
Collaborative Filtering
Collaborative Filtering (CF)
- 협업 필터링
- 많은 유저들의 기호 정보를 이용해 유저의 관심사를 자동으로 예측하는 방법
- 데이터가 축적될수록 추천은 정확해질 것이란 가정에서 출발
목적
- 유저 u가 아이템 i에 부여할 평점을 예측하는 것
방법
- 주어진 데이터로 유저-아이템 행렬 생성
- 유사도 기준을 정하고, 유저 아이템간의 유사도 생성
- 주어진 평점과 유사도를 활용하여 행렬의 비어 있는 평점을 예측
분류
- Neighborhood-based CF (Memory-based CF)
- Model-based CF
- Hybrid CF
Neighborhood-based CF, NBCF
User-based CF, UBCF
- 유저간 유사도를 구한 뒤, 타겟 유저와 유사도가 높은 유저들이 선호하는 아이템을 추천
Item-based CF, IBCF
- 두 아이템이 얼마나 유사한 평점을 받았는가
- 아이템간 유사도를 구한 뒤, 타겟 아이템과 유사도가 높은 아이템 중 선호도가 큰 아이템을 추천
최종 목적
- 유저 u가 아이템 i에 부여할 평점을 예측하는 것
특징
- 구현이 간단하고 이해가 쉬움
- 아이템이나 유저가 늘어날경우 확장성이 떨어짐 (Scalability)
- 주어진 평점/선호도가 적을 경우, 성능이 저하 됨(Sparsity)
Sparsity
- 실제 행렬 대부분의 원소는 비어 있음 (희소 행렬)
- NBCF를 적용하려면 적어도 Sparsity ratio가 99.5%를 넘지 않는 것이 좋음
K-Nearest Neighbors CF
NBCF의 한계
- 아이템 i에 대한 평점 예측을 위해서 모든 유저와의 유사도를 구해야 함
- 유저가 많아질 경우 계속해서 연산해야 하고, 성능이 떨어짐
KNN
- 유저와 유사한 K명의 유저를 이용해 평점을 예측
- 유사성은 우리가 정의한 유사도 값으로 판단
유사도 측정법
- 두 개체 간의 유사성을 수량화 하는 실수 값 함수 혹은 척도
MSD

- 추천 시스템에서만 사용
- 유클리드 거리에 반비례
- 분모가 0이 되는 것을 방지하기 위해 1을 더함
Cosine Similarity

- 벡터의 각도를 이용하여 구함
- 가리키는 방향이 얼마나 유사한지를 의미
Pearson Similarity

- 피어슨 상관계수와 동일
- 코사인 유사도와 다른 점은 표본 평균으로 정규화
Jaccard Similarity

- 집합에 대한 유사도
- 평점 데이터의 경우 일종의 threshold로 이진 값을 생성해야 함
Rating Prediction
Average
- 다른 유저들의 rating의 평균을 계산
- 유저의 가중치를 동일하게 적용하는게 맞는가?
Weighted Average
- 유저 간의 유사도 값을 가중치로 사용해 rating의 평균을 계산
Absolute Rating
- 위의 두 방법이 Absolute Rating
- 유저마다 평점을 주는 기준이 다르면 예측이 정확하지 않다는 한계가 존재
Relative Rating

