논문: https://arxiv.org/pdf/1512.03385v1.pdf
Abstract
neural networks에서 네트워크가 깊어질 수록 훈련하기 어려워 지는 문제를 해결 하기위해, (새로운 함수 훈련에 활용하는 대신) residual function 잔차함수를 활용하는 방법을 제시합니다. 실험을 통한 경험적 증거 제시를 통해 깊은 네트워크 훈련의 쉬운 최적화와 정확도를 보입니다.
ImageNet data set에 대해 152개의 레이어를 쌓은 실험에서 기존 VGG net보다 8배 깊은 깊이에서 더 낮은 복잡성을 확인 할 수 있었고, 3.57%의 오류로 ILSVRC 2015 classification task에서 1위를 차지했습니다. 이와 더불어 CIFAR-10 with 100 and 1000 layers data set에 대한 분석을 통해 논문은 앞서 제시한 방법에 대한 결과를 보입니다.
Introduction
이미지 분류에서 심층 네트워크는 중요한 역할을 하고 대단한 이점으로 작용한다고 여겨졌고, 당시의 주요 연구들의 결과에서 그런 결과가 나타났습니다. vanishing/exploding gradients 문제가 이 깊은 layer를 쌓는것에 대한 어려움을 만들었지만 여러 정규화를 통해 이는 해결됐습니다. 하지만 더 깊은 네트워크에서 "degradation"문제가 나타났고, 이 저하가 overfitting에 의한 문제는 아니라고 합니다.
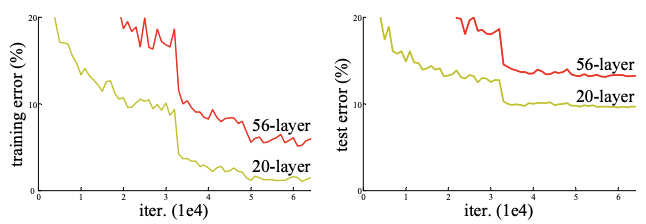
그 근거로 56-layer에서 20-layer에 비해 train, test set 모두의 error가 높은 것을 확인 할 수 있습니다.
논문에서는 이러한 문제점을 deep residual learning framework의 도입을 통해 해결합니다.
Deep Residual Learning
Residual Learning
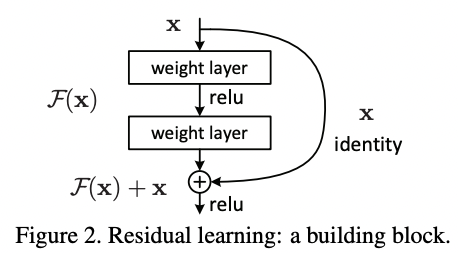
기존 매핑(underlying mapping)의 output F(x)대신 잔차 매핑(residual mapping)의 F(x)+x를 적용합니다. 또한 논문은 unreferenced mapping인 H(x)보다 residual mapping의 최적화가 더 쉽다는 가정하에 진행합니다.
Identity Mapping by Shortcuts
y = F(x, {Wi}) + x
각 블록에서의 정의 입니다. input dimension과 output dimension이 다를 경우 input에 linear projection하여 차원을 맞춰줍니다.
Network Architectures
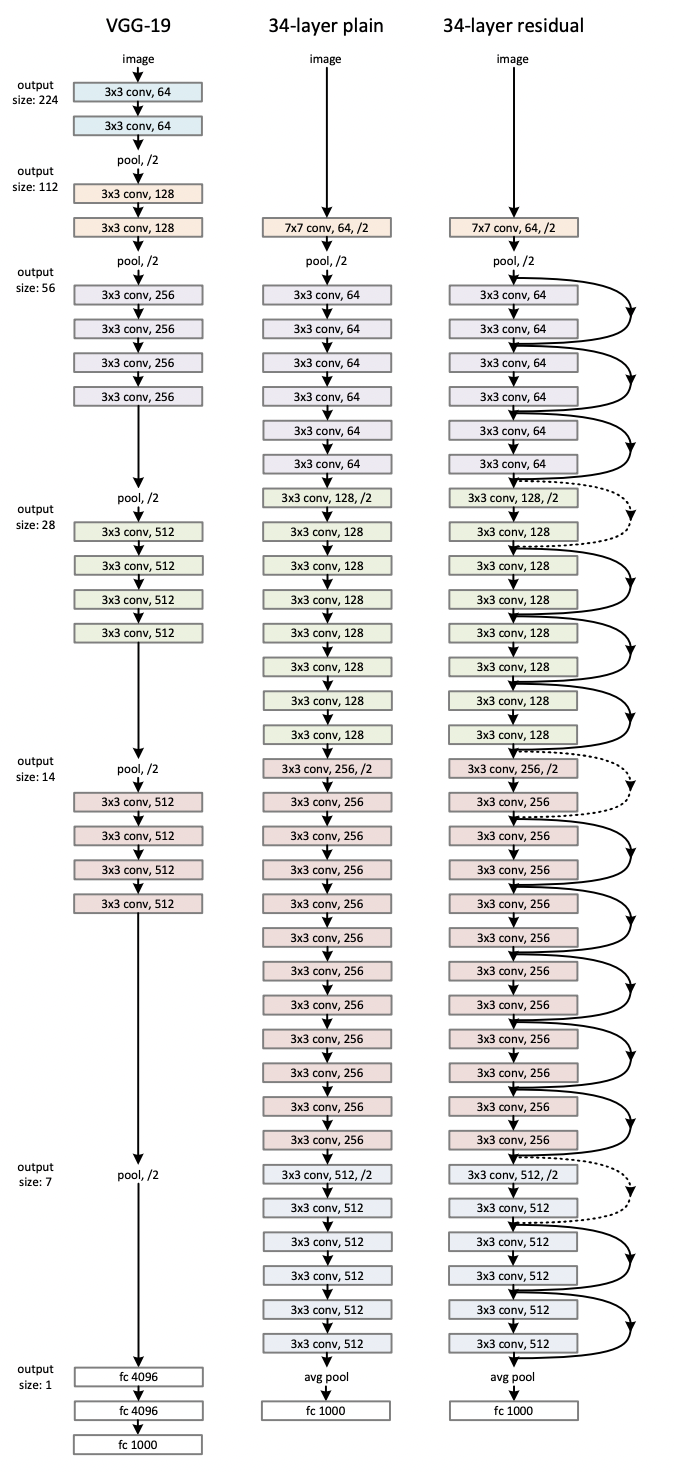
VGG, Plain, Residual 네트워크를 비교한 그림 입니다.
