[Tech Blog 번역] 미켈란젤로: 우버의 Machine Learning 플랫폼
우버 엔지니어링은 고객들에게 원활하면서 인상깊은 경험들을 제공할 수 있는 기술들을 발전시키는데 기여를 하고 있다. 우리는 이러한 비전을 충족시키기 위해서 AI와 머신러닝에 점차 많은 투자를 하고 있다. 우버에서는 이러한 기여를 '미켈란젤로'라고 부른다. 미켈란젤로는 내부의 ML 플랫폼으로, 머신러닝을 누구나 사용가능하게 하고 ride를 요청하는 것을 쉽게 하고자하는 비즈니스의 요구를 충족시키기 위해 AI를 점차 확대해 나가고 있다.
미켈란젤로는 내부 팀들이 원활하게 빌드, 배포, 그리고 우버의 규모에 맞는 머신러닝 솔루션을 구동가능하도록 한다. 그리고 이것은 머신러닝의 workflow를 처음부터 끝까지 커버하도록 설계되었다: 데이터 매니징, 학습, 평가, 그리고 모델의 배포와 예측, 예측의 모니터링까지를 포함한다. 시스템은 또한 전통적인 ML 모델들, 시간별 예측, 딥러닝또한 제공한다.
미켈란젤로는 우버에서 약 1년간 production use case들을 제 공하고 있으며 수십개의 팀 빌딩과 배포 모델과 함께 엔지니어들과 데이터 사이언티스트들을 위한 de-facto 시스템이 되어가고 있다. 실제로, 여러개의 우버 데이터 센터들에게 배포되었고, 특수한 하드웨어와 기업에서 가장 많이 사용되는 온랄인 서비스를 위한 예측까지 제공한다.
이 글에서는, 미켈란젤로를 소개하고, 제품에서의 실제 사용 케이스에 대해 논의하고 강력하면서 새로운 ML as a service시스템의 workflow에 대해서 살펴볼 것이다.
미켈란젤로 이면의 동기
미켈란젤로 이전에, 우리는 우버에서 운영에 관련해 사이즈와 스케일에 관련한 머신러닝 모델들의 배포와 빌딩에 관련된 수많은 어려움을 마주했었다. 데이터 과학자들이 (R, scikit-learn, 커스텀 알고리즘등) 등의 에측 모델들을 만들기 위해 여러종류의 다양한 도구들을 사용했던 반면, 개별 엔지니어링 팀들은 또한 프러덕션에서 이러한 모델을 사용하기위해 일회성 맞춤형 시스템을 만들어야 했다. 결과적으로 우버에서의 머신러닝의 영향은 적은 수의 데이터 과학자들과 엔지니어들이 대부분 사용하는 오픈 소스 도구들과 함께 짧은 시간 프레임 안에서만 만들 수 있는 정도로 제한되었다.
특히, 규모가 있는 예측데이터의 학습을 생성하고 관리하는데 필요한 재현가능한 파이프라인들을 안정적으로 빌드하고 통합하는 시스템이 없었다. 미켈란젤로 이전에 데이터 과학자의 데스크톱 머신에서의 크기보다 더 큰 모델을 학습하는 것이 불가능했다. 뿐만 아니라 한 실험을 다른 실험과 비교하는 쉬운 방법도 업었을 뿐더러 학습 실험에 대한 결과를 저장할 수 있는 표준 공간 또한 없었다. 더 중요한 것은, 프로덕션으로 모델을 배포할 수 있는 경로조차 없었다는 것이다. (대부분의 경우, 관련된 엔지니어링 팀이 그 프로젝트에 맞는 컨테이너를 직접 만들었어야 했다.) 그와 동시에 Scully et al에 의해 많은 ML 안티패턴에 대한 징후들도 보기 시작했다.
Michelangelo는 회사 전체의 사용자가 대규모로 머신 러닝 시스템을 쉽게 구축하고 운영 할 수 있도록 지원하는 엔드-투-엔드 시스템을 통해 팀 전체의 워크 플로와 도구를 표준화하여 이러한 차이를 해결하도록 설계되었다. 우리의 목표는 이러한 즉각적인 문제를 해결하는 것 뿐만 아니라, 비즈니스와 함께 성장하는 시스템을 만드는 것이다.
2015년 중반 미켈란젤로를 만들기 시작한 때에, 우리는 확장 가능한 모델 학습 및 프로덕션 서비스 컨테이너에 대한 배포와 관련된 문제를 해결하는 것으로 시작했다. 그 다음에는 feature 파이프라인을 공유하고 관리하는 더 나은 시스템을 구축하는 것에 집중했다. 최근에는 이 초점이 개발자의 생산성으로 옮겨갔다 - 아이디어에서 첫번째 프로덕션모델까지 빠르게 구축을 하는 방법과 빠른 iteration 방법들.
다음 섹션에서는, 미켈란젤로가 어떻게 우버에서 어떤 특정한 문제를 해결하기 위해 모델을 구축하고 배포했는지를 이해할 수 있도록 어플리케이션의 예시를 살펴볼 것이다. UberEATS에서의 특정한 유즈케이스에 대해 살펴볼 것이지만, 이 플랫폼은 회사에서 예측 유즈케이스의 다양성을 위해 수십개의 유사한 모델들을 관리하고 있다.
Use case: UberEATS 배달 예상 시간
UberEATS는 음식 배달 시간 예측, 랭킹 검색, 자동 완성 및 레스토랑 랭킹등을 포함하는 여러 모델들을 Michelangelo에서 구동하고 있다. 배달 시간 모델은 얼마나 음식이 준비하는데 시간이 걸리고, 각 배달 단계에서의 시간을 예측하는 모델이다.
