최근 LLM의 성공은 텍스트뿐 아니라 다양한 도메인으로 확장되고 있다. 이번에 소개할 논문은 Amazon에서 발표한 Chronos (Time Series Foundation Models with Pretrained Transformers) 로, 이전에 리뷰한 PAPAGEI 논문에서 Baseline 모델로 쓰였다. Chronos는 시계열 데이터를 마치 텍스트처럼 다루어 학습하는 모델로, 기존의 ARIMA, DeepAR 같은 전통적 모델들을 크게 뛰어넘는 성능을 보여주었다. Chronos는 LLM 기반 pretrained time series forcasting model이지만, 시계열 예측 뿐만 아니라 representation learning에서도 좋은 성능을 보여주었다.
Chronos의 핵심 아이디어
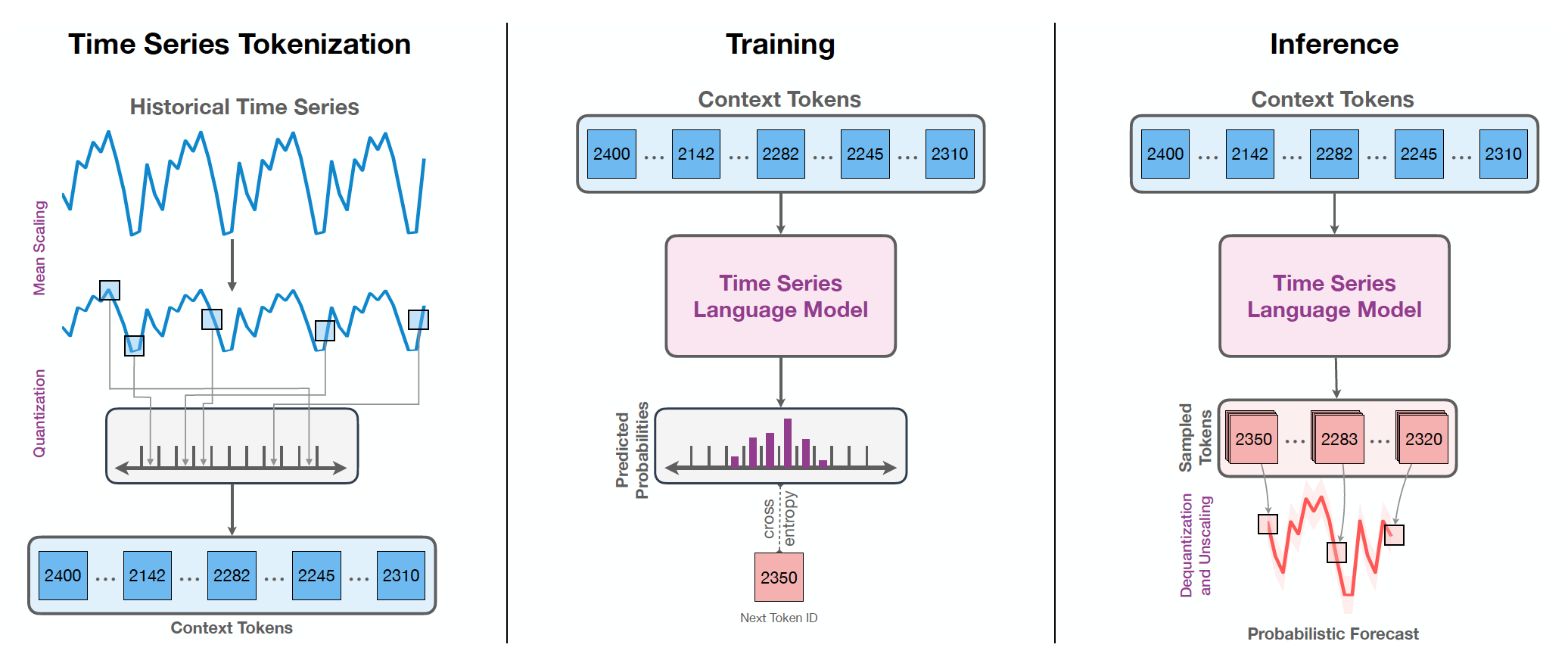
Chronos의 핵심은 시계열 데이터를 토큰(token) 시퀀스로 변환한 뒤, 이를 언어 모델과 같은 Transformer 아키텍처로 학습하는 것.
