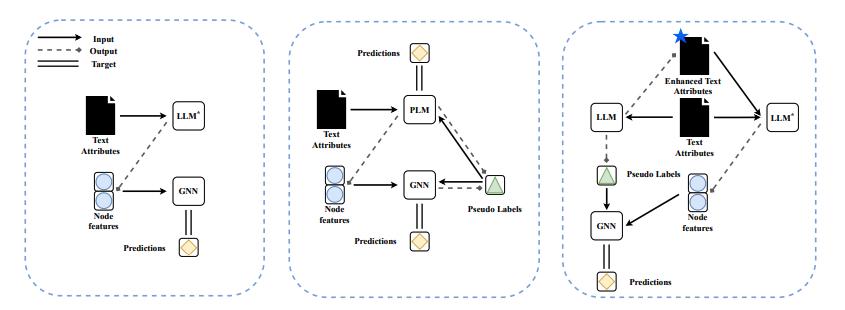
- 1, 2는 feature level enhancement이며 3은 text-level enhancement
- Cascading Structure: Embedding visible LLM을 통해 node attribute를 embed하여 GNN을 통과하는 sequential
- Iterative Structure: PLM과 GNN을 psuedo label을 통해 동시에 학습
- Text-level enhancement: LLM이 augment된 attribute를 생성하고, 이를 embedding-visible LLM이 embedding하여 최종적으로 GNN을 통과하게 학습
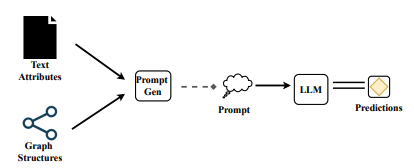
- Graph와 text를 사용해 적절히 prompt를 제작하고 이를 LLM에 통과시켜 학습
LLMs as the Enhancers
Feature-level Enhancement
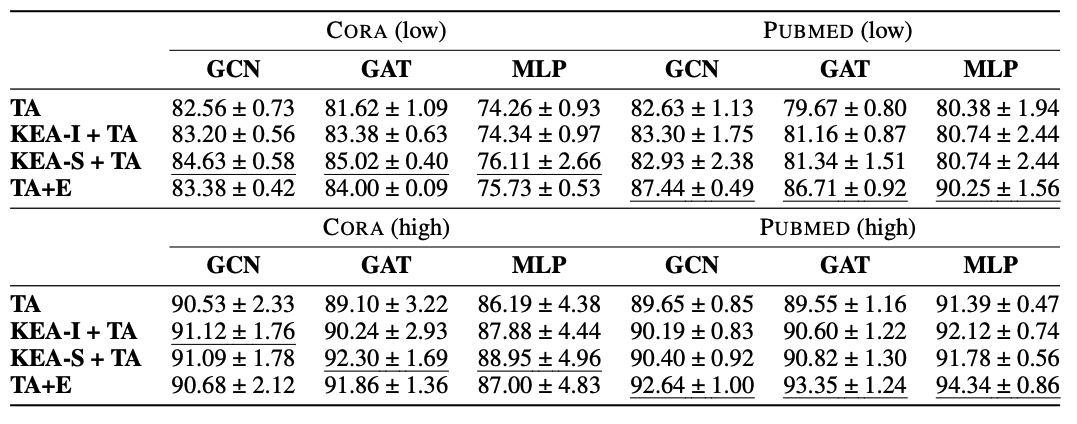
- CORA, PUBMED, OGBN-ARXIV, OGBN-PRODUCTS 사용
- low-labeling-rate와 high-labeling-rate를 함께 실험에 사용
Baseline Models
GNN
- GCN, GAT, MLP, RevGAT, GraphSAGE, SAGN과 관련 trick들을 모두 사용
LLMs
- embedding visible LLM이 필요
- Fixed PLM/LLMs without fine-tuning
- Deberta, LLaMA
- 각각 CLS 토큰과 EOS 토큰을 text embedding으로 사용
- Deberta, LLaMA
- Local sentence embedding models
- Sentence-BERT, e5-large
- 전자는 가벼운 널리쓰이는 deep text model이며, 후자는 SOTA
