python - re 라이브러리
- re.func(Pattern, "string", Flag)
Pattern.func("string", Flag)
: 같은 동작 다른 표현 - 성사된 매치에 대해 re.match 객체를 리턴
pattern 지정
re.compile()
- 컴파일 된 Pattern 객체 리턴
import re
p = re.compile(r"정규표현식")문자열 matching
re.match()
- 문자열의 처음 시작이 match (선두)
p = re.compile('python')
m = p.match("python")
print(m)
# <re.Match object; span=(0, 6), match='python'>
m = re.match(p, "python")
print(m)
# <re.Match object; span=(0, 6), match='python'>
m = p.match("python3.0ver")
print(m)
# <re.Match object; span=(0, 6), match='python'>
m = p.match("version--python3.0")
print(m)
# Nonere.search()
- 위치에 상관없이 가장 먼저 매치되는 객체 리턴
re.findall()
- 매치되는 모든 문자열을 찾아 문자열 list 리턴
p = re.compile('py')
m = p.findall("pypy, python3.0, python3.8")
print(m)
print(type(m))
# ['py', 'py', 'py', 'py']
# <class 'list'>re.finditer()
- match객체를 element로 갖는 iterator 객체 반환
- 한 번 루프 돌면서 접근하면 없어짐
p = re.compile('python')
m = p.finditer("pypy, python3.0, python3.8")
print([s for s in m])
print(type(m))
# [<re.Match object; span=(6, 12), match='python'>, <re.Match object; span=(17, 23), match='python'>]
# <class 'callable_iterator'>re.fullmatch()
- 문자열 전부가 매치되는가를 체크
re.split()
- 정규표현 패턴을 기준으로 문자열을 분할
- 기본 파이썬의 split함수를 사용하면 분리 기준 str이 삭제됩니다. 하지만 re.split에서는 괄호를 사용하면 보존 된다.
print(re.split('(,)', "1,2,3,4,5"))
print(re.split(',', "1,2,3,4,5"))
# ['1', ',', '2', ',', '3', ',', '4', ',', '5']
# ['1', '2', '3', '4', '5']- 즉, 그룹화 된 정규표현식에 대해 split마다 매치 정보를 출력한다.
print(re.split('(&)|(and)', "1&2and3and4&5"))
print(re.split('&|and', "1&2and3and4&5"))
# ['1', '&', None, '2', None, 'and', '3', None, 'and', '4', '&', None, '5']
# ['1', '2', '3', '4', '5']- '&'를 만나 split된 경우 - 매치된 '&'와 매치되지 않은 'and'에 대한
[ '&', None ]이 split()의 결과로 출력되어 있는 것을 확인 할 수 있다.
re.sub(s1, s2), re.subn()
- s2에서 패턴에 해당하는 문자열을 s1으로 바꾼다.
- 세 번째 파라미터에 정수를 넘겨주면 앞에서부터 해당 횟수 만큼만 바꾸는 작업을 수행한다.
p = re.compile('(blue|white|red)')
p.sub('colour', 'blue socks and red shoes')
# 'colour socks and colour shoes'- 첫 번째파라미터에 함수를 넣어서 매치된 문자열에 대한 동작을 수행 할 수도 있다.
def hexrepl(match):
value = int(match.group())
return hex(value)
p = re.compile(r'\d+')
p.sub(hexrepl, 'Call 65490 for printing, 49152 for user code.')
# 'Call 0xffd2 for printing, 0xc000 for user code.'- subn()은 ("바뀐 문자열", 매치(작업 수행) 횟수) 튜플형태로 리턴한다.
p = re.compile('(blue|white|red)')
p.subn( 'colour', 'blue socks and red shoes')
# ('colour socks and colour shoes', 2)re.match object
- match 객체를 통해 매치된 문자열에 대한 다양한 정보 얻을 수 있다.