1. 정규화 & 양자화 (Scaling & Quantization)
- 연속적인 시계열 값을 일정한 구간으로 잘라 불연속적인 토큰으로 바꿈
- 이 과정을 통해 시계열 → 언어 모델이 처리할 수 있는 시퀀스로 변환
2. 언어 모델 학습 방식 차용
- next token을 예측하는 Autoregressive 과정으로 학습
- regression via classification
- 손실 함수는 Cross Entropy Loss를 사용하며, 이는 정답 토큰(one-hot 분포)과 모델의 예측 확률 분포 사이의 차이를 최소화하는 방식
3. GP Prior & Synthetic Data
- 실제 데이터만으로는 다양한 패턴을 학습하기 어렵기 때문에, Gaussian Process(GP) 기반 합성 데이터(KernelSynth)를 생성하여 사전학습에 활용
- 이를 통해 모델이 더 다양한 주기성과 추세(trend)를 배울 수 있음.
Time Series Tokenization
1. 정규화 (Scaling)
- 시계열의 절대 단위나 단위별 차이를 줄이기 위해 mean scaling 또는 z-score scaling 적용
- mean scaling의 경우 0을 그대로 0으로 만들어 주기 때문에 semantically important (zero sales, zero solar energy 등)한 데이터셋에 적합하다. 논문에서는 mean scaling을 사용하였다.
- Standard Scaling:
- Mean Scaling:
2. 양자화 (Quantization)
- 정규화된 값을 구간으로 나누어 정수 인덱스를 생성
- 이 과정은 시계열을 단어처럼 다룰 수 있게 만들어 줌
- 각각의 bin은 uniformly-spaced 되거나 distribution에 따라 동일한 개수의 데이터가 bin안에 들어가도록 할 수 있는데, downstream task의 distribution을 모르기 때문에 본 논문에서는 uniformly-spaced bin을 사용하였다.
3. Objective Function
- Transformer에 과거 context 길이 C를 입력
- 다음 token에 대한 확률 분포 예측
- 손실 함수는 Cross entropy (regression via classification)
- Autoregressive 방식으로 한 스텝씩 롤아웃 (예측 후 입력에 다시 포함)
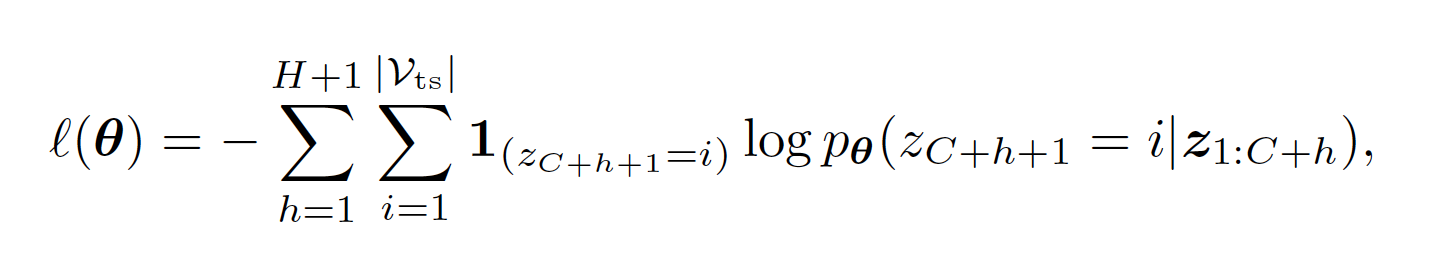
Data Augmentation
1. TSMixup: Time Series Mixup
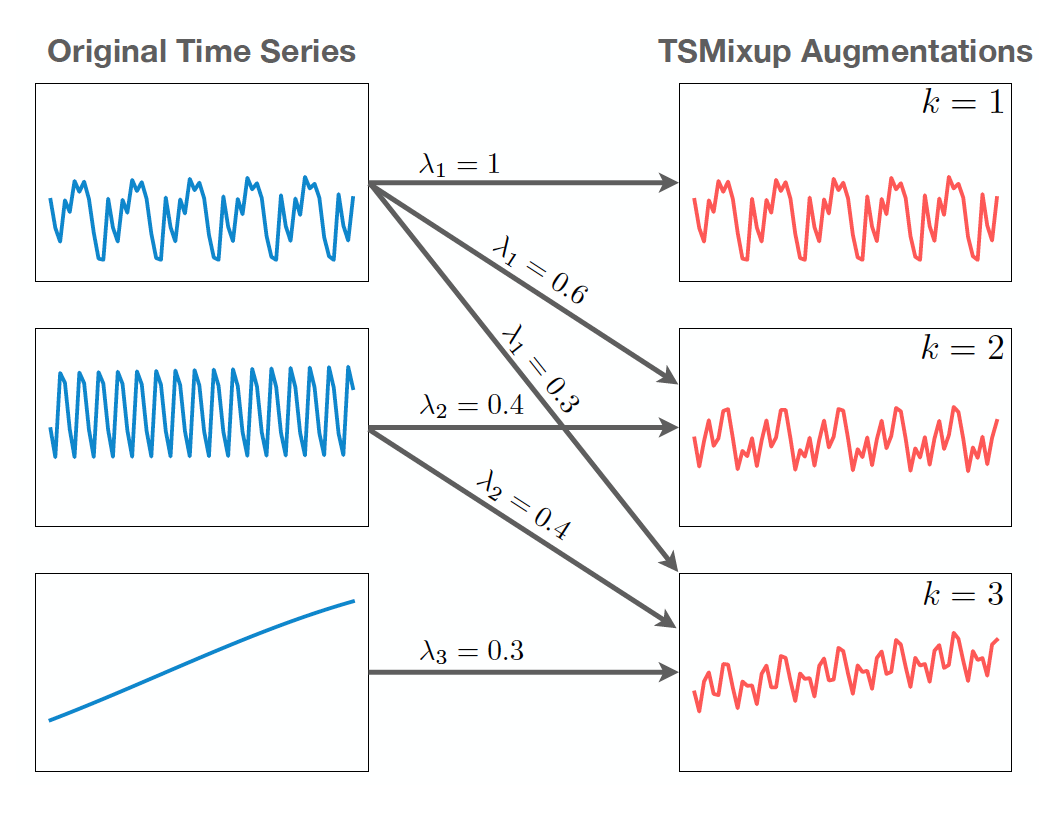
- 특정 랜덤 길이의 time series를 training set에서 랜덤하게 추출한 다음, 그들의 convex combination을 하여 Augmentation을 만들어 낸다.
- 위 그림은 각각 1개, 2개, 3개의 신호를 합쳐서 augmentation을 만든 신호를 보여주고 있다.
