Reflexion: Language Agents with Verbal Reinforcement Learning (NeurIPS 2023)

Introduction
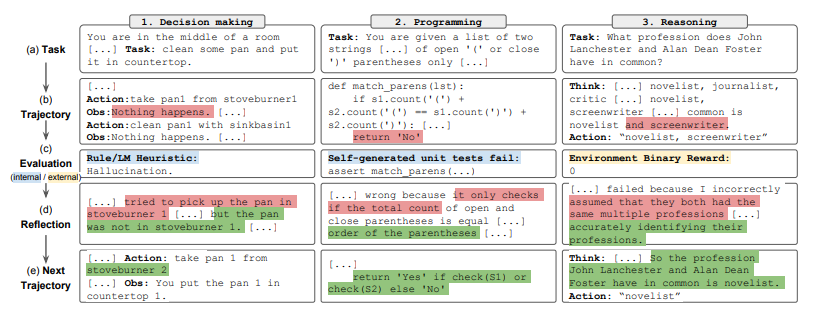
- 최근 LLM은 agent의 실현 가능성을 입증
- 지금까지의 Gradinet descent 기반 방법론은 time consuming
- 우리는 verbal feedback을 기반으로한 강화학습 방법론 Reflexion을 제시
- Binary, scalar feedback을 textual summary로 전환하여 feedback
- 이는 의미적인 Gradient 신호 역할
- Figure와 같이, Reflexion agent는 실행, 평가, reflextion을 통해 행동을 최적화 함
- 유용한 feedback을 생성하는 것은 어렵기에, 우리는 binary feedback, 휴리스틱 feedback, LLM을 이용한 feedback을 사용
- 이는 여러개의 advantage를 가져옴
- Lightweight, doesn't need fine tuning
- 더 미묘한 feedback에 대응 가능
- 과거에 대한 명시적이고 해석 가능한 feedback이 가능
- future episode에 대한 더 explicit한 Hint를 제공
- 위의 세 가지 feedback 모두에서 LLM의 추론 능력 향상을 실험적으로 증명함
Reflexion: reinforcement via verbal reflexion
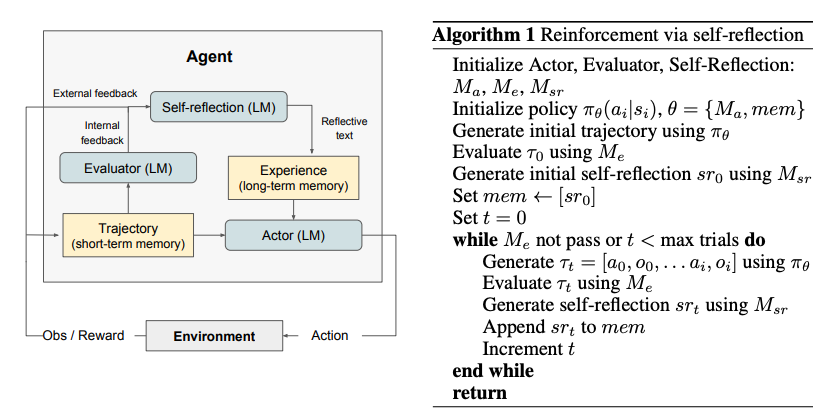
- 3 가지 모듈을 사용
- text와 action을 생성하는 Actor Ma
- output을 점수화 하는 Evaluator Me
- 언어적인 feedback을 생성하는 Self-Reflector Msr
Actor
- template화 된 text와 action을 생성하는 LLM을 기반으로 구성
- CoT, ReAct와 같은 다양한 모델을 사용할 수 있음
- 이를 비교하여 reflexion이 어떻게 verbal feedback을 받아들이는지 확인할 수 있음
- 또한 추가적으로 context를 제공하는 component인 mem을 사용
Evaluator
- Actor가 생성한 출력을 evaluate
- reward function을 자체적으로 정의하는 것은 어렵기에, 여러가지 evaluator model을 구현
- 추론 task에서는 정확한 일치(EM) 기반, 의사 결정 task에서는 휴리스틱 함수, 이외에도 LLM 자체를 evaluator로도 설정하여 실험 진행
Self-reflexion
- Reflexion에서의 key component
- future trial에 valuable한 verbal self-reflection feedback을 generate
- 이러한 정보는 단순 scalar보다 더 많은 정보를 포함함으로, mem에 저장됨
- 예를 들어, multi-turn decision making에서, 한 동작이 틀린 것으로 판명되면 실패한 동작에 따라 어떤 틀린 action들이 취해질 것이라고 verbal feedback을 명시하여 이를 Memory에 저장할 수 있음
Memory
- Reflexion의 또 다른 핵심 component는 long-short term memory
- Actor는 결정을 단기와 장기 기억에 의존하며, 이는 인간의 추론 process와 유사
- actor의 행동들은 단기 기억의 역할을 수행하며, self-reflexion의 output은 장기 기억에 저장 됨
- 이 두 가지 요소는 context를 제공하여 여러번 시행에서의 결과를 바탕으로 actor가 더 나은 선택을 하도록 유도함
The Reflexion process
- 반복적인 최적화 process로 formulization
- actor의 τ0를 바탕으로 evaluator가 rt=Me(τ0)를 생성
