
모델 기반 추천 알고리즘 (model-based RS)
메모리 기반 추천 알고리즘(memory-based RS)
: CF(Collaborative Filtering)로 대표되며, 추천이 필요 할 때 마다 데이터로 계산하여 추천하는 방식입니다. 개별 사용자 데이터에 집중할 수 있지만, 모든 데이터가 매번 메모리에 올라와 있어야 하기 때문에 계산시간이 오래 걸린다는 특징이 있습니다.
모델 기반 추천 알고리즘 (model-based RS)
: 데이터로 한 번 모델을 생성해 놓고, 이 모델을 통해 추천을 제공하는 방식입니다. 모델 생성 때는 많은 계산이 요구되지만 매번 더 빠른 추천을 제공 할 수 있으며, 메모리 기반 RS와 달리 사용자의 평가 패턴으로 모델을 구상하기 때문에 잘 드러나지 않는 weak-signal을 더 잘 잡아 낼 수 있습니다.
: MF(Matrix Factorization) 방식과 deep-learning을 활용한 방식이 여기 속합니다.
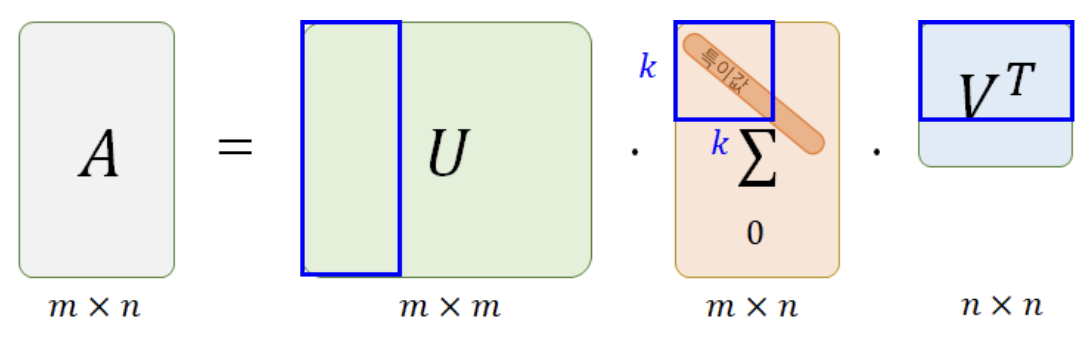
SVD vs MF
: 추천시스템 분야에서 흔히 SVD와 MF가 같은 의미로 사용되고는 합니다.
결론부터 말하자면 명백히 둘은 다른 기법이고, 실제로 SVD기법은 추천시스템에서 거의 사용되지 않습니다.
추천시스템의 데이터셋에는 사용자가 평가하지 않은 많은 null값이 존재하게 되는데,
- (3개의 행렬로 분해되는) SVD방식에서는 null을 대체한 0값이 하나의 값으로 적용돼서 학습 후에도 0에 근사한 예측값이 도출됩니다.
즉, null에 대한 예측이 제대로 이루어지지 못합니다.
- (2개의 행렬로 분해되는) MF방식은 모델을 학습하는 과정(SGD)에서 null(0)값을 제외하고 계산하는 구조이며, 이렇게 학습된 행렬 P,Q를 통해 null에 대한 예측도 정확하게 할 수 있습니다.