2. KernelSynth: Synthetic Data Generation using Gaussian Processes
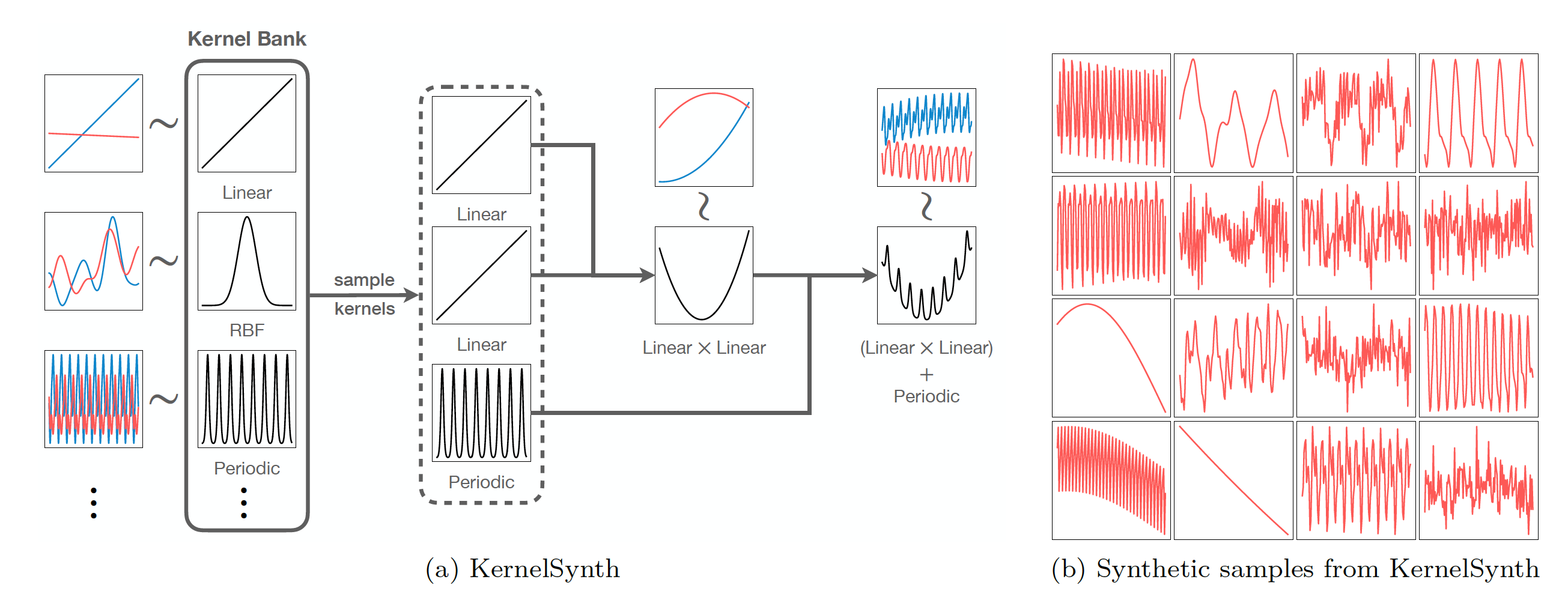
- Gaussian Processes는 확률 분포가 걸려있는 함수들의 집합이라고 생각하면 된다.
- 보통 우리는 확률 변수 (random variable)이 어떤 분포를 따른다고 하는데, GP에서는 하나의 함수 전체가 확률 분포를 따른다고 가정하는 것.
- : 평균 함수 (보통 으로 둠)
- : 커널(공분산 함수), 두 시점 사이의 유사도를 정의
- 즉 GP는 함수가 어떤 모양일지에 대한 분포이다.
- GP에서 샘플링을 하면, 랜덤한 곡선이 튀어나오는데, 이들은 커널의 특성에 따라 달라질 수 있음.
- 미리 다양한 Kernel이 있는 Kernel Bank를 정의해두고, 여기에서 샘플링 한 곡선들을 더하거나 곱해서 Synthetic Sample을 만들어낼 수 있다.
- Chronos의 목표는 하나의 데이터셋에 특화된 모델이 아니라, 가능한 많은 종류의 시계열 데이터를 만들어야 zero-shot에 더 높은 성능을 달성할 수 있기 때문.
Results
1. 평가 지표
(1) WQL (Weighted Quantile Loss)
- Chronos는 확률적 예측 (probabilistic forecasting)-각 bin이 정답일 확률을 softmax로 출력-을 하기 때문에 단순히 “예측값이 맞았냐/틀렸냐”가 아니라 예측 분포가 얼마나 잘 calibration 되었는지를 평가해야 함.
- 이를 위해 Quantile Loss (Pinball Loss)를 사용하고, 여러 quantile을 합친 것이 WQL입니다.
계산 방법
- bin별 확률 분포(softmax)를 출력.
- 이 분포에서 누적 분포(CDF)를 생성 → quantile 지점을 뽑을 수 있음.
- 그 다음 실제 값 y와 비교하여 quantile loss 계산. 실제값 가 quantile 예측보다 크면 만큼, 작으면 만큼 가중된 절대 오차를 계산해서 더해준 다음, WQL을 계산할 수 있음.
