
데이터가 단일 물리 머신의 저장 용량을 초과하게 되면 전체 데이터셋을 분리된 여러 머신에 나눠 저장할 필요가 있다. 네트워크로 연결된 여러 머신의 스토리지를 관리하는 파일시스템을 분산 파일시스템이라고 한다.
1. HDFS 설계
- HDFS는 범용 하드웨어로 구성된 클러스터에서 실행되고 스트리밍 방식의 데이터 접근 패턴으로 대용량 파일을 다룰 수 있게 설계되었다.
- HDFS는 매우 큰 파일을 다루며, 스트리밍 방식으로 데이터에 접근한다.
- 빠른 데이터 응답시간이 필요한 시스템에는 적합하지 않다. HDFS는 높은 데이터 처리량에 최적화되어 있다. (HBase가 대안이 될 수 있다.)
- 수많은 작은 파일이 있는 시스템에는 적합하지 않다. 네임노드는 파일시스템의 메타데이터를 메모리에서 관리하기 때문에 저장할 수 있는 파일 수는 네임노드 메모리 용량에 좌우된다.
2. HDFS 개념
1) 블록
- 블록 크기는 한 번에 읽고 쓸 수 있는 데이터의 최대량이다.
- HDFS의 블록은 128MB와 같이 굉장히 큰 단위다. HDFS의 파일은 단일 디스크를 위한 파일시스템처럼 특정 블록 크기의 청크로 쪼개지고, 각 청크는 독립적으로 저장된다.
- HDFS 블록의 크기가 큰 이유는 탐색 비용을 최소화하기 위해서다. 블록이 매우 크면 블록의 시작점을 탐색하는 데 걸리는 시간을 줄일 수 있고, 데이터를 전송하는 데 더 많은 시간을 할애할 수 있다.
- 분산 파일시스템에 블록 추상화 개념을 도입하면서 얻게 된 이득
- 이제 파일 하나의 크기가 단일 디스크 용량보다 커질 수 있다. 하나의 파일을 구성하는 여러 개의 블록이 아무 데나 저장되어도 되기 때문.
- 스토리지의 서브 시스템을 단순하게 만들 수 있다. 블록은 고정 크기고 저장된 데이터의 청크일 뿐이다.
- Fault tolerance와 Availability를 제공할 때 필요한 Replication 구현이 쉽다.
2) 네임노드와 데이터노드
- HDFS 클러스터는 master-worker로 동작하는 두 종류의 노드 (마스터인 하나의 namenode & 워커인 여러 개의 datanode)로 구성되어 있다.
- 네임노드는 파일시스템의 네임스페이스를 관리한다. 파일시스템 트리와 그 트리에 포함된 파일과 디렉터리에 대한 메타데이터를 유지한다. 이 정보는 namespace image와 edit log라는 두 종류의 파일로 로컬 디스크에 영속적으로 저장된다.
- HDFS 클라이언트는 사용자 대신 네임노드와 데이터노드 사이에서 통신하고 파일시스템에 접근한다.
- 데이터노드는 클라이언트나 네임노드의 요청에 따라 블록을 저장하고 탐색한다.
- 네임노드 장애 복구 위해 2가지 기능이 제공된다.
1) 파일 백업
2) Secondary namenode
3) Block cache
- 자주 접근하는 블록은 off-heap(자바 힙 외부에서 관리) block cache라는 데이터노드의 메모리에 명시적으로 캐싱할 수 있음.
4) HDFS Federation
- HDFS Federation을 활용하면 각각의 네임노드가 파일시스템의 네임스페이스 일부를 나누어 관리할 수 있다. -> 메모리 확장성 문제 해결
5) HDFS 고가용성
- 네임노드는 여전히 SPOF(Single Point Of Failure)다.
- Active-stanby 상태로 설정된 한 쌍의 네임노드를 구현한다. 활성 네임노드에 장애가 생기면 대기 네임노드가 역할을 이어받는다.