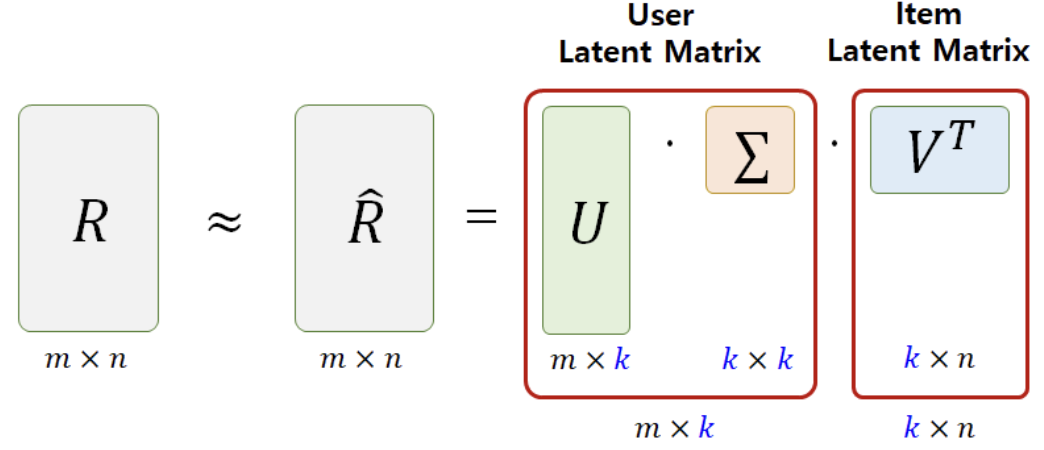
Matrix Factorization(MF) 알고리즘의 원리
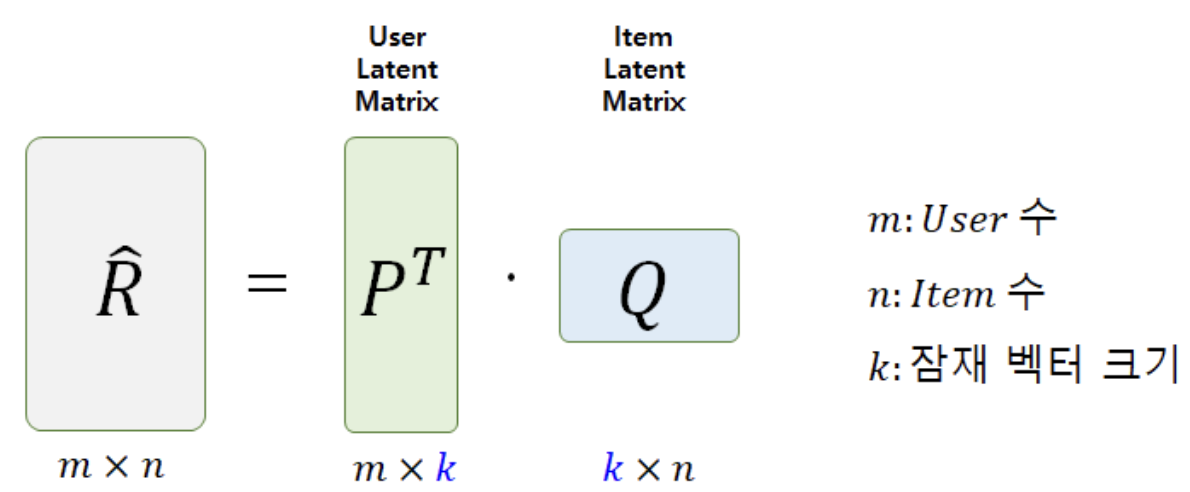
- MF 알고리즘은 R : [ user x item ] 형태의 full-matrix(평가데이터)를
- P : [ user x feature ]
- Q : [ item x feature ]
두 개의 행렬로 쪼개서 분석하는 방식입니다.
- 여기서 k개의 feature은 latent factor(잠재요인)로, user와 item이 공유하고 있는 특성입니다. 이 k개의 특성을 매개로 user와 item의 관계성이 형성됩니다.
- MF 알고리즘을 통해 우리가 궁극적으로 얻으려는 모델의 핵심은, user와 item의 특성이 가장 잘 적용된 각각의 latent factor value를 찾는 것 입니다.
- P, Q기반으로 예측값을 구하는 기본 식
MF 기반 추천 알고리즘의 과정
- 잠재요인의 개수 K를 정합니다.
