
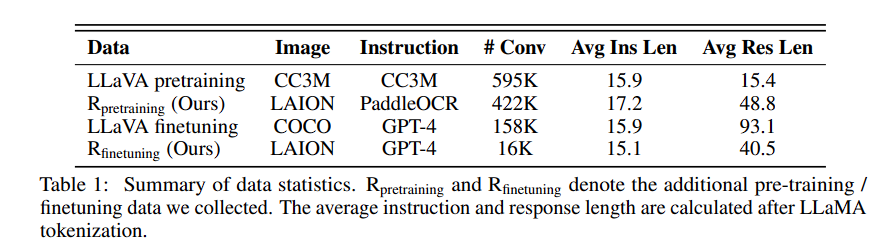
Introduction

- Instruction Tuning은 generalization을 향상시킴
- 그러나 LLaVA는 natural image 기반이기에 text를 인식하는 데에 어려움이 존재함
- OCR을 통해 인식 시킨 뒤, input으로 하는 나이브한 접근은 유용하지만 time consuming하고 visual encoder를 fully leverage 할 수 없음
- 우리는 end-to-end visual instruction을 통해 text understanding을 강화하고자 함
- text-rich image를 collect한 뒤, OCR result와 함께 instruction-following dataset을 제작 함
- 그 뒤, GPT4를 활용해 conversation을 만들어 LLaVA를 추가로 fine tuning
- 우리는 이를 LLaVAR (Large Language and Vision Assistant that can Read)로 명명
- SOTA 달성
Data Collection
- 가장 먼저, LAION-5B dataset에서 text-rich image만을 남기고자 함
- simple DiT backbone을 통해 image에 text가 존재하는지를 분류해 threshold 기준 필터링
- 이후 clean up 및 human judgement를 통해 50K image를 randomly sample 및 CLIP을 통해 100개로 clustering
Noisy Instruction-following Data
- filtering 된 image를 PaddleOCR을 이용해 text 추출
- Robust instruction을 위해 'Identify any text visible in the provided image'를 동일한 뜻의 다양한 instruction 준비
- 이후 input instruction을 randomly sample하고 text를 output response로 하여 데이터셋 제작
- 이 data는 OCR의 한계로 인해 noisy (diverse fonts, coloful backgrounds)
GPT-4-based Instruction-following Data
- 기존 instruction-following data에 비해 두 가지 한계가 존재
- raw OCR result로 인한 missing word, grammar error가 존재