- Sentence-BERT, e5-large
- Online sentence embedding models
- text-ada-embedding-002(OpenAI), Palm-Cortex-001(Google)
- Fine-tuned PLMs
- fine-tuning Deberta on the downstream dataset
- Integration structure
- cacading structure, iterative structure(GLEM-GNN, GELM-LM)
- 전자는 dataset으로 fine tune 후, GNN 학습
- 후자는 pseudo label을 통해 co-trained
- cacading structure, iterative structure(GLEM-GNN, GELM-LM)
- 비교를 위해 TF-IDF 와 Word2vec을 사용
Experiments
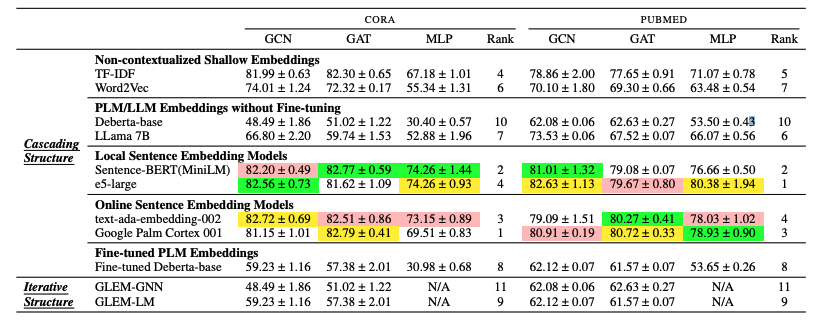
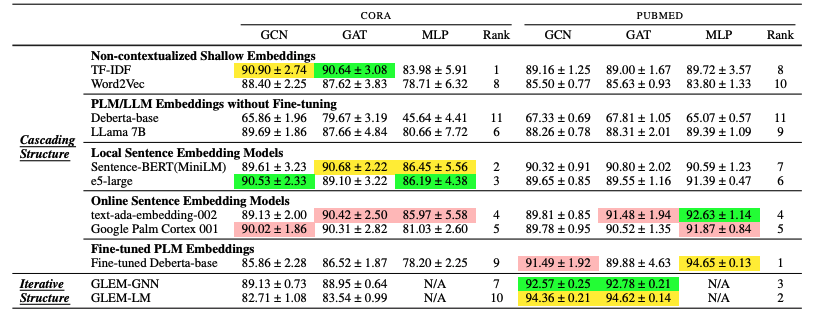
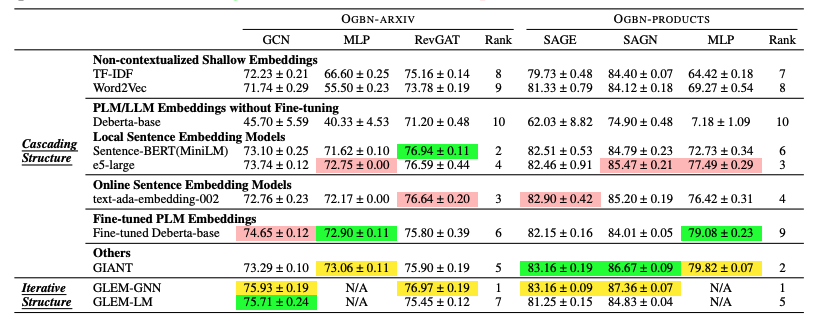
- 노랑, 초록, 핑크 순으로 1, 2, 3등
- MLP는 구조적인 정보를 주지 않기에 co-train이 의미가 없으므로 N/A
- 각각 low labeling ratio with cora pubmed, high labeling ratio with cora pubmed, OGBN-ARXIV OGBN-PRODUCTS
Observation
- table 3를 통해 다른 text embedding에 따라서, GNN의 효과가 상이한 것 을 알 수 있음
- 이 효과가 상이함을 나타내는 지표는 아직 존재하지 않음 (한계)
- table 1을 통해, Fine-tune-based LLMs는 low labeling rate setting에서 자주 실패함을 알 수 있음 (cascade, iterate 관계 없이)
