문자열 type으로 형변환
- str( )
a = 456
b = str(a)
print(b) #456
print(type(b)) #<class 'str'>ascii
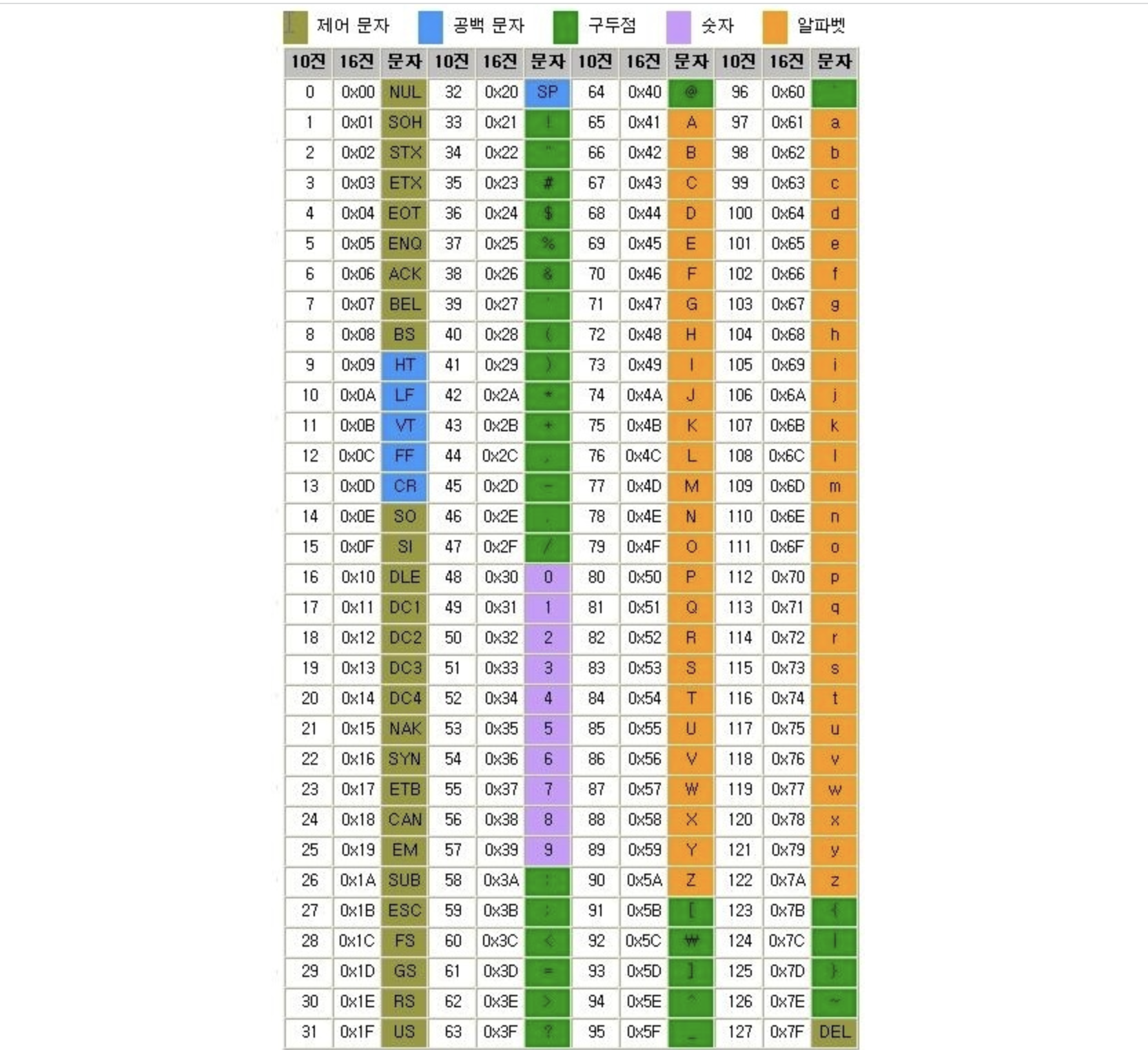
- 0 = 12 x 4 = 48
A = 13 x 5 = 65
a = 97
비교연산
- int와 문자 바로 비교 불가능
if 'A' == 65:
print('O')
else:
print("X")
# X
if 'A' == chr(65):
print('O')
else:
print("X")
# Oord() : 문자 -> ascii
- ord(' ')
x = 'a'
print(ord(x)) #97
print(ord('x')) #120
print(type(ord('x'))) #intchr() : ascii -> 문자
- chr( )
print(chr(65)) #A
print(chr(48)) #0
print(type(chr(48))) #<class 'str'>f-string
print(f"{num}변수를 함께 출력")
formatting
- str
- f"{name:10}"
: 전체 10칸 차지, (default)왼쪽 정렬, 문자열 뒤로 공백 채워짐 - f"{name:>10}"
: 10칸, 오른쪽 정렬, 문자열 앞으로 공백 채워짐 - f"{name:^10}"
: 10칸, 가운데 정렬 - f"{name:*<10}"
: 10칸, 왼쪽 정렬, 문자열 외 나머지 칸 '*' 로 채우기
- f"{name:10}"
- 숫자
- f"{num:10d}"
: 정수 - 전체 10칸, 오른쪽 정렬(숫자 앞에 공백 채움) - f"{num:.1f}"
: 실수 - 소수점 아래 1자리까지 반올림하여 출력 - f"{num:10.1f}"
: 실수 - 전체 10칸, 오른쪽 정렬(숫자 앞에 공백 채움), 소수점 아래 1자리까지 반올림 - f"{num:010.3f}"
: 전체 10칸, 오른쪽 정렬(숫자 앞에 0 채움), 소수점 아래 3자리까지 반올림 출력
- f"{num:10d}"
name = "david"
print(f"{name:*<10}")
num = 17.5678
print(f"{num:.2f}")
print(f"{num:010.3f}")
# david*****
# 17.57
# 000017.568문자열 -> list
문자 하나하나를 element로
- list(str)
str = "python"
my_list = list(str)
print(my_list)
# ['p', 'y', 't', 'h', 'o', 'n']문자열 역순으로 list에 담기
str = 'Hello'
my_list = list(str[-1::-1])
# list(str[::-1])
print(my_list)
# ['o', 'l', 'l', 'e', 'H']str.split("")
- 띄어쓰기를 기준 - 단어를 element로
: str.split()
str = "python is good "
my_list = str.split()
print(my_list)
# ['python', 'is', 'good']- 어떤 문자열을 기준 - 단어를 element로
: str.split('x')
str = "a,b,c,d,e"
my_list = str.split(',')
print(my_list)
# ['a', 'b', 'c', 'd', 'e']list -> 문자열
for문
def listToString(str_list):
result = ""
for s in str_list:
result += s + " "
return result.strip()
str_list = ['This', 'is', 'a', 'python tutorial']
result = listToString(str_list)
print(result)
# This is a python tutorial"".join( )
- 리턴타입은 str type(문자열)
- elements가 (문자열)str타입이라면 그냥 list 자체를 전달.
l = ['b', 'a', 'c']
s = ''.join(l)
print(s) #bac
print(type(s)) #<class 'str'>
l = ['apple', 'can', 'fly']
s = ''.join(l)
