Chain-of-thought prompting elicits reasoning in large language models (NIPS 2022)
Paper Review
목록 보기
28/51

Introduction
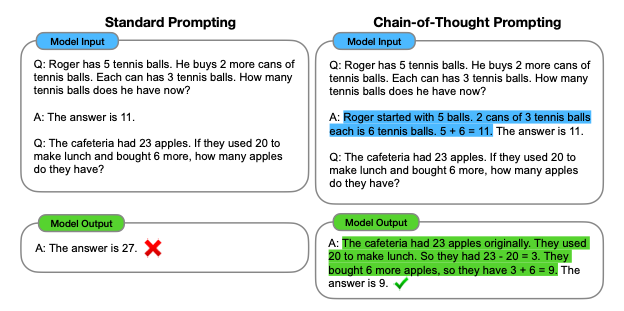
- 아무리 모델의 크기를 늘려도 LLM은 추론에 취약
- 이 연구는 어떻게 LLM이 다음 두 motivation을 통한 simple method로 인해 unlocked 되는지를 보여줌
- 이전에는 fine tuning or neuro symbolic method를 통해 해결하려 함
- 또한 LLM은 prompting이라 불리는 few-shot learning을 통해 해결하려 함
- 이는 simple QA에서는 효과를 보임
- 그럼에도 Cost, poor improvement 등 한계가 존재
- 우리는 두 motivation을 조합해 한계를 해결하려 함
- (input, CoT, output) triple을 생성
- CoT는 결과로 다다르는 추론 과정의 자연어
- Benchmark에서 눈에 띄는 성능 달성
- 특히 prompting only approach는 training data, time, generality 등 cost가 필요하지 않기에 매우 유의미
Chain-of-Thought Prompting
- 복잡한 문제를 푸는 것은 intermediate step으로 decompose 하는 것
- CoT의 properties
- multi-step problem을 intermidiate step으로 쪼개어 추가적인 decompose가 필요할 경우 할당할 수 있음
- CoT는 해석 가능한 창문으로써 어떤 부분에서 model이 왜 에러를 일으키는지 확인할 수 있음
- 수학 문제, 상식 추론, 상징 조작과 같은 task에서 활용 가능하며, 이는 인간이 해결할 수 있는 어떤 language problem이라도 해결할 수 있다는 것을 보여줌
- 단순히 LLM에 CoT example을 prompting하는 것 만으로 작동
Arithmetic Reasoning

- 수학 추론 문제는 LLM에게 매우 struggle한 problem
Experimental Setup
- 여러 벤치마크 사용
- Standard Few-shot prompting과 CoT를 비교
- LLM으로 GPT-3, LaMDA, PaLM, UL220B, Codex를 사용
Result
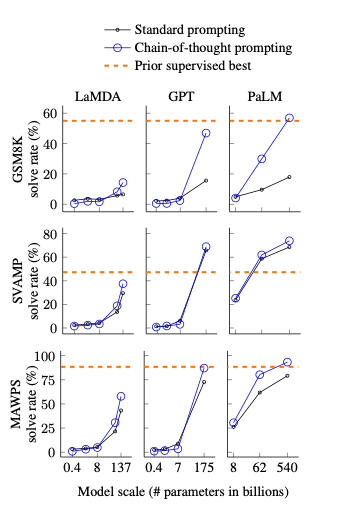
- 총 3가지 key
- CoT는 parameter가 큰 모델일 경우에만 잘 작동 (작은 모델에선 오히려 성능 저하)
- 더 복잡한 task일 수록 Baseline과의 성능 차이가 큼
- 여러 벤치마크에서 Fine tuning보다 성능이 좋은 SOTA 달성
- Case Study를 위해 50개의 correct answer와 wrong answer를 추출
- Correct는 2개 결과를 제외하고는 모두 논리적인 정답
- Wrong은 46%는 사소한 실수이며, 54%는 중대한 오류
Ablation Study
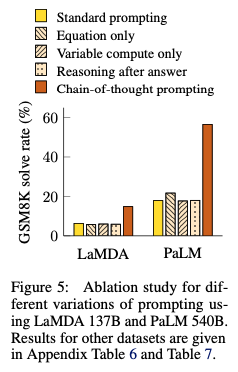
Equation only
- 공식만 주어졌을 때 복잡한 추론에서의 성능이 향상은 거의 일어나지 않음
- one-step, two-step problem에서는 성능 향상을 가져옴
Variable compute only
- CoT는 length가 크니, 단순히 자원을 더 몰아주면 성능이 올라가는게 아닐까?
- CoT length만큼 dot을 채워줌
- 역시 성능 향상 없음
Chain of thought after answer
- answer를 주고 이후에 CoT를 prompting한 경우
- 성능 향상 없음
- intermidiate step을 알려주는 CoT가 유의미함을 알 수 있음
Robustness of Chain of Thought
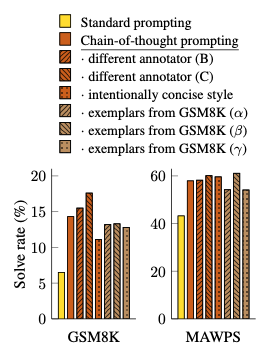
- Annotator랑 CoT가 특별히 잘 반응한게 아닐까?
- 상관 없이 CoT가 성능이 좋은 것을 보여줌
Commonsense Reasoning
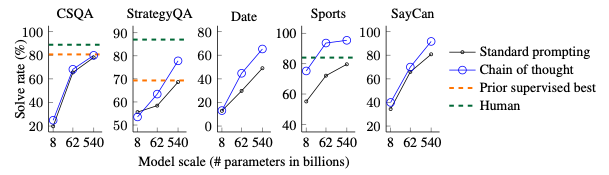
- 복잡한 language task인 commonsense reasoning에도 잘 동작할까?
- general background knowledge를 기반으로 physical and human interaction을 잘 해석할 수 있어야 함
- 역시 CoT가 우수
Symbolic Reasoning
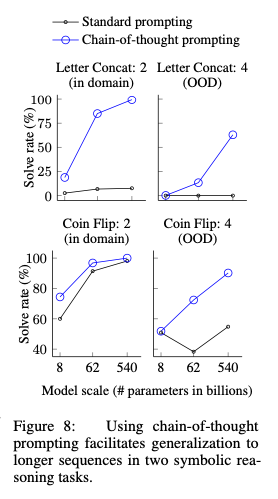
- Symbolic reasoning은 대표적으로 인간에게 쉽지만 LLM에게 어려운 task
- Last letter concatenation과 Coin Flip problem을 test
- 작은 모델에서는 잘 작동하지 않지만, 큰 모델에서 높은 성능 향상
- Coin Flip은 length가 긴데도 성능이 향상되었으니, length에 상관 없이 CoT가 효과적
Discussion
- Simple mechanism인 CoT로 성능 향상을 목도
- 또한 이는 standard prompting이 lower bound인 것 - 이를 통해 긍정적인 질문이 생김
- model scale이 커짐에 따라 성능이 얼마나 상승하는가?
- 미지의 prompting method를 사용하면 language model이 해결할 수 있는 영역을 늘릴 수 있는가?
- 그럼에도 한계는 존재
- 실제로 LLM이 사고하는 것인지, 모방하는 것인지는 알 수 없음
- CoT 자체를 fine-tuning에 적용하기는 어려움
- CoT가 correct answer을 보장하지는 않음
- small model에서는 성능 향상을 보장하지 못함
Conclusions
- simple prompting method CoT 제안
- arithmetic, symbolic, commonsense reasoning에서 SOTA 달성
