Hadoop: The Definitive Guide
1.1. 하둡과의 만남

1. 하둡과 다른 시스템과의 비교 1) RDMBS와의 비교 하지만 하둡 역시 Interactive하게 발전하고 있으며(Hive) 색인이나 트랜잭션 기능을 추가하고 있다. 하둡은 처리 시점에 데이터를 해석하도록 설계되어 있기 때문에 비정형 데이터(일반 텍스트, 이미지)나 반정형 데이터(그리드 형태의 셀 구조로 된 스프레드시트)도 잘 처리할 수 있다. sche...
2.2. MacOS에 하둡 설치하는 법
1. Java 설정 1) 터미널에서 java -version을 입력했을 때 java version이 1.8 이하이면 2)로 넘어간다. 그렇지 않고 15나 14로 나오면 아래 절차를 수행한다. 1-1) 터미널에서 /usr/libexec/java_home -V라고 치면 다음과 같이 출력된다. 만약 목록에 1.8 이하 버전이 없는 경우 구글에 검색해서 설치한다....
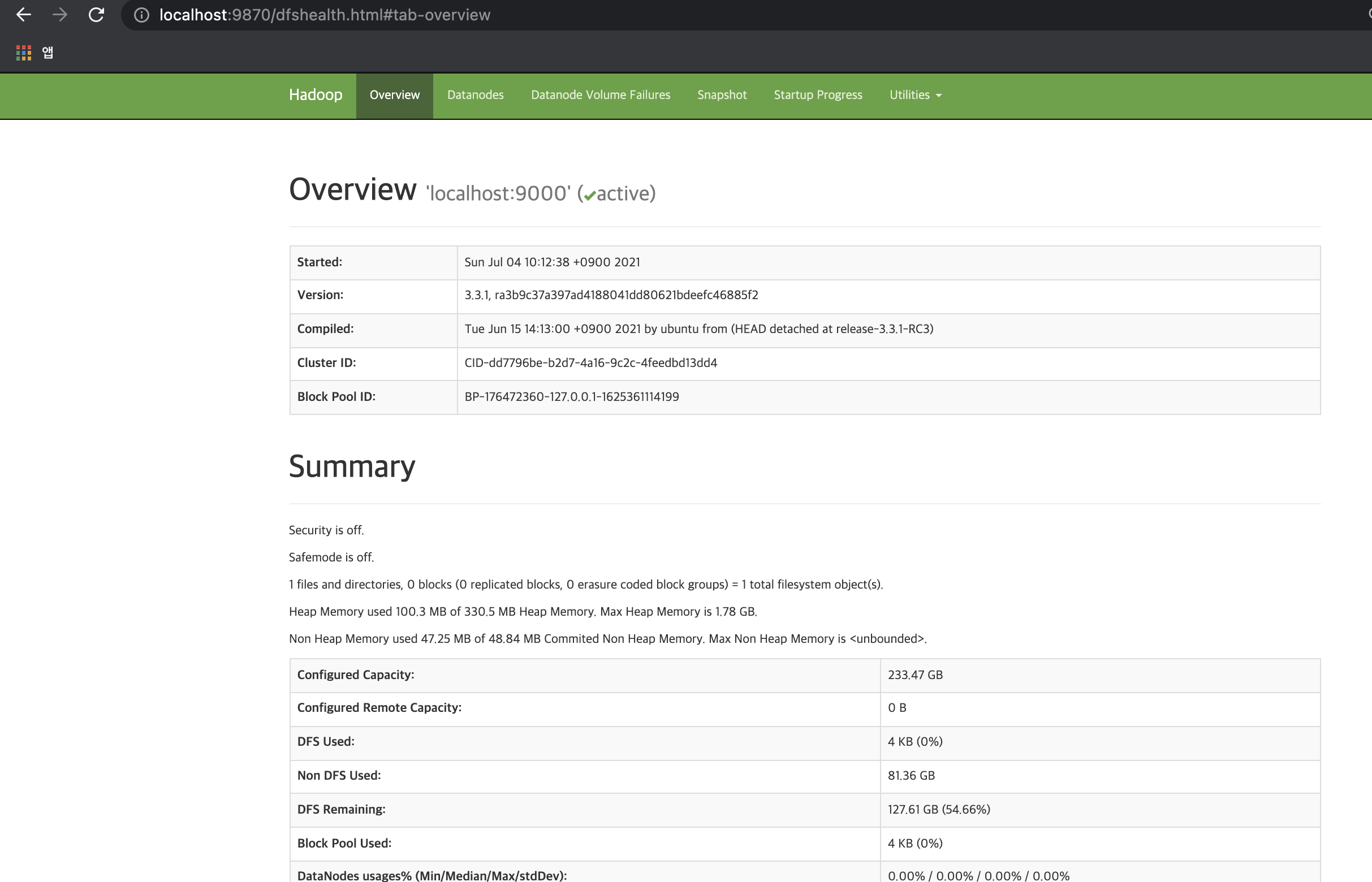
3.3. HDFS