- 아마 training dataset이 한정되어 있기 때문이라고 판단
- 모든 테이블에서, 간단한 cascading structure와 deep sentence embedding의 조합이 좋은 성능을 보임을 알 수 있음
- 단순히 LLMs의 크기를 늘리는 것으로는 node-classification 성능을 올릴 수 없음
Scalability Investigation
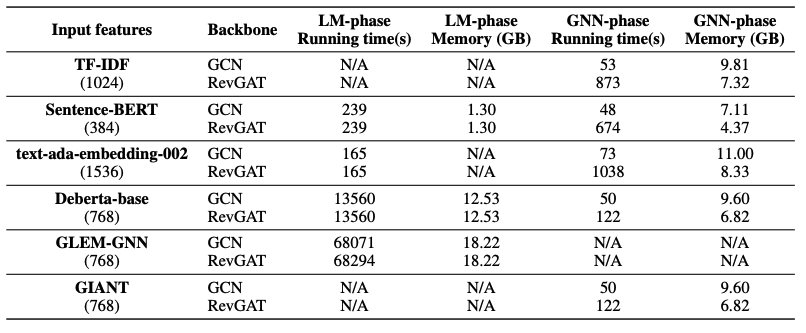
- OGBN-ARXIV에서 GLEM과 같이 fine-tuning을 필요로 하는 모델은 fine-tuning을 필요로 하지 않는 모델에 비해 훨씬 많은 학습 시간을 필요로 함
- 보다 깊은 scalability problem 이해를 위해 학습 시간과 추론 시간에 대한 실험을 진행함
- 총 5가지 비교군
- train inference 시간을 무시해도 되는 모델 (TF-IDF)
- inference 시간만 필요한 모델 (Sentence-BERT)
- Embedding을 위해 API 호출이 필요한 모델 (text-ada-embedding-002)
- LM의 fine-tuning과 inference 동시에 필요한 모델 (Deberta-base)
- co - train이 필요한 모델 (GLEM)
Observation
- interative structure에서 막대한 병목현상이 train stage에서 발생 됨
- deep sentence embedding 모델이 fine-tuned PLMs보다 빠르고, memory 사용량이 적음
- Gradient 등을 저장할 필요가 없기 때문
Text-level Enhancement
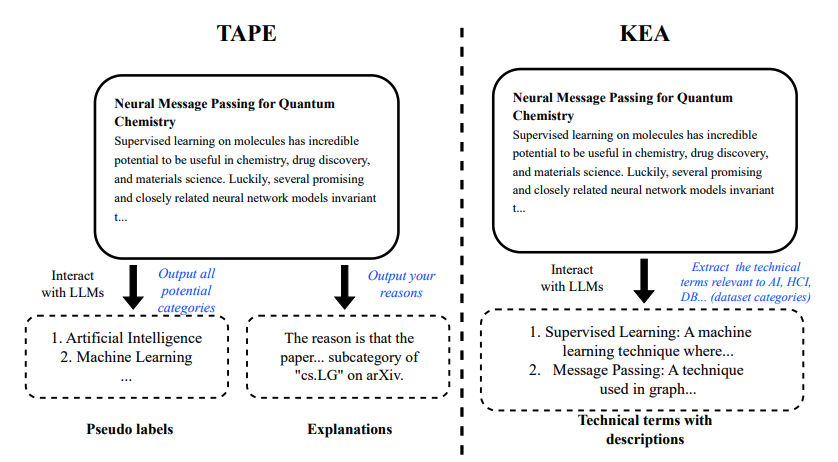
- 우리의 연구는 embedding-visible model에 한정되어 있음
- 그러나 진정 powerful한 것은 ChatGPT, GPT4와 같은 invisible model
- 여러 확장할 방법을 제시
