Attention Is All You Need

Abstract

- 기존 sequence 변환 모델
: 복잡한 RNN, CNN 기반 모델 (enc, dec을 attention 매커니즘을 활용해 연결한..) - Transformer
: 오로지 attention 매커니즘에만 기반한 모델 - 병렬화 가능, 더 적은 훈련 시간
-> 우수한 성능 - 다른 task들에서도 generation 잘 됨을 보였다.
(by.구문 분석 실험)
Introduction
recurrent language model

- RNN, LSTM, GRU 모두 language model 문제에서 SOTA 모델이다.
- (이전 hidden state)와 시점 를 입력받아 다음 를 생성하는 순차적 연산.
- 순차적 연산으로 인해 병렬화 불가능.
: 길이가 긴 sequence에서 더 치명적(batching_일괄처리 불가능.) - 많은 시도들로 연산 효율성을 높였지만, 순차적 연산의 근본적 문제 해결 X
attention mechanism (seq2seq)

- 입,출력 sequence 사이 거리에 관계 없이 dependency 모델링 가능.
- 하지만 역시, RNN과 함께 사용.
tranformer

- golbal dependency 구하는데 attention mechanism만 사용
- 훨씬 많은 병렬화 가능
Backgound
순차적 연산 줄이기

- 기존 - CNN으로 모든 입출력에 대한 hidden-state vector 병렬적으로 계산
- 거리에 비례하여 연산 수 증가
- 먼 거리의 dependency 학습 어려움 (Long Term Dependency Problem)
- transformer
- multi-head attention 도입으로 연산수를 상수로 줄였다.
self-attention

- 다양한 task에서 성공적으로 사용되어 왔다.
- My )
- 하나의 sequence내에서 스스로에게 attention mechanism 적용
- 각 position들 서로에게 가중치 부여
- 한 sequence에 대한 representation 효과적 학습 가능
end-to-end memory network

- QA, Language Model에서 성능 좋게 나타났다.
- My )
- 모든 parameter(weight)들이 하나의 loss에 대해 한 번에 학습(update)되는 모델 구조
- 입력에서 출력까지 하나의 network로 한 번에 처리
transformer
- 새롭게 제시한 Transformer
: 입출력 표현을 위해 전적으로 self-attention에 의존하는 최초의 변환 모델 (transduction model)
Model Architecture
Encoder & Decoder Stacks
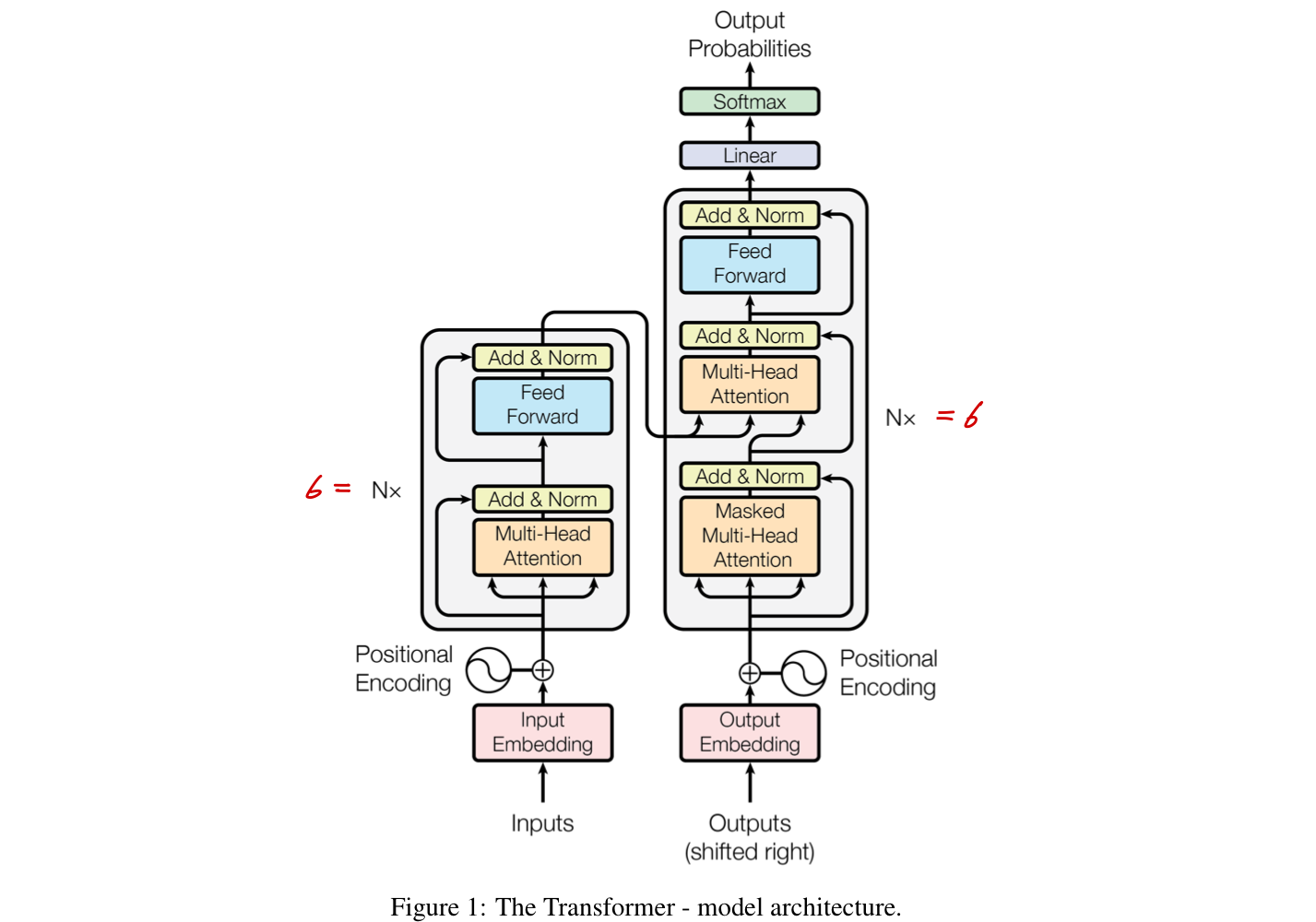
- 각 인코더와 디코더는 [self-attention], [point-wise], [fully-connected] Layer들이 쌓인 구조를 따른다.