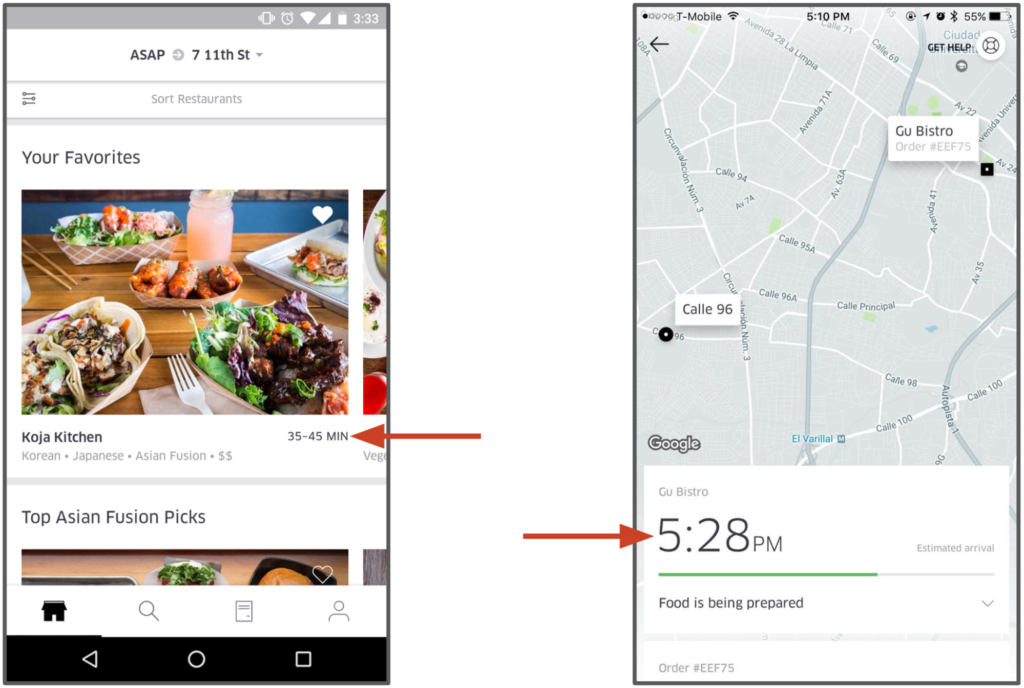
식사의 도착시간을 예착하는 것은 그리 간단하지 않다. UberEATS의 고객이 주문을 하면 그 주문은 레스토랑에게 전달된다. 레스토랑에서는 이 주문이 들어온 것을 알아야 하며 레스토랑이 얼마나 바쁜지, 그리고 요리의 난이도에 따라 이를 준비하는데 시간이 각각 다를 것이다. 요리가 다 준비될 때 쯤에는 Uber의 배달 파트너는 이 요리를 가지러 알림을 받는다. 그리고 배달 파트너는 레스토랑을 가야 하고, 주차할 곳을 찾고 요리를 가지러 들어가고, 다시 차에 와서, 고객의 위치로 이동하고 (경로와, 교통상황 그리고 여러가지 요인들이 있다.), 주차할 곳을 찾고 고객의 집에 도착해서 배달을 완료한다. 목표는 이러한 복잡한 여러 단계의 프로세스의 총 소요 시간을 예측하는 것이고 프로세스의 매 단계마다 이러한 배달 예측시간을 다시 계산해야 한다.
미켈란젤로의 플랫폼에서는, UberEATS의 데이터 과학자들이 이러한 end-to-end 배달 시간을 예측하기 위해 gradient boosted decision tree regression model을 사용한다. 이 모델의 주요 특징은 의뢰에서의 정보 (날짜의 시간, 배달 위치), 기록적인 특징 (지난 7일간 평균 음식 준비 시간), 그리고 실시간 계산된 featrue들 (지난 1시간동안 평균 음식 조리 시간)등이다. 모델들은 Uber의 데이터 센터와 미켈란젤로 전반적으로 컨테이너 형태로 배포가 되어 있고, UberEATS 마이크로서비스들의 네트워크 요청들에 의해 불러진다. 이러한 에측들은 UberEATS의 고객들에게 레스토랑으로부터 주문을 하기 전과 그들의 음식이 준비되고 배달되기에 앞서 보여진다.
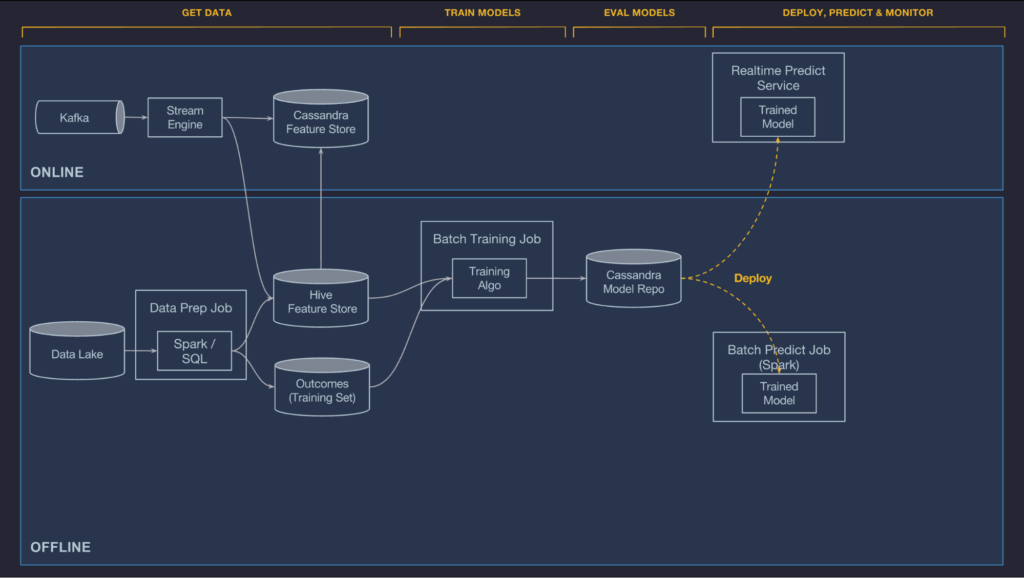
시스템 아키텍쳐
미켈란젤로는 내부에서 개발한 컴포넌트와 오픈소스시스템가 섞여서 이루어져있다. 주로 사용되는 오픈소스 컴포넌트로는 HDFS, Spark, Samza, Cassandra, MLLib, XGBoost, 그리고 Tensorflow등이 있다.우리는 주로 우리의 use case에 그 솔루션을 사용하는 것이 이상적이지 않음에도 불구하고 많이 발전되어있는 오픈소스를 사용하는 것을 선호한다.
미켈란젤로는 우버의 데이터 최상단 위에 만들어져, 인프라를 연산하고 모든 우버에서의 트랜잭션과 로그 데이터, 모든 우버의 서비스로부터 오는 메시지의 로그를 수집하는 Kafka broker, 스트리밍 연산 엔진인 Samza, Cassandra 클러스터 관리 그리고 우버의 내부 서비스 프로비저닝과 개발 툴들과 같은 데이터 호수를 제공한다.
다음 섹션에서는, 미켈란젤로의 기술적인 디테일을 설명하기 위해 UberEATS 의 ETD 모델을 케이스 스터디로써 이용해 시스템 레이어들을 살펴볼 것이다.