TAPE
- original attribute "mean-field approximation"
- label "probabilistic methods"
- LLM을 통해 "mean-field approximation is a widely adopted simplification technique for probabilistic models" 생성 (그럴듯한 문장)
- 이를 통해 PLMs fine tuning
Knowledge-Enhanced Augmentation (KEY)
- LLM을 이용해 text의 더 많은 맥락을 전달하고자 함
- 문장에 속한 단어들의 desctiption을 추가적으로 생성
- 이를 통해 fine tune
- TAPE는 LLM이 잘못된 연결을 제공하면 critical한 반면, KEY는 보다 stable함 (직접적인 예측에 의존하지 않기에)
Experiment
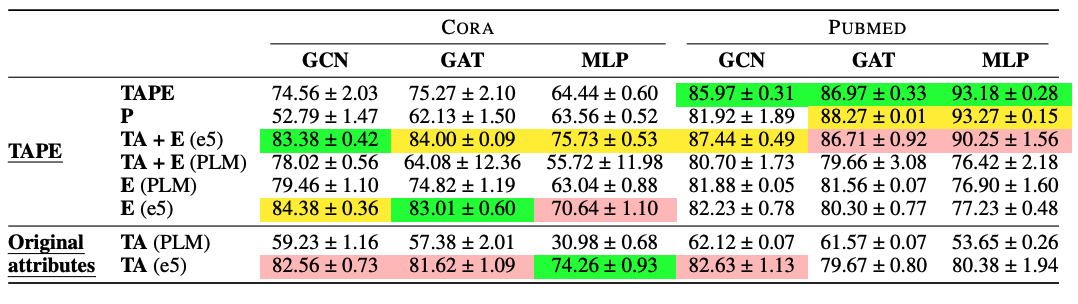
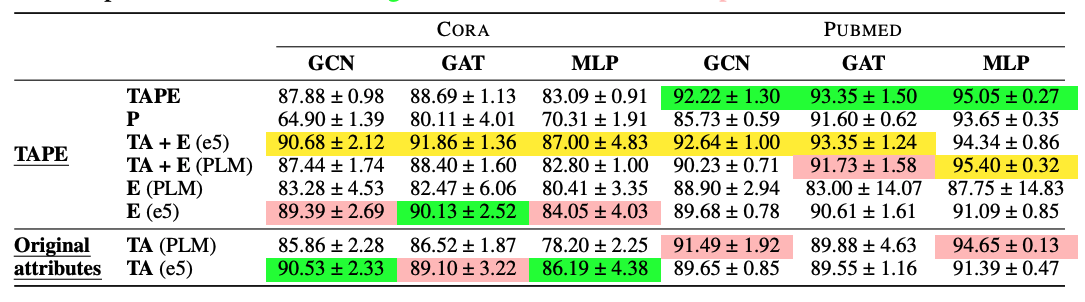
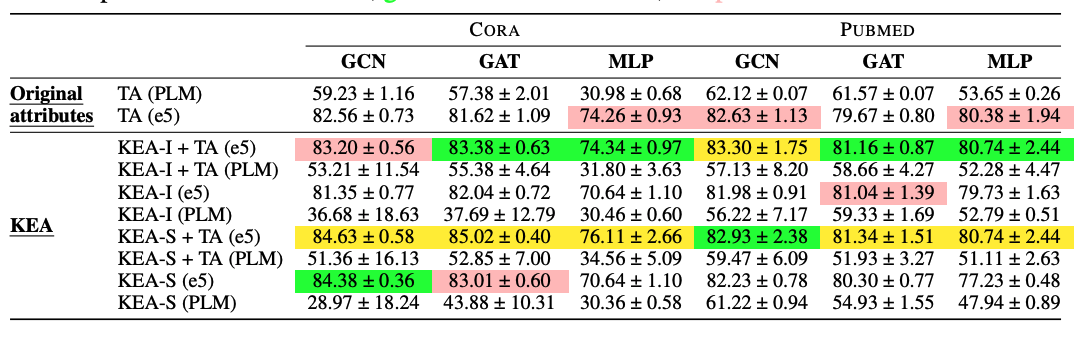
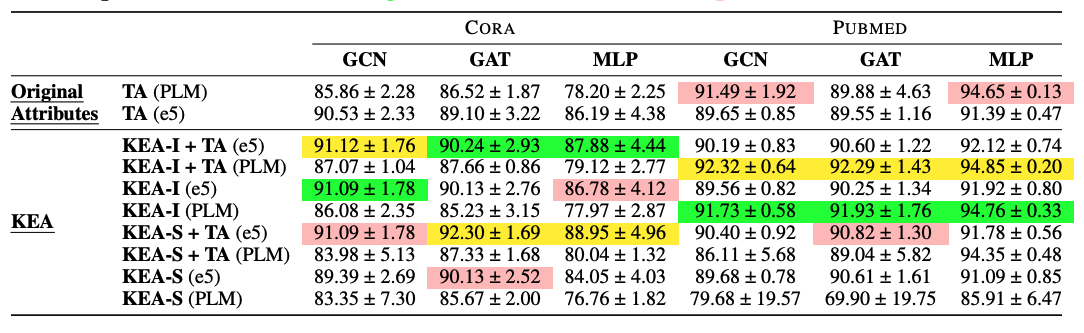
- LLM cost를 고려해 비교적 작은 데이터셋인 CORA와 Pubmed 사용
- TAPE
- TA "text attribute"
- P "psuedo labels"
- E "explanations"
- KEY
- KEY-I "combined original with augmentation"
- KEY-S "separate original and augmentation"
Observation
- TAPE의 효과는 주로 explanation "E"에서 발생함
- PLM을 deep sentence embedding으로 교체할 시 TAPE의 성능이 향상함
- KEY를 사용하면 TAPE의 TA 성능을 향상시킬 수 있음
- 데이터셋 마다 성능을 향상 시키는 방법론은 매우 다양함