3. CLI
1) 기본적인 파일시스템 연산
- 단 책에서는 hdfs://localhost/user~ 이렇게 했는데, /etc/hadoop/site-core.xml에서 localhost:9000으로 포트를 잡아주었으므로 localhost:9000으로 명령을 줘야 제대로 들어간다.

- https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/FileSystemShell.html
4. 하둡 파일 시스템
- 하둡은 파일시스템의 추상화 개념을 가지고 있고, HDFS는 그 구현체 중 하나일 뿐이다.
- 자바 추상 클래스 org.apache.haddop.fs.FileSystem을 이용하면 하둡의 파일시스템에 접근할 수 있다.
- HTTP REST API를 이용해도 HDFS에 접근할 수 있지만 네이티브 자바 클라이언트보다는 느리다.
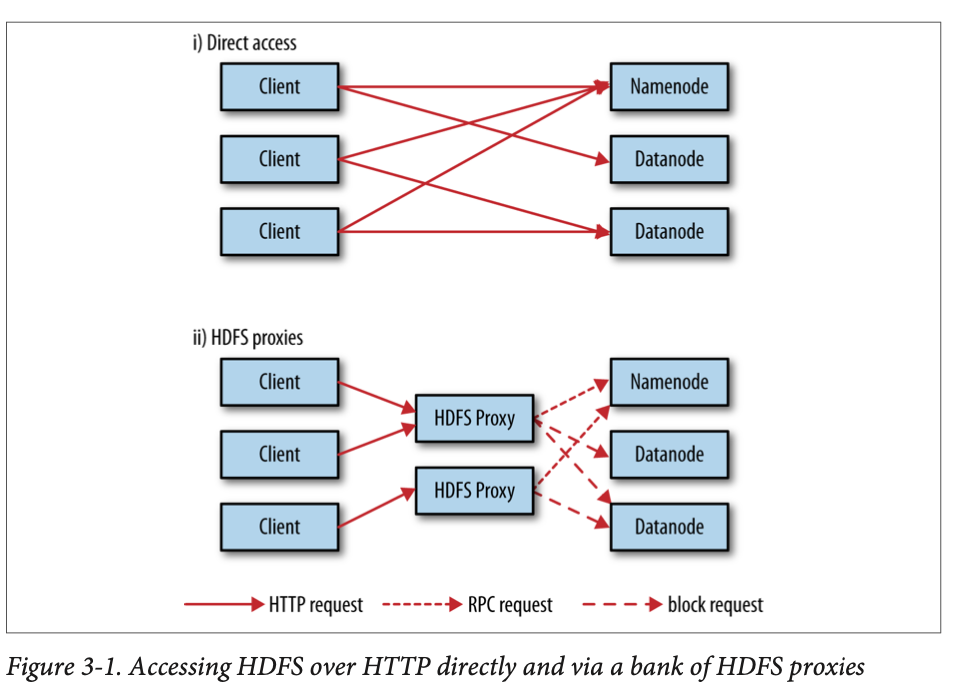
5. 데이터 흐름
-
Read에서 데이터의 흐름
1) DistributedFileSystem 인스턴스인 FileSystem 객체의 open() 메소드로 원하는 파일을 연다.
2) DistributedFileSystem은 파일의 첫 번째 블록 위치를 파악하기 위해 RPC를 사용하여 네임노드를 호출한다. 네임노드는 블록별로 해당 블록의 복제본을 가진 데이터노드의 주소를 반환한다. 이 때 클러스터의 네트워크 위상에 따라 클라이언트와 가까운 순으로 데이터 노드가 정렬된다.
3) FSDataInputStream을 이용해 읽고 닫는다.
