Large Language Models are Zero-Shot Reasoners (NIPS 2022)

Introduction

- LLM과 prompting은 Hot Topic in NLP
- task-specific한 few-shot, zero-shot prompting의 한계를 극복하기 위한 method인 CoT의 등장은 매우 Novel
- 특히 CoT 성능은 모델 scale과 비례하기에 LLM의 한계를 뛰어 넘게 해줌
- 우리는 이러한 CoT가 zero-shot에서도 잘 작동함을 보여줄 것
- 특히 Zero-shot CoT는 versatile(다재다능)하며 task-agnostic(특정 task에 구애받지 않음)함 (이전 prompting method와 차별화되는 점)
- empirical하게 향상된 성능을 보여줌
- few-shot CoT에서는 human engineering이 필요해 human error의 가능성이 있음
- 우리의 zero-shot prompt는 single prompt이기에 better one
Background
Large language models and prompting
- Large scale parameters and Large Data enable LLM to work well
- pre-training, fine-tuning, prompting strategy가 개발됨
Chain of thought prompting
- Few-shot prompting에 속하는 분야로, multi-step problem을 Intermidiate하게 설명하여 performance improvement를 이루어낸 method
- 우리의 Zero-shot-CoT와 구분하기 위해 Few-shot-CoT로 명명
Zero-shot Chain of Thought
- zero-shot template-based CoT prompting인 Zero-shot-CoT를 제안
- Original과 달리 few-shot example이 필요하지 않음, 이전의 template가 필요하지 않음
Two-stage prompting
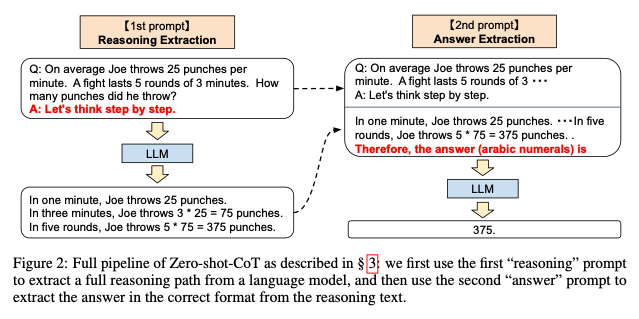
- 위 처럼 prompting을 두번 이용
- Few-shot-CoT처럼 carefull human engineering이 필요하지 않지만, 적어도 두 번 prompting이 필요
- x가 input일 때 "Q: [X], A:[T]"
- A는 CoT trigger (ex: "Let's think step by step")
- 이를 통해 CoT prompt Z를 생성
- "[X'][Z] [A]"를 concat하여 prompt 생성
- X는 이전 질문, Z는 생성된 CoT prompt, A는 answer trigger (ex: "Therefore, the answer (arabic numerals) is)
- Z를 생성하는 과정에서 self-augmented (자가 증강)이 이루어짐
- 최종 answer Y를 생성
Experimennt
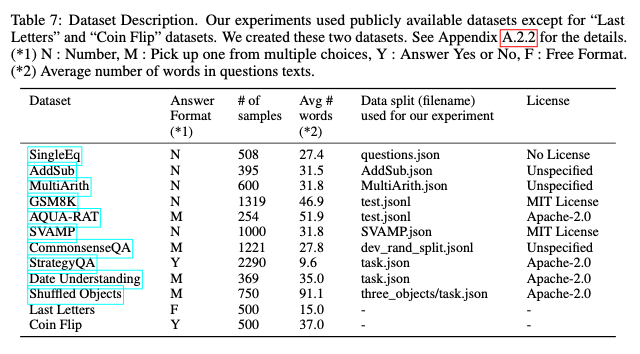
Task and dataset
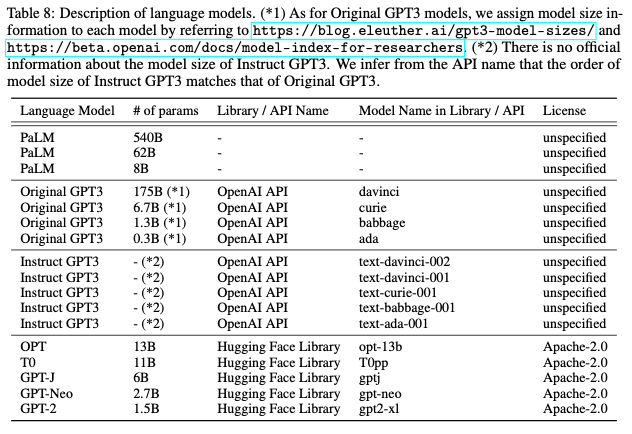
Models
Baselines
- Zero-shot prompt, Few-shot-CoT prompt와 비교
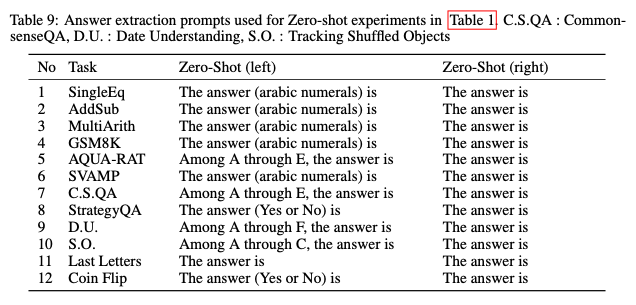
Answer cleansing

