
Parquet는 중첩된 데이터를 효율적으로 저장할 수 있는 Columnar 저장 포맷이다. Columnar 포맷은 동일한 컬럼의 값을 나란히 모아 저장하기 때문에 인코딩 효율이 높고 파일 크기가 작다. 또, 쿼리 엔진은 필요 없는 컬럼 빼기 때문에 쿼리 성능도 높다. Parquet의 핵심은 중첩 구조의 데이터를 저장할 수 있다는 것이다.
1. 데이터 모델
- Parquet 파일에 저장된 데이터는 루트에 필드 그룹을 포함한 Message를 갖는 스키마로 정의된다. 각 필드는 반복자(required, optional, repeated), 타입, 이름으로 되어 있다.
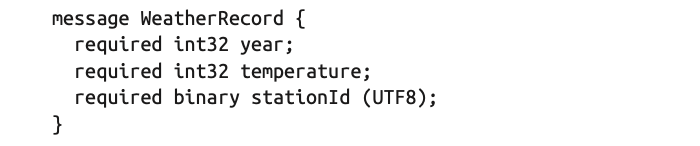
- 재밌는 것은 String 타입의 primitive 자료형이 없다. 대신 기본 자료형에 대한 해석 방식을 정의한 논리 자료형을 제공한다. 문자열은 UTF-8 어노테이션을 가진 binary 기본 자료형으로 표현된다.
- 리스트와 맵은 중첩된 repeated group로 표현된다.

- 중첩 인코딩
- 컬럼 기준 저장 방식에서 동일한 컬럼의 모든 값은 함께 저장된다.
2. Parquet 파일 포맷
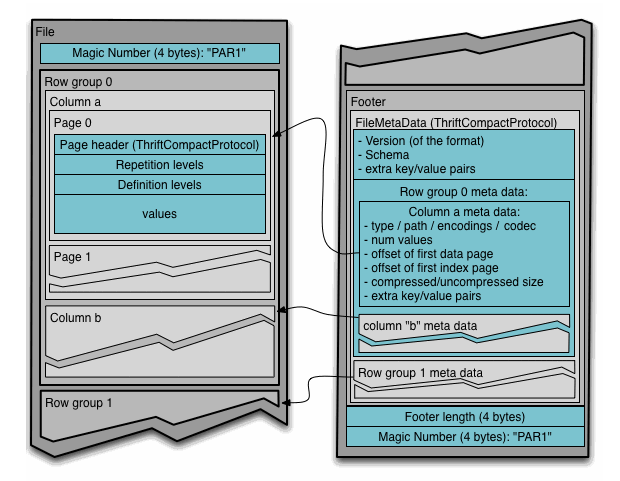
- Parquet 파일은 Header, 하나 이상의 블록, Footer 순으로 구성된다.
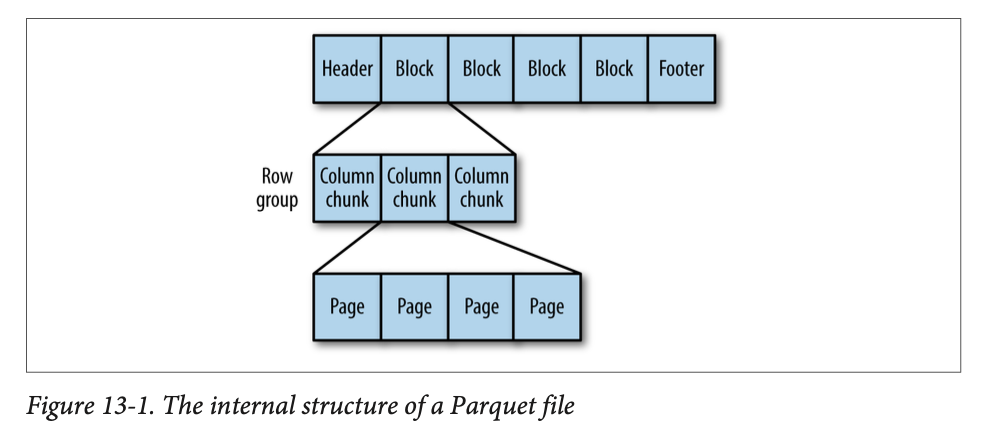
- Header에는 파케이 포맷임을 알려주는 PAR1만 있다. 모든 메타데이터는 Footer에 있다.
- Parquet는 Footer를 읽으면 블록의 위치를 알 수 있다. 따라서 파일 분할이 가능하고 병렬(MapReduce)로 처리할 수 있다.
- Parquet 파일의 각 블록에는 Row group을 저장한다. Row group은 행에 대한 열 데이터를 포함한 Column Chunk로 이루어져 있다. 각 Column Chunk의 데이터는 페이지에 기록된다.
3. 사용 예시
- VCNC에서 JSON 압축 로그를 Parquet로 바꿔 쓴 사례. 74%의 저장 용량 이득, 10~30배의 처리 성능 이득. 링크
- 이들이 원했던 기능은
- Dictionary encoding(String을 압축할 때 dictionary를 만들어서 압축하는 방식.)
- Column pruning(필요한 column만을 읽어들임)
- Predicate pushdown, row group skipping(필터를 저장소 레벨에서 적용하는 기법)
- 이들이 원했던 기능은
