Large Language Model Augmented Narrative Driven Recommendations (RecSys 2023)

INTRODUCTION

- RS는 매우 유용한 tool
- Interaction base recommendation은 효과적이나, 모호한 idea, 혹은 desire 하는 item이 특정 context에 한정 된 경우 이는 효과적이지 않음
- 이러한 맥락에서, user는 dialogue의 형태로 추천을 요청하는 경우가 많음, 그릭도 현재의 추천 시스템에서 이는 limitation이 존재
- 이러한 complex NDR(narrative driven recommendation)은 필수적이며, LLM은 이를 효과적으로 해결할 수 있음
- 본 연구는 기존 user-interaction dataset을 augmentation하여 NDR에 사용하려 함
- InstructGPT를 기반으로 synthetic query를 생성한 뒤, 유저 리뷰 기반 likelihood를 통해 적절한 query를 선택 및 이를 통해 fine tuning하는 것
- 이는 NDR dataset에 비해 기존 classic dataset의 규모가 훨씬 크다는 것에서 착안
METHOD
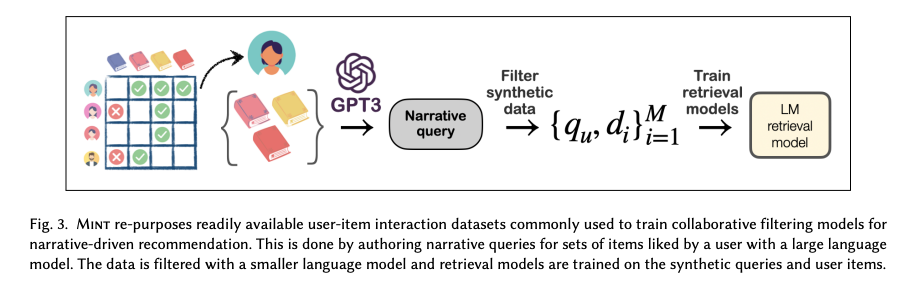
Problem Setup
- 우리는 NDR을 ranking task로 정의
Proposed Method
- 우리의 모델 MINT는 LLM을 통해 generation된 synthetic dataset을 사용해 LLM을 fine-tuning하는 것
Narrative Queries from LLMs.
- 우리는 InstructGPT를 우리의 query generation model QGEN으로 사용
- 3 개의 few shot example을 통해 사용자를 선정하여 query를 generate
Filtering Items Synthetic Queries.
- 합성 query는 관심사의 일부분 만을 포착할 것 이기에, PLM을 사용하여 likelihood를 계산 해 높은 우도의 아이템 만을 synthetic data로 사용
- 이는 실험적으로 효과적인 query generation 방법론임이 입증 됨
Training Retrieval Models
- 이후 bert의 아키텍쳐와 유사한 MPnet을 사용하여 training (이는 search 에서 흔히 사용되는 모델)
- Bi-Encoder를 통해 embedding을 생성한 후 cross-encoder를 통해 query와 item의 ranking을 측정
- Triplet loss, CE loss로 각각 Bi-encoder와 cross-encoder를 학습
EXPERIMENTS AND RESULTS
- MINT를 publicly available testset을 통해 evaluate 및 ablation
Results
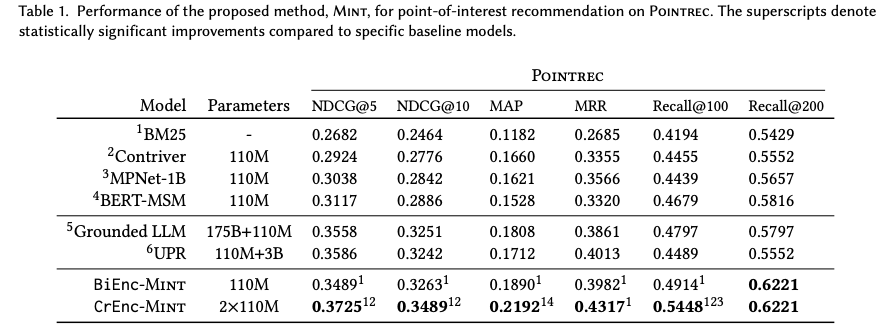
- ours가 baseline을 outperform
Ablations
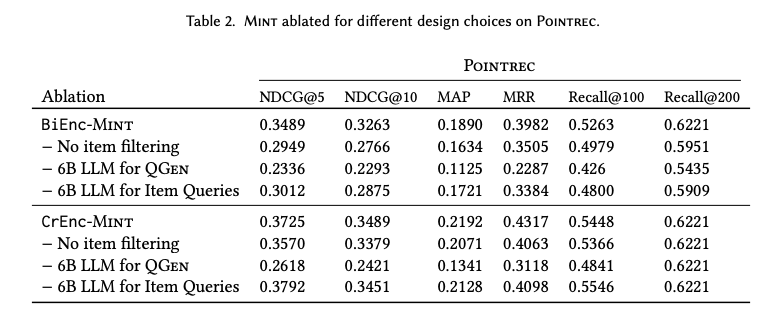
- 총 3가지 ablation
- No item filtering: filtering이 없어 더 large하고 noisy
- 6B LLM for QGEN: InstructGPT모델 사이즈를 175B에서 6B로
- 6B LLM for Item Queries: 더 적은 파라미터의 LLM
