Multi-Objective Intrinsic Reward Learning for Conversational Recommender Systems (NeurIPS 2023)
Paper Review
목록 보기
40/51

Introduction
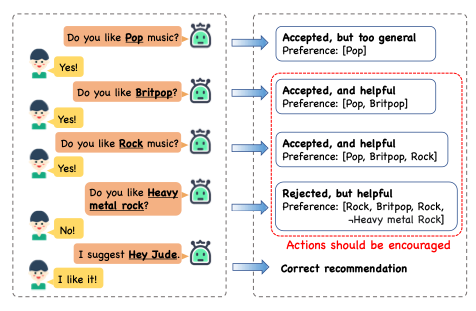
- CRS에서 보상 함수를 정의하는 것은 매우 중요하지만 어려운 task
- CRS에서 explicit한 외부적 reward는 매우 희소하며, 내재적 reward를 복잡하게 만듬
- Reject된 항목은 반드시 부정적인 reward를 의미하는 것은 아님 (사용자가 찾는 것일 수도 있음)
- CRS의 evaluation은 단순히 추천 품질 뿐만 아니라 사용자 경험의 전반적인 특성을 모두 보유해야 함
- 더 나은 추천을 위해 사용자의 선호도를 프로파일링 하는 것 뿐만 아니라, 더 적은 대화를 통해 아이템을 retrieve하는 것 또한 필수적 요소
- reward learning 관점에서, multi-objective optimization을 통해 내재적 reward function을 학습하는 우리의 솔루션은 CRISRL (CRS with Intrinsic Reward Learning)
- 첫 째로는 외부 reward를 최대화 하는 것으로 항목을 가장 빨리 탐색할 수 있도록 학습
- 둘 째로는 실패한 경로보다 성공적인 경로를 촉진하도록 학습
- CRSIRL이 다른 model을 outperform 한다는 것을 실험적으로 증명
Related Work
Conversational Recommender Systems
- 기존 연구는 단일 turn에서 multi-turn으로 확장 됨
- 지식 그래프, 동적 임베딩 등 다양한 이전 연구가 존재하였지만, 수동적인 reward function의 한계로 sub-optimial 하였음
Intrinsic Reward Learning in Reinforcement Learning
- Optimal Reward function을 찾는 방법, 복잡한 환경을 탐색할 수 있는 방법 등 다양한 내재적 reward function에 대한 연구가 존재
- 본 논문에서는 CRS에 맞게 설계된 내재적 reward 학습 프레임워크를 제안하여 희소한 명시적 reward feedback을 통해 multi-objective를 동시에 달성하도록 함
Preliminaries
Problem Definition
- Markov Decision process로 가정
- : 각각 state space, action space(item or attribute), state transition function, reward function을 의미
- T는 maximum turn이며, conversation은 유저가 만족하였을 때 or turn을 넘겼을 때 terminate
- policy는 로 정의할 수 있으며, 는 T turn까지의 reward이고
- 다음 loss를 minimize하여야 함
- 이전 연구에서의 수동 reward function 대신, 매개변수화 된 내재적 reward function을 학습
- 이 단락에서, 외부적 reward는 본질적으로 희소하며, 성공적인 완료시에는 positive, 그렇지 않을 경우에는 negative, 중간 단계에서는 어떠한 보상도 할당하지 않음
Multi-Objective Optimization
- 우리의 multi-objective optimization은 success rate를 극대화 하고 conversational length를 최소화 하는 것
- 이 두 목표는 trade-off가 존재하여 최적 솔루션을 찾기 힘듬
Definition 1 (Pareto optimality)
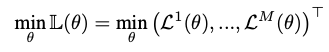
