
1. 하노이의 탑
잘 알고있는 하노이 게임을 알고리즘으로 풀어낸 것이다. 재귀함수를 이용해 블록의 이동순서를 나타내는데, 이해하는데 상당히 어려움이 있었다.

코드는 정말 간단한데,, 들어있는 로직을 머리속으로 그려내는게 쉽지는 않았다. discCnt가 3일 때를 보면, moveDisc()함수에서 discCnt가 1일 때 까지 else 첫번째 구문에서 계속 재귀함수를 호출하게 되어있다. 이후 discCnt가 1이 되면 print문을 출력하고 그 다음 else 2,3번째 구문이 실행된다.
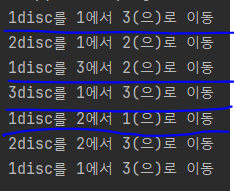
각 구문을 숫자로 나누었는데 실행결과와 맞춰서 비교해보자. 처음 moveDisc(3,1,3,2)이 들어오면 2번이 먼저 실행되는데 discCnt-1 = 2이므로 1번의 조건을 만족하지 못한다. 따라서 다시 2번으로 들어가는데, 이때는 1번의 조건을 만족하기 때문에 1번을 실행한다. 그 다음 두번째 2번으로 들어갔던 함수가 3번을 실행하고 4번으로 들어가서 4번이 1번을 실행한다. 여기까지가 실행결과의 파란색 2번째 줄까지이다.
중간정리 : 2->2->1->3->4->1
여기까지 끝나면 re재귀함수 부분이 모두 끝났기에 제일 처음 moveDisc(3,1,3,2)이 들어와서 2번에서 끝났으니 3번부터 다시 실행한다. 그다음 4번으로 들어가는데 다시 discCnt-1 = 2가 되기 때문에 위에서 일어났던 일이 반복된다.
중간정리 : 3->4->2->2->1->3->4->1
최종정리 : 2->2->1->3->4->1->3->4->2->2->1->3->4->1
벌써 쉬고싶다
2. 병합 정렬
자료구조를 분할하고 각각의 분할된 자료구조를 정렬한 후 다시 병합하여 정렬하는 방법
처음 들었을 때는 굳이 복잡해보이고 어려운 병합 정렬을 왜 사용할까 라는 의문이 들었는데, 검색해보니 안정성, 성능 측면에서 다른 정렬보다 우수하다는 내용이 있다,,
여튼 얘도 재귀함수로 연결되는데 하노이 보다 머리가 더 아프다. 그래도 뜯어보자

하노이처럼 실행 순서를 표기하는건 너무 노가다라 제쳐두고 동작원리 정도만 보려고 한다.
1. 자료가 하나만 남을 때 까지 즉, len(ns)가 1이 될 때 까지 분할을 수행
1-1 분할하기 위해 중간 인덱스 값으로 len(ns)를 2로 나눈 몫을 저장
1-2 왼쪽분할은 0부터 중간 인덱스까지
1-3 오른쪽분할은 중간 인덱스부터 끝까지
1-4 왼쪽, 오른쪽 분할이 모두 완료되면 병합 시작
2. mergeNums = []로 병합할 리스트 생성
2-1 while문 동작 조건을 분할된 leftNums와 rightNums의 길이가 끝날 때 까지로 설정
2-2 만약 8개의 값이 있다면 2,2,2,2개씩 분할된 상태에서 2묶음씩 서로 비교를 진행하는데, 이때 2묶음안에서 왼쪽이 큰지 오른쪽이 큰지를 값을 비교
2-3 오른쪽이 크다면 왼쪽값을 먼저 mergeNums에 넣고 다음 오른쪽값 넣음
2-5 2,2,2,2 묶음을 모두 진행했다면 4,4 묶음 진행
2-4 4,4 이후는 마지막 작업 모두 병합 원리는 각 작업 모두 동일
최대한 이해해보려고 풀어썼는데, 그래도 아직 이해가 잘 안가는건 사실,,
위는 병합정렬 예제인데, 유심히 봐야할 부분은 오름,내림차순 정렬을 옵션으로 넣었을 때이다. 원함수 mSort에 asc=False조건을 넣어도 후행 기술될 재귀함수의 인자에도 asc=asc 조건을 넣어야만 동작한다. 만약 asc 조건을 넣지 않으면 처음에만 asc=False가 들어오고 뒤부터는 asc=True(default값)이 들어가기 때문에 우리가 원하는 결과가 나오지 않는다는 점
3. 퀵 정렬
기준보다 작은 값과 큰 값을 분리하여 정렬
병합 정렬보다는 해석이 쉬운편이다.

퀵정렬의 동작원리도 위 코드를 통해 차근차근 뜯어보자.
1. midIdx=5, midVal=5이다.
2. for문에서 ns값들을 midVal과 비교하여 각 리스트에 담는다
2-1 첫번째의 경우 1,3,2,4가 smallNums에 담기고 5가 sameNums에 6,8,8,10이 bigNums에 담긴다.
3. 이를 return하여 small과 bigNum은 re재귀를 통해 안의 값들을 정렬하는 절차를 가진다.
3-1 두번째의 경우 qSort(smallNums)와 qSort(bigNums)로 분기가 나뉜다.
3-2 small의 경우 1,3,2,4 가 들어갔으므로 midIdx=2, midVal=2이며 마찬가지로 for문을 통해 1이 small, 3,4가 big에 담긴다. 이를 다시 re재귀 하면 1, 2, 3, 4로 정렬되는 결과를 가져온다.
3-3 big의 경우 6,8,8,10이 들어갔으므로 midIdx=2, midVal=8이며 마찬가지로 for문을 통해 6이 small, 8은 same, 10은 big에 담긴다. 이를 다시 re재귀하면 6, 8, 8, 10으로 정렬되는 결과를 가져온다
4. 3-2와 3-3의 결과로 재귀함수가 마무리 됐기 때문에 3번으로 돌아가서 3-2의 결과와 sameNums 그리고 3-3의 결과를 모두 더한것을 리턴하면 최종 정렬이 완성된다.
분기가 나뉘어져서 약간 당황했지만 그래도 이해하기는 수월했다,, 병합 정렬 예제와 마찬가지로 내림차순 옵션을 넣고 싶으면 해당 재귀함수 안의 내림차순 코드에 asc인자를 넣어야 정상 작동한다는 점을 꼭 유의하자 !

기록의 여정