논문 : https://arxiv.org/abs/1409.0473
Abstract

- Neural machine translation은 단일 신경망을 구성하고 학습을 통해 번역성능을 최대화 한다.
- 발표 시점에서 많은 neural machine translation들이 Encoder-Decoder 방식을 이용했다.
- Enc-Dec 방식에서 고정길이 vector로 Encode하는 과정이 성능 개선에 대해 병목현상을 일으킨다고 예측했다.
- target 단어와 관련성있는 source 문장의 파트를 자동으로 탐색하는 방법으로 모델을 개선했다.
- 이를 통해 기존 구문기반 번역 시스템 성능에 필적하는 성능을 얻어냈다.
-(당시에는 구문기반 번역 시스템의 성능이 뛰어난 편이었다고 예측해 볼 수 있다.) - 번역 결과가 직관과도 잘 맞았다.
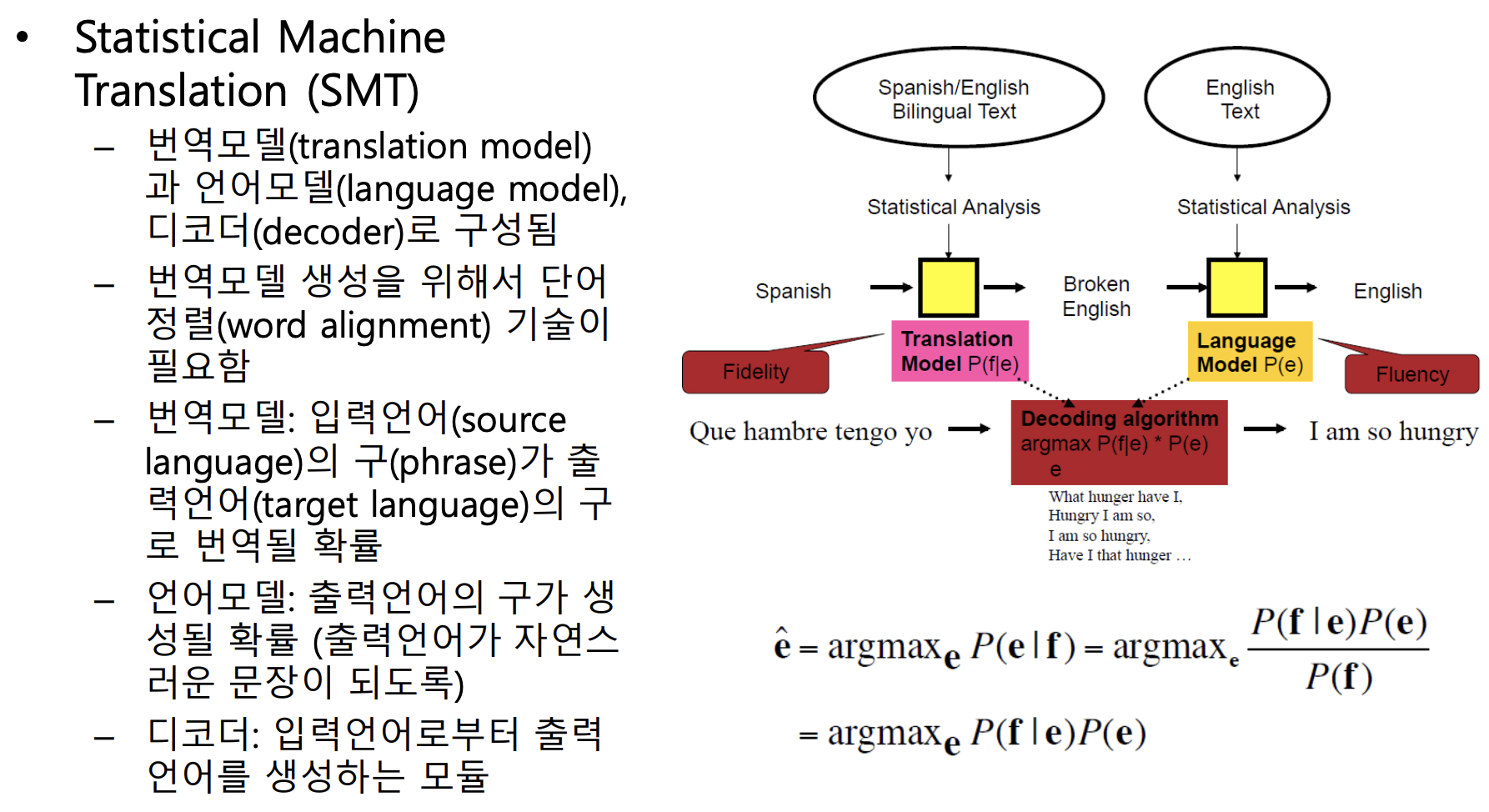
- 기존 SMT(traditional statistical machine translation)는
번역모델과 통계모델로 구성됐었다.
Introduction

- Neural machine translation은 하나의 거대한 신경망 모델 훈련을 통해 번역을 진행한다.