start(), end(), span()
- 매치된 문자열의 시작 index
- 매치된 문자열의 끝 index + 1
- (시작, 끝+1)
리턴
m = p.search("3 python")
m.group()
# 'python'
m.start()
# 2
m.end()
# 8
m.span()
# (2, 8)group(), groups()
- group()
- 매치된 문자열 리턴
- 인자를 넣으면 해당하는 그룹에 의해 매치된 문자열만 리턴
- groups()
- 모든 그룹에 의해 매치된 문자열을 리턴
m = re.match('(\d{2})-(\d{3,4})-(\d{4})', '02-123-1234')
print(m.groups())
print(m.group())
print(m.group(0))
print(m.group(1))
print(m.group(2))
# ('02', '123', '1234')
# 02-123-1234
# 02-123-1234
# 02
# 123
result2 = re.match('\d{2}-\d{3,4}-\d{4}', '02-123-1234')
print(result2.groups())
print(result2.group())
# ()
# 02-123-1234정규표현식
- 정규표현식을 통해 내가 어떤 문자열들을 찾을 것인지, 처리 할 문자들의 "패턴"(조건)을 설정 할 수 있다.
- 기본적으로 pattern으로 전달해준 문자열을 찾는다.
- 여러가지 메타 문자를 활용해 pattern에 추가적인 조건을 설정 할 수 있다.
s = "abc123abc45"
p = re.compile('bc')
result = p.findall(s)
print(result)
# ['bc', 'bc']r-string(raw string)의 역할과 사용배경
escape-code
- 문자열 표준 출력 과정에서 특별한 역할을 수행하기 위한 코드. 문자열을 잠시 탈출해서 다른 할일을 하고 다시 문자열로 돌아온다.
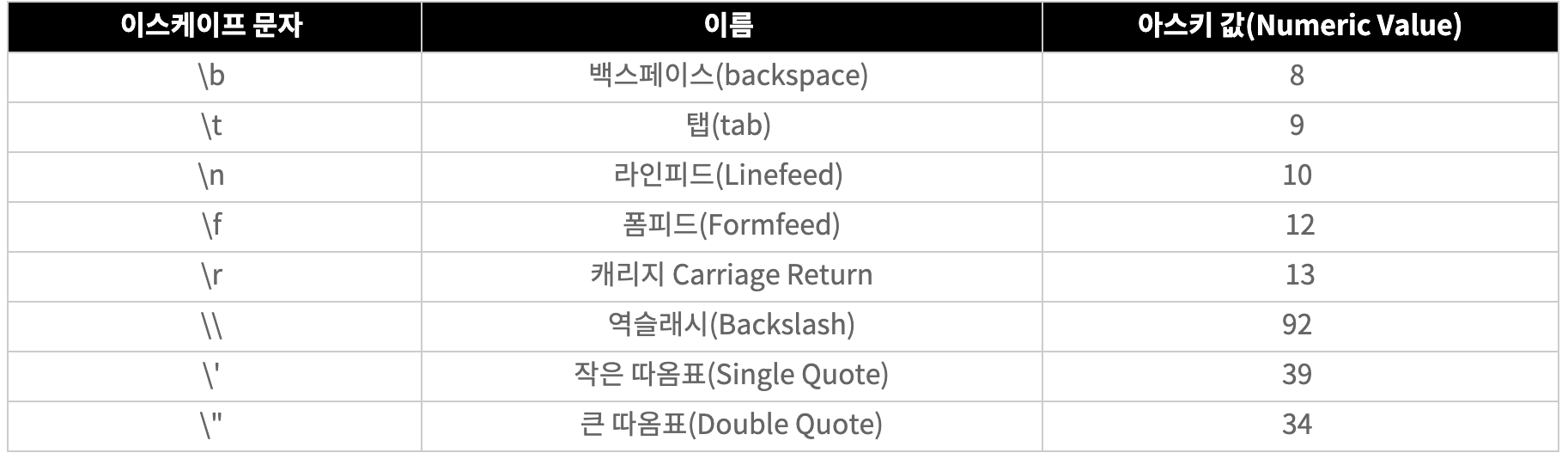
- \ ' " 는 문자열로 인식되지 않는 문자를 문자열로 인식되게끔 하는 역할 수행
print("개행 \n 됐다")
print("\\")
print("따옴표 \' 또는 \" 를 사용하는예")
# 개행
# 됐다
# \
# 따옴표 ' 또는 " 를 사용하는예r-string
- raw string 표기법은 역슬래시('\')가 가지는 파이썬 기본 문자열 표현법에서 적용되는 (이스케이프 코드) 특별한 역할을 없앤다.