Machine learning workflow
같은 일반적인 workflow는 이러한 문제에 당면한 부분과 이를 포함하는 classfication과 regression, 뿐만 아니라 time series 예측등에 상관없이 거의 모든 machine leraning use case들에 걸쳐 존재한다.
workflow는 일반적으로 구현에 구애받지 않으며, 쉽게 새로운 알고리즘 타입 또는 프레임워크와 함께 확장 가능하다. 또한 온라인 또는 오프라인 (in-car모드, in-phone 모드) 와 같은 다른 deployment mode에 걸쳐서도 전반적으로 적용된다.
우리는 미켈란젤로를 특히 쉽게 확장가능하고, 안정성있으며, 복제가능하고, 사용하기 쉬우며 자동화된 도구로써 아래와 같이 6단계의 workflow로 설계했다:
- 데이터 관리
- 학습 모델
- 모델 평가
- 모델 배포
- 예측 실행
- 예측 관리
다음으로, 이 workflow에서 어떻게 미켈란젤로의 아키텍쳐가 각 단계를 가능하게 하는지 자세히 살펴볼 것이다.
데이터 관리
머신러닝에서 좋은 기능을 찾는 것은 가장 어려운 부분중 하나이다. 그리고 우리는 데이터 파이프라인을 관리하고 개발하는 것이 전형적으로 완전한 머신러닝 솔루션을 만드는데 가장 비용이 소모되는 조각들이라는 것을 깨달았다.
플랫폼은 기능과 학습을 위한 데이터 레이블을 생성하기 위한 데이터 파이프라인을 개발하기 위한 표준화된 도구를 제공해야 한다. 이러한 도구들은 기업의 데이터 호수 혹은 웨어하우스 그리고 기업의 온라인 데이터 제공 시스템과 깊은 integration이 이썽야 한다. 파이프라인들은 확장가능해야 하며, 효율적으로 동작해야 하며, 데이터 플로우와 데이터 퀄리티를 위해서 통합 감시가 필요하고, 온라인 오프라인 둘다 학습과 예측을 지원해야 한다. 이상적으로, 그들은 또한 튼튼한 가드 레일과 사용자에게 가장 적합한 practice(학습 시간과 예측 시간에서 동일한 데이터의 생성/준비의 사용이 쉽도록 보장하는 등) 를 채택하도록 독려해야 한다.
미켈란젤로에서 데이터 관리 컴포넌트는 온라인과 오프라인 파이프라인으로 나누어져 있다. 현재, 오프라인 파이프라인은 배치 모델 학습과 배치 예측 job이 작동하도록하는데 사용되고 있으며 온라인 파이프라인은 온라인, low latency prediction이 작동하도록 한다.
게다가 우리는 데이터 관리 레이어를 추가했다. 이는 팀에게 공유되고 발견되며, 머신러닝 관련 문제들에 관련된 curating set을 사용가능하도록 하는 feature store이다. 우리는 Uber에서 꽤나 많은 모델링 문제들이 동일한 혹은 비슷한 기능들을 사용한다는 것을 알아냈고, 그것은 그들만의 프로젝트 그리고 서로 다른 조직의 팀 사이에 기능들을 공유할 수 있도록 하는 꽤나 중요한 가치들이 있다.
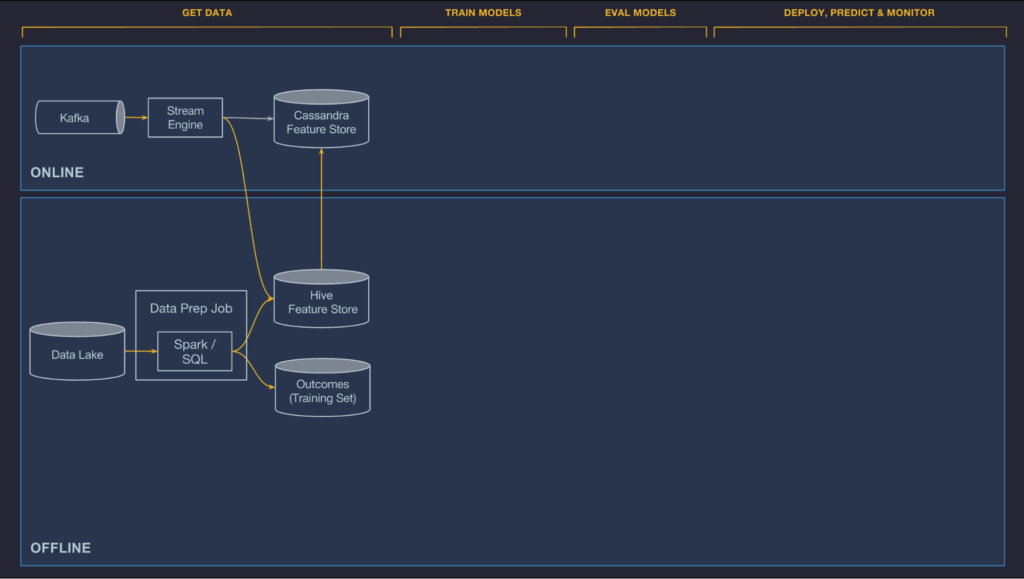
Offline
Uber의 트랜잭션 가능하면서 로그로 남는 데이터는 HDFS data lake에 흘러들어가고 Spark와 Hive SQL compute jobs를 통해 쉽게 접근이 가능하다. 우리는 컨테이너와 주기적인 job들을 스케줄링하는 것을 제공하는데, 이 때 이 job들은 어떤 특정한 feature들을 계산하는 역할을 한다. 이는 private 한 프로젝트이거나 팀간에 feature store로 publish 될 수도 있는데, 그러는 동안에는 batch job들이 스케줄로 돌아가거나 파이프라인에서의 회귀를 빠르게 감지하기 위한 데이터 퀄리티 감시 tool로 통합되기도 한다.
Online
온라인으로 배포되는 모델은 HDFS에 저장되어 있는 데이터에 접근할 수 없다. 그리고 이것은 종종 어떤 feature 들을 더 나은 방법으로 직접적으로 온라인 데이터베이스에서 Uber의 production service로 계산하는 것이 어렵다. (예를 들어, UberEATS의 주문 서비스에 레스토랑 간 특정 시간의 평균 식사 시간을 query 하는 것은 불가능하다.) 대신, 예측된 시간에 낮은 latency로 읽을 수 있도록 미리 계산되어 Cassandra에 저장하는 등, 온라인 모델들을 위한 기능들을 가능하게 한다.