- 대표적인 방식인 encoder-decoders에서, 필요한 모든 정보를 고정된 길이의 벡터로 압축하기 때문에, 길이가 긴 문장에 대한 번역이 어렵다.
- 문장 길이 증가에 따라 모델의 성능 저하가 급격하게 나타난다.
learn to align and translate jointly

- 하나의 단어를 번역할 때 마다 매번
- source 문장에서 관련성 높은 부분
- 지금까지 예측한 target 단어들
- 위 두 정보를 기반으로 (by.context vector) target 단어를 예측한다.
- 하나의 고정길이 벡터로 압축하지 않고, source 문장 전체를 벡터화 한 후 디코딩 때 이 중 일부 정보를 선택하여 이용한다.
- 이를 통해, source-target 간 그럴듯한 (soft-)alignment를 이룬다.
Background - Neural Machine Translation

- 확률론 관점에서 번역
- source 문장 x에 대한 target 문장 y의 조건부확률을 최대화하도록 모델 학습
- Neural Machine Translation (반복)
- 뉴럴넷으로 바로 위의 조건부확률을 학습
- 고정된 길이 벡터로 encode하고, 가변길이로 decode하는 Enc-Dec 방식
- LSTM기반 Neural 모델로 이미 구문기반 모델과 가깝게 좋은 성능 냈다.
RNN Encoder-Decoder

- Encoder
- h : Encoder의 각 hidden state
- c : Context vector

- Decoder
- 모든 target 단어에 대한 조건부 확률 곱을 통해 y 예측 (번역)
: 직전 예측, decoder hidden state, context vector를 통해 각 조건부확률 구성
Model : Learning to Align and Translate
Decoder
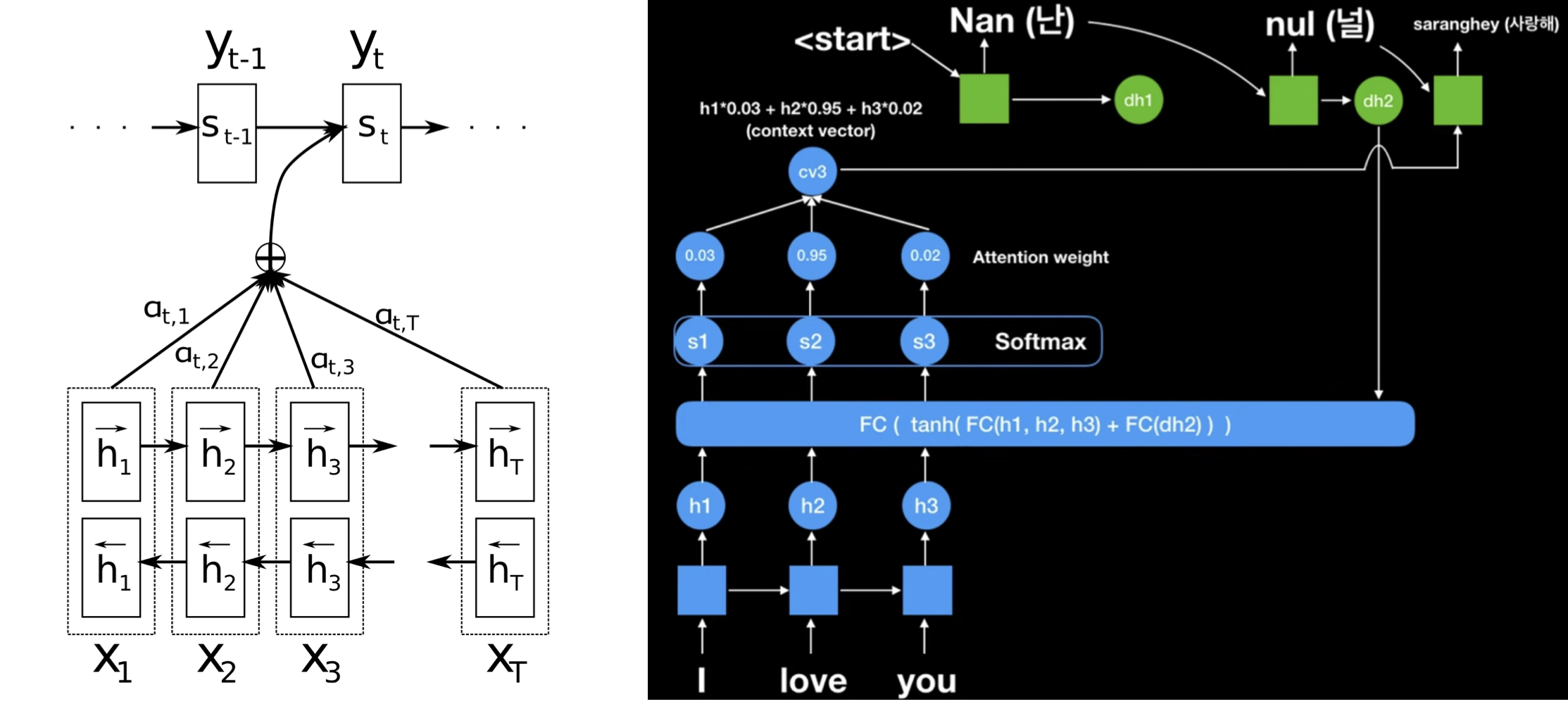
- 인코더의 모든 셀에 대한 annotation(hidden state)값이 context vector를 만드는데 활용된다.