Encoder
- 6개의 동일한 Layer stack으로 구성된다.
- 각 Layer는 2개의 sub-layer를 갖고있다.
- multi-head self-attention mechanism
- position-wise fully-connected feed-forward network
- 각 sub-layer마다 residual connection을 적용하고, normalization을 수행합니다.
- 모든 sub-layer와 embedding layer의 output dim을 인 512로 통일
-> residual connection 용이
Decoder
- Encoder와 같게, 동일한 6개의 Layer로 구성.
- 3개의 sub-layer
- "masked" multi-head self-attention mechanism
- (encoder 출력에 대한) multi-head attention
- position-wise fully-connected feed-forward network
- 역시 sub-layer마다 residual connection을 적용하고, normalization을 수행합니다.
- masking : (앞 position) 이전 정보만 attention에 활용되도록 하기 위함. 알려진 출력에만 의존.
Attention
- output에 (Query)와 (Key-Value pair들의 집합)을 mapping.
Scale Dot-Product Attention
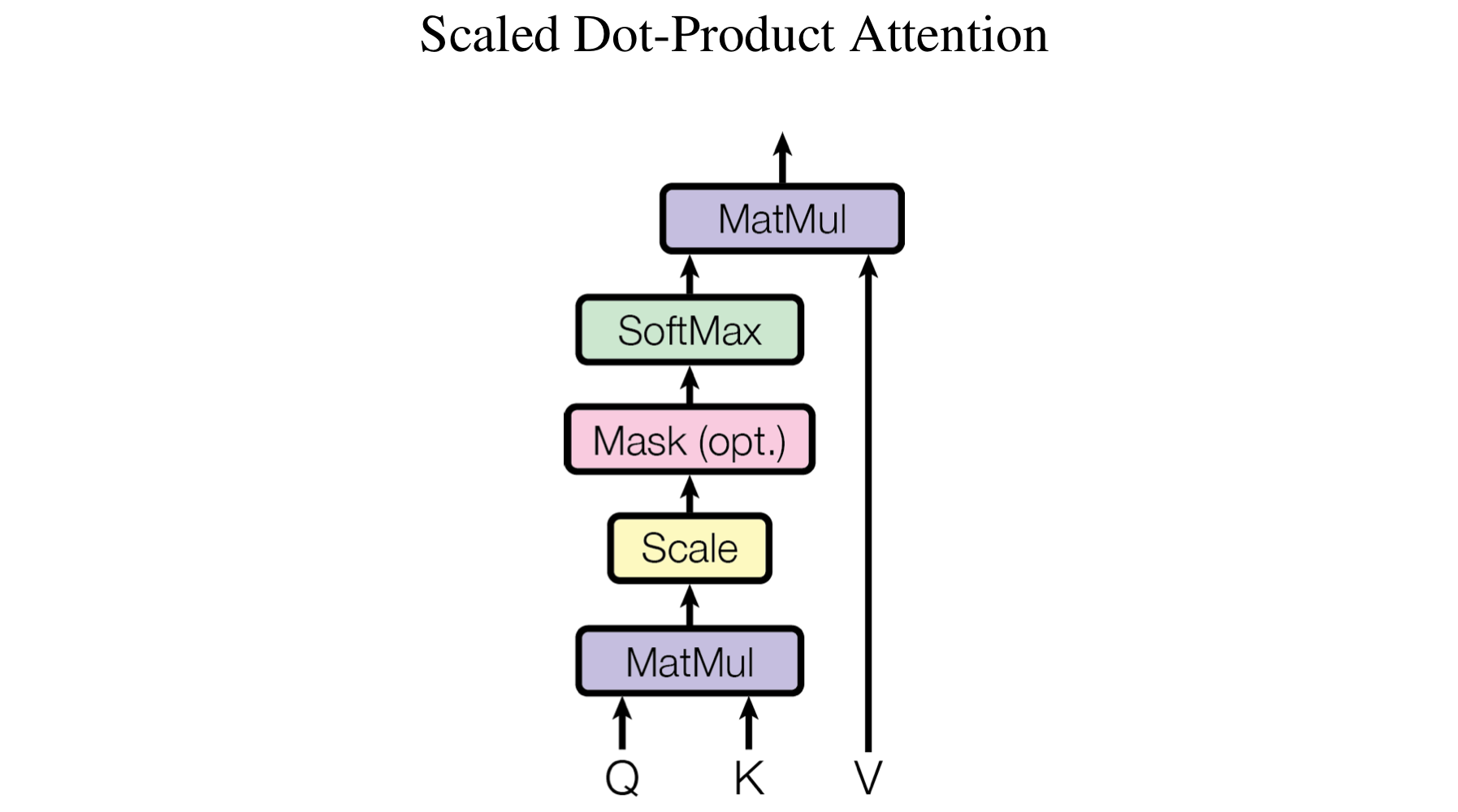