우리는 이러한 온라인에서 제공하는 feature 들을 계산하기 위한 두가지 옵션을 제공한다 : batch precompute 와 near-real-time 계산이다. 설명은 아래와 같다:
-
Batch precompute : 연산을 위한 첫번째 옵션은 주기적으로 HDFS에서 Cassandra로 bulk precomputing을 실행하고 historical feature들을 불러오는 것이다. 이것은 단순하고 효율적이며 일반적으로 매 몇시간마다 혹은 하루에 한번정도 업데이트 되는 historical feature들에게는 잘 작동한다. 이 시스템은 동일한 데이터와 배치 파이프라인이 training과 serving 둘다에 사용된다는 것을 보장한다. UberEATS는 '지난 7일간 레스토랑의 평균 식사 준비시간'과 같은 feature들을 시스템에 사용한다.
-
Near-real-time compute: 두번째 옵션은 Kafka에 관련 metric들을 publish 하고 낮은 지연율의 aggregate feature들을 Samza 기반의 streaming compute jobs들을 실행하는 것이다. 이러한 특징들은 Cassandra에 곧바로 쓰여지며 HDFS에 미래의 학습 job으로 log가 남는다. 배치 시스템과 비슷하게, near-real-time 연산은 동일한 데이터가 학습되고 serving 되는것을 보장한다. Cold start를 피하기 위해서 우리는 데이터를 "backfill"하기 위한 tool을 제공하면서 historical logs에 거스르는 batch job을 실행함으로써 training data를 생성한다. UberEATS는 이러한 near-realtime 파이프라인을 '레스토랑의 지난 1시간동안의 평균 식사 준비 시간'과 같은 feature들을 연산하기 위해 사용한다.
Shared feature store
우리는 중앙화된 feature store를 하나 만드는데서 굉장히 큰 가치를 찾았다. 이는 Uber에서의 팀들이 그들의 팀원들 혹은 다른 사람들과 사용하기 위한 표준 feature들을 생성하고 관리한다는 것이다. 높은 관점에서 보면 이것은 두가지를 완수한다:
-
이것은 그들이 만든 기능들을 쉽게 공유된 feature store에 추가할 수 있게 해준다. 아주 조그만 양의 metadata (저자, 설명, SLA 등)을 가장 상단에 표기해 이것이 private한 용도인지 특정 프로젝트의 사용용도인지 추가하는 것만으로도 가능하다.
-
한번 Feature들이 Feature Store 안에 있으면 그것들은 온라인 또는 오프라인에서 아주 쉽게 사용된다. 모델 configuration 안에 있는 feature의 단순한 CName (Canonical name)을 참고함으로써 가능하다. 이러한 정보와 함께 시스템은 모델의 학습, 배치 예측 그리고 온라인 예측을 위한 Cassandra로부터 올바른 데이터를 가지고 오는 것 등의 올바른 HDFS data set에 접근하는 것을 다룬다.
지금 현재, 머신러닝 프로젝트를 가속화하기 위해 대략 10,000개의 feature들이 feature store에 위치하고 있으며 회사의 모든 팀들이 동시에 새로운 것들을 추가하고 있다. Feature Store안의 Feature들은 매일 자동으로 계산되고 업데이트 된다.
후에는, Feature Store를 자동으로 훑어 주어진 예측 문제를 해결할 수 있는 가장 유용하면서 중요한 feature들을 규정하는 자동화 시스템을 만들어볼려고 하고 있다.
Domain specific language feature selection and transformation
종종 데이터 파이프라인에 의해 생성된 feature 혹은 client 서비스로 부터 보내진 feature등은 모델에 적합한 포맷이 아닐수 있으며 채워져야하는 누락된 정보가 있을 수 있다. 게다가, 모델은 주어진 feature의 subset만을 필요로 할 수도 있다. 여러한 케이스에서, 모델을 hour-of-day 혹은 day-of-week과같은 timestamp로 변형시키는 것은 계절별 패턴을 발견하는데 유용할 수 있다. 다른 케이스에서는 feature 값들이 normalized 될 필요가 있다.(평균값을 빼고 standard deviation으로 나눈 값)
이 issue들을 해결하기 위해, 우리는 예측시간과 학습 모델에 보내지는 feature들을 모델러들이 select, transform, combine 할 수 있는 DSL (Domain specific language)을 만들었다. DSL은 Scala의 sub-set으로 구현되었다. 이것은 일반적으로 사용되는 기능들의 완전한 set와 함께 있는 순수한 기능적 언어이다. DSL과 함께, 우리는 customer team이 그들만의 user-defined function들을 추가할 수 있는 기능을 제공하였다. 그리고 현재의 문맥(오프라인에서의 데이터 파이프라인 또는 온라인 모델에서의 클라이언트로 부터 온 request) 또는 feature store로부터 feature value들을 가져올 수 있는 accessor function도 있다.
DSL 표현이 모델 config의 일부라는 것과 같은 표현들이 학습시관과 예측시간에 적용된다는 점은 매우 중요하다. 이 때, DSL expression들은 같은 최종 feature set들이 생성되고 두가지 케이스의 경우에 속하는 모델에 보내진다는 것을 보장해주는데 도움이 된다.
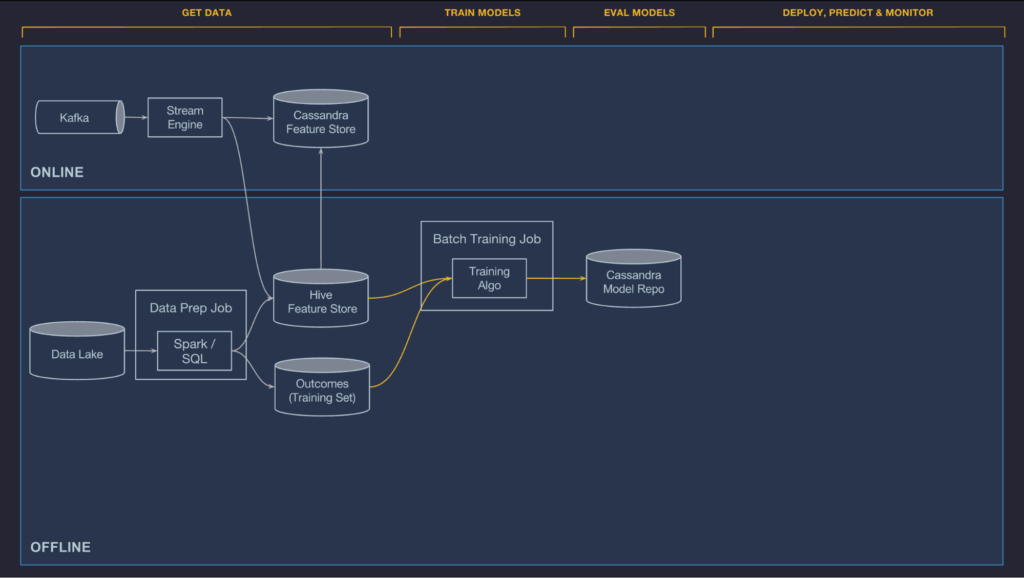
학습 모델
우리는 현재 오프라인의, 큰 스케일의 분산된 decision tree의 학습, 선형적이면서 logistic한 모델, unsupervised model, time series 모델, 그리고 딥 뉴럴 네트워크등을 지원하고 있다. 우리는 주기적으로 사용자의 요구에 따라, 그리고 Uber AI Labs 또는 내부 연구자들에 의해 개발되는 즉시 새로운 알고리즘을 추가하고 있다. 게다가 우리는 사용자들로 하여금 그들만의 커스텀 학습, 평가, 배포하는 코드등을 제공함으로써 그들만의 모델 타입들을 추가하도록 하고 있다. 분산 모델의 학습 시스템은 수십억개의 샘플을 빠른 iteration으로 조그만 데이더 셋으로 만들어 다룬다.