데이터가 단일 물리 머신의 저장 용량을 초과하게 되면 전체 데이터셋을 분리된 여러 머신에 나눠 저장할 필요가 있다. 네트워크로 연결된 여러 머신의 스토리지를 관리하는 파일시스템을 분산 파일시스템이라고 한다. 1. HDFS 설계 HDFS는 범용 하드웨어로 구성된 클러스터에서 실행되고 스트리밍 방식의 데이터 접근 패턴으로 대용량 파일을 다룰 수 있게 설계되었...
4.4. HDFS Java API 사용법
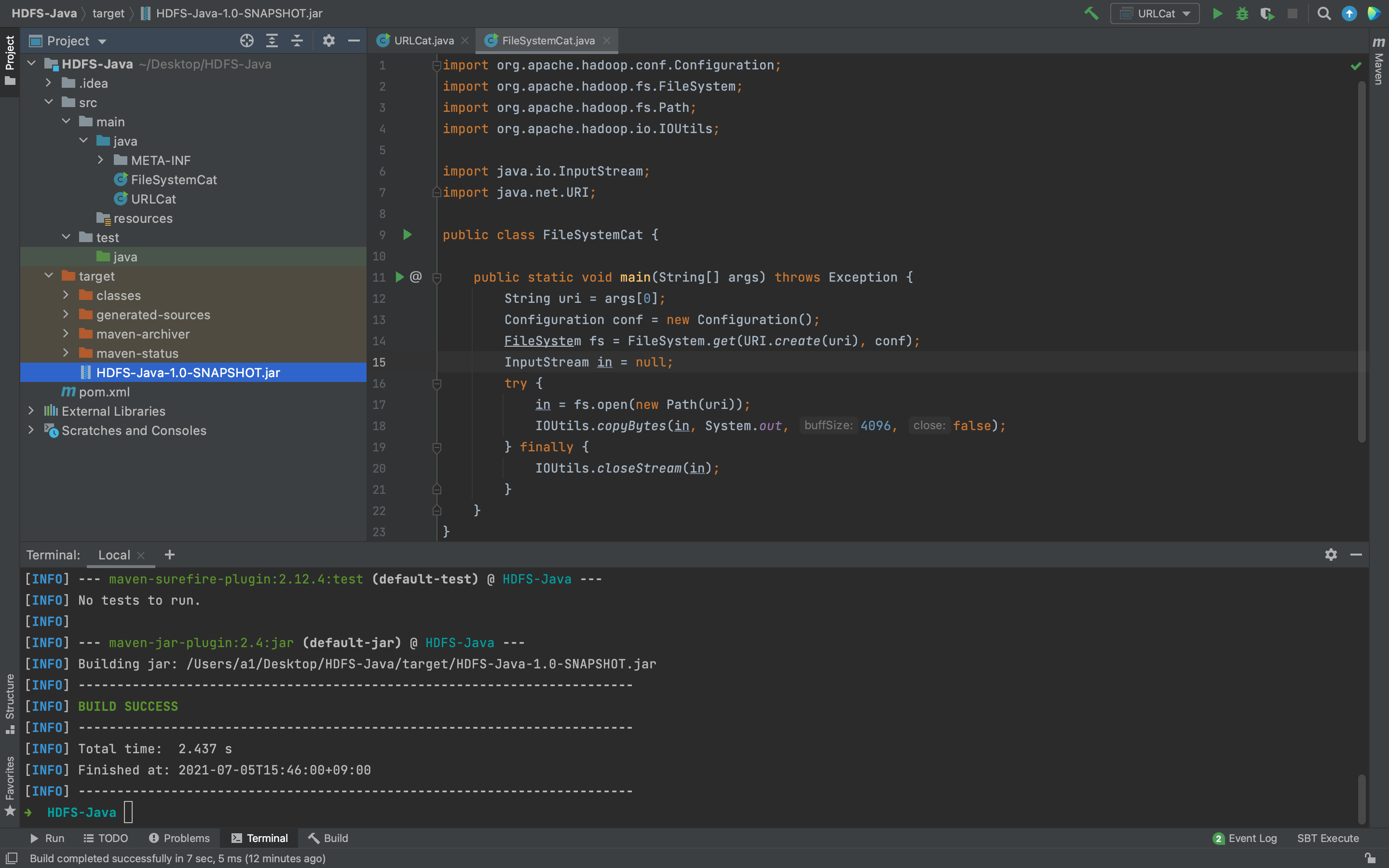
위 스크린샷처럼 사용할 클래스들을 생성한 후 터미널에서 mvn package 입력하면 snapshot jar 파일 생성됨. 터미널에 아래와 같은 커맨드를 주면 파일시스템에 접근 가능.
5.4. Parquet

Parquet는 중첩된 데이터를 효율적으로 저장할 수 있는 Columnar 저장 포맷이다. Columnar 포맷은 동일한 컬럼의 값을 나란히 모아 저장하기 때문에 인코딩 효율이 높고 파일 크기가 작다. 또, 쿼리 엔진은 필요 없는 컬럼 빼기 때문에 쿼리 성능도 높다. Parquet의 핵심은 중첩 구조의 데이터를 저장할 수 있다는 것이다. 1. 데이터 ...
6.5. YARN

YARN은 하둡의 클러스터 자원 관리 시스템이다. YARN 위에서 분산 컴퓨팅 애플리케이션이 돌아간다. YARN이 애플리케이션을 구동하는 방식은 다음과 같다. https://www.popit.kr/what-is-hadoop-yarn/ https://dabingk.tistory.com/8
7.6. Hive

하이브는 하둡 기반의 데이터 웨어하우징 프레임워크다. 대량의 데이터를 관리하고 학습하기 위해 개발되었다. HDFS를 SQL로 분석할 수 있는 도구이다. 1. Hive 설치 https://wannabe-gosu.tistory.com/54 이 때 주의할 점. mysql 'hiveuser'@'localhost'에 권한 주는 코드가 deprecated 되어서 ...