(2) MASE (Mean Absolute Scaled Error)
- MAE, RMSE와 같은 지표는 시계열의 단위 크기에 영향을 받아 서로 다른 데이터셋을 비교하기 어렵다. (예: 전력 수요 vs. 환자 심박 수)
- MASE는 단위에 독립적이므로, 여러 시계열이나 도메인을 공정하게 비교할 수 있음.
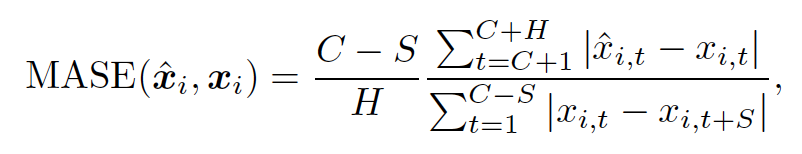
- 분자 = 모델의 평균 절대 오차 (MAE)
- 분모 = Naiive forcast의 평균 절대 오차
- Naiive forcast: 직전 시즌의 값 그대로 예측하는 방식. 계절성이 있다면, S는 계절 주기를 의미한다. (예: 일별 데이터에서 주간 계절성이 있으면 S=7)
- : context length
- : prediction horizon
- : seasonality parameter
해석
- : 모델 성능이 나이브 방법과 동일