모델의 구성은 모델의 타입, 하이퍼-파라미터(모델링시 사용자가 직접 설정해주는 값), 데이터 소스 참고 그리고 feature DSL표현, 그리고 계산 리소스에 필요한 요구사항 (machine의 수, 메모리는 얼마나 필요한지, GPU를 사용하는지의 여부 등)등을 명시한다. 이것은 YARN 또는 Mesos cluster에서 동작하는 학습 job을 구성하는데 이용된다.
모델이 학습되고 나면, 성능 metrics (ROC Curve 혹은 PR Curve)들을 연산되고 모델 평가 리포트에 병합된다. 학습의 끝에는 구성의 원본, 학습된 파라미터, 그리고 평가 리포트가 우리의 모델 repository에 분석과 배포를 위해 저장된다.
단일 모델을 학습하기 위해서는, Michelangelo는 partitioned 모델을 포함한 모든 모델타입들을 위한 하이퍼 파라미터 검색을 지원한다. Partitioned 모델과 함께, 우리는 자동적으로 사용자로부터 configuration에 기반하여 학습 데이터를 구분하고 한 parition당 한 모델을 학습 시키고 필요할 때 그 parent 모델로 돌아간다.(도시당 한 모델을 학습하고 정확히 city-level 모델이 학습될 수 없을 때에 country-level로 돌아가는 것과 같다).
학습 job은 Web UI 또는 API를 통해 구성되고 관리된다. 종종 Jupyter Notebook에 관리되기도 한다. 많은 팀들은 이 API와 workflow tool들을 이용해 모델들의 주기적인 재학습을 스케줄링 한다.
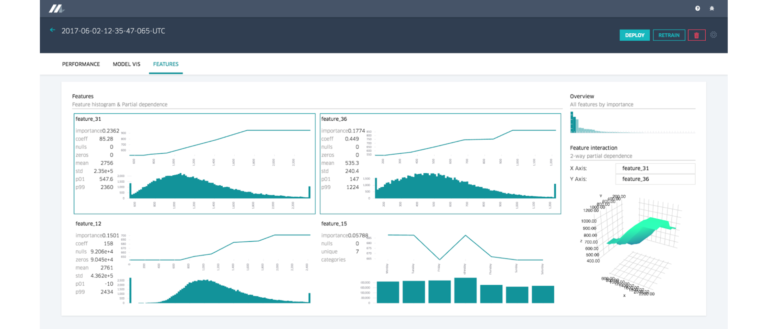
Evaluate Models
모델들은 종종 체계적인 exploration process의 부분으로 feature와 알고리즘, 그리고 hyper-parameter들을을 확인하기 위해 학습된다. 그리고 이것들은 그들의 문제를 위한 가장 적합한 모델을 생성한다. 주어진 use case을 위한 이상적인 모델에 도달하기 전에는, 어떤 기준에 적합한 수백개의 모델을 학습하는 것은 일반적이지 않다. 궁극적으로 production에서 사용되지 않을 것 이라면, 이러한 모델의 성능은 엔지니어를 가장 좋은 성능을 내는 모델을 만드는 모델의 config로 이끈다. 이러한 학습 모델을 끝까지 트랙킹하고 (누가 학습시켰는지, 언제, 무슨 데이터 셋을, 무슨 hyper-parameter로 등)그것들을 평가하고, 서로 비교하는 것은 전형적으로 많은 모델에서 여러가지 큰 도전으로써 존재하고 또한 플랫폼에 많은 가치들을 더할 수 있는 현재의 기회로써도 생각할 수 있다.
미켈란젤로에서 학습된 모든 모델에 대해서, 우리는Cassandra 내 우리의 모델 repository에 버전별 object를 저장한다.
- 누가 학습 시켰는가
- 학습 job의 시작과 종료시간
- Full Model Configuration (사용된 feature, hyper-paramter 값 등)
- 학습과 테스트 데이터 셋의 참조
- 각 feature의 분포와 상대적인 중요성
- 모델 정확성 metrics
- 각 모델 타입의 표준 chart와 그래프 (ROC curve, PR curve, binary classifier를 위한 confusion matrix)
- 모델의 완전히 학습된 파라미터
- 모델 시각화를 위한 summary statistics
정보는 Web UI와 프로그램적으로 API를 통해서 쉽게 접근이 가능하며 각 모델의 상세정보를 확인하는 것과 하나의 모델과 다른 모델의 것들을 비교하는 것도 가능하다.