- i시점에서 하나의 target 단어를 예측할 때 마다, 매번 알맞은 새로운 context vector가 계산된다.
- 해당 target 단어와 관련성 높은 source 문장의 부분 정보에 가중된 context vector
( annotation 전체를 활용하지만 현재 예측하려는 target과 관련성이 높은 부분만 뽑아서 쓰겠다. )
- 해당 target 단어와 관련성 높은 source 문장의 부분 정보에 가중된 context vector
- 이전 DNN모델 기반 translation
: n대n RNN을 기반으로 했기에 입력 길이와 출력길이가 다른 기계번역에 적합하지 않았다.- Seq2Seq
: source 문장의 정보를 압축한 context vector를 활용해서 디코더(두번째RNN)로 target 문장 예측
: target size 제약 해결
: source 정보를 압축한 하나의 (고정길이) 벡터를 모든 target 예측에 공통적으로 사용하기 때문에 제한된 source 정보만 반영된다는 한계
- 기본적으로 RNN에서 (i-1번째) 직전 hidden-state를 기반으로 이어질 i번째 target 예측이 이루어진다.
-> i번째 예측을 위한 source 문장의 정보를 담은 context vector은 i-1번째 (디코더의) hidden state와의 관련성(Attention Score)을 기반하여 구성된다.
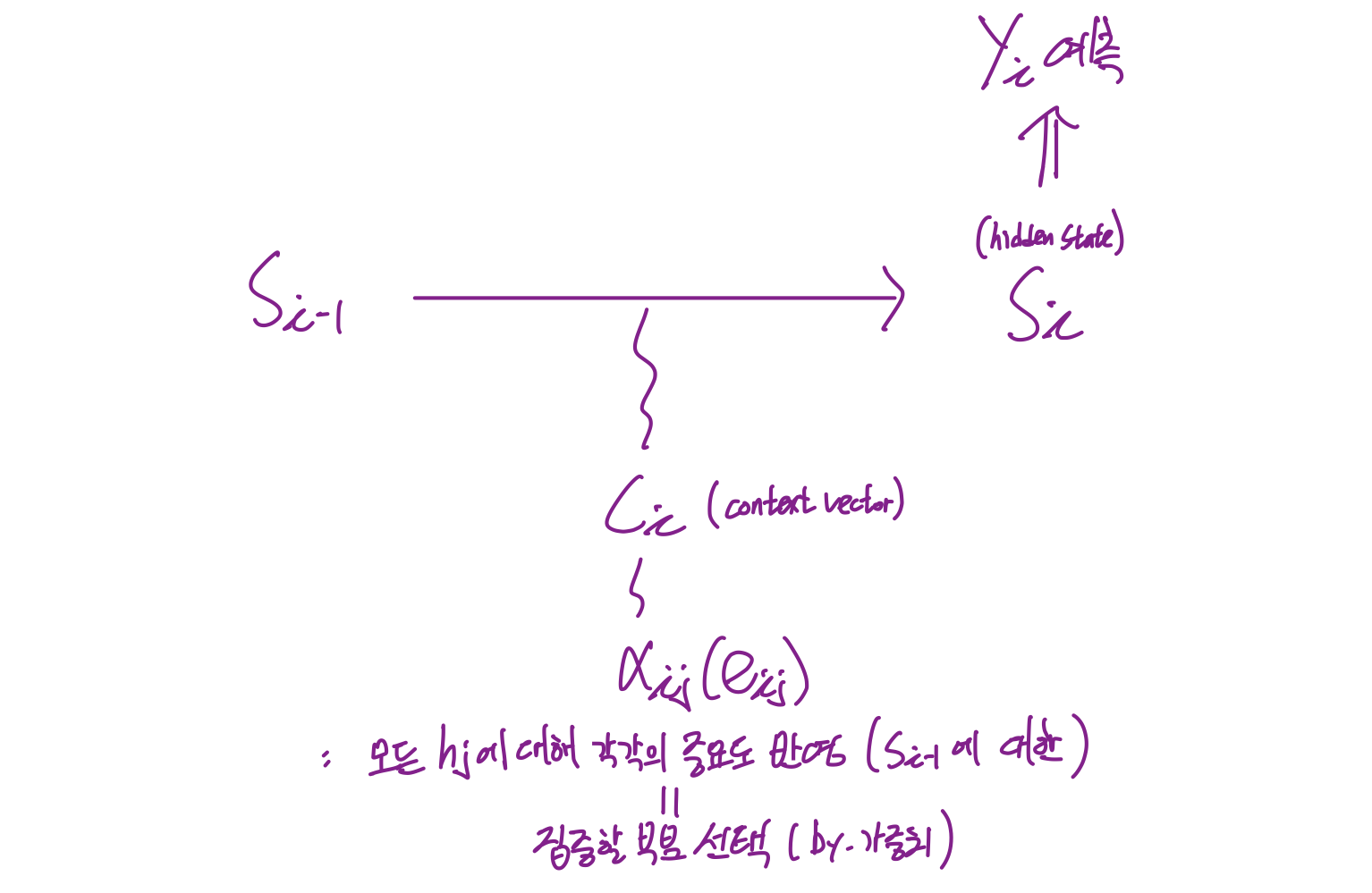
- : Decoder's Index