- Q, K, V : Query, Key, Value를 묶어놓은 행렬
- Q, K의 dim =
V의 dim =- My ) single-attention 에서 = =
- 두 가지 많이 사용되는 attention function
- additive attention
- dot-product attention
- 두 function은 계산 복잡도 측면에서 비슷하지만
- 최적화된 matrix multipicatoin 명령어 code를 사용 할 수 있기 때문에 dot-product attention이 더 빠르고 공간효율적이다.
- 가 커지면 내적 값(QK)도 커지게 되는 경향성 존재.
-> Gradient Vanishing & Exploding
-> 학습 잘 안 된다. - 이 효과 상쇄 위하여, 의 scaling factor를 적용해준다.
Multi-Head Attention
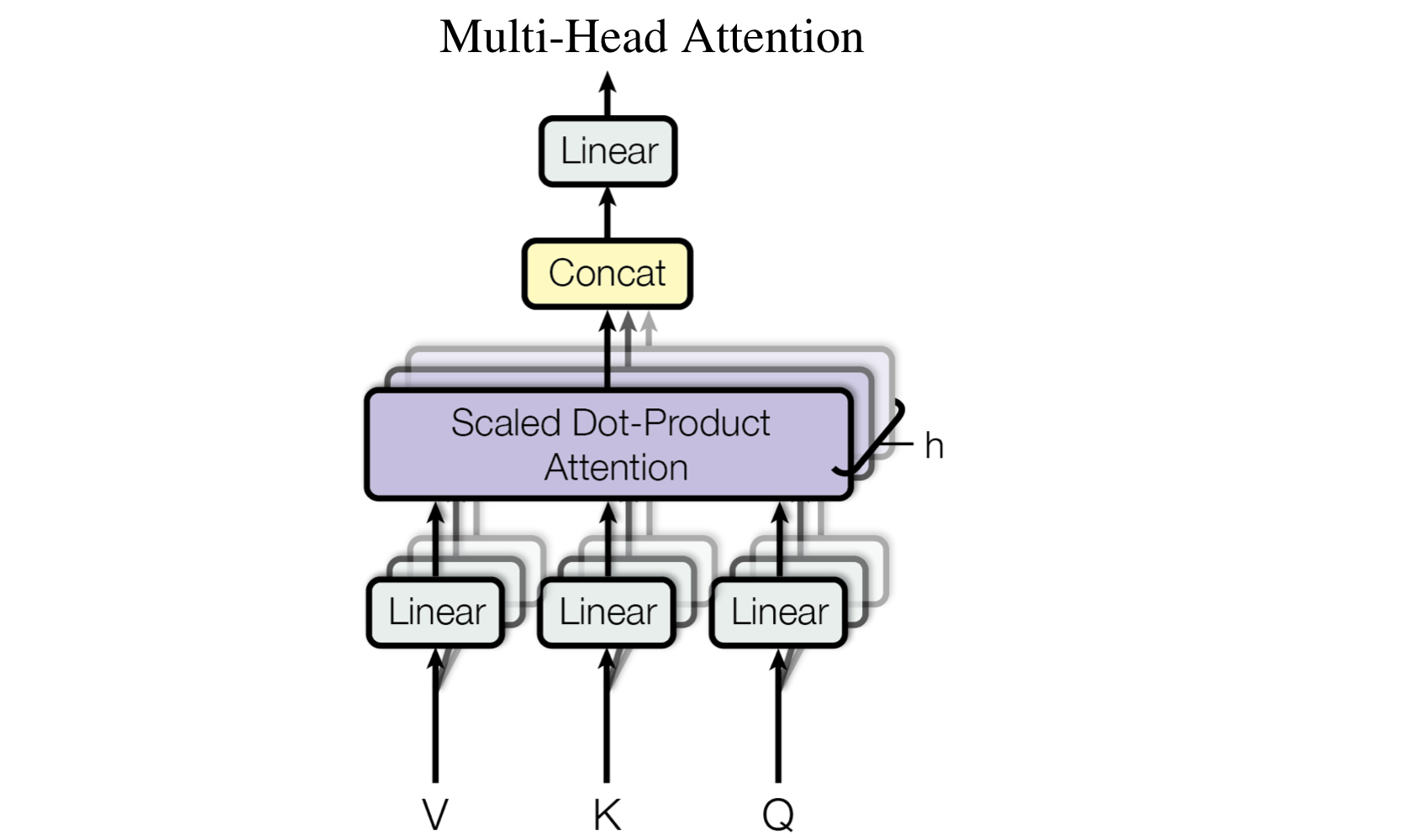