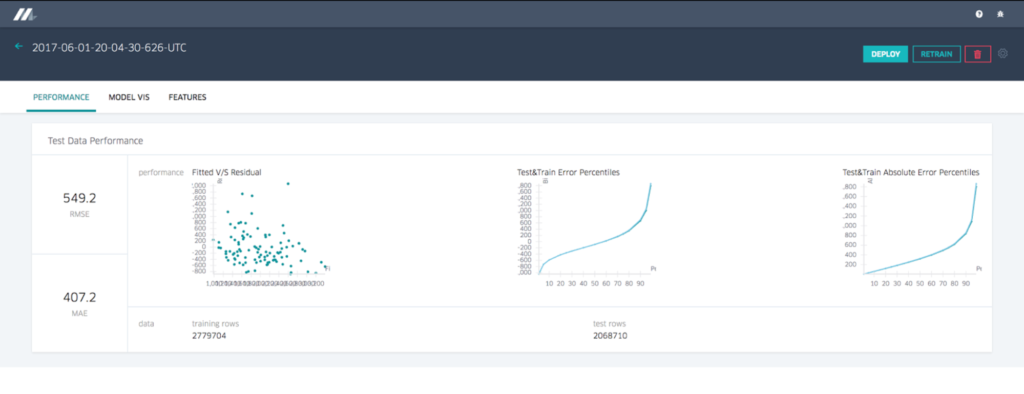
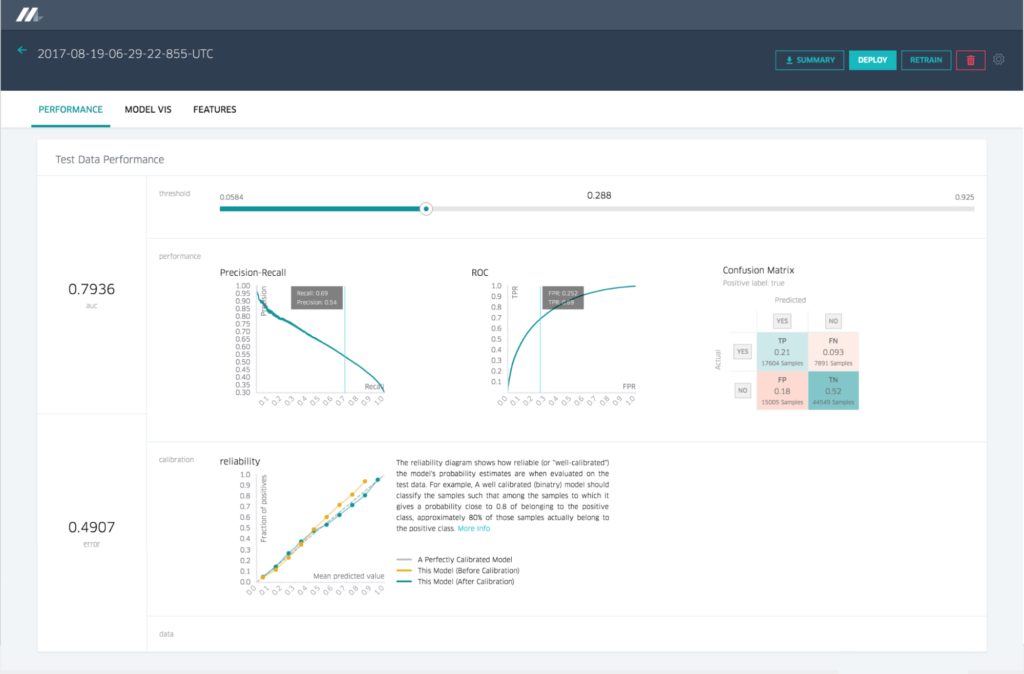
모델 정확도 리포트
회귀 모델을 위한 모델 정확도 리포트는 차트와 표준 정확도 metric을 보여준다. 아래 Figures4와 5에서는 분류모델이 각각 다른 set를 보여준다.
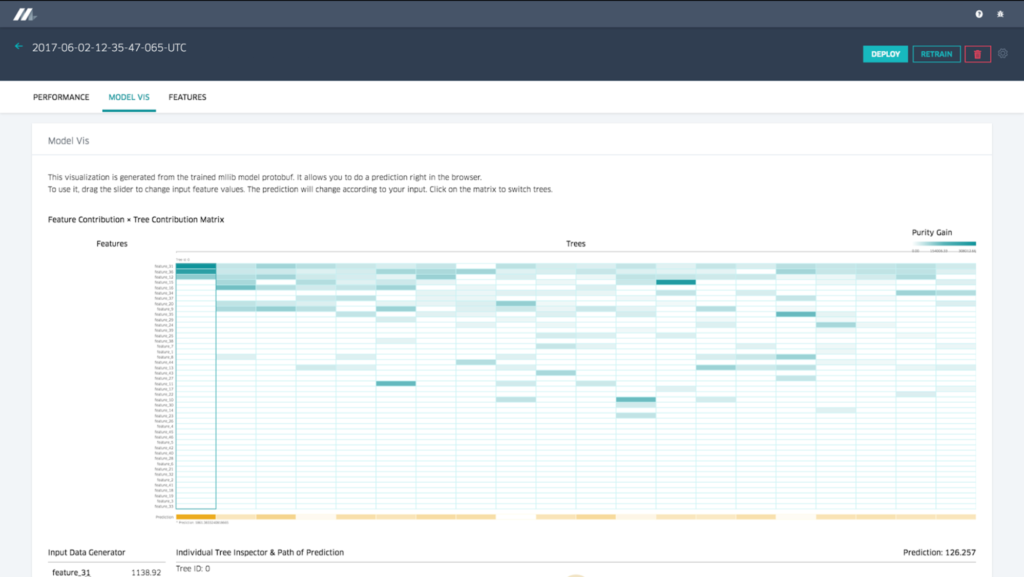
Decision tree 시각화
중요한 모델 타입으로는, 우리는 모델러들이 왜 모델이 이렇게 동작해야 하는지의 이해와 필요하면 디버그하는 것을 도와주는 것들을 정교한 시각화 도구와 함께 제공한다. 결정 트리 모델의 경우, 우리는 사용자들이 각각의 개별 트리를 살펴볼 수 있도록 하고, 그것을 통해 전체적인 모델, 그것들의 split points, 특정 트리에 대한 각각의 중요한 feature, 그리고 여러 다른 변수들간의 데이터 분포등의 상대적인 중요성을 확인할 수 있다. 사용자는 feature value들을 specify할 수 있으며 시각화는 decision tree, 트리당 prediction, 모델 전반적인 prediction등의 trigger path를 확인할 수 있다.