- 임의의 값으로 채워진 두 행렬 P(m x k), Q(n x k)를 생성합니다.
- 실제 평점과 예측 평점 오차를 줄여가며 P, Q를 수정합니다. (SGD)
- 기준에 도달 할 때 까지 3.과정을 반복 합니다.
-
기본 오차
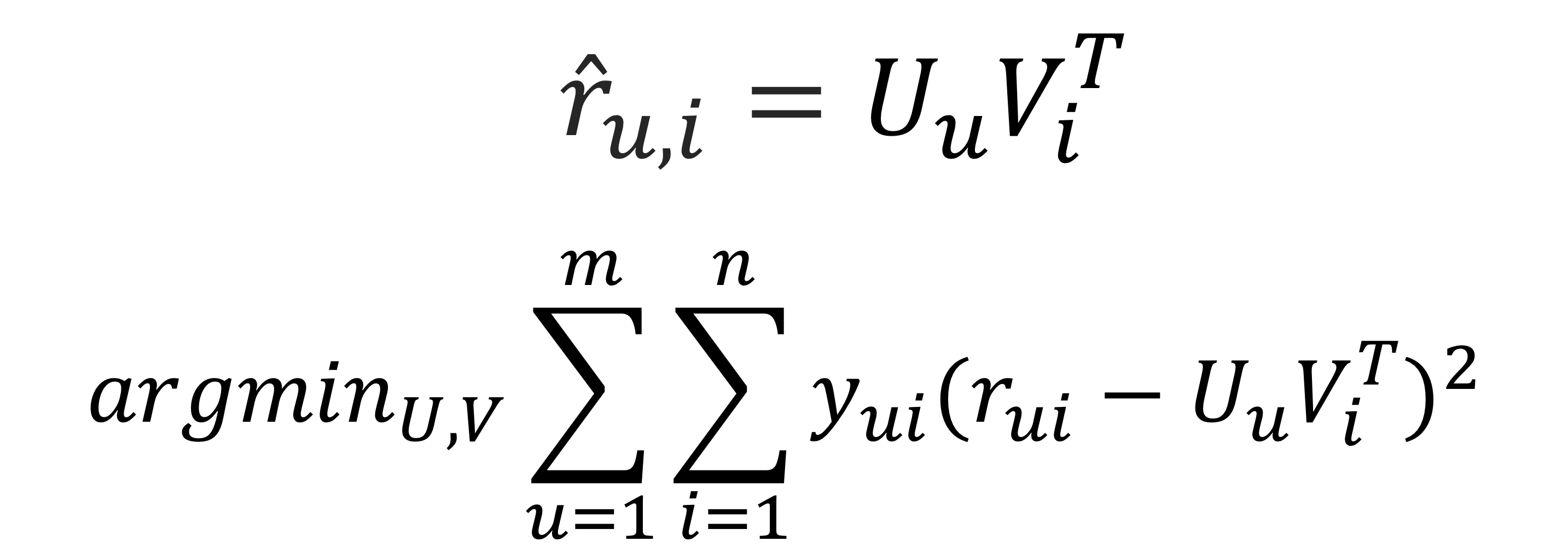
-
과적합 방지 위한 정규화 적용
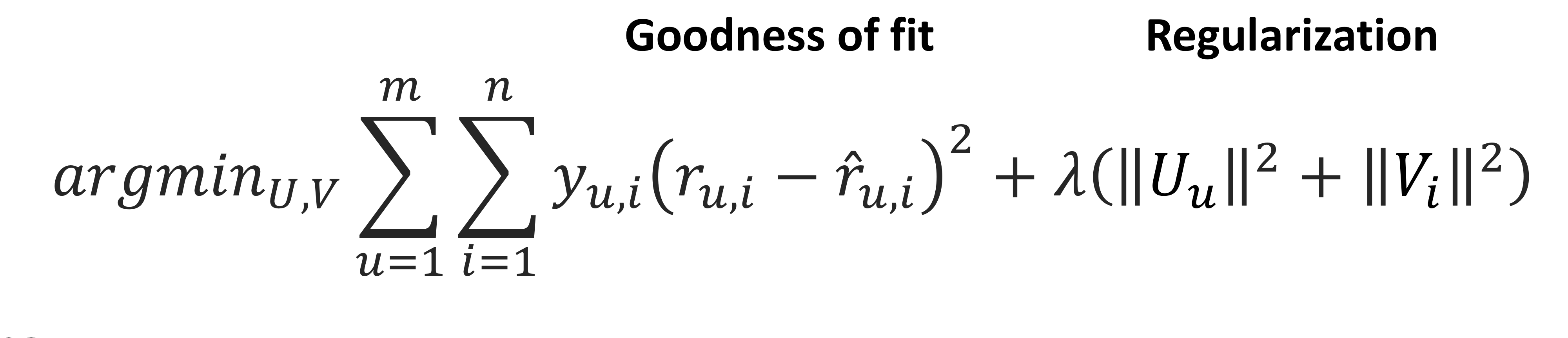
-
각 user와 item의 bias 고려
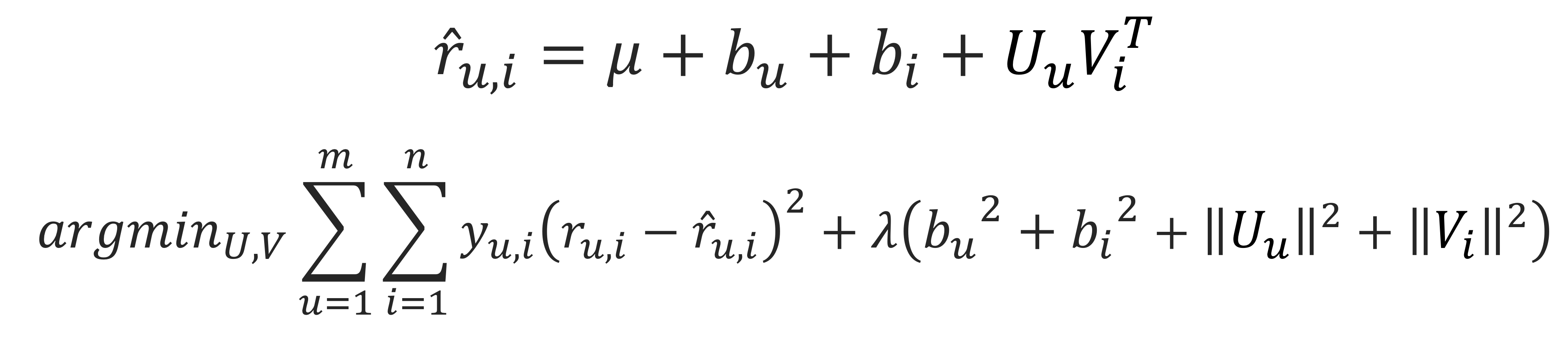
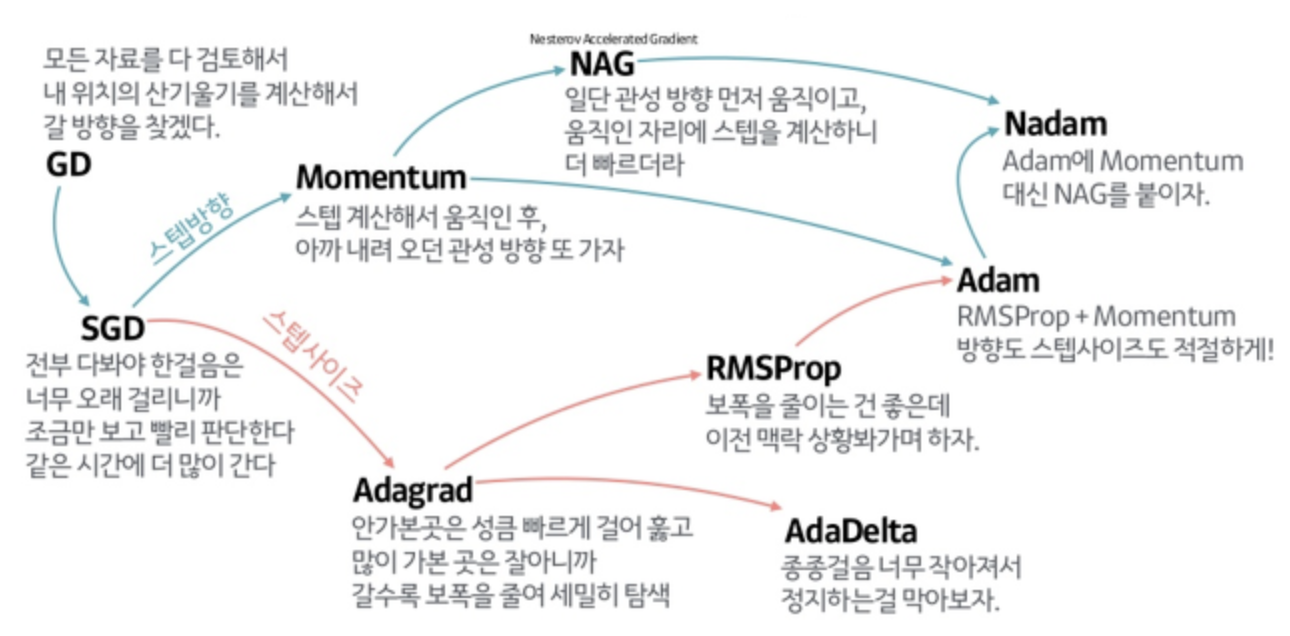
SGD 외 Optimization
- ALS (Alternating Least Squares)
: SGD의 목적함수(objective function)는 non-convex function이기 때문에 gredient descent를 사용할 때 속도가 느리고 cost가 많이 들게 됩니다.