- h개의 head에서 각각 학습된 다른 linear layer에 따로 Q,K,V를 통과시킨다.
(어떤 head에서 Q,K,V의 linear layer weight도 각각 따로 - )
- h개로 쪼개진다.
- vector를 head개수 만큼 토막내서 사용
- 전체 연산 수 비슷하다 (head 배 증가X )
- 기존 이었던 K,Q,V가 , 로
- = =
- head 마다 attention function 병렬적 수행
- 모든 head의 ouput - concat
-> - linear layer 통과

- Multi-Head Attention 효과
- Multi-Head Attention을 통해 다른 representation 공간벡터에 위치한 다른 position의 정보에 attention을 줄 수 있다.
- single attention에서는 평균으로 가져와서 불가능.
Multi-Head Attention의 활용

- Enc-Dec attention layer
- Q : from 이전 Dec
K, V : from Enc output - 디코더의 어떤 position에서도 input sequence의 전체에 대해 attention 줄 수 있다.
- seq2seq의 Enc-Dec 메커니즘 차용
- Q : from 이전 Dec
- self-attention layer(Enc)
- Q,K,V 모두 이전 layer의 output
- 이전 layer의 모든 position에 attention 줄 수 있다.
- masked self-attention layer (Dec)
- Enc와 마찬가지 이지만
- auto-regressive 유지를 위해 정보가 왼쪽으로 향하는 것을 막아야 한다.
(뒤의 정보 확인 못 하도록) - auto-regressive : Decoder에서 출력을 다시 입력에 넣어 다음 예측을 이어가는 flow
- 해당하는 값들 masking해서 softmax에 넣는다.
Position-wise Feed-Forward Networks