LLMs as the Predictors
- LLM은 독립적으로 graph structure의 predictive task를 이행할 수 있는가? (추천, logical reasoning 과 같이)
- TAGs에서 node classification은 본질적으로 text classification과 큰 차이가 없음
- 그러나 어떻게 structure를 반영할 것인가?
- Prompt를 통해 structural information을 NL로 반영해야 함
How Can LLM Perform on Popular Graph Benchmarks without Structural Information

- 구조적인 정보를 무시하고 text classification으로 실험
- Zero-shot prompt
- Few-shot prompt
- Zero-shot prompts with Chain-of-Thought(CoT)
- Thinking step-by-step (CoT)
- Few-shot prompts with CoT

Observations
- 몇몇 데이터 셋에서, LLM은 좋은 예비 효과를 줌
- LLM이 만든 틀린 prediction은 때때로 합리적임 (multi-label problem)

- CoT는 performance gain을 가져오지 못함

- Potential test data leakage가 존재함
- label design strategy에 따라 성능 차이가 유의미함
- strategy 3와 유사하게 미리 arXiv로 모델이 학습하였을 가능성 존재
- 이는 test leakage..

Incorporating Structural Information in the Prompts


- LLM이 꽤 괜찮은 성능을 보여주더라도, GNN계열 모델에 비해 안좋음
- How to get structural information
- 어떻게 prompt로 graph 정보를 전달하는가?