- self-reflector가 τ0,r0를 바탕으로 verbal feedback sr0를 생성 후 mem에 저장
- Evalutor가 올바르다고 평가할 때까지 위 시행을 반복하며, token 제한을 준수하기 위해 저장되는 memory는 1~3개 내부로 선정함
Experiments
Sequential decision making: ALFWorld
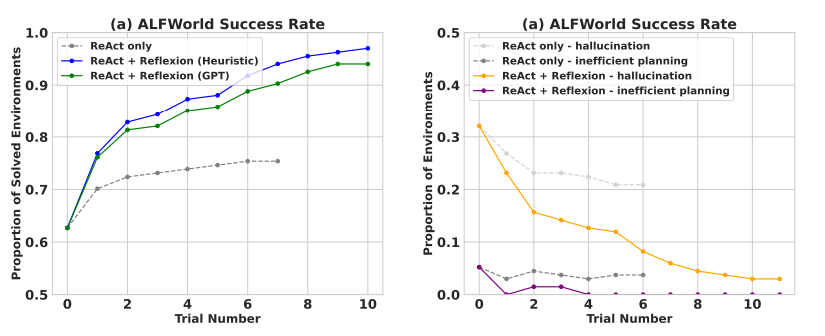
- 텍스트 기반 다단계 작업 해결 task
- ReAct를 actor로 사용
- 자체 evaluator는 LLM classification과 휴리스틱
- 휴리스틱에 경우, 3 사이클 이상 동일한 응답 혹은 수행된 작업의 수가 30을 초과할 때(비효율) reflect
Result
- ReAct + Reflexion이 ReAct를 outperform
Analysis
- 대부분 ReAct에서의 실패는 agent가 item을 소유하고 있다고 착각한 것
- Reflexion은 self-reflection을 통해 실패한 경로를 정리하여 자체적인 hint로 사용
- 긴 경로에서의 초기 실수를 쉽게 식별
- 아이템을 확인해야 할 경로가 너무 많을 때, 에이전트는 경험을 통해 철저한 경로 탐색이 가능
Resoning: HotpotQA
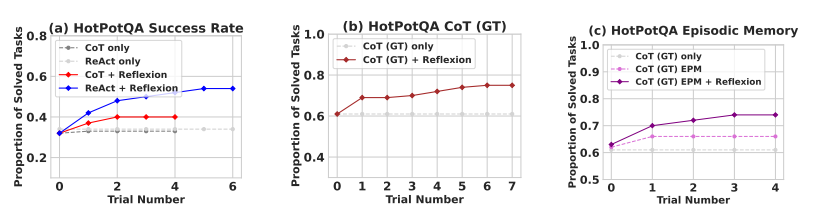
- Wikipedia기반 QA 데이터셋
- reasoning only ability를 test하기 위해 Reflexion + CoT를 step by step implementation
- CoT는 multi-step decision making technique이 아니기에, ground truth context를 agent에게 주어 isolate
- 추론 및 답변 능력을 test하기 위해 Reflexion + ReAct를 구현
- Wikipedia API를 사용하여 관련 문맥을 검색하고, 단계별 사고를 통해 답변을 추론하도록 함
Result
- 모두 outperform
- 특히 CoT, ReAct 등은 모두 첫 번째 시도에서 실패하였을 때 이후 계속 실패하였지만, reflexion은 3 번까지 다시 시도
- 더 나아가 실제 문맥에 접근할 수 있는 CoT(GT) 조차 39% 실패하였지만, Reflexion은 잘함
Analysis
- (c) figure에서 CoT, CoT + EPM (가장 최근 trajectory), CoT + Reflexion을 비교
- 가장 최근 경로를 포함한 EPM이 있을 때 성능 증가를 보이지만, Reflexion이 더 우세
- 이는 refinement-only approach가 self-reflection guided refinement보다 열세함을 의미
Programming

- MBPP, HumanEval, 그리고 our new dataset인 LeetcodeHardGym으로 평가
Result
Limitations
- policy optimization은 local minima solution에 빠질 가능성이 존재
- sliding window로 long-term memory를 제한한 본 연구와 달리, vector embedding database, SQL DB 등을 활용한다면 구조를 더 강화할 수 있을 것
Broader impact
- LLM은 외부 environment 및 인간 상호작용에서 더 널리 사용됨
- Our agent는 높은 자동화와 업무 효율성을 가져올 수 있지만, 오용시 위험을 증대할 수 있음
- 따라서 안전 및 윤리적 고려 사항이 요구됨
- 반면, 강화학습은 black box 및 optimization 설정에서 어려움이 존재
- Our verbal RL은 일부 문제를 해결하며 explain에 용이
- 예를 들어, 인간이 이해하기 어려운 tool-usage에 경우, self-reflxion을 통해 proper intent를 파악할 수 있음
