
다양한 모델
Word2Vec
임베딩
- 주어진 벡터를 낮은 차원으로 만들어서 표현하는 방법
Sparse Representation
- 아이템의 전체 가짓수와 차원의 수가 동일
- One-hot encode
Dense Representation
- 전체 가짓수보다 훨씬 작은 차원으로 표현
- 실수값으로 표현
워드 임베딩
- 단어를 벡터로 표현하는 방법
- 단어 간 의미적인 유사도를 구할 수 있음
- 임베딩으로 표현하기 위해서는 학습 모델이 필요함
Word2Vec
- 뉴럴 네트워크 기반
- 대량의 문서 데이터셋을 Vector 공간에 투영
- 효율적이고 빠름
CBOW
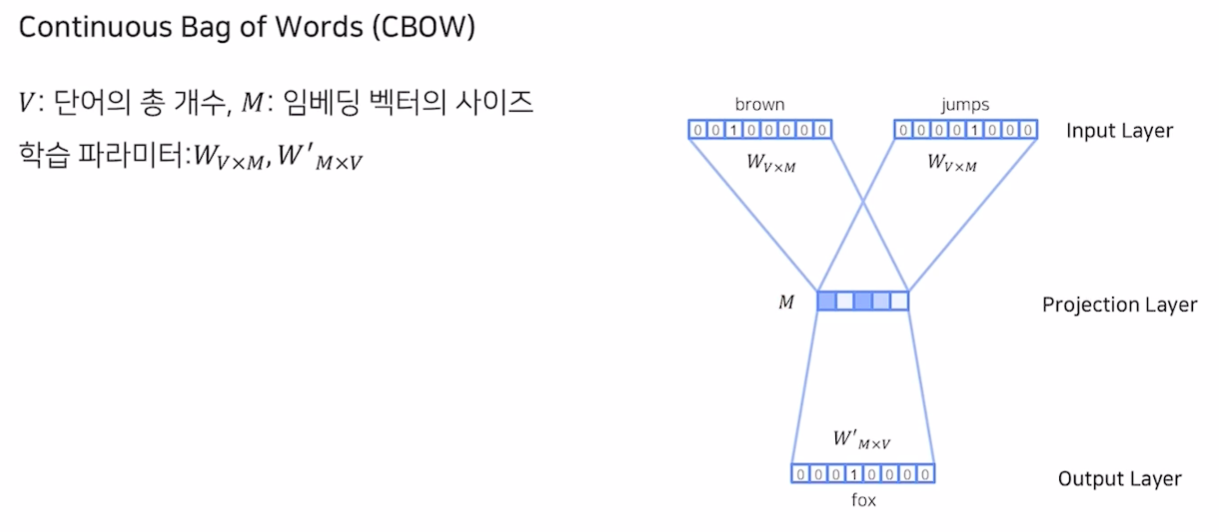
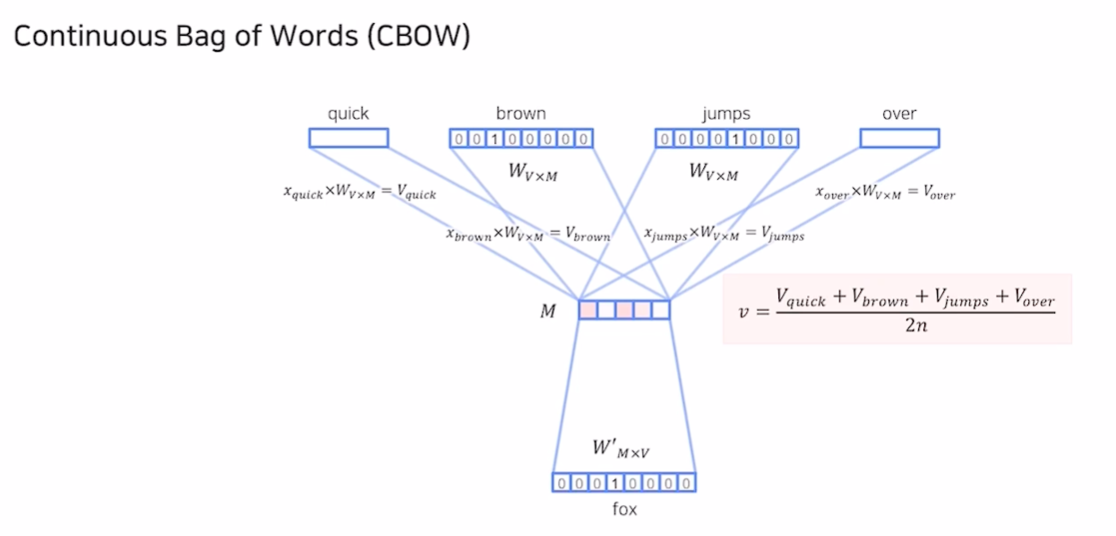
- Continuous Bag of Words
- 주변에 있는 단어로 센터에 있는 단어를 예측