- : Encoder's Index
- : Decoder의 i번째 hidden state
- : annotation (Encoder의 j번째 hidden state)
- : attention value
- source단어 j가 target단어 i와 유사함을 판단하는 score
- 인코더의 j번째 hidden state가 디코더의 i-1번째 hidden state에 대응되는 alignment를 판단하는 score
- j번째 source(원본) 단어가 i번째 target(번역) 단어와 관련성이 크다는 것은, i-1번째 target단어에 이어지는 alignment를 가질 확률이 높다는 것
- : attention weight
- 하나의 target과 모든 source annotation(단어)에 대한 attention value들 -> softmax
- source 문장에서 j번째 단어가 Decoder의 i번째 단어와 관련있는 정도를 확률적으로 표현한 것
- target 단어 가 source 단어 에 의해 번역 될 확률
: 전체 source 문장에서 어떤 부분이 target 단어와 관련도가 높은 부분인지에 대한, 확률적 표현
- : context vector
- 디코더에서 i번째 셀의 context vector
- i번째 target 단어에 대한 attention weight가 반영된 모든 source 셀들의 annotation 가중합

- Enc-Dec에서 공통된 context 벡터 c를 사용한 것과 달리, target 단어 y마다 각각의 context-vector를 사용한다.


- Attention Score에 소프트맥스를 적용해 Attention Weight를 구한다.
- 인코더의 annotation(hidden state)과 i번째 target단어와의 관련성을 구하려면, i-1번째 디코더 hidden state와의 관련성을 구해야한다.
- 기존 기계번역에서는 alignment를 잠재변수로 여겼지만, 여기서는 alignment(모델 a)를 feedforward신경망의 파라미터로 설정하고 학습한다.
alignment
Encoder

- bidirectional RNN으로 구성
- annotation
: forward hidden state와 backward hidden state의 결합 벡터
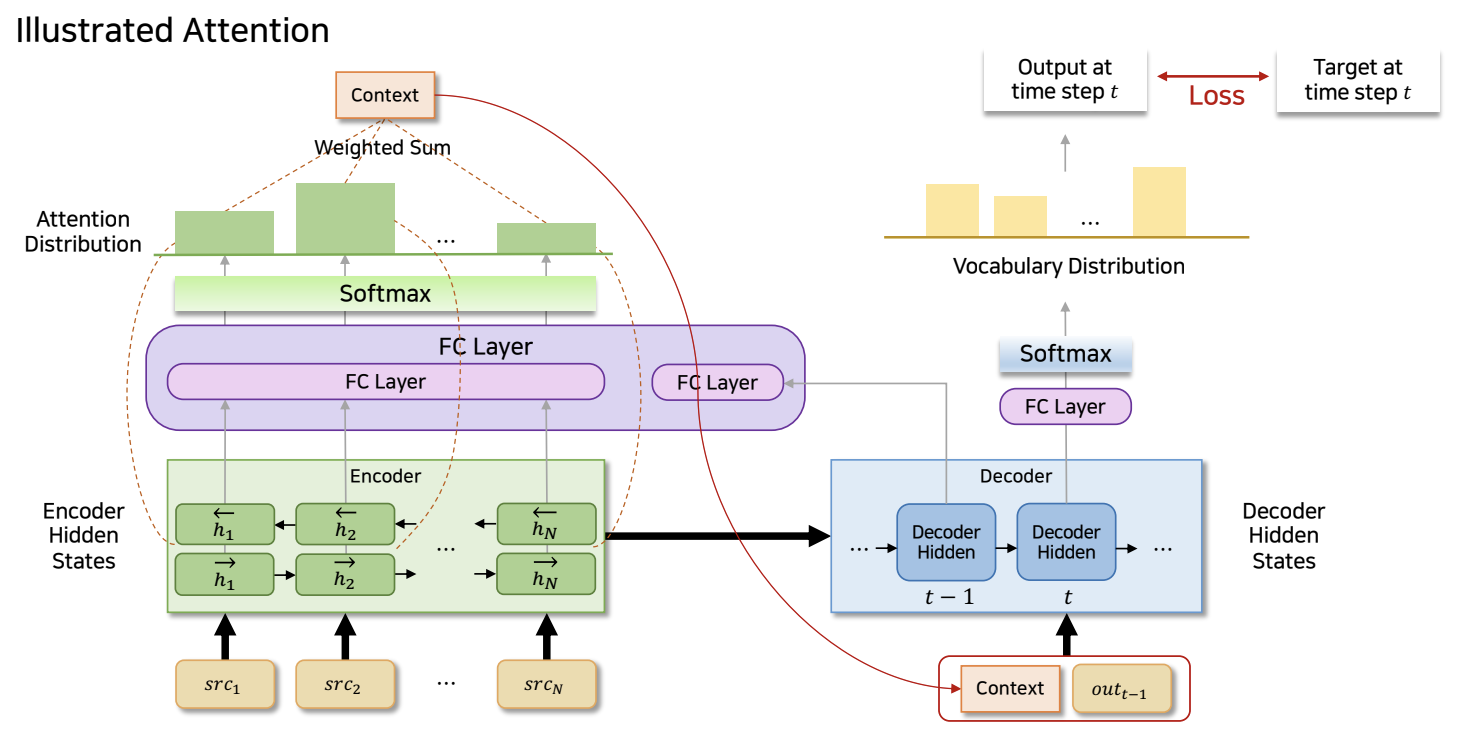
Model Architecture
GRU 기반의 neural machine
Encoder
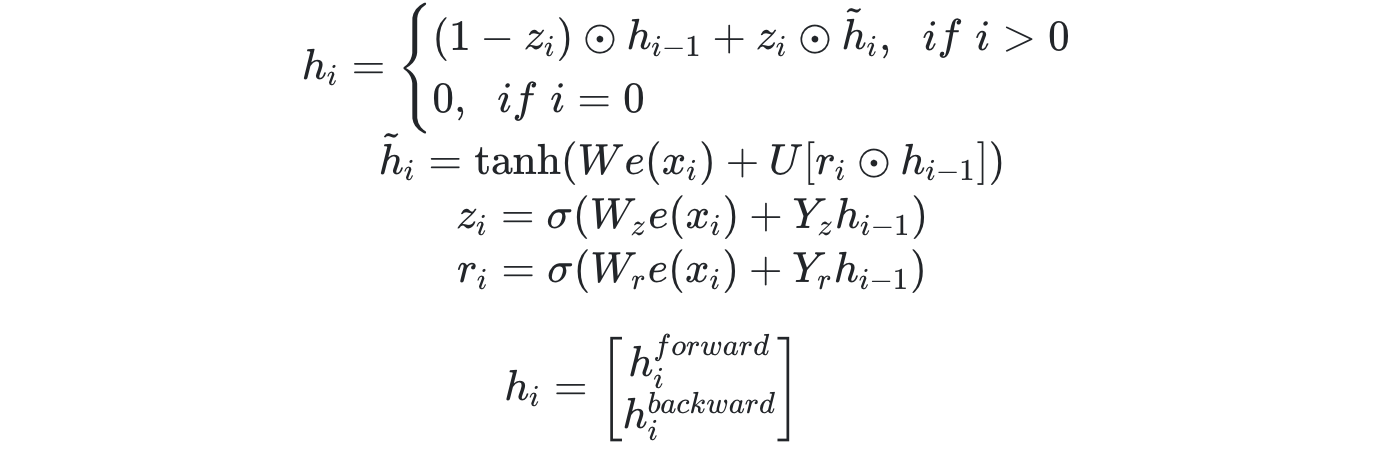
- : update gate
- : reset gate
- : cadidate hidden state
Decoder
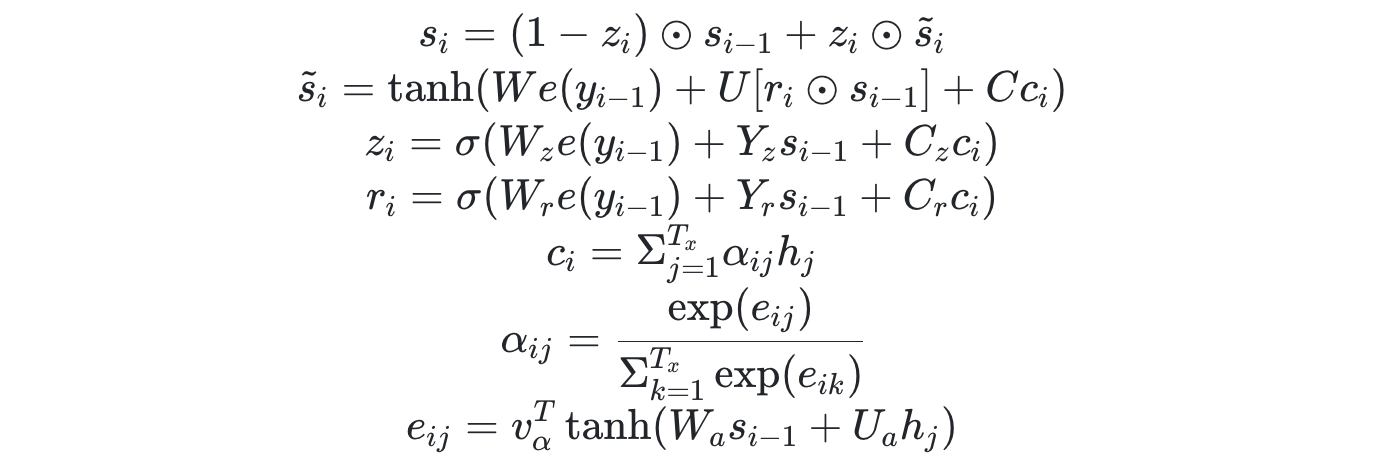
- weights


- attention value의 alignment model 수식 확인 ( )
- 항은 i에 상관없기 때문에 연산을 줄이기 위해 미리연산(pre-trained)해둔다.
