
학습목표
- Multi-Layer Perceptron(MLP) 구조를 설명할 수 있다.
- MLP를 이용해서 이미지 분류를 어떻게 할 수 있는지를 설명하고, 코드를 작성할 수 있다.
- 이미지 데이터를 분석할 때 MLP가 가진 한계점을 설명할 수 있다.
MLP 모델 복습하기
-
What is Deep Learning?
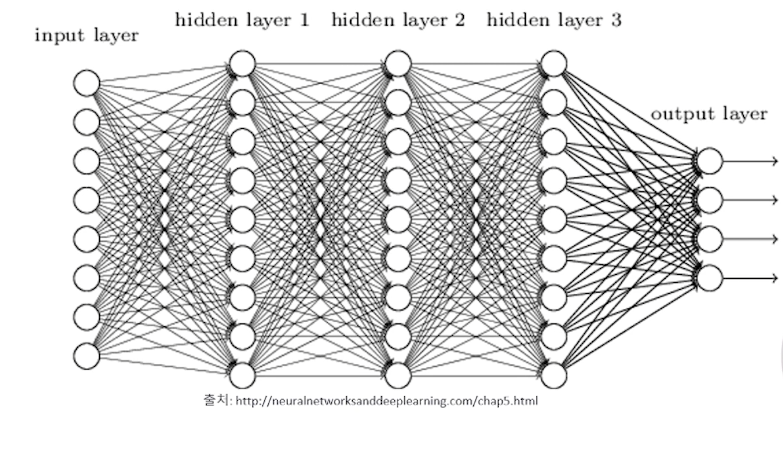
딥러닝 구조의 핵심은 여러 개의 hidden layer로 인해 학습기가 deep 하다는 것이다.
-
뉴런의 작동 방식
수용 → 조합 → 경계값/조건에 따라 전달
뉴런은 계속해서 신호를 받아서 그것을 조합하고, 특정 threshold가 넘어서면 "fire"를 한다.
-
퍼셉트론의 구조 및 역할
퍼셉트론 ≈ 뉴론
입력변수 ≈ 수용
가중합 ≈ 조합
활성함수 ≈ Threshold
최종 결과물 ≈ 전달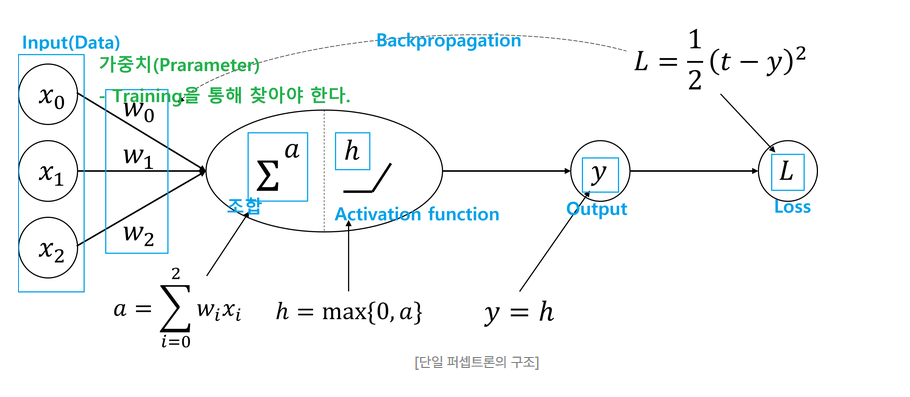
단일 뉴런의 작동 원리를 묘사
- 뉴론 : 시냅스로부터 탐지된 자극을 수상돌기를 통해 세포핵에 전달 후 역치를 넘어서는 자극에 대해서는 축색돌기를 이용하여 다른 뉴런으로 정보를 전달
- 퍼셉트론 : 입력변수(수용)의 값들에 대한 가중합(조합)에 대해 활성함수(임계값/조건)를 적용하여 최종 결과물 생성
-
더 많은 은닉 노드(뉴런)의 효과
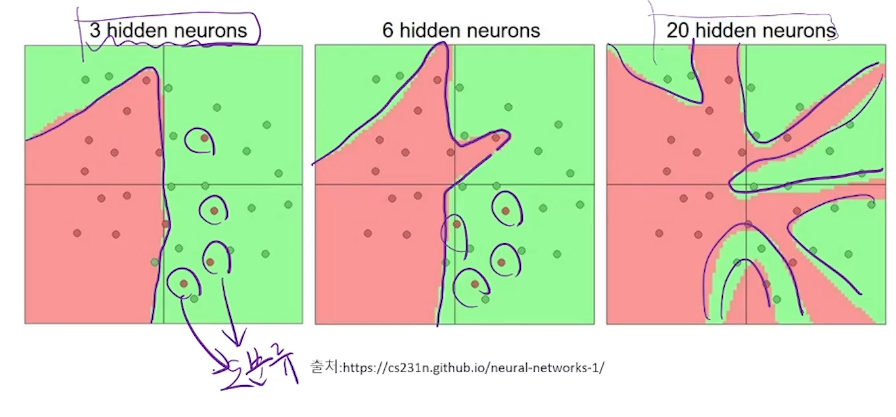
더 많은 은닉 노드가 생기면 분류 경계면 복잡도가 늘어난다.