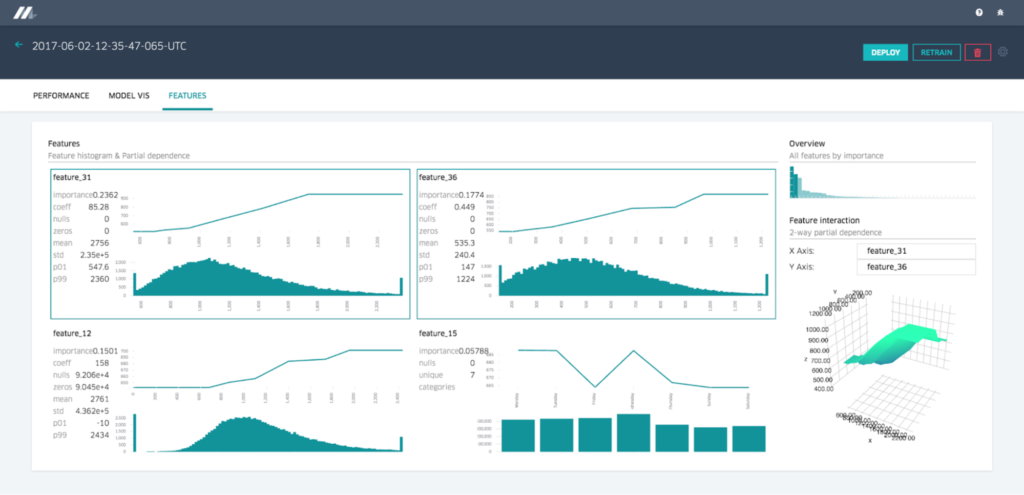
Feature Report
미켈란젤로는 partial dependence plots 와 distubution diagram과 함께 각 feature들이 모델에 어떻게 중요한지를 보여주는 feature report를 제공한다. 두 개의 feature들을 선택함으로써 사용자는 two-way partial dependence diagram과 같이 feature interaction들을 이해할 수 있다.
Deploy Models
미켈란젤로는 UI 혹은 API를 통해 모델 배포 관리를 위한 end-to-end support를 제공하고, 모델이 배포될 수 있는 세 개의 모드가 존재한다:
-
Offline deployment: 모델은 offline container로 배포되며 배치 예측 혹은 요구에 따라 반복되는 스케줄을 생성한다.
-
Online deployment: 모델은 온라인 예측 service cluster에 배포된다. (일반적으로 로드 밸런서 뒤에 수백개의 machines들을 포함하고 있다.), 그리고 클라이언트는 network RPC call등의 개별 혹은 batched prediction request를 보낼 수 있다.
-
Library deployment: 우리는 다른 서비스에서 라이브러리로 embedded 된 컨테이너로 배포되는 보델을 런치하려고 하고 이는 Java API를 통해 불러진다.
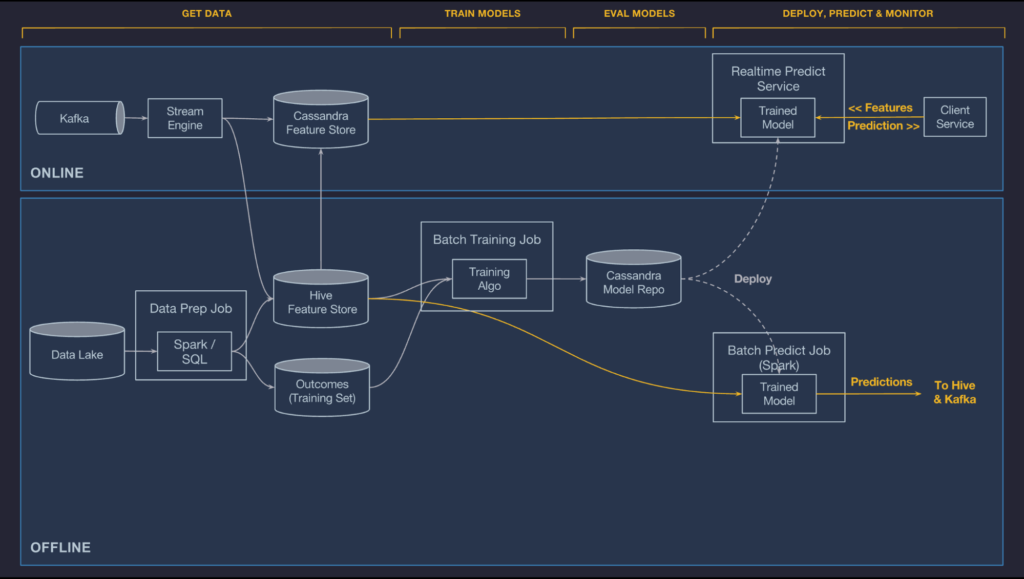
모든 케이스에서, 요구되는 모델 artifacts (메타데이터 파일, 모델 파라미터 파일, 그리고 컴파일된 DSL expression) 들은 Zip archive로 포장되고 복사되어 관련있는 Uber의 데이터 센터너머의 host로 표준 code 배포 인프라를 이용해 복사된다. 예측 컨테이너느 자동적으로 디스크로부터 새로운 모델을 불러오고 prediction request를 다루기 시작한다.
많은 팀들은 모델을 주기적으로 재학습 시키고 미켈란젤로 API를 통해 배포하는 automation script를 가지고 있다. UberEATS의 time 모델의 경우, 학습과 배포는 Web UI를 통해 데이터 과학자와 엔지니어에 의해 수동적으로 트리거 된다.
Make predictions
한 번 모델이 serving container에 의해 배포되고 로드되면, 그들은 client service로 부터 직접 혹은 데이터 파이프 라인으로 부터 불러와진 feature data에 기반하여 예상값을 만들어내곤한다. 날 것의 feature 들은 Feature Store로 부터 부가적인 feature들을 fetch하거나 raw feature들을 변경할 수 있는 compiled DSL expression들을 통과한다. 제일 마지막의 feature vector는 형성되고 scoring을 위해 모델을 통과한다. offline model의 경우, 예상값들은 아래 그림 처럼, downstream bach job 혹은 sql-based query tool에 의해 직접 사용자에게 접근될 수 있도록 Hive에 다시 기록된다.
Referencing models
한 모델 이상이 현재 서빙되고 있는 컨테이너에 의해 동시에 배포될 수 있다. 이것은 오래된 모델에서 새로운 모델의 안전한 전환을 가능하게하고 side-by-side A/B 테스팅또한 가능하게 한다. 배포가 되는 시점에, 모델은 각각의 UUID와 alias에 의해 구별되고 이 때 이 alias는 배포중에 명시된다. 온라인 모델의 경우, 클라이언트는 모델의 UUID 혹은 모델의 태그를 따라 feature vector를 전송한다 : tag의 경우, 컨테이너는 그 태그에 배포되었던 가장 최근의 모델을 이요해 예측치를 생성해낸다. 배치 모델의 경우, 모든 배포된 모델은 각 배치 데이터 셋들의 점수를 매기고 예측 기록은 소비자가 적절하게 필터링할 수 있도록 모델의 UUID 와 optional tag를 포함한다.