- 단, 따옴표는 문자열을 감싸는 '', ""와 구분되어야 하기 때문에 r-string에서도 단독으로 따옴표 문자열을 표현 할 수 없다. 단독 사용을 위해서는 ''' ''' 를 이용해야 한다.
- \'과 \"에서의 역슬래시는 r-string에서도 이스케이프 코드의 역할을 동시에 수행한다. 역슬래시는 (따옴표가 문자열로 남아있도록 구분하는)이스케이프 코드 역할을 수행한 후 문자열 자체로 남아있는다.
- 그렇기에 문자열 마지막에 역슬래시가 홀수개로 들어가면 오류 발생.
: 문자열을 종료하는 역할의 따옴표를 문자열로 가져와 버린다.
(짝수개가 오면 오류 안 난다.)
print("\\\\"== r"\\")
# True
print('"', "'")
print(''' 따옴표 '와 쌍따옴표" ''')
# " '
# 따옴표 '와 쌍따옴표"
print("\"")
print(r"\"")
# "
# \"
print(len("\""))
print(len(r"\""))
# 1
# 2
print(r"abc\")
# Error
print(r"abc\\")
# abc\\- 정규표현식에서 찾으려는 패턴에 대한 문자열 표현을 문자열로 표현해야 한다.
- 예를들어, 백슬래시 하나를 패턴으로 설정하기 위해 '\\'로 표현해야 한다.
- 백슬래시 하나에 대한 문자열 표현 (패턴) : "\"
- 위의 패턴을 문자열로 표현 : "\\"
import re
s = "\\good\\"
# \good\
p = re.compile('\\\\')
result = p.findall(s)
print(result)
# ['\\', '\\']- 정규표현식에서 pattern으로 설정할 문자열을 다시 한 번 문자열로 표현해야 하기 때문에 백슬래시('\')가 포함된 이스케이프 코드에 대한 표현이 너무 복잡해질 수 있다.
- 숫자를 탐지하는 "\d"를 pattern으로 설정하기 위해서 정규표현식으로 해당 패턴을 표현하면 "\d"가 된다. r-string을 활용하면 r"\d"로 표현 할 수 있다.
s = "abc123de45"
p = re.compile('\\d+')
p = re.compile(r'\d+') # 같은 표현
result = p.findall(s)
print(result)
# ['123', '45']- 그러므로 보통 정규표현식에서 r-string(raw string)을 사용한다.
메타 문자(meta characters)
- 메타 문자란 원래 그 문자가 가진 뜻이 아닌 특별한 용도로 사용하는 문자를 말한다.