-
MLP
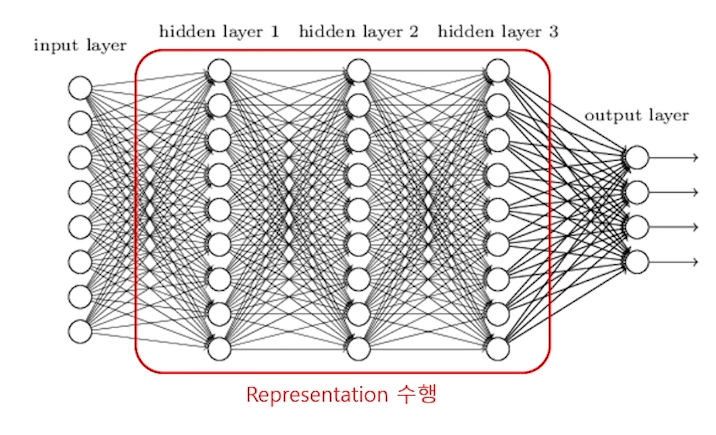
Representation 수행
정보(Input layer)의 패턴을 찾는 과정이 Representation Learning이라고 한다.
은닉 노드가 증가하면 패턴을 다양하게, 복잡하게 찾을수 있다.
Representation Learning = Pattern Extraction = Feature Extraction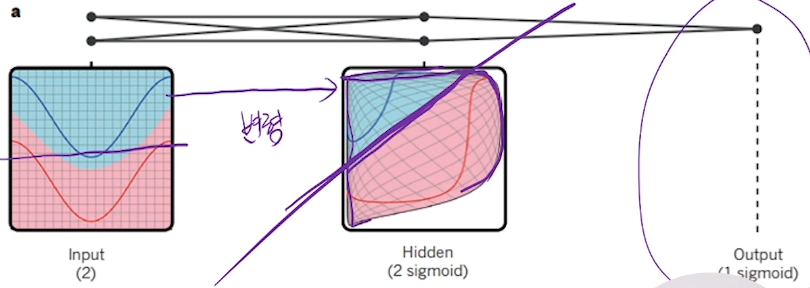
Representation을 통해서 원래 데이터가 존재하는 공간을 변경한다.
Training하는 과정에서 은닉 노드가 task를 수행하는 데에 가장 적합한 공간구조를 Representation하게 된다.Task 수행
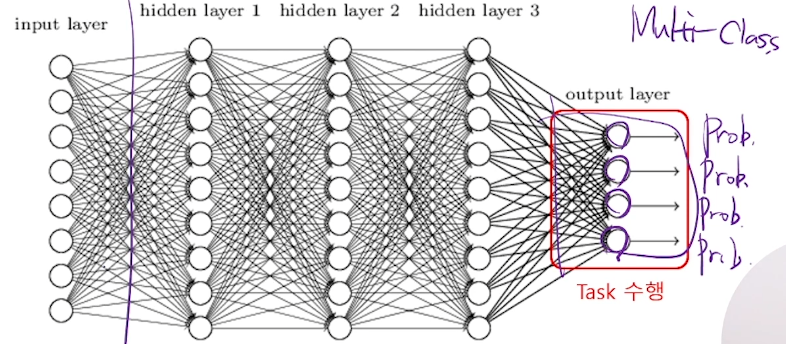
확률값을 출력한다.
모델설계부분을 아직 못함(LMS)
MLP 모델의 한계
-
어떻게 이미지 데이터를 MLP에 적용할까?
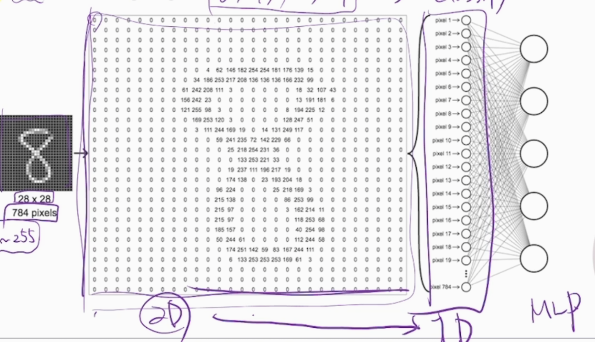
MNIST dataset은 28 x 28 사이즈로 784 pixel의 2D 이미지다. 이를 MLP 모델에 적용하기 위해서는 2차원 데이터 1차원 구조로 변경시켜야 한다.
행과 열로 저장된 데이터에서 하나의 행 혹은 열을 노드로 전환 시켜서 적용시킨다. (28 X 28 => 784노드) -
이미지 데이터와 MLP 구조의 불합치
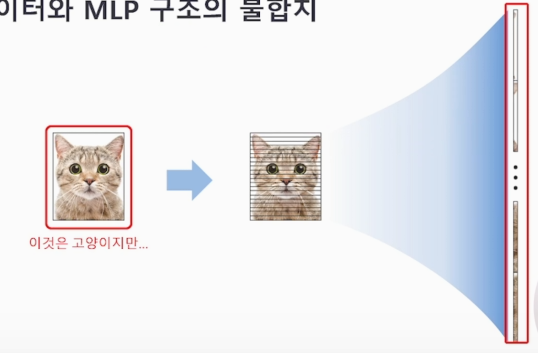
하지만 앞에서 픽셀 하나로만 데이터의 정보를 파악할수 없다. 따라서 이미지 데이터와 MLP 구조의 불합치가 일어난다.
정리
- MLP구조는 데이터 안에 숨겨진 패턴을 Representation을 통해서 찾는다.
- MLP로 이미지 분류를 하기 위해서 2차원의 이미지를 1차원으로 변형해야 한다.
- 이미지의 차원을 변형할 때, 이미지 데이터가 가진 정보가 사라질 수 있다.
