학습목표
- 딥러닝 모델을 학습하기 위한 개념을 이해한다
- 손실 함수, 옵티마이저, 지표에 대해서 학습한다.
손실함수
-
손실함수는 학습이 진행되면서 해당 과정이 얼마나 잘 되고 있는지 나타내는 지표(손실함수는 작을수록 좋다)
-
모델이 훈련되는 동안 최소할될 값으로 주어진 문제에 대한 성공 지표
-
손실 함수에 따른 결과를 통해 파라미터를 조정하며 학습이 진행
-
손실함수는 최적화 이론에서 최소화 하고자 하는 함수로 미분 가능한 함수를 사용
-
keras에서 제공되는 주요 손실 함수
- 'sparse_categorical_crossentropy' : 클래스가 배타적 방식으로 구분, 즉 (0,1,2, ....,9)와 같은 방식으로 구분되어 있을 때 사용
- 'categorical_cross_entropy' : 클래스가 원-핫 인코딩 방식으로 되어 있을 때 사용
- 'binary_crossentropy' : 이진 분류를 수행할 때 사용
-
평균절대오차
- 오차가 커져도 손실함수가 일정하게 증가
- 이상치에 강건한 특성
- 데이터에서[입력-정답] 관계가 적절하지 않은 것이 있을 경우에, 좋은 추정을 하더라도 오차가 발생하는 경우가 발생하는데, 이상치에 해당하는 지점에서 손실 함수의 최소값으로 가는 정도의 영향력이 크지 않은 특성을 가지고 있음
- 일반적으로 회귀에 많이 사용하는 손실함수
- |정답 - 모델 예측한 결과 값| = 평균절대오차
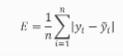
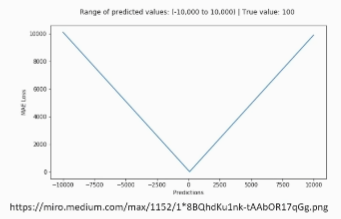
-
평균제곱오차
- 가장 많이 사용되는 손실 함수 중 하나
- 오차가 커질수록 손실함수가 빠르게 증가하는 특성
- 정답과 예측한 값의 차이가 클수록 더 많은 페널티를 부여하는 형태로 동작
- 일반적으로 회귀에 사용되는 손실함수
- (정답 -모델 예측한 결과 값)^2
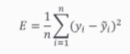
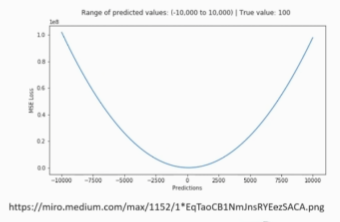
-
평균절대오차 vs 평균제곱오차
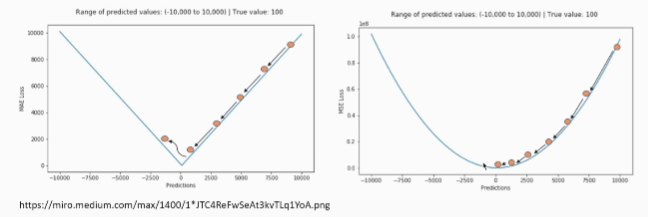
평균절대 오차 : 일정하게 감소
평균제곱 오차 : 차이가 클때는 더 많이 감소한다. -
원-핫 인코딩
- 범주형 변수를 표현할 때 사용
- 가변수라고도 함
- 정답인 레이블만 1이고 나머지는 0으로 처리하는 형태
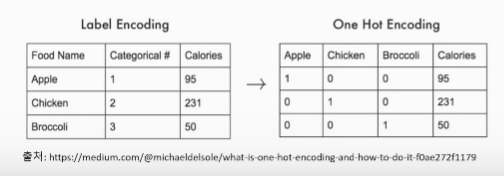
-
교차 엔트로피 오차
-
이진 분류 또는 다중 클래스 분류에 주로 사용
-
오차는 소프트맥스 결과와 원-핫 인코딩 사이의 출력 간 거리를 비교
-
정답을 맞추면 오차가 0, 틀리면 그 차이가 클수록 오차가 무한히 커지게 됨
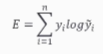
-
이진 분류 문제의 교차 크로스 엔트로피
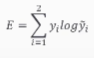