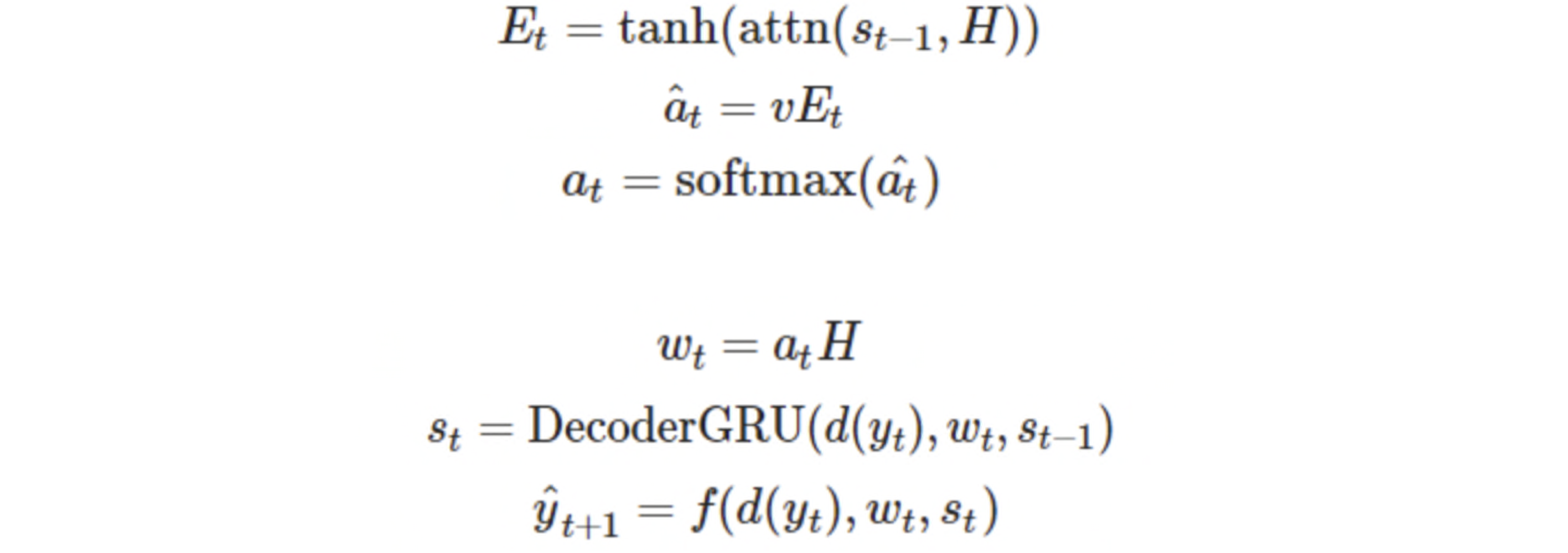
- attention value : 를 통해 source embedding dim으로 조정.
- 소프트맥스 함수를 통해 attention weight 얻는다.
- annotation과 행렬곱으로 context vector 얻는다.
- Decoder의 GRU forward를 통해 hidden state 얻는다.
- FC-layer를 통해 예측값 얻는다.
Experiment Setting
Dataset
- English-French 병렬말뭉치
- Europarl (61M words), news commentary (5.5M), UN (421M) and two crawled corpora of 90M and 272.5M words
- 총 850M 개 단어 중, data selection을 통해 348M개의 단어 말뭉치 사용
- 그 외 단일 언어 데이터 사용X
- tokenize 후, 빈도 높은 30,000개 사용.
나머지는 [UNK]토큰으로 처리. - validation set 추가
: news-test-2012 and news-test-2013 - test set
: (news-test-2014) from WMT ’14, which consists of 3003 sentences
: 학습되지 않은 data
Models
- 두개의 모델로 실험, 비교
- RNN Encoder–Decoder (RNNencdec)
- RNNsearch
- 각 모델을 두 가지 dataset으로 한 번씩, 총 두 번 훈련하여 실험
- 최대 30단어로 구성된 문장들 dataset
- 최대 50단어로 구성된 문장들 dataset
- activation function
: single maxoutmaxout
Training

- optimizer
: SGD & Adadelta - 매번 gradient norm이 임계값(=1) 이하가 되도록 정규화를 수행
- 학습 때 minibach의 문장 중 최대 길이 문장에 비례하는 시간 소요.
