
1. 최솟값
최대값 알고리즘과 매우 유사하다.

2. 최빈값
빈도수가 가장 높게 나온 자료를 찾는것이다.
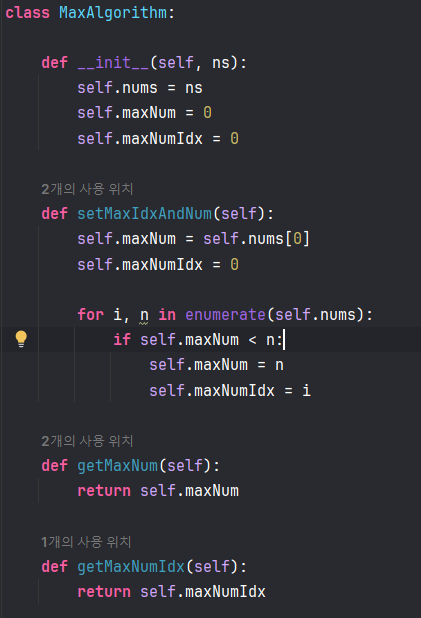
입력된 자료를 enumerate()를 통해 인덱스와 값을 분리하고, 최대값 알고리즘을 통해maxNum과 maxIdx를 분리한다. 분리하는 이유는 후에 기술될 indexes 때문인데, 최빈값을 찾는 원리가 자료안의 값(수)을 인덱스로 보고 indexes를 maxNum+1길이 만큼 설정하면, 해당하는 인덱스에 자료를 카운팅 하는 방식으로 최빈값을 찾는다.

nums의 최대값이 17이므로, indexes는 17까지의 인덱스를 가지는 빈 리스트로 생성해야한다. 이후
for n in nums:
indexes[n] = indexes[n] + 1
위 코드를 통해 앞서 설명했던 nums안의 수를 인덱스로 보고 indexes에 카운팅 해주면 최빈값을 도출할 수 있다.
마지막으로 최대값 알고리즘을 통해 indexes의 최대값(최빈값 카운팅)과 해당 인덱스(최빈값에 해당하는 수)를 출력하면 된다.
3. 근삿값
찾고자 하는 수에 가장 근접한 수를 찾는 알고리즘이다.
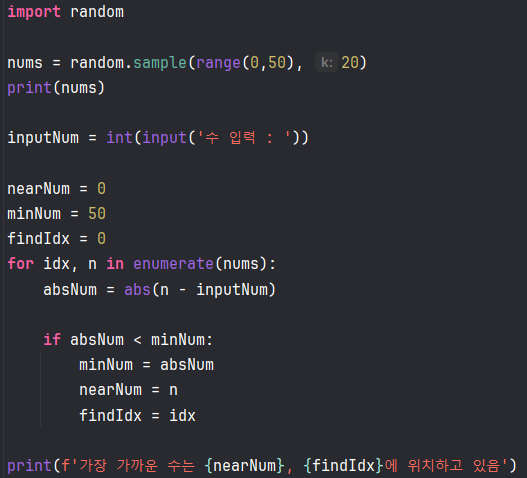
원리는 찾고자하는 수와 찾으려는 자료안의 수와의 차이를 절댓값으로 새로운 변수 (absNum)를 선언한다. 이후 absNum이 minNum (minNum은 자료의 최대값 - 이 역시 최대값 알고리즘으로 찾을 수 있음) 보다 작은 경우 minNum에 absNum값을 넣고 nearNum에 그때의 자료값, 그리고 findIdx에 그때의 인덱스를 저장한다.
작업의 루틴을 예를 들어보자. 만약 찾고자 하는 수가 15이고 nums의 첫번째에 나온값이 18이다. 그렇다면 absNum의 값은 3이 되고 이것은 minNum=50보다 작기 때문에 minNum에 3이 저장되고, nearNum에는 18, findIdx에는 0이 저장된다. 3보다 작은 값이 안나와 자료를 쭈욱~ 훑다가 17번째 인덱스에서 16이 나왔다. 그렇다면 다시 한 번 minNum에는 15와 16의 차이인 1이 저장되고 nearNum에는 16이 findIdx에는 17이 저장된다. 그리고 자료가 끝날 때 까지 16보다 작은수가 안나오면 근삿값은 16이 되는 셈이다.
4. 평균
항상 사용해왔던 평균 알고리즘이다. 너무나 익숙하기 때문에 정리할 것이 별로 없다.

자료 안의 값을 모두 더한다음 해당 자료의 길이만큼 나눠주면 평균이 나오는 구조
5. 재귀
재귀는 자기 자신을 특정 조건을 만족할 때 까지 계속 불러와서 반복하는 것이다. 앞선 기초수학 시간에 팩토리얼이 재귀함수의 대표적인 예시인데, 이번에 예제를 보다가 아,, 또 학창시절 수학공부 안한 티가 난 문제가 나와서 잠시 끄적여본다.

(유클리드 호제법이 뭔데????????)
당황스러웠다. 여튼 원리는 두 자연수 n1, n2에 대하여 (n1 > n2) n1를 n2로 나눈 나머지를 r이라고 할 때,
n1, n2의 최대공약수는 n2와 r의 최대공약수와 같다. 이것을 이용하면 재귀함수를 통해 최대공약수를 구할 수 있다. n1을 n2로 나누었을 때 나머지가 0이라면 당연히 n2가 최대공약수이다. 그렇지 않은 경우에는 유클리드 호제법의 원리에 따라 n1자리에 n2를, n2자리에 나눈 나머지인 r을 넣어줌에 따라 계속해서 반복한다. n2 / r이 0이 될 때 까지 이 작업을 반복하는 것이다.

기록의 여정