Plain Network
VGG net을 기반으로 합니다. feature map size를 통일하기 위해 레이어들이 같은 필터의 개수를 갖고, 또한 연산량 유지를 위해 feature map size가 2배가 되면 필터 수는 2배가 되도록 설계했습니다. Convolutional Layer는 3x3 필터로 구성했고, stride 2로 직접 downsampling합니다. 마지막은 global average pooling 후 1000-way fully-connected layer로 출력 변환하였고 softmax를 loss function으로 사용합니다. 이러한 구조의 Plain Network는 VGG net에 비해 filter가 적고 복잡도가 낮으며, 연산량은 18%밖에 되지 않습니다.
Residual Network
Plain Network을 기반으로, short connection을 적용했습니다. 차원이 증가하면 1)zero padding을 적용하여 identity shortcuts 효과를 내거나 2) projection을 통해 차원을 증가시켜 같은 차원으로 맞춰줍니다.
Experiments
ImageNet Classification
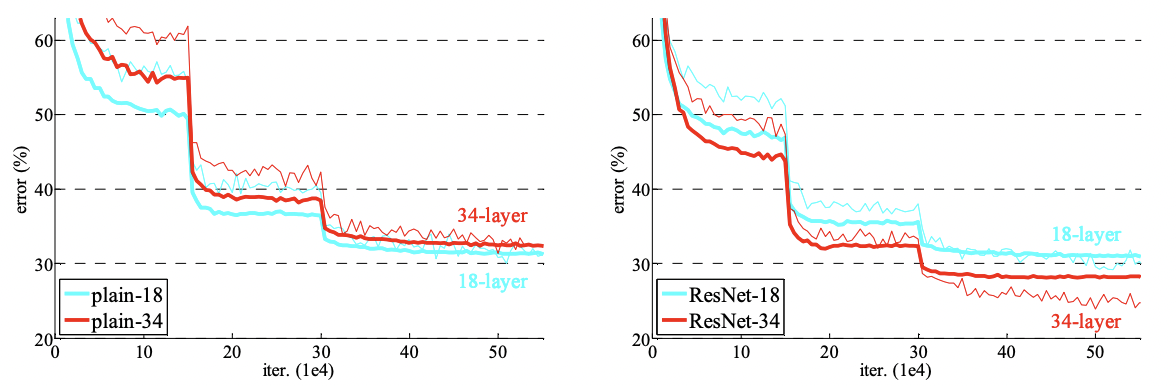
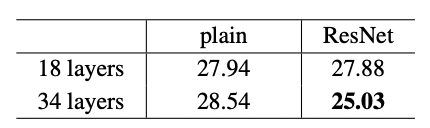
plain과 달리 ResNet을 사용했을 때 34 layers 일 때 18 layer 보다 성능이 향상된 것을 확인 할 수 있습니다. 이는 degration 문제가 해결 된 것을 나타냅니다. 즉, 깊이가 증가해도 정확도가 향상됩니다. 또한 수렴속도가 빨라 최적화에 유리합니다.
ensemble model
- 차원 증가를 위해 projection을 사용하고 다른 shortcut은 identity를 사용합니다.
- Bottleneck design을 사용합니다.
- 50 layer ResNet : 34-layer에 3-layer bottleneck block 적용 합니다.
- 101-layer and 152-layer ResNets
CIFAR-10 and Analysis

CIFAR-10 dataset에서도 layers가 증가 할 때 error가 감소하는 것을 확인 할 수 있습니다. 단, 110개 부터는 error가 증가하는데 이것은 overfitting이 원인일 것이라 예상되고 이는 dropout등의 방법을 통해 해결 할 수 있습니다.