- 개별 유저의 평균 평점을 구하고, 그 편차를 사용
- 예측 deviation을 구하는 것
Model Based Collaborative Filtering
- 추천 시스템은 sparsity와 scalability issue가 항상 존재
- 데이터가 희소하거나, 유저 아이템이 너무 많으면 문제가 생긴다는 것
- MBCF는 항목 간 유사성을 단순 비교하는 것에서 벗어나, 데이터의 내재한 패턴을 이용해 추천하는 CF 기법
- Parameter를 학습하는 ML 기법
- NBCF는 유저/아이템의 벡터를 계산된 형태로 저장하여 Memory based라고도 불림
장점
- 모델 학습/서빙에서 빠름
- Sparsity, Scalability 문제 개선
- Overfitting 방지
- Limited Coverage 극복 (공통의 유저, 아이템이 없어도 덜 민감)
Implicit Feedback
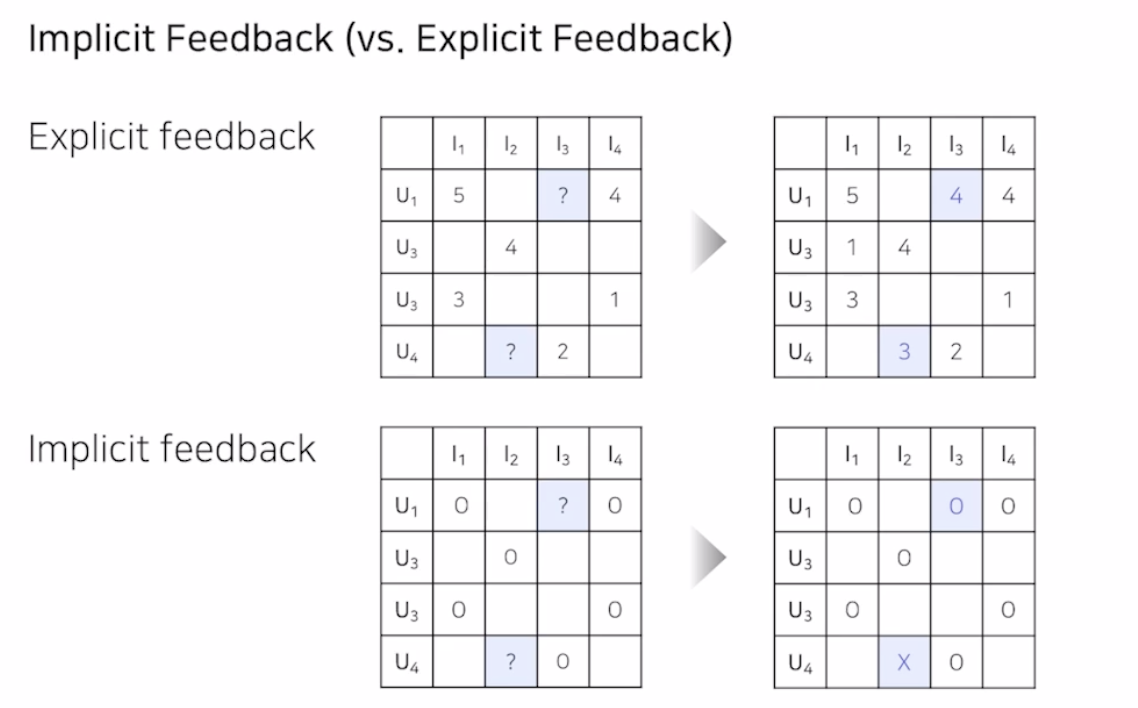
- 평점, 별점과 같은 선호도를 직접 알 수 있는 데이터는 Explicit Feedback
- 실제 추천 시스템에는 Explicit Feedback 보다 Implicit Feedback이 훨씬 많음
- 유저-아이템 간 상호작용이 있었다면 1을 원소로 가짐
Latent Factor Model
- 유저와 아이템의 관계를 잠재적 요인으로 표현할 수 있음
- 유저 - 아이템 행렬을 저차원으로 분해하는 방식으로 작동
