
Knowledge Distillation
지식 + 증류
딥러닝에서 증류는 추출을 의미
큰 모델로부터 증류(추출)한 정보를 작은 모델로 transfer 하는 과정을 Knowledge Distillation이라고 할 수 있음
Why?
효율적인 model deployment 를 위해
Heavy한 모델은 성능이 좋으나 용량이 크고, 예측 소요 시간이 김
단순한 모델은 성능이 비교적 좋지 않으나 효율적
이때 Heavy한 model의 지식을 small model에 증류해준다면?
Profit!
When?
“Distilling the Knowledge in a Neural Network” (2014 NIPS)로 부터 등장
논문은 다음과 같음
- 앙상블과 같은 복잡한 모델을 다량의 유저에게 배포하는 것은 하드웨어적으로 어려움
- 앙상블이 가진 지식을 단일 모델로 전달해주는 기존 기법이 있으나 그보다 더 일반적인 연구
- MNIST 데이터를 사용해, 큰 모델로부터 증류된 지식이 작은 모델로 잘 전달되는지 확인
- 앙상블 학습 시간을 단축하는 새로운 방법의 앙상블을 제시
How?
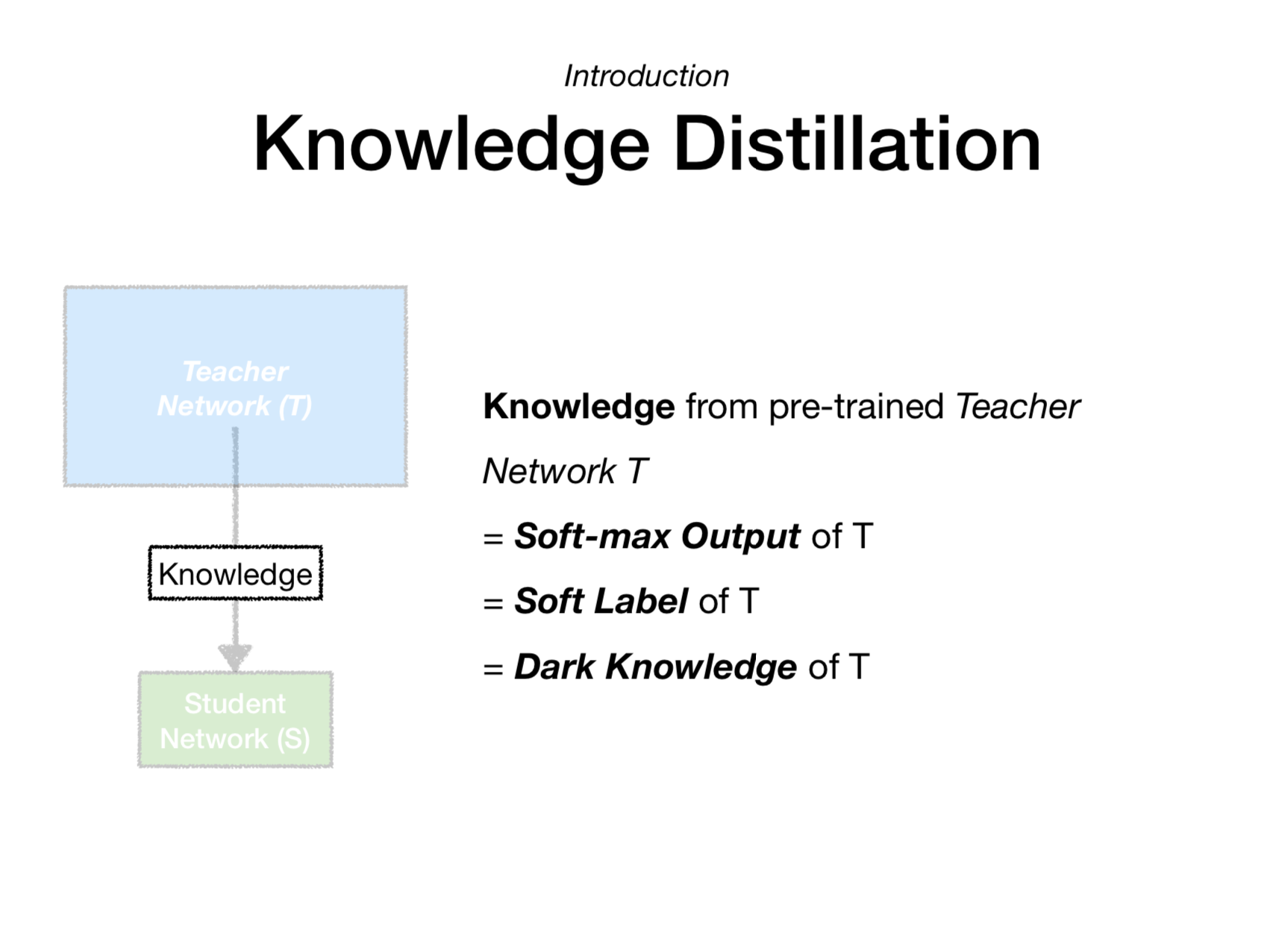
T를 온도라고 표현하여, softmax output을 student model로 증류
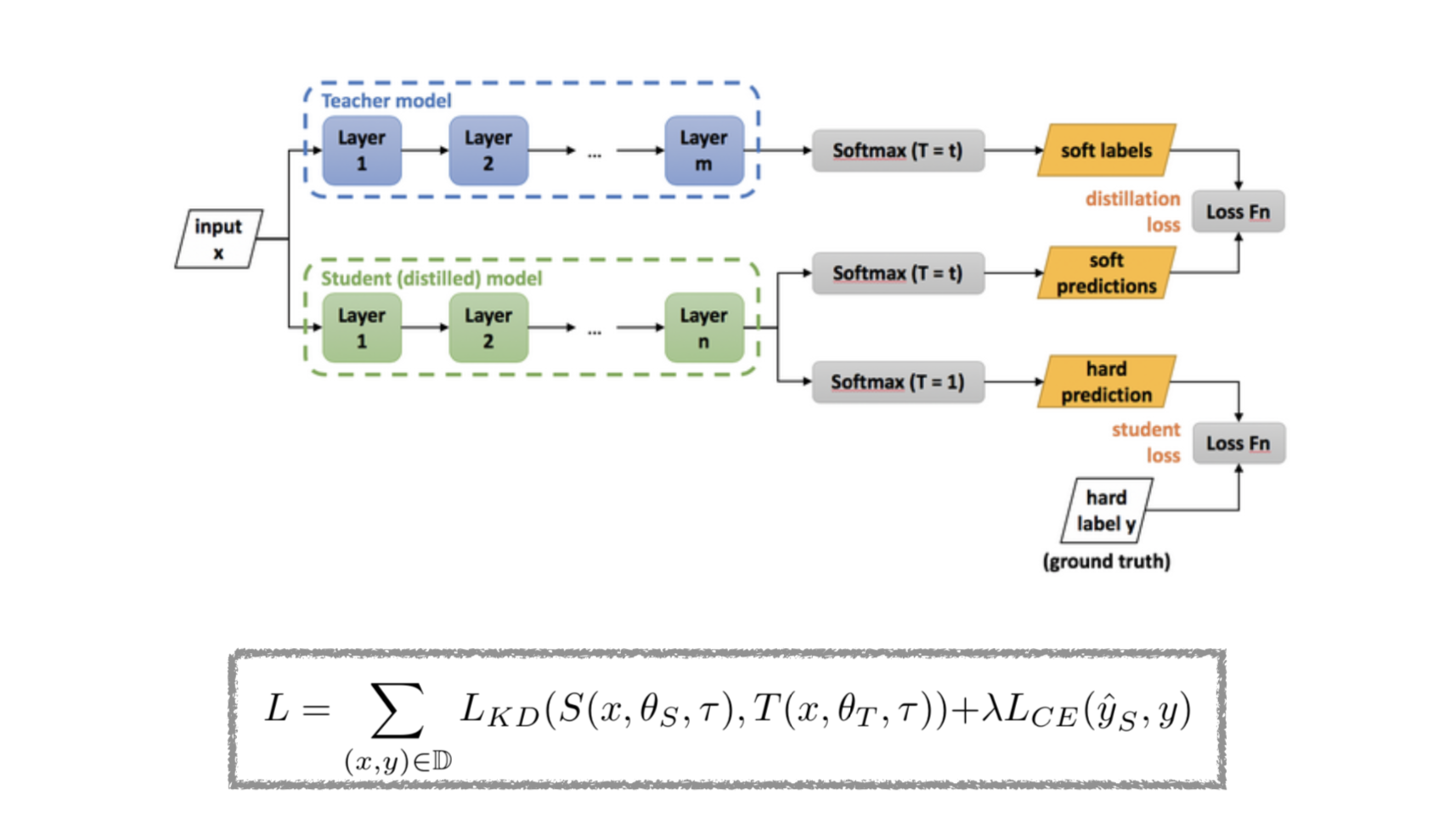
다음과 같은 손실 함수를 통해 small model이 학습하는 것
ETC
- Knowledge Distillation과 Transfer Learning의 차이
- Transfer Learning은 서로 다른 도메인에서 지식을 전달
- Knowledge Distillation은 같은 도메인 내 모델에서 지식을 전달
일종의 Model Compression 역할..