- 정규표현식의 모든 메타 문자 :

Groups and ranges
- 정규 표현식의 분류 범위와 방식을 선택
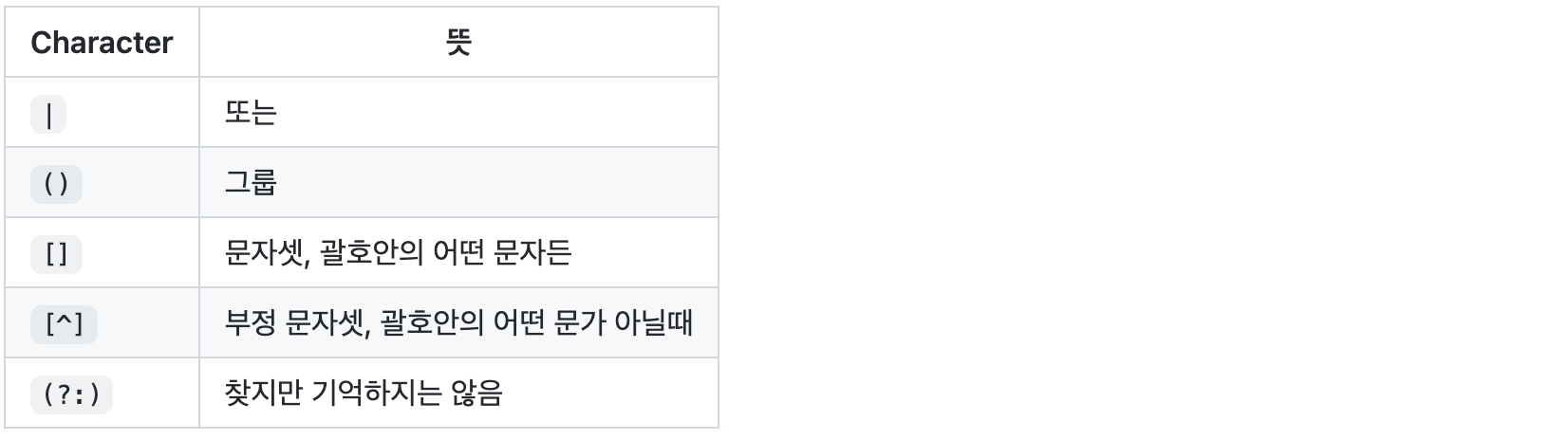
- |
- or
- 패턴을 추가 할 때 사용.
- 두 정규표현식의 합집합
- ( )
- 괄호 내부에 설정한 pattern에 해당하는 문자열들을 group으로 설정한다.
- 즉, pattern의 일부분과 그에 해당하는 문자열들을 명시하는 기능이라고 이해 할 수 있다.
: pattern의 특정 부분집합 참조하기. - 그룹화된 문자열들은 앞에서부터 그룹의 index가 부여된다.
그룹의 중첩 설정도 가능하고(괄호 안에 괄호), 이때 바깥쪽부터 시작하여 안쪽으로 들어갈수록 인덱스가 증가한다. - group에 대한 접근을 index로 하는것에 한계가 있으므로, 이름을 지정 할 수 있다.
: (\w+) --> (?P<그룹이름>\w+)
import re
p = re.compile(r"(\w+)\s+((?P<dialing>\d+)[-]\d+[-]\d+)")
m = p.search("park 010-1234-1234")
print(m.group(1))
print(m.group(2))
print(m.group("dialing"))
# park
# 010-1234-1234
# 010- (?: )
- non-capturing parentheses
- 그룹화 하여 pattern을 표현하지만, 해당 그룹을 이후에 참조 할 수 있도록 관리하지 않습니다.
- r"abc+" : abccc등 ab에 이어 여러개의 c가 있는 문자열 매치
r"(?:abc)+" : abcabc.. 등 abc 문자열이 한 번 이상 반복되는 문자열 매치
- [ ]
- 문자 클래스(character class)
- 찾아야 할 문자의 전체 집합을 명시하는 역할.
ex. [abc] : a,b,c 중 아무 문자나 등장하면 매치 - 하이픈(-) : 문자의 범위를 표현 할 때 사용. (ascii기준)두 문자 사이의 모든 문자를 포함 시킨다. from - to
- [a-zA-Z] : 알파벳 모두
[0-9] : 숫자
- [^ ]
- 문자 클래스(character class)의 역
- 명시한 범위의 문자가 아닌 문자들을 매치
- [^0-9] : 숫자가 아닌 문자에 매치
Quantifiers

r"ca*t"
# "ct", "cat", "caat" ..
r"ca+t"
# "ct" 매치X, "cat" or "caat" or "caaa...aat"
r"ca{2,4}t"
# "c + a가2~4회반복 + t" : "caat" or "caaat" or "caaaat"
r"ab?c"
# "abc" or "ac"Boundary-type

- 해당 문자열이 해당하는 위치에 있을 때만 매치된다.