- 같은 벡터 공간에서 임베딩 할 경우, 유저와 아이템의 유사한 정도를 확인할 수 있음
- Latent 벡터 차원의 의미를 알기는 힘듬
Singular Value Decomposition
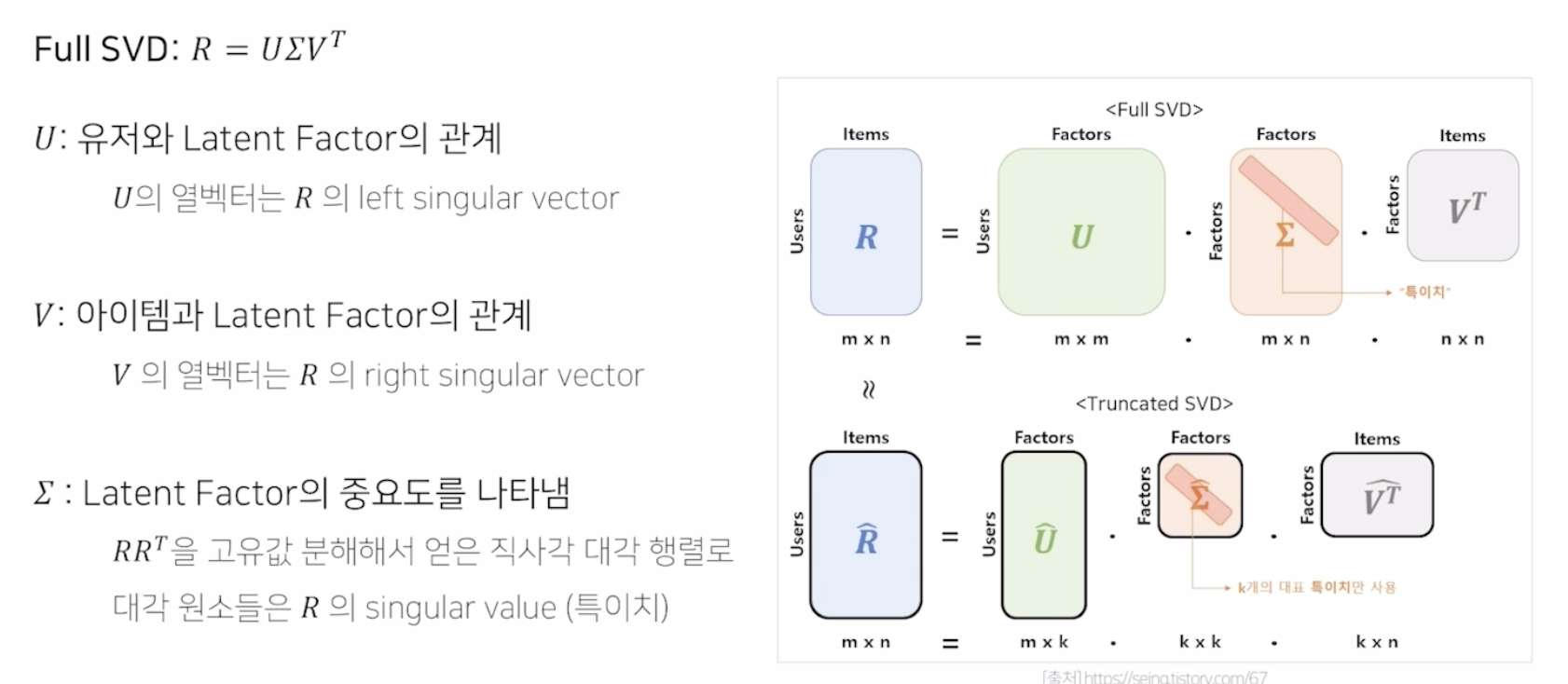
- 2차원 행렬을 분해하는 기법
- 유저 잠재 요인 행렬, 잠재 요인 대각 행렬, 아이템 잠재 요인 행렬로 분해
- 선형 대수학에서 차원 축소 기법 중 하나로 분류 됨
- m x m 의 user matrix, n x n 의 item matrix, m x n 의 잠재 요인 대각 행렬로 구성
- 다만 모든 특이치를 사용하는 것이 아닌, 특이치 중 k 개를 사용해 R_hat을 복원
- 결국 m x k , k x k, k x n 의 3 행렬을 유추하는 것
한계
- 분해하려는 행렬의 Knowledge가 불완전 할 때 정의되지 않음 (sparsity가 존재할 때)
- 결측된 entry를 모두 채우는 Imputation을 통해 Dense matrix를 만들어야 함
- 즉 왜곡되어 예측 성능을 떨어트림
- 이는 MF의 등장 배경이 됨
Matrix Factorization
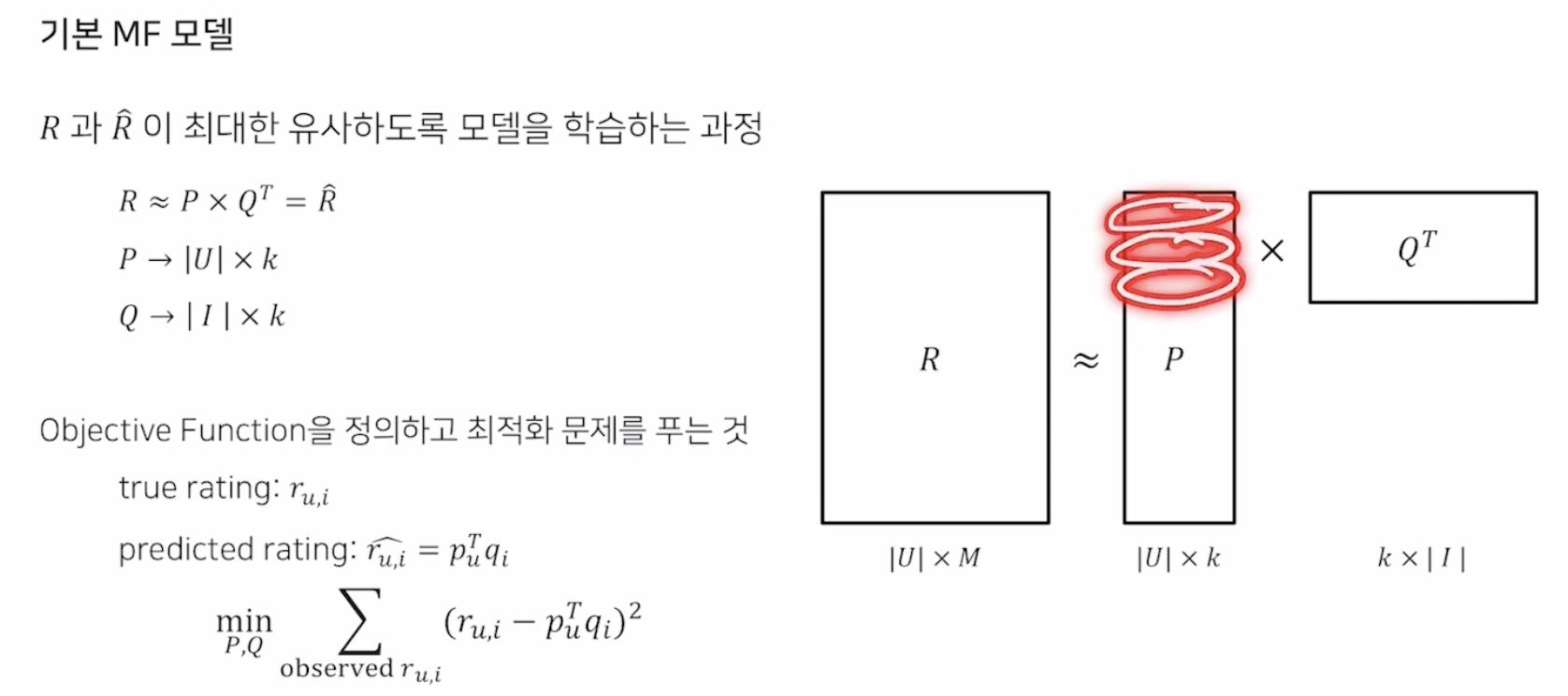
- 유저 아이템 행렬을 저차원의 User, Item matrix로 분해하는 것
- 관측된 선호도만 모델링에 활용
Objective Function