print(s) #applecanfly
print(type(s)) #<class 'str'>- elements사이에 공백 - 다른 타입 elements있을 때
str_list = ['There', 'is', 4, "items"]
result = ' '.join(str(s) for s in str_list)
print(result)- list - 공백 없이 출력
- 모든 정수 elements 이어서 하나의 (수)문자열로 출력
str_list = [3, 4, 5, 6]
result = ''.join(str(s) for s in str_list)
print(int(result))탐색
in
- 단순히 부분 문자열인지 판별할 때는 in 사용
s = "abcdefg"
if "de" in s:
print("yes")
#yesstr.find(), str.index()
- 가장 먼저 등장하는 문자열의 첫 번째 글자 index 리턴
- find()는 문자열 없을 시 -1 리턴
text = 'Welcome to Codetorial'
pos_e = text.find('e')
print(pos_e) #1
pos_Code = text.find('Code')
print(pos_Code) #11
pos_code = text.find('code')
print(pos_code) #-1- index()는 문자열 없을 시 예외발생
text = 'Welcome to Codetorial'
pos_e = text.index('e')
print(pos_e) # 1
pos_Code = text.index('Code')
print(pos_Code) #11
pos_code = text.index('code')
print(pos_code) #ValueError: substring not foundstr.rfind(), str.rindex()
- 가장 마지막에 등장하는 해당 문자열의 첫 번째 글자 index 리턴
- rfind()는 문자열 없을 시 -1리턴
text = 'Welcome to Codetorial'
pos_to_last = text.rfind('to')
print(pos_to_last) #15
pos_to_first = text.find('to')
print(pos_to_first) #8- rindex()는 문자열 없을 시 예외발생
text = 'Welcome to Codetorial'
pos_Code_last = text.rindex('Code')
print(pos_Code_last) #11
pos_code_last = text.rindex('code')
print(pos_code_last) #ValueError: substring not found수정, 삭제
: 함수를 적용한 기존 문자열 자체의 값은 유지된다. 함수 적용한 결과의 새로운 문자열을 리턴
text = 'abccc'
text.replace('ab', '')
print(text)
# abcccstr.replace()
- replace("before","after")
text = 'Welcome to Codetorial'
new_text = text.replace('to', 'TO')
print(new_text)
# Welcome TO CodeTOrial- replace("abc","")로 특정 문자열 삭제 가능
text = "this is a abcabcabc text"
text.replace("abc", "")
# 'this is a text'- 2중으로 돌려서 공백제거도 가능
text.replace("abc", "").replace("a ","a")
# 'this is a text'str.strip()
: 문자열 양쪽 끝에서 삭제
: 디폴드 - 인자를 전달하지 않으면 문자열 양 끝의 white space 제거
- lstrip([chars]) : 인자로 전달된 문자열에 포함하는 문자 전부 String의 왼쪽에서 제거
- rstrip([chars]) : 인자로 전달된 문자열에 포함하는 문자 전부 String의 오른쪽에서 제거
- strip([chars]) : 인자로 전달된 문자열에 포함하는 문자 전부 String의 왼쪽과 오른쪽에서 제거
s = " abc d ef "
print('-'+s.strip()+'-')
# -abc d ef-
s = ",,,,,123.....water....pp"