- 단어를 예측하기 위해 앞 뒤로 몇개의 단어를 사용할 지 정해야 함 (Window)
- Multi Classification task
Skip-Gram
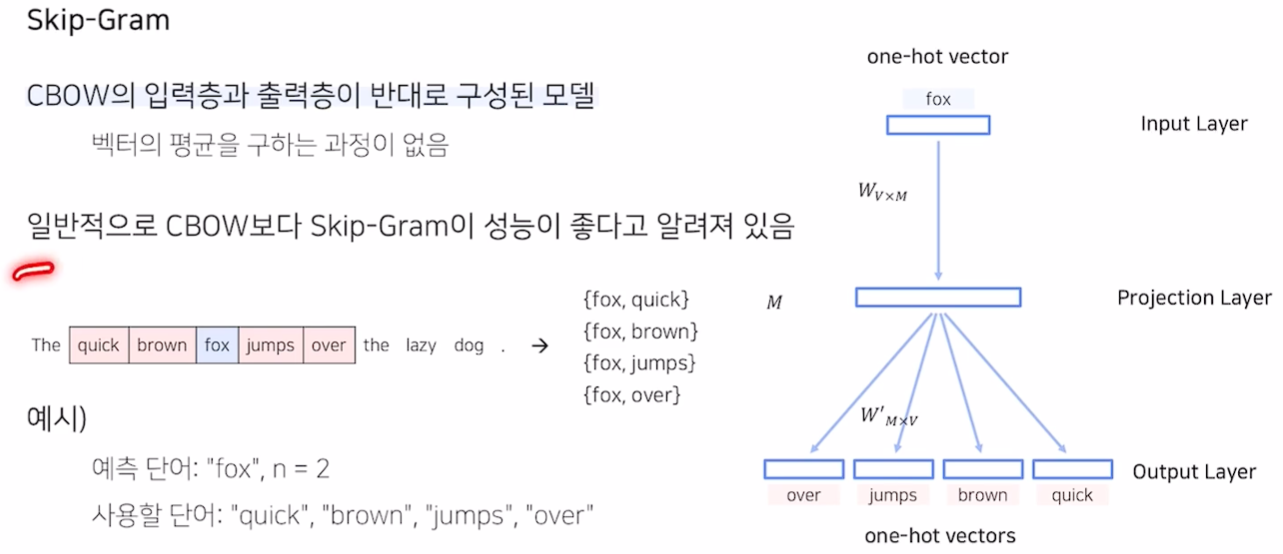
- CBOW의 입력층과 출력층이 반대로 구성된 모델
- 일반적으로 CBOW 보다 Skip-Gram이 성능이 좋다고 알려져 있음
Skip-Gram with Negative Sampling
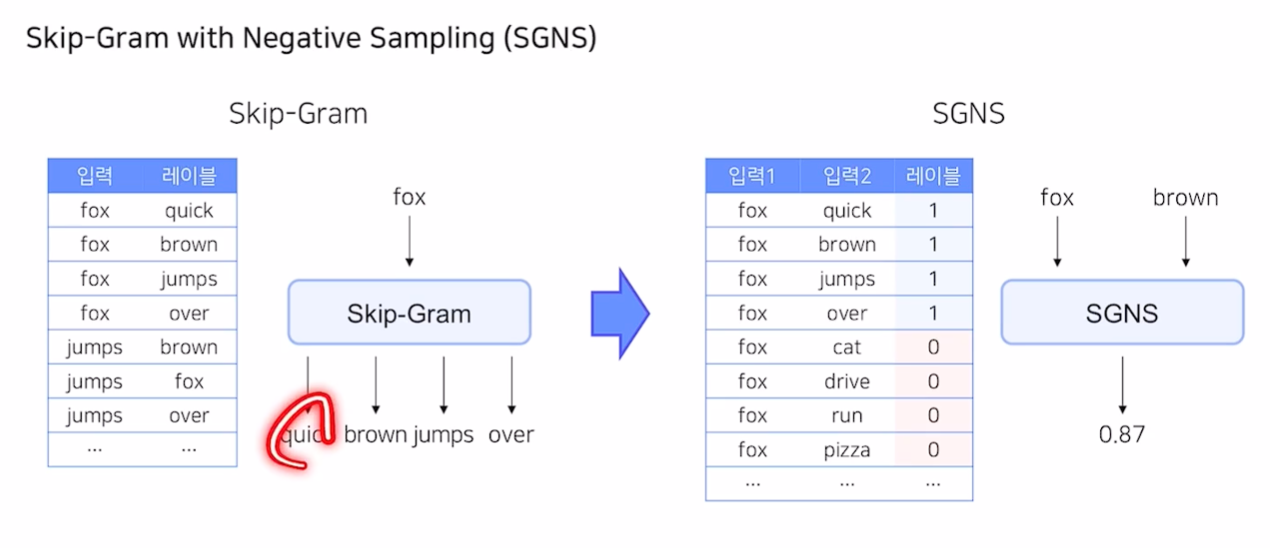
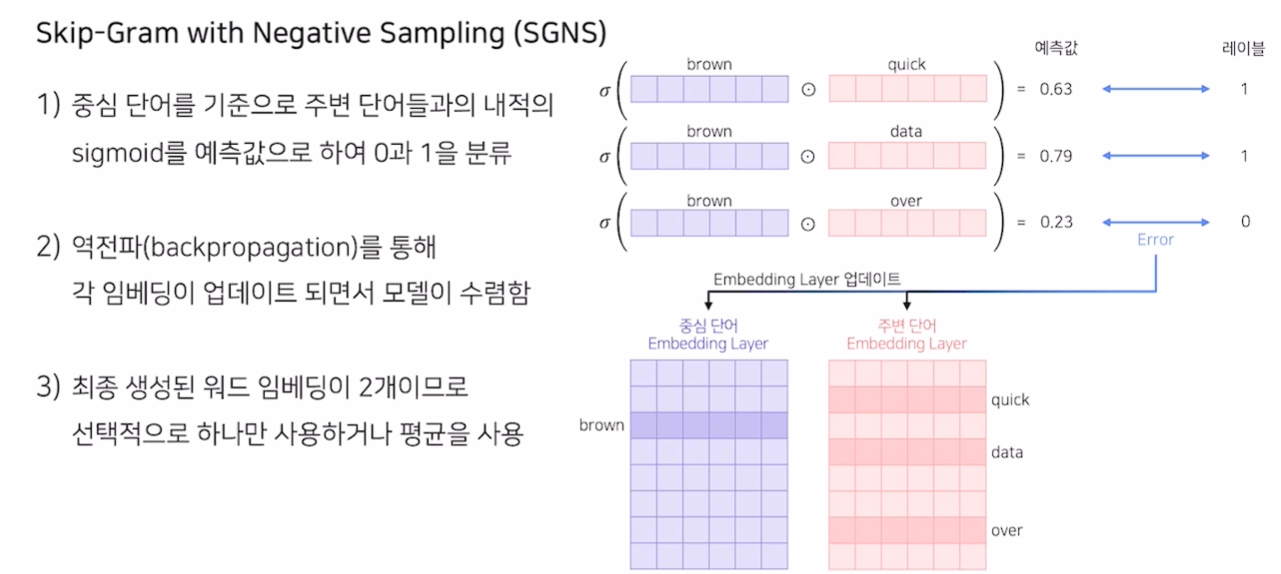
- 주변에 그 단어가 있다면 1, 없으면 0 을 예측하는 Binary Task로 변형
- 레이블이 Input이 되어, 관련 없는 단어를 강재로 Sampling
Item2Vec
-
SGNS를 추천 시스템에 사용한 모델
-
추천 아이템을 사용하여 임베딩
-
유저가 소비한 아이템 리스트를 문장으로, 아이템을 단어로 가정