이러한 점을 극복하기 위해 도입된 방법이 ALS입니다. 두 행렬을 동시에 최적화 하는 대신, 하나의 행렬을 고정시켜서 다른 행렬을 최적화 한 후 반대의 최적화를 진행하는 과정을 반복함으로써 최적을 찾아가는 방법입니다. 이러한 방법을 이용하면 목적함수가 convex function의 수렴된 형태를 가짐으로써 더 빠른 Optimization이 가능하게 됩니다.

K와 iterations의 최적값 찾기
- iterations로 춘분히 큰 숫자를 준 채로, K를 50~260까지 넓은 범위에서 10간격으로 RMSE를 계산해 최적값을 찾습니다.
- 찾은 최적값 K를 기준으로 더 작은 1의 간격으로 다시 RMSE값을 계산해 K의 최적값을 찾습니다.
- K를 찾은 최적값으로 고정 후 iterations의 1~300 범위에서 설정, 반복하여 iterations 최적값을 찾습니다.
- 학습률과 정규화 정도도 같은 방법으로 최적값을 찾아줍니다.
- train/test set 분리와, SGD 실행 시 적용되는 난수에 따라 계산값이 달라질 수 있으므로 코드를 여러번 반복 실행 후 평균값으로 최적값을 설정합니다.
- 각 파라미터의 최적값이 다른 파라미터 값의 변화에 영향을 받을 수 있다는 것입니다. 때문에 특정 파라미터부터 최적값을 찾아 고정 후, 차례로 다음 파라미터 최적값을 찾아나가는 방식으로 진행합니다.
참고
- 이미지
https://sungkee-book.tistory.com/12
https://seamless.tistory.com/38
투빅스16-17기 세미나 RS_basic 발표자료 - ALS
https://yeo0.github.io/data/2019/02/23/Recommendation-System_Day8/