- 각 position에 동일하게 FFN() 적용
- layer마다 다른 각각의 weight(parameter) 학습
- input, output dim = = 512
내부 layer dim = 2048 ( x 4)
Embeddings and Softmax

- 학습된 embedding 사용
- (tokenize된) input token을 dim = 로 변환
- 두 embedding layer와 pre-softmax linear transformatoin이 같은 weight matrix를 공유
- 단어를 벡터로 만드는 embedding layer
- 벡터를 다시 단어들에 대한 확률을 통해 하나의 단어 예측을 뽑아내는 soft 전 linear transformatoin
: model_dim 벡터를 vocab size 차원으로 늘린다. - 유사한 역할에, (max_len, vocab size)로 형태도 유사하기에 같은 weight를 사용한다.
- 매우 큰 weight이기 때문에 같은 것 사용하면서 cost 이득 크다.
- embedding layer에서 곱 -???
Positional Encoding

-
recurrence, convolution를 포함하고 있지 않기 때문에, sequence에 대한 위치 정보를 알려줘야 sequence 순서 활용 가능하다.
-
인코더, 디코더 최하단 layer에 input-embedding 벡터에 "positional encoding"정보를 더한다.
-
dim = 이어서 더할 수 있다.

-
positional encoding은 각 dim마다 파장이 다른 사인파 함수로 표현.
-
linear function으로 표현 할 수 있기에 학습이 용이하다.
-
학습된 positional embedding으로도 실험 진행.
: 결과는 비슷했다. -
사인파 함수가 훈련한 것 보다 긴 sequence에 대한 추정도 가능했기에 채택
Why Self-Attention



: self-attention을 사용하는 요인
-
long-range dependency 학습
- 신경망에서 순전파, 역전파 진행 경로 길이
- self-attention layer에서 모든 position 간 거리를 O(1)의 순차적 수행으로 연결합니다.
- Recurrent에서는 O(n)의 sequential operatoin 필요.
-
layer당 전체 연산 복잡도
- sequence represent가 n < d인 경우 self-attention의 복잡도가 가장 작다.
- 대부분의 SOTA word embedding model에서 n < d 이다.
- Convolution
: 모든 입,출력 position 쌍 연결 위해- single conv : O(n/k) layers 필요
확장된 conv : O(logk(n)) 필요
-> 경로 길이 증가 (recurrent보다 안좋다) - seperable conv : 로 줄어들지만
최적인 k=n일 때, 우리가 사용하는 self-attention과 같아진다.
- single conv : O(n/k) layers 필요
-
병렬 연산 할 수 있는 양
-
해석 가능 한 모델
by. attention distribution -
각 head의 attention
- 다른 task에 대한 성능 학습 가능
- 문장 구조, 의미 구조에 관한 표현 가능
Training
Training Data & Batching

- Eng-Ger
- sentence pairs - 4.5 M
- byte-pair encoding - 37000 vocab
- Eng-Fre
- 36 M
- 32000 vocab
- 하나의 batch에 두 문장 pair로 들어있다.
optimizer

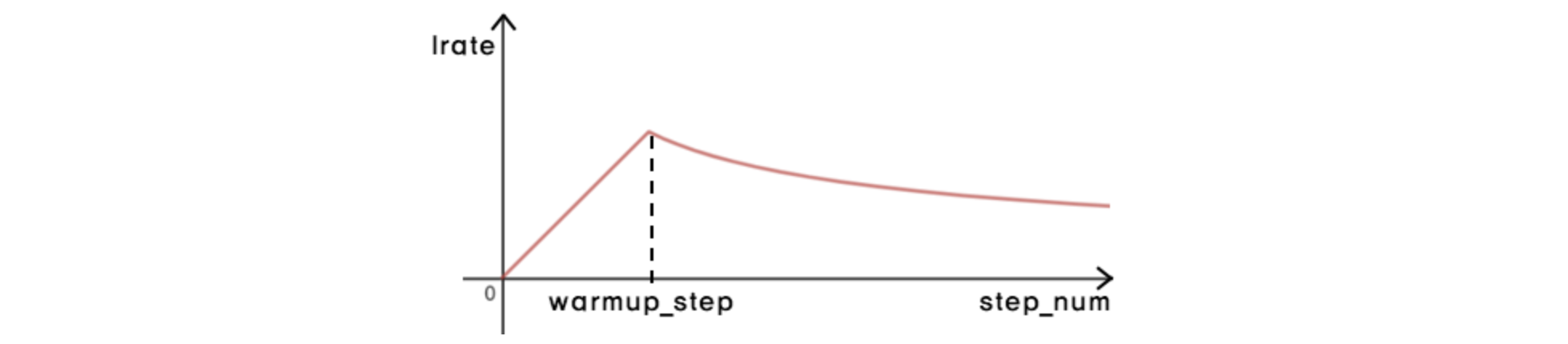
- Adam - 가변 learning rate
- LR : warm-up step에서 선형적으로 증가, 이후에 step 수의 역제곱근에 비례하게 감소
Regularization