-
SGNS 기반의 Word2Vec을 사용해 아이템을 벡터화
-
유저와 아이템 관계를 사용하지 않음
-
공간적 정보를 무시하므로, 동일한 아이템 집합 내 쌍은 모두 SGNS의 Positive Sample 이 됨
-
가능한 모든 집합으로 Positive Sample을 만듬
-
아프리카 TV의 Live2Vec, Spotify의 Song2Vec 등으로 파편화
Approximate Nearest Neighbor
Nearest Neighbor
- Query Vector와 가장 유사한 Vector를 찾는 알고리즘
- 아이템의 유사도 연산이 필요
- 추천 시스템에선, 유저 아이템 Vector와 가장 인접한 이웃을 찾는 것
Brute Force KNN
- 가능한 모든 벡터를 구해 가장 유사한 벡터를 구하는 것
- 벡터의 수가 늘어날수록 연산 속도가 비효율
- 정확도를 조금 포기하더라도, 빠른 속도로 근접 이웃을 찾을 필요가 있음
근사 해법
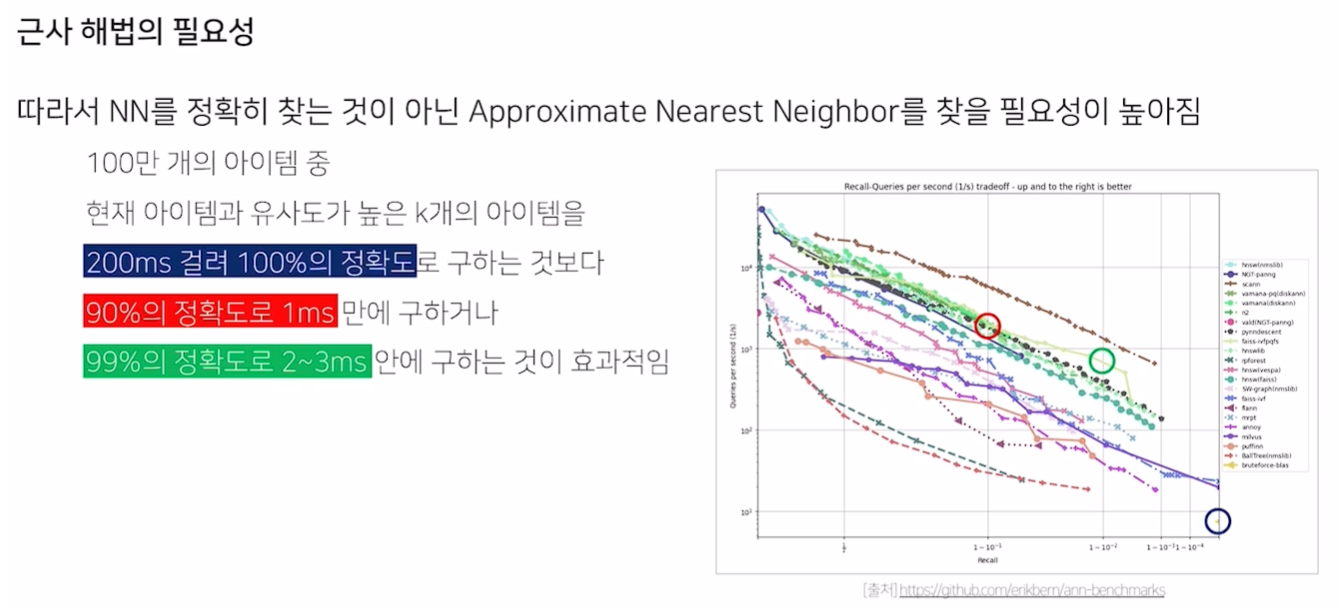
- Accuracy와 Speed의 Trade-Off가 존재
ANNOY
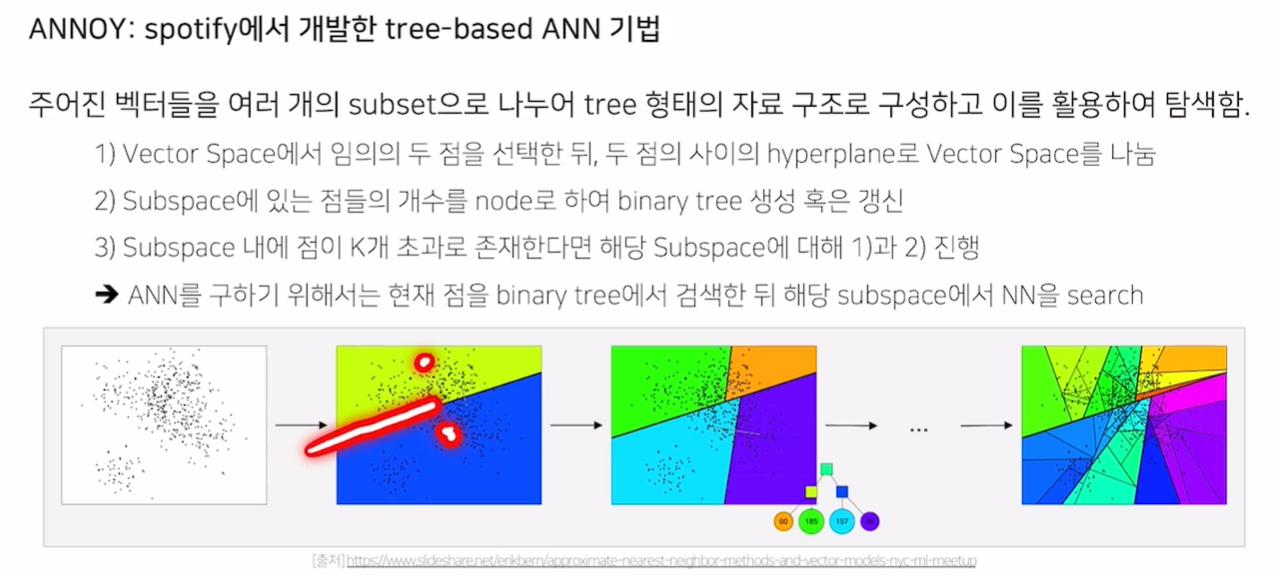
- Spotify에서 개발한 tree-based ANN 기법
- 주어진 벡터를 여러 개의 subset으로 나누어, tree 형태의 자료 구조로 구성 및 탐색
- HyperPlane을 반복적으로 계산해 분리
- 가장 마지막 노드의 SubSpace에서 NN 연산 수행
문제점
- 가장 근접한 점이 tree의 다른 node에 있을 경우, 해당 점은 subset에 포함되지 못함
해결 방안
- priority queue를 채택해 tree내의 다른 노드도 탐색하는 것
- binary tree를 여러 개 생성해 병렬적 탐색 (일종의 Ensemble)
Hyperparameter
- number of tree