만약 오래된 모델을 새로운 모델로 교체해 배포할 때 두 모델 다 동일한 시그니쳐(set of feature 가 동일한 경우)를 가지고 있는 경우, 사용자는 새 모델을 오래된 모델의 태그와 동일한 것으로 배포하고 컨테이너는 새로운 모델을 즉시 시작할 것이다. 이것은 사용자로 하여금 그들의 client code 변경 없이 새로운 모델을 배포할 수 있도록 한다. 사용자들은 또한 그들의 UUID만을 가지고 새로운 모델을 배포할 수 있다. 그리고 클라이언트 혹은 중간 서비스의 트래픽을 예전 모델에서 새로운것으로 점차 증가시키기 위해 config를 변경할 수도 있다.
A/B 모델 테스팅의 경우, 사용자는 단순히 UUID 혹은 태그를 통해 경쟁 모델을 배포할 수 있으며 그리고 Uber의 실험적인 프레임워크를 각 모델이 일정량의 트래픽을 보내게끔 하면서 사용할 수 있다.
Scale and latency
머신 러닝 모델은 stateless이고 아무것도 공유하지 않으므로, 온라인과 오프라인 서빙 모델에서 그 모델들을 확장하기는 매우 쉽다. 온라인 모델의 경우, 우리는 단순히 예측 서비스 클러스터에 host들을 추가할 수 있으며 로드밸런서가 load를 분산시키게 하는 것도 가능하다. 오프라인 예측의 경우, 더 많은 Spack executors를 추가할 수 있고, Spark가 그 선형성을 관리할 수 있다.
온라인 서빙의 latency는 모델타입과 복잡도에 의존하고 있으며 모델이 Cassandra feature store를 필요로 하는지 아닌지에 따라도 의존성이 있다. Cassandra로 부터 feature이 필요하지 않은 모델의 경우, 우리는 일반적으로 5ms 보다 적은 p95 latency를 볼 수 있고, 필요한 경우는 10ms 보다 작은 P95 latency를 확인할 수 있다. 현재 가장 높은 트래픽 모델의 경우 초당 250,000예측을 제공하고 있다.
Monitor predictions
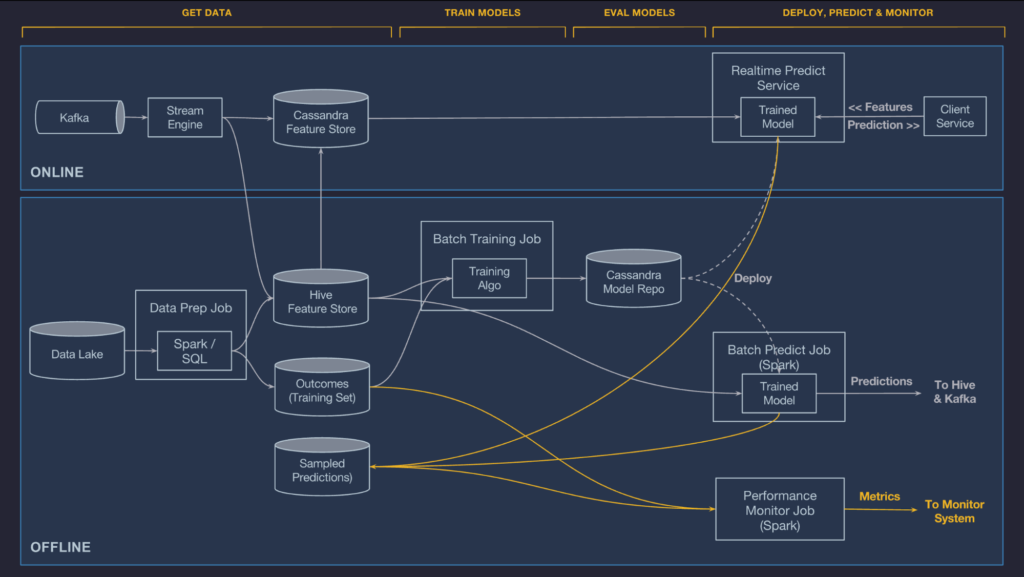
모델이 학습되고 평가되고나면, 이전 데이터는 언제든지 사용된다. 모델이 나중에도 잘 작동할거라는 것을 확신하기 위해, 데이터 파이프라인이 정확한 데이터를 꾸준히 보내고 있는지, 그리고 실제 프로덕션 환경에서 모델이 더이상 정확하지 않을 때 변화가 없도록하는지 등을 보장하기 위해 그 예측을 계속 모니터링하는 것은 중요하다.
이 문제를 해결하기 위해, 미켈란젤로는 자동으로 로그를 남기고 원하면 예측값의 비율을 잡아 나중에 데이터 파이프라인에 의해 생성된 결과값과 병합시키기도 한다. 이러한 정보와 함께, 우리는 실시간으로 모델 정확도의 측정값을 생성할 수 있다. Regression model의 경우, 우리는 R-squared/coefficient of determination, RMSLE, RMSE, mean absolute error metrics등을 우버의 시간 연속 관리 시스템에 배포하여 사용자가 계속해서 차트를 분석하고 쓰레숄드 경고를 세팅할 수 있도록 한다.
Building on the Michelangelo platform
다음달에는, 전체적인 우버의 비즈니스와 customer team의 성장을 지원하기위해 현재의 시스템을 확대하고 단단하게 다지는 계획을 하고 있다. 플랫폼 레이어가 성장할 수록, 우리는 더 높은 레벨의 tool과 서비스에 투자할 것이고 비즈니스의 니즈에 더 나은 지원과 머신러닝의 민주화를 기대할 수 있을 것이다:
- AutoML: 자동으로 모델 config (알고리즘, feature set, hyper-parameter 값 등)를 발견하고 검색하는 시스템이 될 것이다. 그리고 이는 주어진 모델의 문제에 가장 적합한 모델을 찾아낼 것이다. 시스템은 또한 자동으로 모델에 전원을 공급하기 위해 label과 feature을 생성하는 데이터 파이프라인을 빌드할 것이다. 우리는 이미 Fetaure Store을 통해 큰 조각을 해결했다. (온라인, 오프라인의 데이터 파이프라인, hyper-parameter search feature들의 통합). 우리는 AutoML을 통해 이러한 데이터 과학 업무를 가속화 할 것이다. 시스템은 데이터 과학자들이 레이블의 세트를 구체화하고 목표한 function을 구체화 가능하게 하며 그리고나서 문제에 가장 적합한 모델을 찾기 위해 가장 안전한 Uber의 데이터를 사용할 것이다. 목표는 그들의 일을 더욱 쉽게 ㅏㅁㄴ드는 스마트한 도구를 통해 데이터 과학자들의 생산성을 극대화하는것이다.