-> 문장들을 길이순으로 정렬 한 뒤, minibatch 생성Adadelta
: 2차 미분 활용, learning rate 자동 조정
https://twinw.tistory.com/247
Result
Quantitative Result
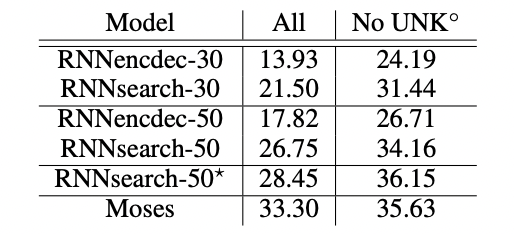
- BLEU-score
- 제한된 단어로만 구성된 문장으로만 학습하였지만, 418M개의 추가 단어 data를 사용하는 Moses에 준하는 성능을 보여준다.
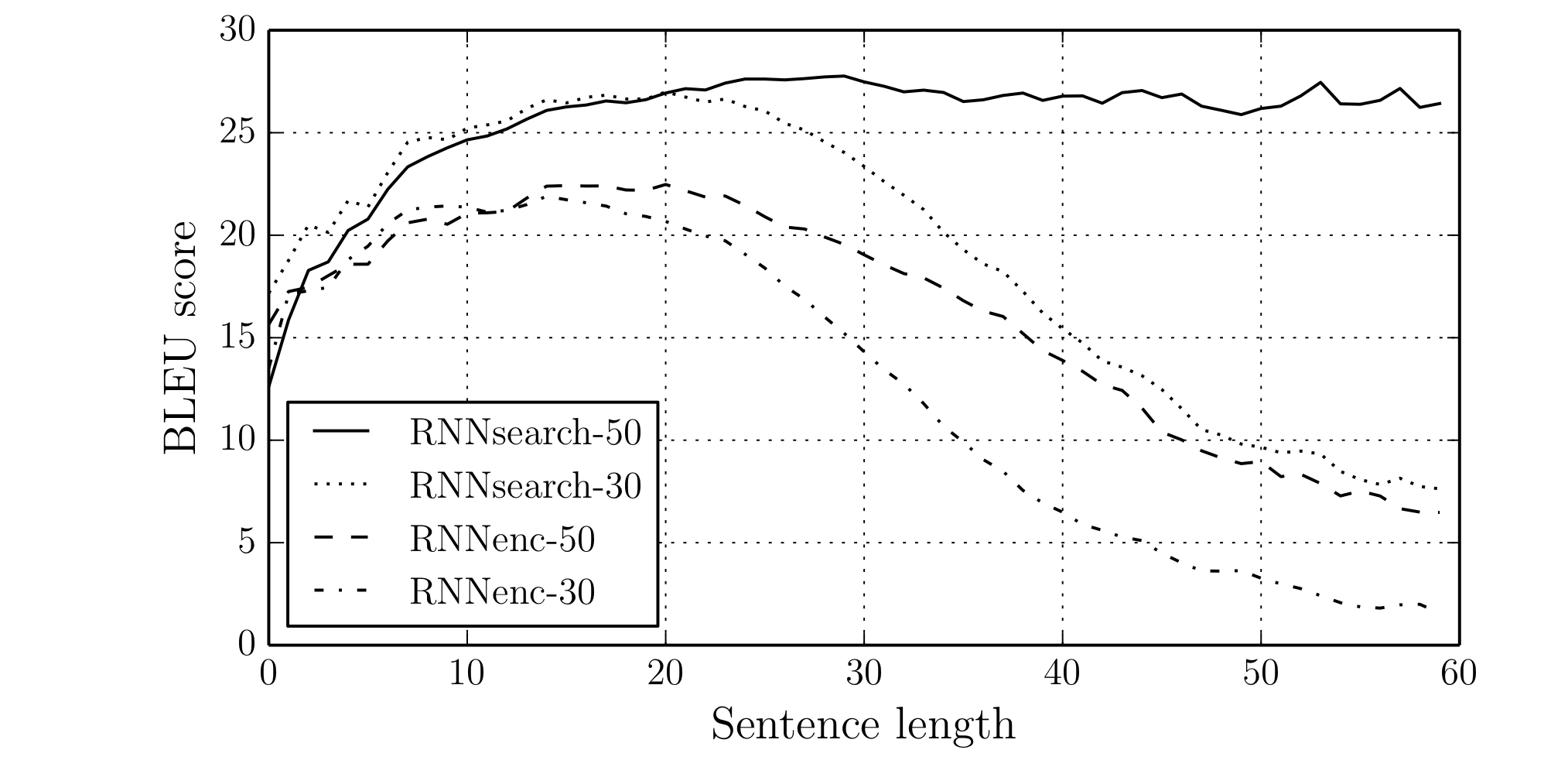
- 문장의 길이가 늘어나도 성능저하가 일어나지 않는다. (RNNsearch-50)
- RNNsearch-30이 RNNenc-50보다 BlEU-score가 좋다.
- 고정길이 context-vector를 사용하지 않기 때문에.