- 다음과 같이 answer를 보다 cleansing
Result
Zero-shot-CoT vs. Zero-shot
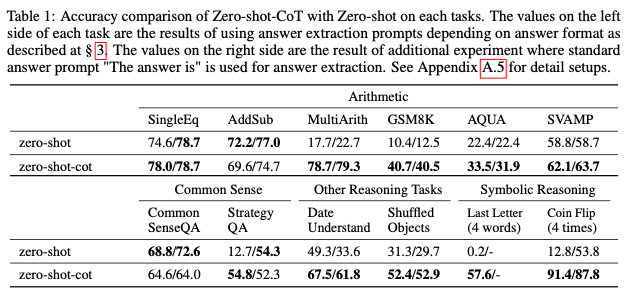
- Zero-shot-CoT가 가볍게 zero-shot을 outperform
- 다만 multi 추론이 필요 없는 task에서는 zero-shot과 비슷한 성능

- 독특한 점은 LLM이 사람과 비슷한 추론, 사람이 할 법한 실수를 저지른다는 점
Comparison with other baselines
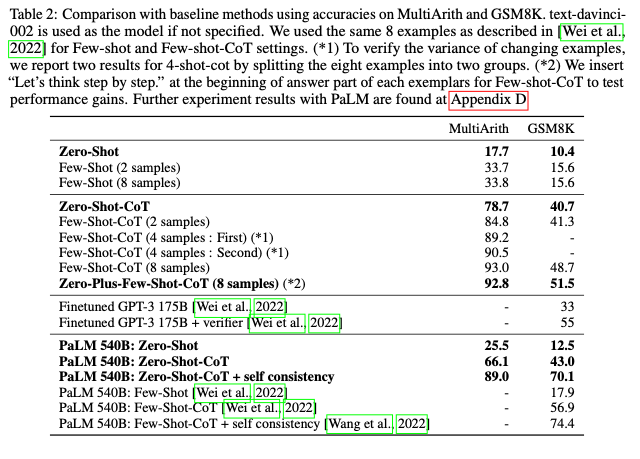
- few-shot prompting보다는 좋은 성능이지만, few-shot-CoT에 비해서는 낮은 성능
Does model size matter for zero-shot reasoning?
- 모델 사이즈가 작을 경우, zero-shot-CoT는 잘 작동하지 않음
- 그러나 few-shot-CoT와 달리 모델 사이즈가 커진다고 하더라도 드라마틱한 성능 향상을 보이지는 않음
Error Analysis
- Commonsense reasoning 에서 Zero-shot-CoT는 flexible 하지만 가끔 틀리는 경우가 있음
- 또한 결정을 내리기 어려운 경우 여러 개의 답변을 output으로 보여주는 경우가 존재
- Arithmetic reasoning에서는 확연한 차이
- Zero-shot-CoT는 불필요한 연산을 지속하여 틀린 결과를 내리는 경우가 있음
- Few-shot-CoT는 3단 연산에서 취약 (3+2) * 4
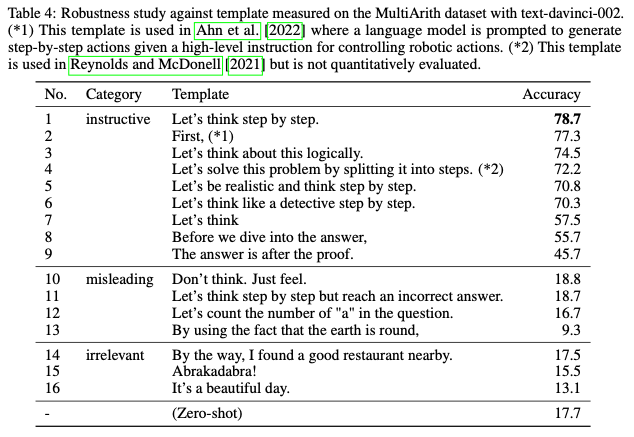
How does prompt selection affect Zero-shot-CoT

- CoT를 더욱 강화하는 방향으로의 prompt가 성능 향상에 크게 기여함
- zero-shot CoT는 LLM이 내재적으로 intermidiate step을 파악할 수 있다는 것을 의미
- fine tune, few shot prompting 등 추가적인 cost를 극단적으로 감소하게 할 수 있음
Limitation and Social Impact
- Zero-shot CoT 또한 LLM의 내재적인 단점을 공유
- 다만 Zero-shot CoT를 통해 LLM의 추론 과정에 접근할 수 있는 실마리를 포착
Conclusion
- hand-craft few-shot example을 제작할 필요가 없는 reasoning technique인 zero-shot-CoT를 제안
- 자원 절약과 system-2 reasoning task의 새로운 baseline이 될 수 있음