- 단순히 text를 묻는 것이 아닌, diverse한 instruction이 필요
- prompting만으로 non-trivial한 instruction을 생성하는 것은 어려움
- 따라서 이전 cluster 결과에서 충분히 visible하고 coherent sentence를 보유한 몇몇 군집을 carefully select
- 이후 OCR result와 image caption을 통해 GPT-4로 하여금 conversation을 생성
- Visual element에 집중시키기 위해, BLIP-2를 활용해 text-masking 된 image에서 생성한 caption을 사용
- caption에서 hallucination이 존재할 수 있기에, GPT-4가 올바른 답변을 생성하게끔 함
Model Architecture and Training
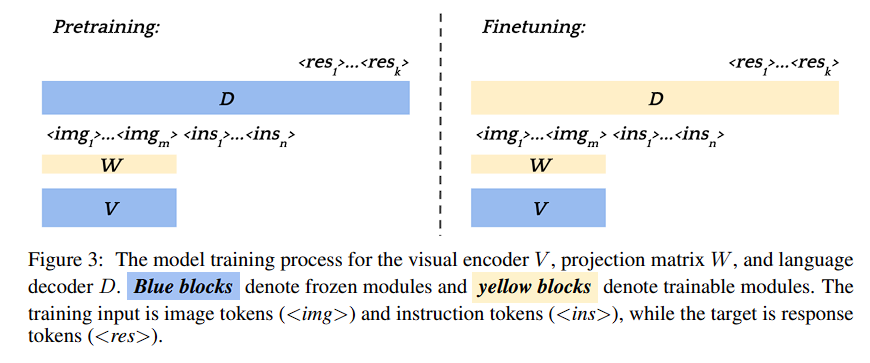
Architecture
- LLaVA와 동일
- 다만 추가적으로 high-resolution visual encoder를 사용
- 이는 text-decoder의 차원과 맞지 않기에, cross-attention module을 사용하여 decoder가 high-res patch와 align할 수 있게끔 함
Training
- LLaVA의 two-stage training design을 채택
- first pre-training시 projection matrix만을 학습
- LLaVA의 data와 우리의 noisy intstruction-following data를 사용해 학습
- 이후 LLaVA와 같이 projection matrix와 text decoder를 학습
- 다만, CLIP은 general-purpose text-image alignment를 위해 trained 되었기에, 이를 학습 시키는 것이 text recognition에 효과적일 수 있음
- 이는 future work로 남겨둠
- 다만, CLIP은 general-purpose text-image alignment를 위해 trained 되었기에, 이를 학습 시키는 것이 text recognition에 효과적일 수 있음
Experiments
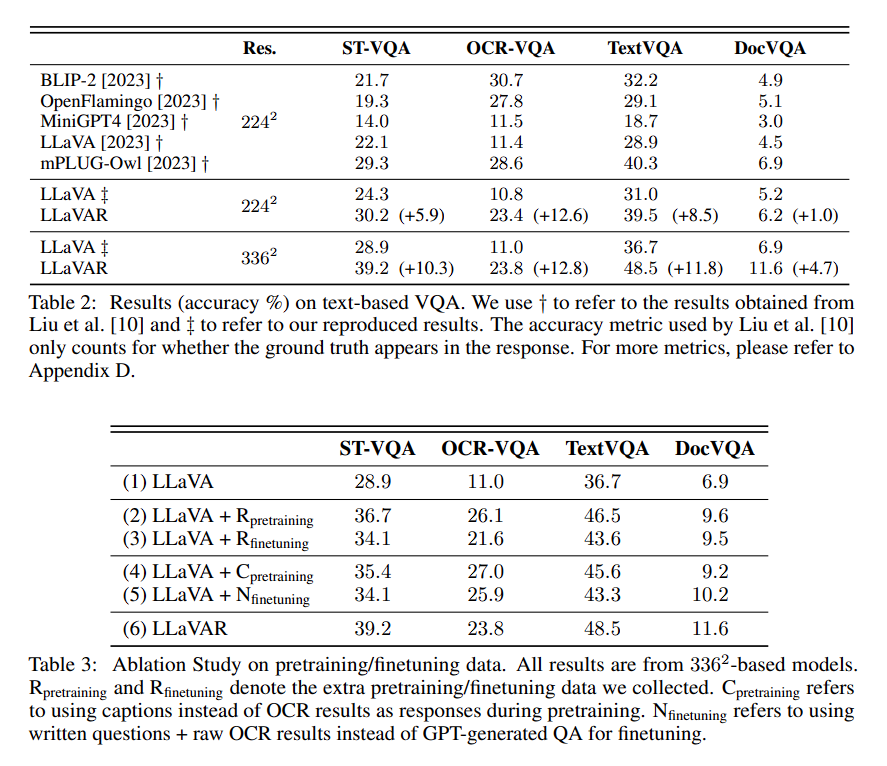
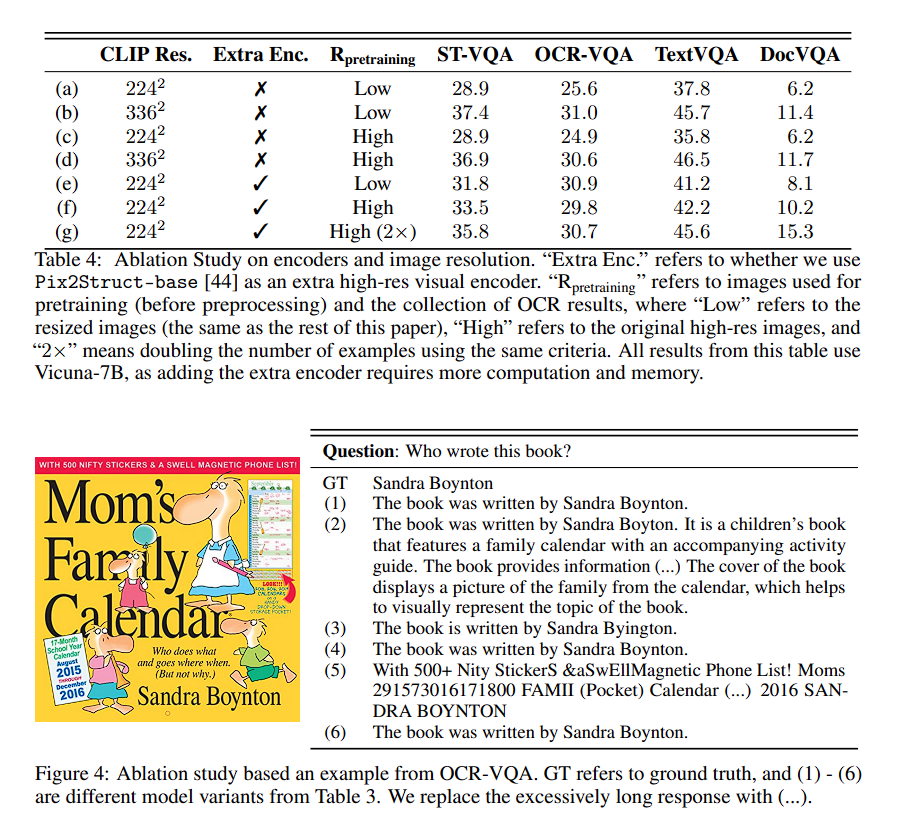

- Table의 성능과 ablation을 통해 우리의 method가 효과적임을 증명