print(s.strip(',123.p'))
# waterre.sub
- re.sub(치환하고 싶은 문자열(정규표현), 새로운 문자열(정규표현), 대상변수)
- import re 필요
import re
text = "abc123def456ghi"
new_text = re.sub(r"[a-z]", "", text)
print(new_text)
# 123456특정 index 문자 삭제
- list로 변환
- del list[i] : 리턴 X
- list.pop(i) : 삭제한 element 리턴
- 모두 list만의 내장함수
s = "abcd"
i = 1
l = list(s)
del l[i]
s = ''.join(l)
print(s) #acd- 슬라이싱 이용
- s = s[:i] + s[i+1:]
s = "abcd"
i = 1
s = s[:i] + s[i+1:]
print(s) #acd슬라이싱
- 양수
s[:a] == s[0:a]- s[:0] == ''
s[:0] != s[0]
s[:1] == s[0] - s[:0] == s[0:0]
- s[:0] == ''
- 음수
s[a:] != s[a:-1]- s[a:]는 무조건 마지막 글자를 포함한다. ''를 표현 할 수 없다.
- s[-1:] == s[-1]
s[-1:-1] == '' - s[-2:] = s[-2] + s[-1]
s[-2:-1] = s[-2]
s = "abcde"
print(s[-1:]) #e
print(s[2:]) #cde
print(s[2:-1]) # cd정렬
sorted(str) : 문자열 하나의 문자들 재정렬
- 알파벳 순으로 정렬해서 한 글자씩 element로 갖는 list를 리턴
- 문자열 본체는 그대로 두고, 새로운 정렬된 list를 리턴한다.
- 문자열에 str.sort()은 사용 할 수 없다.
: list타입에 사용가능
s = "badfgcaa"
l = sorted(s)
print(s) #badfgcaa
print(l) #['a', 'a', 'a', 'b', 'c', 'd', 'f', 'g']단어들 list 정렬
- 문자열(단어)들로 구성된 list 정렬
- list.sort(key=f, reverse=True)
- sorted(iterable, key=f, reverse=True)
- 정리) https://velog.io/@sangyun/Python-list
list.reverse()
- str타입에 reverse() 함수는 사용할 수 없다.
- list로 형변환 후 reverse() 함수 이용
- ''.join(list)로 다시 str
str1 = 'abcde'
str1_list = list(str1) # ['a','b','c','d','e']
str1_list.reverse() # ['e','d','c','b','a']
print(''.join(str1_list)) # edcba[::-1] - 슬라이싱으로 역순
str1 = 'abcde'
print(str1[::-1]) # 'edcba'대소문자
str.uppper(), str.lower()
- 문자열 전체를 전부 대문자, 소문자로 바꿔서 반환
- 본체는 변경 안 된다.
s = "sDaXw"
s2 = s.upper()
print(s) #sDaXw
print(s2) #SDAXWstr.isupper(), str.islower()
- 문자열의 모든 문자가 대문자, 소문자인지 판별
s = "sDaXw"
s2 = s.upper()
print(s.isupper()) #False
print(s2.isupper()) #True함수모음

referenced
- https://codechacha.com/ko/python-convert-list-to-string/
- https://codechacha.com/ko/python-string-strip/
- https://codechacha.com/ko/python-convert-string-to-list/
- https://hack.kr/52
- https://engineer-mole.tistory.com/238
- https://codetorial.net/tips_and_examples/replace_all_strings.html
- https://kongpowder.tistory.com/109