- \b와 \B는 white space로 구분
- flag가 re.MULTILINE, re.M로 지정된 경우 문자열 (^)맨 앞,($)맨 뒤라는 조건이 모든 줄마다 따로 각각 따로 적용된다.
- "[^ ]" (지정한 범위에 포함되지 않는 문자 매치)와 "^ "는 다르다.
import re
print(re.search('^Life', 'Life is too short'))
# <re.Match object; span=(0, 4), match='Life'>
print(re.search('^Life', 'My Life'))
# None
p = re.compile("^python\s\w+", re.M)
data = """python one
life is too short
python two
you need python
python three"""
print(p.findall(data))
# ['python one', 'python two', 'python three']
p = re.compile(r'\Bclass\B')
print(p.search('no class at all'))
# None
print(p.search('one subclass is'))
# None
print(p.search('the declassified algorithm'))
# <re.Match object; span=(6, 11), match='class'>Character classes
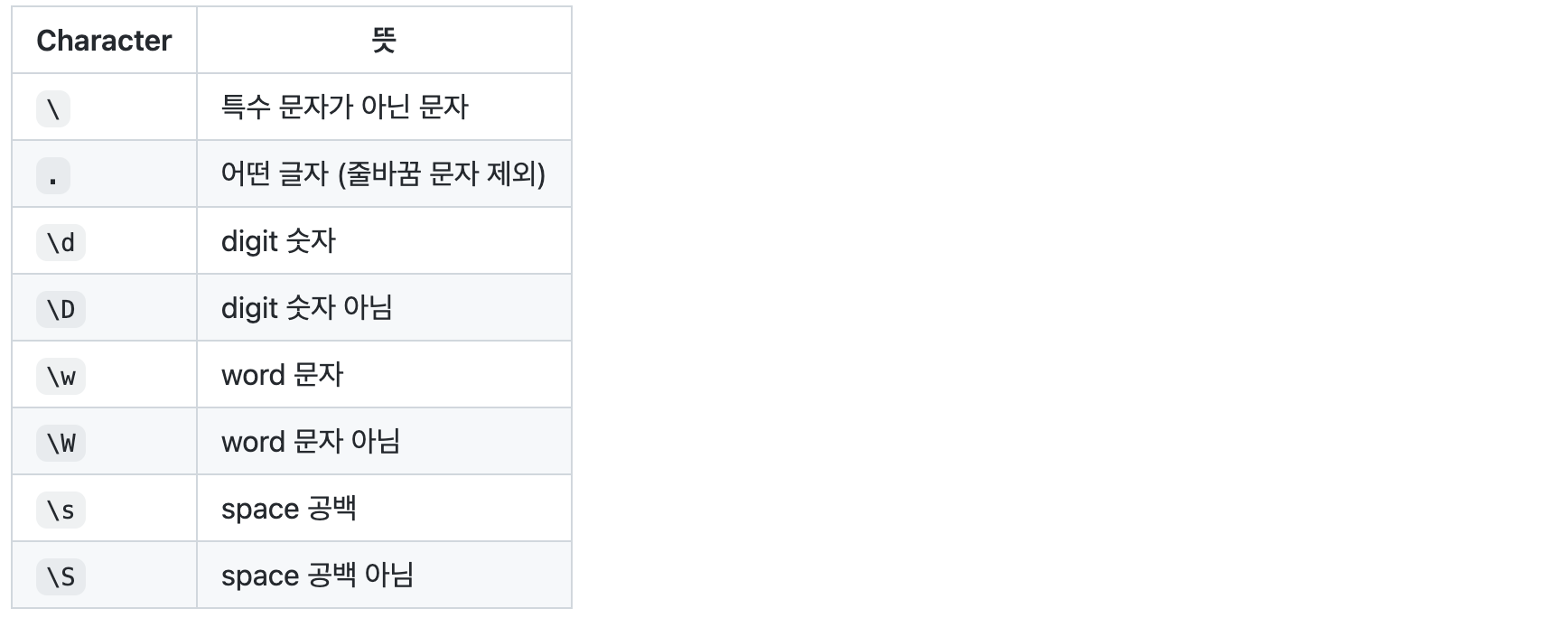
옵션(flag)
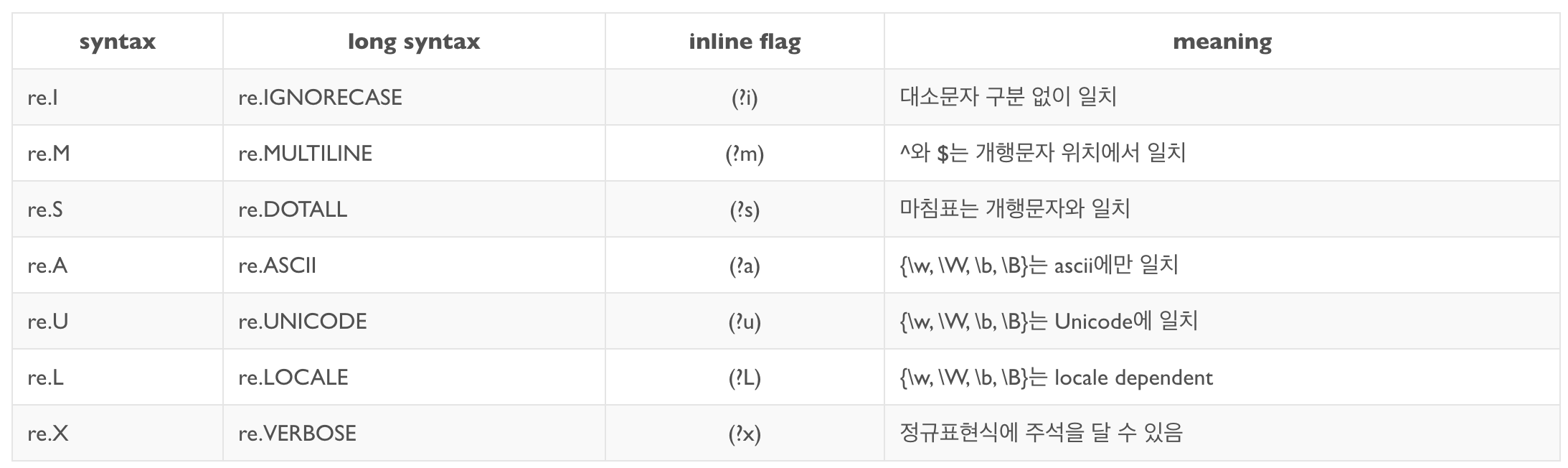
- re.DOTALL, re.S