- : 모델이 나이브보다 낫다
- : 모델이 나이브보다 못하다.
- 즉, 내 모델이 단순 Naive 예측보다 몇 배 더 좋은가를 직관적으로 보여준다.
2. Benchmark 성능
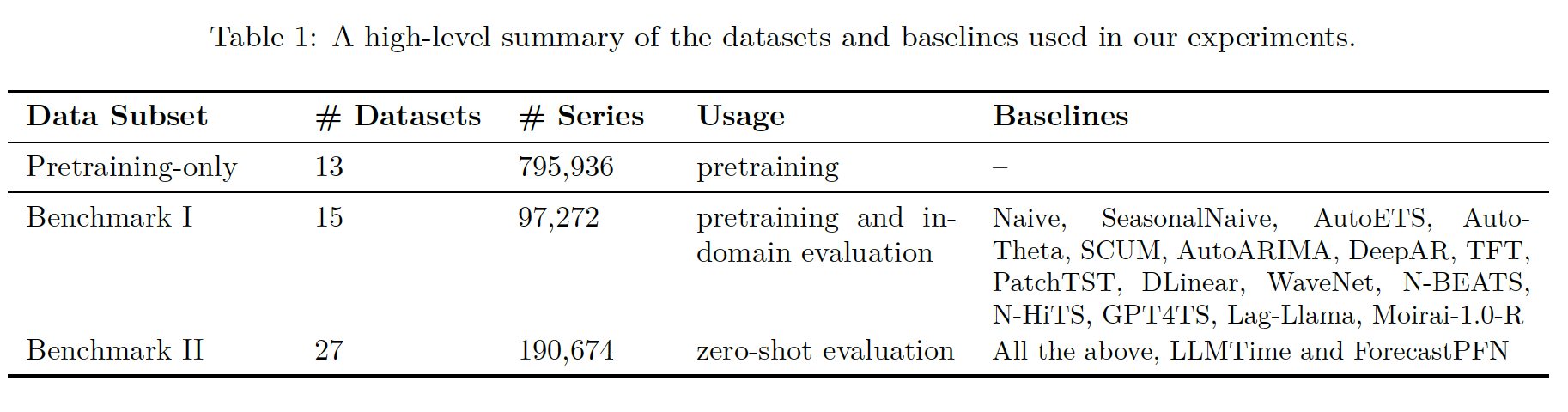
(1) Pretraining & Test Dataset and Baselines
(2) Benchmark I: In-domain Results
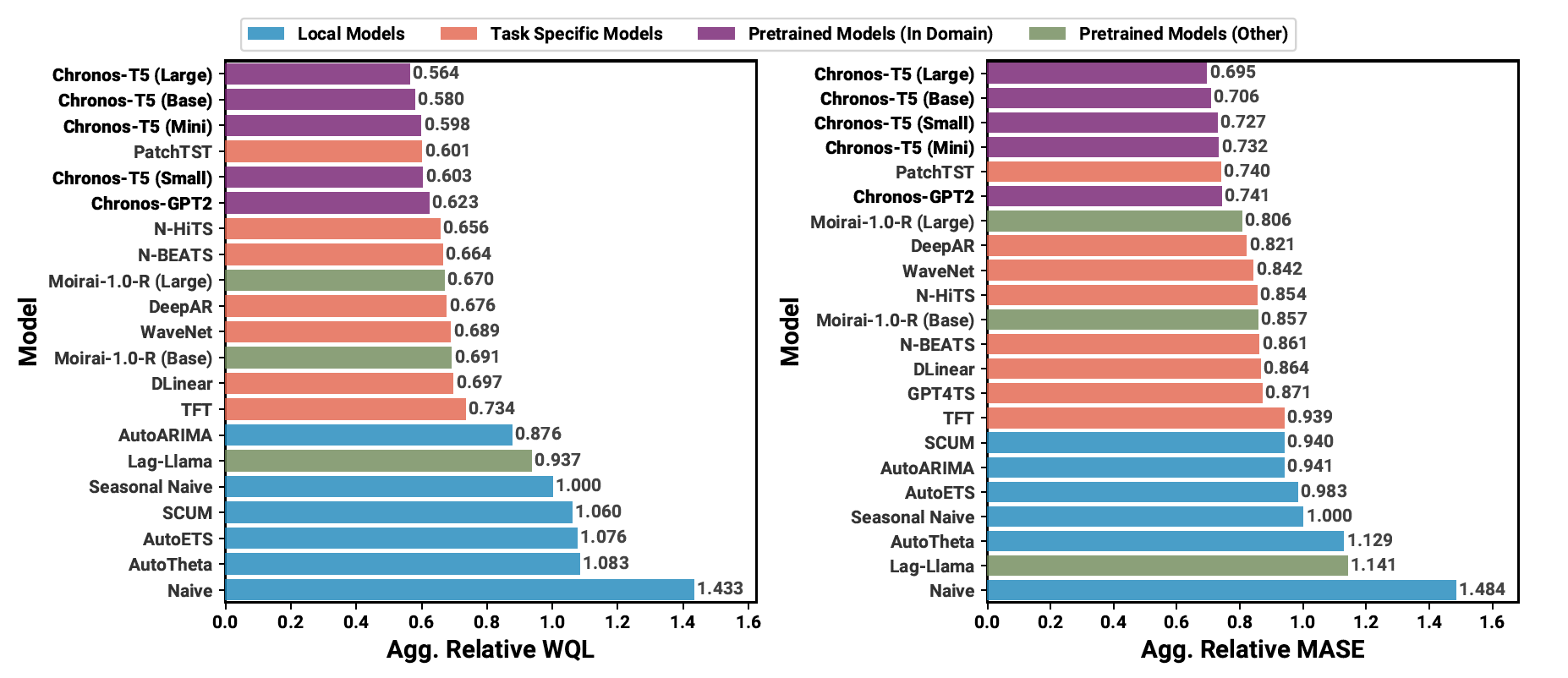
- CHRONOS pretraining에 쓰인 Benchmark 데이터셋을 포함하여 각 Baseline모델들을 평가하고 이를 aggregate 한 성능
(3) Benchmark II: Zero-shot Results
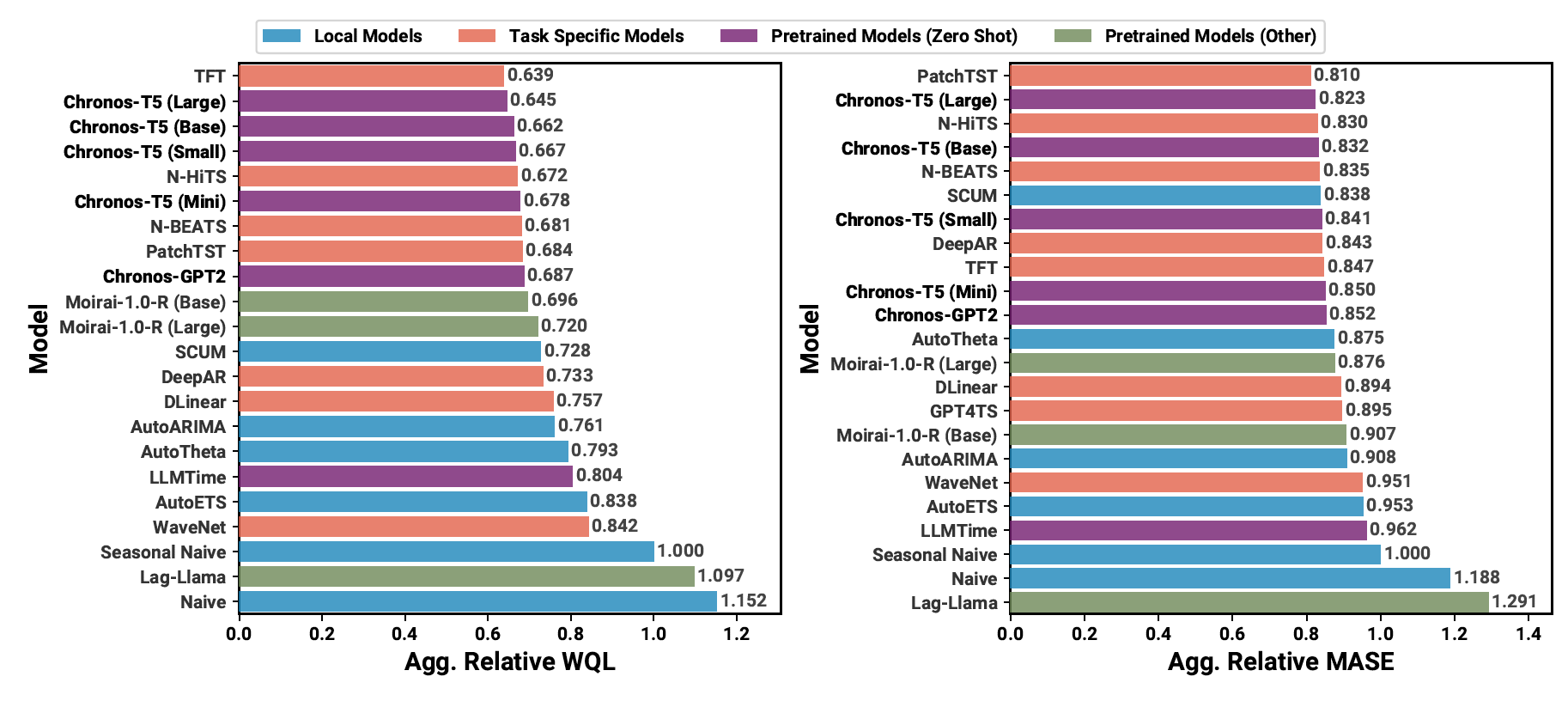
- CHRONOS pretraining에 쓰이지 않은 27개의 데이터셋에 zero-shot 성능을 평가한 것
- 이 외에도 매우 다양한 실험들을 통해 각각의 기법들이 성능 향상에 어떻게 기여하였는지 보여주었다.
Conclusion
- 존재하는 LLM의 architecture와 training 방법론에 tokenization through scaling과 quantization을 활용하여 time-series forcast에 적용.
Contributions
- 기존에 존재하던 LLM architecture가 각각의 time-series dataset에 맞는 customization 없이도 좋은 forecast 성능을 보여줌.
- 기존에는 각각의 태스크에 training/fine-tune이 되어야 했지만, zero-shot 태스크에서 성공적인 성능을 보이며 하나의 거대 pretrained 언어 모델로 inference-only의 파이프라인을 구축할 수 있다는 가능성을 보여줌.

AI 세상에서 개발자로 살아남기