-
-
이진 분류 문제의 교차 크로스 엔트로피
옵티마이저와 지표
-
옵티마이저는 손실 함수를 기반으로 모델이 어떻게 업데이트되어야 하는지 결정
-
keras에서 여러 옵티마이저를 제공하고, 사용자가 특정 종류의 확률적 경사 하강법 지정 가능
- 'keras.optimizer.SGD()' : 기본적인 확률적 경사 하강법
- 'keras.optimizer.Adam()' : 자주 사용되는 옵티마이저
-
보통 옵티마이저의 튜닝을 위해 따로 객체를 생성하여 컴파일시에 포함
-
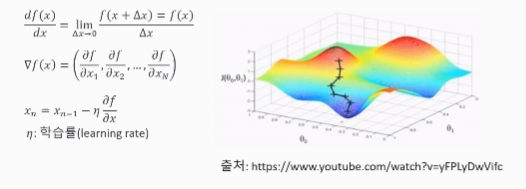
경사하강법
- 경사하강법은 미분과 기울기로 동작하며, 스칼라를 벡터로 미분
- 변화가 있는 지점에서는 미분값이 존재하고, 변화가 없는 지점은 미분값이 0이 되며, 미분값이 클수록 변화량이 큼
- 경사하강법의 과정은 한 스텝마다의 미분값에 따라 이동하는 방향을 결정, f(x)의 값이 변하지 않을때까지 반복
-
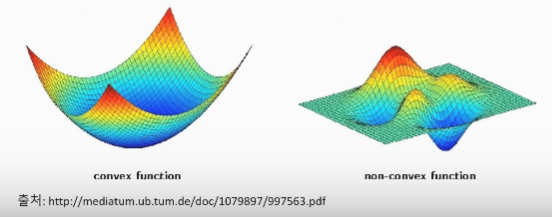
볼록함수와 비볼록함수
- 볼록함수는 어떤 지점에서 시작하더라도 최적값에 도달 가능(최적값 = 손실함수가 최소로 하는 점)
- 비볼록함수는 시작점 위치에 따라 다른 최적값에 도달할 수 있음
-
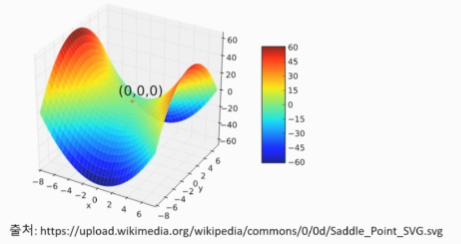
안장점
- 기울기가 0이지만 극값이 되지 않는 안장점이 존
- 기울기의 반대 방향으로 다음 위치를 이동해야하는데 기울기 값이 0이라 이동하지 못한다
- 경사하강법은 안장점에서 벗어나지 못하는 문제가 있음
-
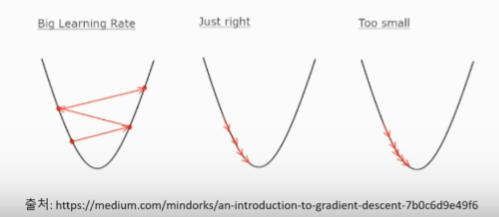
학습률
- 모델을 학습하기 위해서는 적절한 학습률을 지정해야 최저점에 잘 도달할 수 있음
- 학습률은 경사하강법을 통해 손실함수의 반대 기울기 방향으로 업데이트 할 때 업데이트 되는 크기에 관여한다
- 학습률이 너무 크면 발산하고, 너무 작으면 학습이 오래 걸리거나 최저점에 도달하지 못하는 문제가 있음
-
지표
- 딥러닝 학습 시 필요한 다양한 지표들을 지정 가능
- 일반적으로 'mae'나 'accuracy'를 사용
- 'accuracy' 같은 경우 줄여서 'acc'로도 사용이 가능
딥러닝 모델 학습
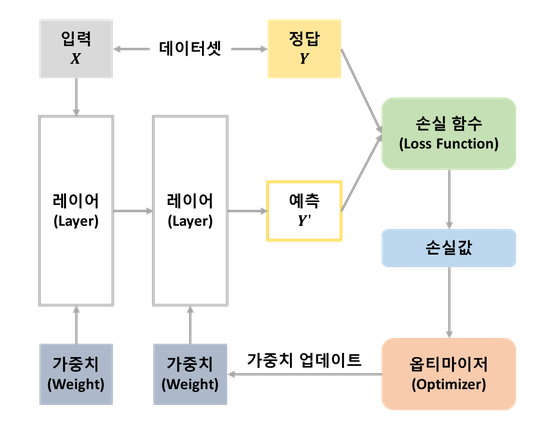
- 데이터셋을 입력 X와 정답(레이블)인 Y로 구분
- 입력 데이터는 연속된 레이어로 구성된 네트워크(모델)를 통해 결과로 예측 Y'을 출력
- 손실 함수는 모델이 예측한 Y'과 실제 정답인 Y와 비교하여 얼마나 차이가 나는지 측정하는 손실 값을 계산한다.
- 옵티마이저는 손실 값을 사용하여 모델의 가중치의 엡데이트하는 과정을 수행합니다.
- 모델이 새롭게 예측한 Y'과 실제 정답인 Y의 차이를 측정하는 손실 값을 계산하는 과정을 반복
- 계산한 손실값을 최소화하도록 옵티마이저가 동작하는 것이 딥러닝 모델 학습이다.

프로그램 공부하는 사람