Qualitative Analysis
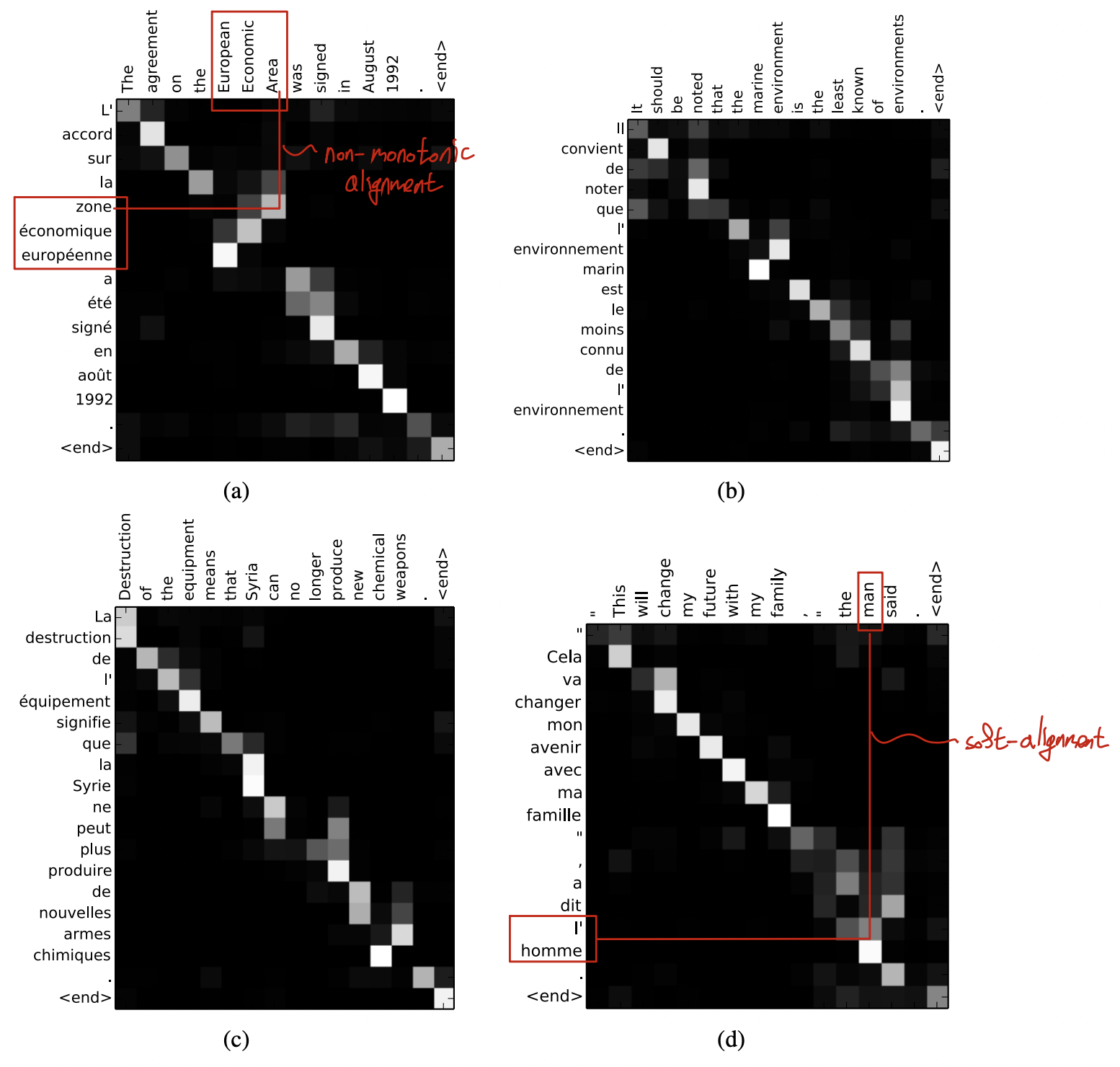
- (soft-)alignment
- 대체로 단조로운 alignment를 보이지만 (대각선대로 대응), (a)에서 그렇지 않은 경우도 발견된다.
- non-trivial, non-monotonic alignment
- 박스친 부분의 단어들에 대해, 대응되는 alignment 순서가 역순임을 확인 할 수 있다.
- source sentence와 target translation의 길이가 다른 경우를 (d)에서 확인 할 수 있다.
long-sentences
- 긴 문장을 고정 길이 벡터로 인코딩하지 않기 때문에, 긴 문장의 번역도 RNNsearch에서 더 좋은 성능을 보인다.
Conclusion

Referenced
- https://arxiv.org/abs/1409.0473
- https://drive.google.com/file/d/1UQpdZP1C_w_NfL1iHXciWtTfMqFemwTK/view
- https://www.youtube.com/watch?v=WsQLdu2JMgI&t=526s
- https://velog.io/@rnjsdb72/논문-리뷰-Neural-Machine-Translation-by-Jointly-Learning-to-Align-and-Translate#conclusion
- https://deep-learning-study.tistory.com/697