- '\n'을 포함한 모든 문자와 매치.
- '.'가 기존에 '\n'을 제외한 모든 문자와 매치되지만 옵션을 주면 '\n'와도 매치된다.
p = re.compile('a.b', re.DOTALL)
m = p.match('a\nb')
print(m)
# <re.Match object; span=(0, 3), match='a\nb'>- re.IGNORECASE, re.I
- 대소문자 구별 X
- re.MULTILINE, re.M
- ^, $ 에 대해 여러 줄에 걸친 문자열의 경우 각 줄 마다의 문자열을 따로 매치 적용

- re.VERBOSE, re.X
- 정규표현식을 여러 줄에 걸쳐 표현 할 수 있도록 설정
referenced
- https://engineer-mole.tistory.com/189
https://brownbears.tistory.com/506 - r-string
https://docs.python.org/ko/3/reference/lexical_analysis.html
https://docs.python.org/ko/3/library/re.html - https://wikidocs.net/4309
https://github.com/dream-ellie/regex - https://wikidocs.net/4309#_6
https://hamait.tistory.com/342 - https://greeksharifa.github.io/%EC%A0%95%EA%B7%9C%ED%91%9C%ED%98%84%EC%8B%9D(re)/2018/07/21/regex-usage-02-basic/#%EC%98%B5%EC%85%98-r-prefix