- Residual Dropout
- 각 sub-layer output에 적용 -> 다음 sub-layer에 넣고 normalize
- 모든 embedding layer - position encoding layer 합에 적용
- Label Smoothing
적용한 최적화 방법 설명 : https://pozalabs.github.io/transformer/
Result
machine translation

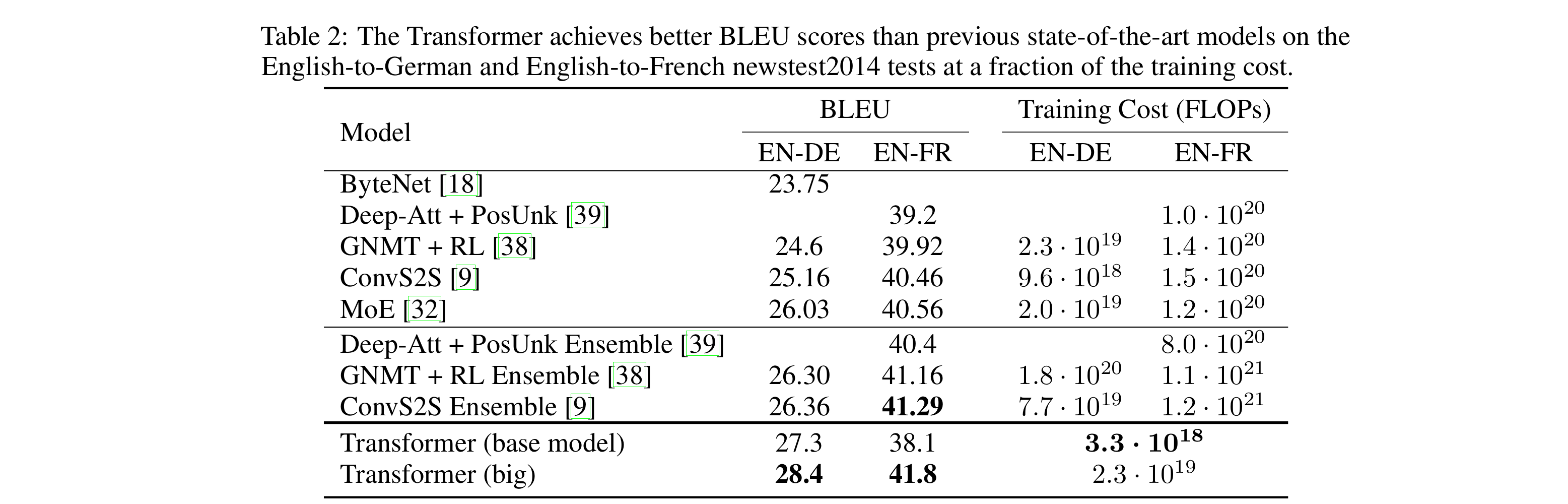
- base model : 10분간격 마지막 checkpoint 5개의 평균 모델 사용
big model : 20개의 평균 모델 사용 - beam search 사용
: beam = - 4, length penalty α = 0.6 - big model
: 기존 SOTA에 비해 4분의1마큼 작은 학습 cost에도, 더 우수한 성능 냈다.
Model Variations