- 최적화 Term과 L2 Norm 적용

- SGD를 통해 학습
Adding Biases


- 전체 평균, 유저/아이템 별 Bias를 추가
- 이 편향도 학습되는 파라미터
Adding Confidence Level

- 모든 평점이 동일한 신뢰도를 갖지 않음 (대규모 광고와 같이 특정 아이템이 많이 노출되는 경우, 유저 아이템 평점이 정확하지 않은 경우)
- Cu,i term이 추가
Adding Temporal Dynamics

- 시간에 따라 변화는 유저, 아이템의 특성을 반영
- 시간이 흐르면서 평점을 내리는 기준이 엄격해질 수 있음
- 시간적 term을 추가한 것
MF for Implicit Feedback
Alternative Least Square (ALS)

- 데이터가 많아지면 SGD 학습 속도가 매우 느려짐
- Update 해야 하는 User, Item matrix를 하나를 고정하고 하나씩 Update하는 것
- 이는 Least-Square 문제로 풀 수 있음 (해를 수식으로 구할 수 있음)
- 수렴할 때 까지 학습
- SGD에 비해 더 Robust, 빠른 학습
MF for Implicit Feedback

- adding confidence level의 응용
Preference
- 유저가 아이템을 선호하는 여부를 Binary로
Confidence
- 유저가 아이템을 선호하는 정도를 나타내는 increasing Function
목적 함수


- Cu,i를 고려해 rating을 고려하게 됨
Bayesian Personalized Ranking
- 베이지안 추론을 반영한 Implicit Feedback MF
Personalized Ranking
- 사용자에게 순서가 있는 아이템 리스트를 제공하는 문제
- 사용자의 클릭, 구매 등 로그는 Implicit Feedback
- 선호도의 정도가 나타나지 않음
- 관측되지 않은 아이템은 두 가지를 고려해야 함
유저가 실제로 관심이 없음
유저가 아직 모름 - 유저의 아이템에 대한 선호도 Rank를 만들어 제공
접근

- User 별로 Item x Item matrix를 생성

최대 사후 확률 추정

- 베이즈 정리를 통해 사후 확률을 Update
- 주어진 정보를 잘 표현하는 Parameter를 추정

- 시그모이드 Function 을 사용해 rating을 0과 1사이의 확률로 변환
- 전부 곱해 Likelihood 를 계산

- 모수를 정규 분포 행렬로 가정

- 목적 함수는 미분 가능
- 다만 논문은 Bootstrap 기반의 SGD를 사용해야 한다고 함

- u, i의 재등장을 막아 성능을 높임

- 다음과 같은 수식으로 Gradient 종결
요약
-
Implicit Feedback 데이터 만을 활용해 아이템 간의 선호도 도출
-
Map 방법을 통해 파라미터 최적화
-
LearnBPR 이라는 Bootstrap 기반의 SGD를 활용해 파라미터 업데이터
-
MF에 BPR을 사용하여 성능 개선