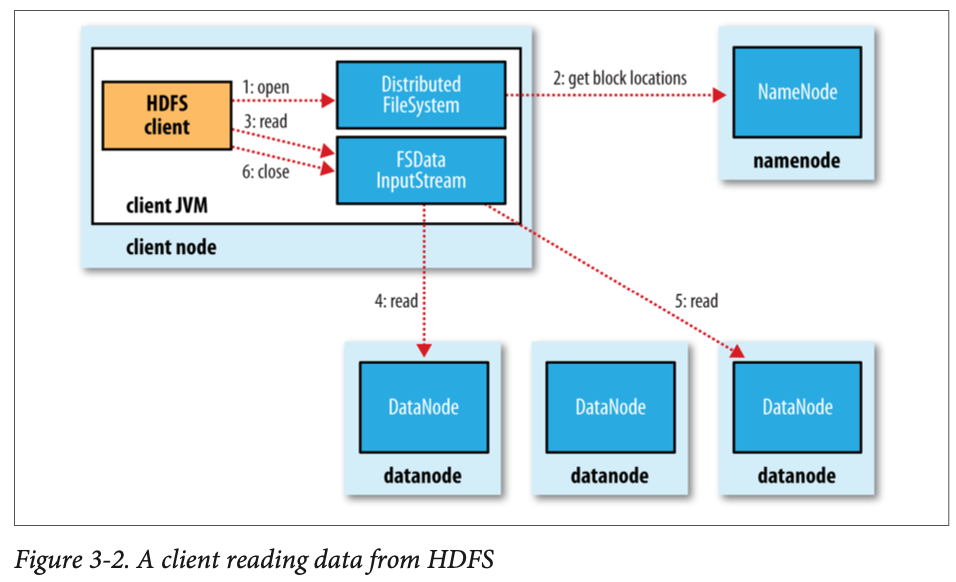
- 중요한 것은, 클라이언트가 데이터노드에 직접 접촉하고 네임노드는 각 블록에 적합한 데이터노드로 안내해준다는 것이다.
- 데이터트래픽은 클러스터에 있는 모든 데이터 노드에 고르게 분산되므로 HDFS는 동시 접속 클라이언트 수를 늘릴 수 있다.
- 네임노드에는 bottleneck 없다. 블록 위치 정보만 처리하고 데이터 직접 저장/전송 안 하기 때문.
-
Write에서 데이터의 흐름
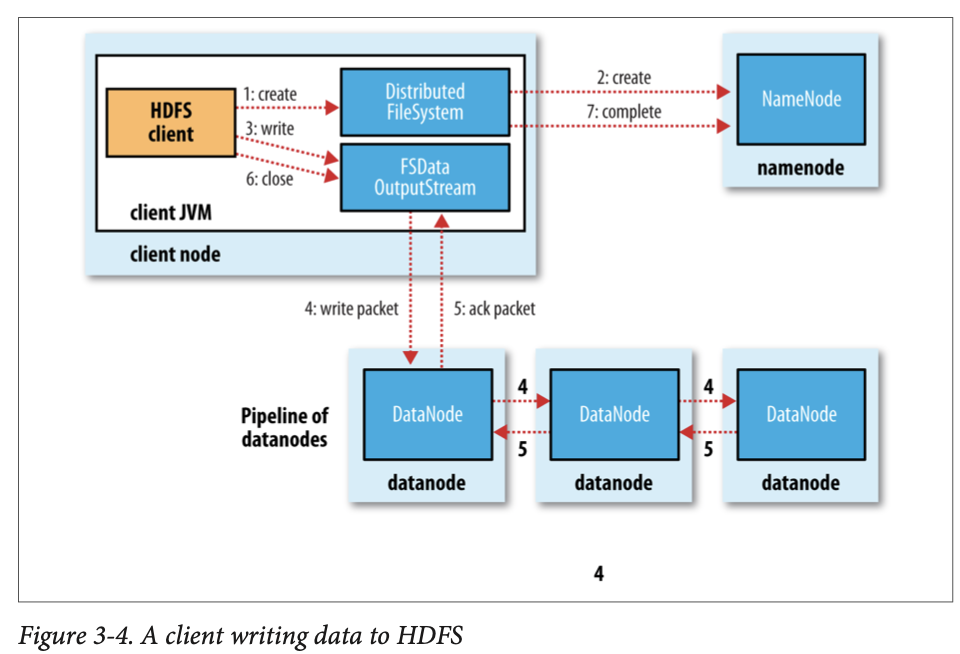
- 핵심은 패킷을 복제 수준에 따라 쓰는 과정 & ack 패킷이다.