- 딕셔너리 형태의 이웃 리스트를 전달하여 graph 정보를 prompt로 전달
- 실제 GNN과 같이 2-hop으로 설정 (이웃을 2-hop까지만 전달)
Observation

- neighborhood summarization이 실제로 성능을 향상시킴
- Transformer와 같은 논문은 ML, CV, AI 어디에 속해도 이상하지 않을 topic
- Graph structure가 bias를 잘 catch한 것으로 보임
- 다만 Pubmed 데이터셋의 경우 오히려 성능이 떨어졌으므로, 깊은 분석을 요구함
- LLMs with structure-aware prompt는 heterophilous neighboring nodes 문제에 빠짐
heteorophilous는 이웃의 이웃 노드가 다른 성질을 띄는 문제
실제로 하단의 프롬프트에서 이웃 노드 두 개가 hetero한 성질을 띄는 것을 보임
* 이는 LLM이 GNN의 issue를 똑같이 공유한다는 것을 뜻함

Case Study: LLMs as the Pseudo Annotators
- zero-shot 예측으로 볼 때, 어떠한 label이 없더라도 LLM은 충분히 좋은 예측모형이 될 수 있음
- 두 가지 한계가 존재
- API 사용으로 높은 cost
- 오픈 소스와 closed 소스 관계 없이, GNN보다 느린 추론 속도
- 따라서 LLM을 annotator로 이용할 수 있음 (GNN 학습을 위해)
- 다만 LLM이 생성한 psuedo-label을 진정 신뢰할 수 있는가?
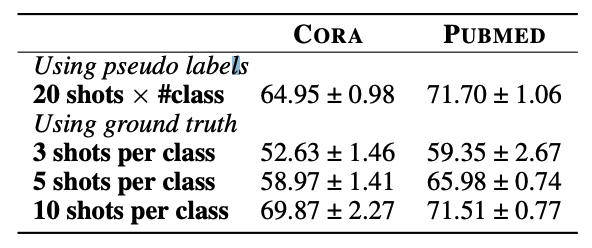
Observation
- psuedo labels의 질이 downstream performance에 중요함
- LLM의 confidence level은 대부분 1이기에, 이를 학습에 사용하는 것은 크게 성능에 영향을 끼치지 않음

Conclusions, Limitations, Future Directions
Key Finding
- LLMs-as-Enhancers, deep sentence embedding models가 좋은 성능을 보임
- LLMs-as-Enhancers, LLMs' augmentation과 ensembling이 좋은 성능을 보임
- LLMs-as-Predictors, preliminary effectiveness를 보였으나, potential evaluation problem 또한 제기됨
Limitations
- text embedding의 효과를 deep하게 이해 불가
- LLM을 이용한 augmentation에서의 cost
- 손 수 prompt를 제작해야 함
Future Directions
- 현재의 pipeline에 다양한 graph learning tasks 적용
- molecular graph 등
- Graph 도메인에 적용될 수 있는 LLM의 구축
- LLM을 효율적으로 사용
- ChatAPI를 사용하는 것은 물론 비용이 요구되며, Open Source를 사용하는 것 또한 학습 및 hardware resource 차원에서 자원이 소모됨
- Graph ML Task에서 LLM's의 능력을 평가하는 것
- 우리는 test data leakage와 ground truth label이 모호한 문제로 인해 LLM의 잠재력을 제대로 파악하지 못함
- 전자는 아얘 새로운 데이터를 사용하면 평가 가능하지만, 이는 또 다른 자원이 소모됨으로 현명한 솔루션이 아님
- 후자는 multi-label selection 문제로 변형하는 등의 해결책이 있지만, 이 또한 더 합리적인 ground truth를 찾아야할 필요성이 있음
- 우리는 test data leakage와 ground truth label이 모호한 문제로 인해 LLM의 잠재력을 제대로 파악하지 못함
- LLMs as annotators for learning on graphs
- 최근 "black-box LLMs"의 uncertainty를 연구하는 방법론이 등장
- 이를 통해 성능 향상과 graph에서 node의 중요도 또한 파악 가능할 것으로 보임

정리가 잘 된 글이네요. 도움이 됐습니다.