- 구성요소 중요성 평가 (전체 계산량 유지)
- head 개수
- ,
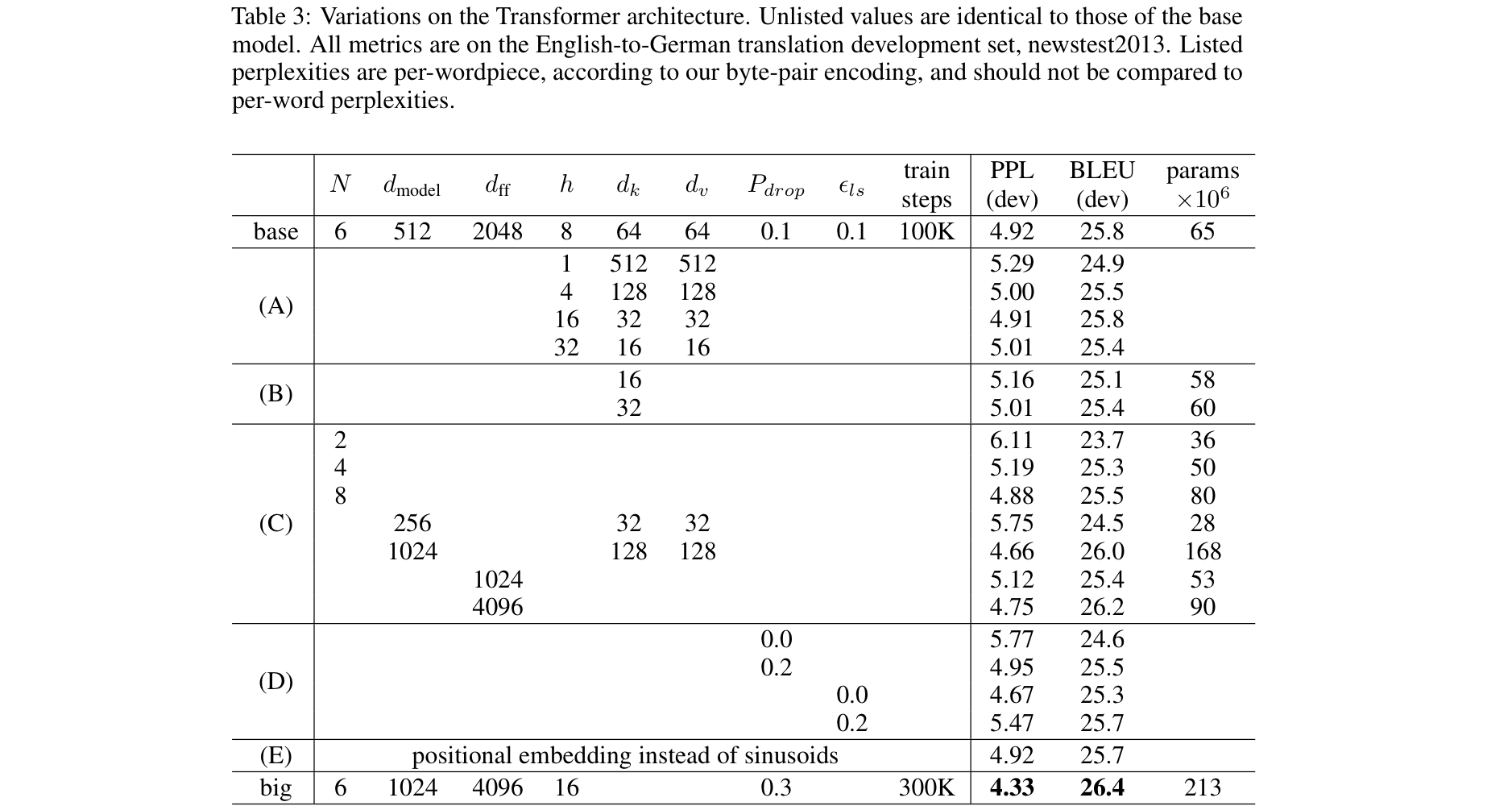
- (A)
: head는 적당한(16) 개수 필요
: single일 때 최대일 때 모두 최고 성능 아님 - (B)
: 작아지니 성능 안좋아짐 - (C, D)
: bigger 모델이 성능 좋고
: dropout은 과적합 방지 효과 있음 - (E)
: 사인파 대신 학습 positional encoding 사용해도 성능 비슷
English Constitiuency Parsing

- 구문 분석 실험 : 동사구, 명사구 등 구 단위로 묶어 나가는 것
- output이 구조적 제약 있음
- output이 input보다 길다.
- RNN 모델에서는 작은 데이터로 좋은 성능 달성 불가.
- Task-specific tuning 없이 좋은 성능 발휘하는지 확인하기 위한 실험
Conclusion