- NN을 구할 때 탐색하는 node의 개수
특징
- 다른 ANN에 비해 간단하고 가벼움
- 이웃의 개수를 알고리즘이 보장
- Parameter를 통해 accuracy / speed 조정 가능
- 새로운 데이터 추가마다 Tree를 계산해야 하는 불편함
Hierarchical Navigable Small World Graphs (HNSW)

- 벡터를 그래프의 노드로 표현하고 인접한 벡터를 edge로 연결
- 유사한 노드들 끼리만 edge를 갖는 것
Inverted File Index (IVF)
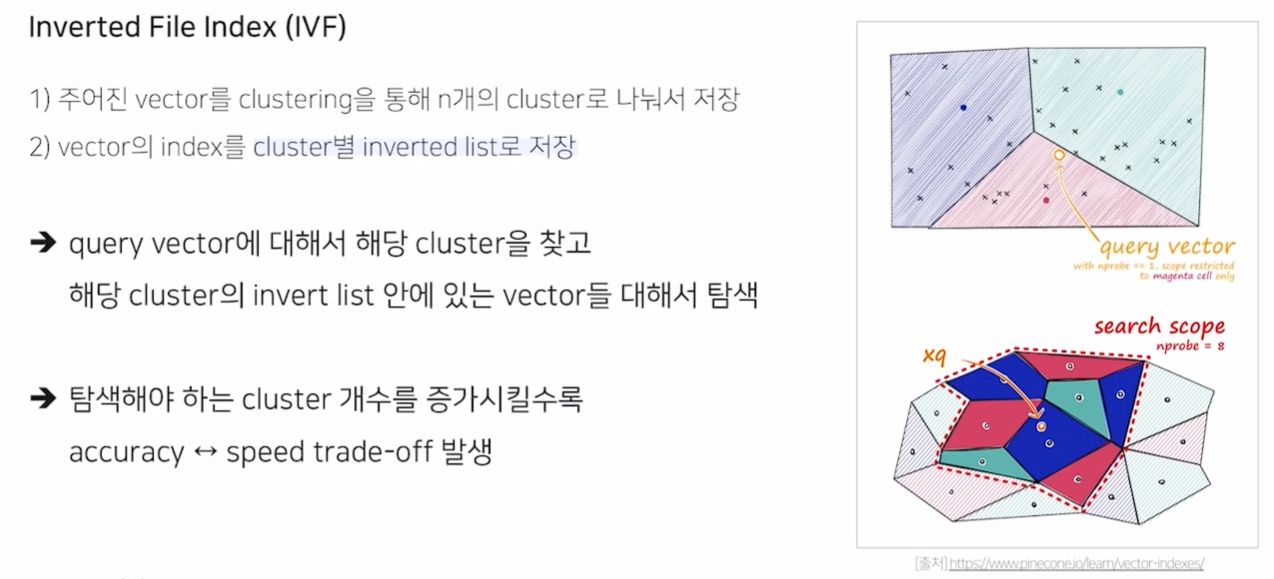
- K means clutering을 통해 n 개의 cluster로 저장
Product Quantization - Compression

- 탐색 공간을 줄이는 것이 아닌, 벡터의 값을 압축해서 표현
- PQ와 IVF를 동시에 사용하여 더 빠르고 효율적인 ANN 수행 가능