- 다음 Loss function에서 모든 목표에 대해 dominate하면서 무결한 pareto solution을 정의
Multi-Objective Intrinsic Reward Learning for CRS
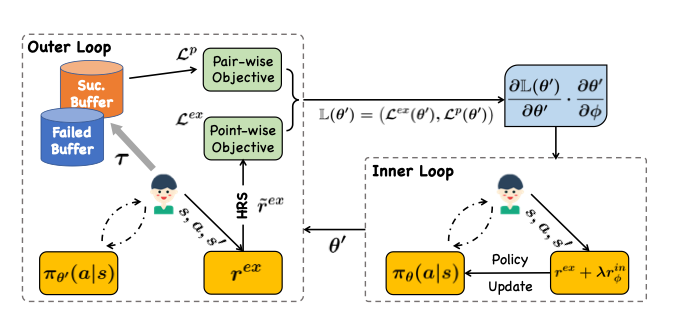
- CRSIRL의 구조를 상세히 설명
- 내부 optimization에서는 policy 개선을 위해 외부적 보상과 학습된 내부적 보상을 모두 사용
- 외부 optimization은 내부 최적화에서 파생된 정책을 기반으로 내재적 보상 개선
- 내재적 보상의 경우, 어떠한 감독이 없기에 경사하강법 사용
- 구체적으로는 외부 최적화에서의 chain rule을 이용하여 meta-gradient를 계산
- 외부 최적화에서는, pointwise로 학습된 내부적 reward function에서 외부적 reward를 향상시키기 위해 hindsight reward shaping (HRS)를 사용
- 이 목표는 대화 길이를 단축시키는데 중요한 작용
- pairwise로는 선호되는 대화를 유도하는 recommendation preference matching (RPM)을 사용
- 성공적인 경로를 비성공적인 경로보다 선호
- 다음 이중 optimization framework를 통해 종합적인 설계
Hindsight Reward Shaping
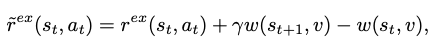
- w, v, gamma는 각각 scoring function, target item, discount factor
Lemma 1
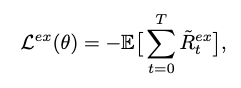
- 여러 증명을 통해 다음과 같은 PBRS(potential-based reward shaping function) condition을 만족할 수 있음
- 대상 항목에 대한 정보가 미리 알려져 있지 않으므로, 대상 항목이 hit 한 경우에만 HRS를 사용 할 수 있음
- 이것이 hindsight라고 명명한 이유
Recommendation Preference Matching
- 중간 동작들이 외부적 보상에 대해 기여도를 측정할 수는 없지만, 가치 있는 중각 동작들은 구별할 수 있음
- 성공한 episode와 실패한 episode를 contrastive
- 성공한 episode는 최적 정책 하에서 더 선호되어야 하며, 이는 likelihood로 측정할 수 있음
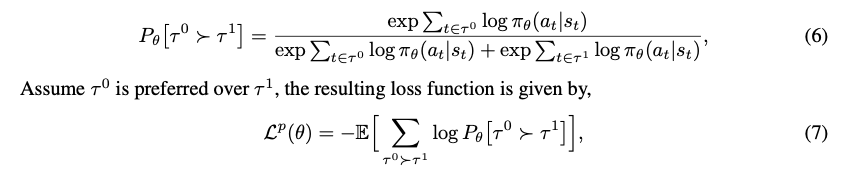
- 여기서, tau0이 tau1에 비해 더 선호된다면
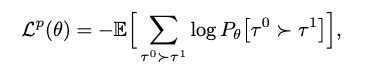
- 다음과 같이 formulate할 수 있음
- tau0, tau1은 buffer로 past tracectory에서 sample되며, bradley-terry model로 score를 estimate
Multi-Objective Bi-Level Optimization
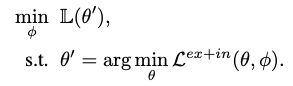
- lambda를 통해 두 loss를 조정
- inner loop에서는, ex-intrinsic reward를 동시에 사용하여 policy를 최적화
- outer loop에서는 vector value loss를 최소화 하기 위해 intrinsic loss를 최적화
Inner Loop: Optimizing , building the connection between and φ
- Policy gradient theorem에 의해 gradient를 통한 학습
Outer Loop: Optimizing φ
- outer loop에서는 상기 언급한 두 objective를 충족시키기 위해 vector loss를 최적화
- 우리는 φ에 대한 supervision이 없지만, chain rule을 통해 gradient를 획득할 수 있음
