서론
음성 인식(ASR, Automatic Speech Recognition)은 음성 데이터를 텍스트로 변환하는 기술로, 인공지능과 머신러닝의 중요한 응용 분야 중 하나입니다. 음성 인식 시스템을 구축하기 위해서는 음성 데이터의 다양한 특징을 추출하고 분석하는 것이 필요합니다. 이번 글에서는 음성 파일을 읽고, 여러 가지 음성 처리 기법을 통해 데이터를 시각화하는 과정을 소개하겠습니다. 이를 통해 음성 신호의 특징을 이해하고 분석하는 방법을 배울 수 있습니다.
음성 파일 읽고 시각화하기
우선, librosa 라이브러리를 사용하여 음성 파일을 로드하고, 시간 도메인에서 음성 신호를 시각화해보겠습니다.
import numpy as np
import matplotlib.pyplot as plt
import librosa
import librosa.display
# 음성 파일 로드
file_path = 'data/A220001.1.1.1.wav'
y, sr = librosa.load(file_path, sr=None)
# 시간축 생성
time = np.linspace(0, len(y) / sr, len(y))
# 음성 신호 시각화
plt.figure(figsize=(10, 4))
plt.plot(time, y)
plt.title('Waveform')
plt.xlabel('Time (s)')
plt.ylabel('Amplitude')
plt.show()위 코드는 librosa.load 함수를 사용하여 음성 파일을 로드하고, 시간 도메인에서 음성 신호를 시각화합니다. y는 음성 신호의 진폭 값들이고, sr은 샘플링 레이트입니다. time 배열은 각 샘플의 시간을 나타내며, 이를 이용해 진폭 값을 시간 축에 따라 시각화합니다.
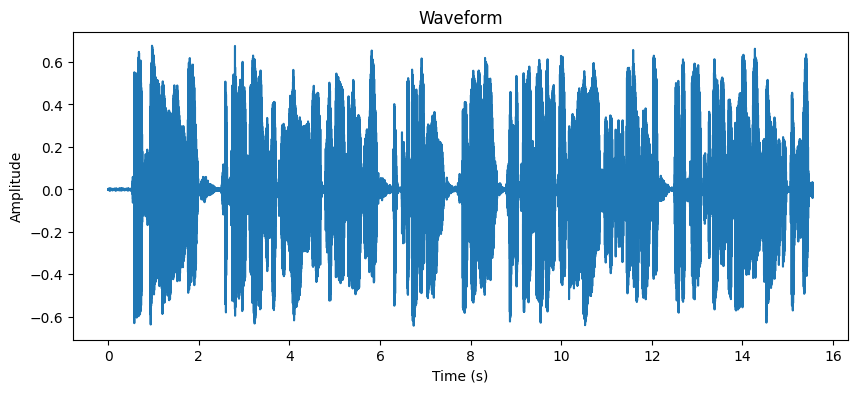
푸리에 변환으로 음성을 주파수 분해하기
음성 신호를 주파수 도메인으로 변환하여 주파수 성분을 분석해보겠습니다.
# 푸리에 변환
Y = np.fft.fft(y)
frequencies = np.fft.fftfreq(len(Y), 1/sr)
# 푸리에 변환 결과 시각화
plt.figure(figsize=(10, 4))
plt.plot(frequencies[:len(frequencies)//2], np.abs(Y)[:len(Y)//2])
plt.title('Fourier Transform')
plt.xlabel('Frequency (Hz)')
plt.ylabel('Magnitude')
plt.show()푸리에 변환은 시간 도메인의 신호를 주파수 도메인으로 변환하는 수학적 방법입니다. 이를 통해 음성 신호의 주파수 성분을 분석할 수 있습니다. np.fft.fft 함수를 사용하여 푸리에 변환을 수행하고, np.fft.fftfreq 함수를 통해 주파수 축을 생성합니다.
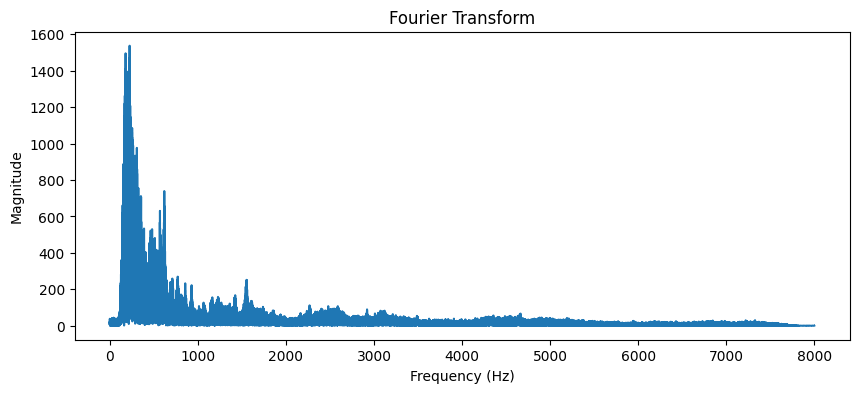
푸리에 변환 시각화 결과 해석
푸리에 변환(FFT, Fast Fourier Transform)을 통해 음성 신호의 주파수 성분을 분석한 결과입니다. 그래프는 주파수(Hz)에 따른 진폭(Magnitude)을 나타내며, 음성 신호의 주파수 도메인에서의 특성을 시각화합니다.
그래프 해석 및 인사이트
-
주파수 성분의 분포
- 그래프의 가로축은 주파수를 나타내며, 단위는 헤르츠(Hz)입니다. 세로축은 각 주파수 성분의 진폭을 나타내며, 이는 해당 주파수 성분의 강도를 의미합니다.
- 그래프에서 볼 수 있듯이, 0Hz에서 1000Hz 사이에 진폭이 가장 크게 나타납니다. 이는 음성 신호의 대부분의 에너지가 저주파수 대역에 집중되어 있음을 의미합니다.
-
주요 피크 분석
- 0Hz에서 약 500Hz 사이에 여러 개의 뚜렷한 피크가 존재합니다. 이러한 피크는 음성 신호의 주요 주파수 성분을 나타냅니다. 특히, 가장 높은 피크는 음성의 기본 주파수(F0, Fundamental Frequency)와 관련이 있을 가능성이 큽니다.
- 이러한 피크는 음성 신호의 음색(timbre)과 성별, 발음 특성 등을 분석하는 데 유용한 정보를 제공합니다.
-
고주파 성분
- 1000Hz 이후부터 8000Hz까지의 주파수 대역에서는 진폭이 상대적으로 낮습니다. 이는 음성 신호의 고주파 성분이 저주파 성분에 비해 에너지가 적음을 나타냅니다.
- 고주파 성분은 일반적으로 음성의 섬세한 부분이나 고음 영역의 특성을 나타내며, 발음의 명료성에 영향을 미칩니다.
설명 및 인사이트
-
음성 신호의 기본 주파수(F0)
- 그래프에서 가장 높은 피크가 나타나는 주파수는 기본 주파수(F0)일 가능성이 큽니다. F0는 사람의 목소리 톤을 결정하며, 남성의 경우 보통 85Hz에서 180Hz, 여성의 경우 165Hz에서 255Hz 사이에 위치합니다.
-
음성의 음색 및 특징 분석
- 여러 개의 피크는 음성의 배음(harmonics)을 나타냅니다. 배음은 기본 주파수의 정수배 주파수로 나타나며, 음성의 음색을 형성합니다. 예를 들어, 기본 주파수가 100Hz라면, 200Hz, 300Hz 등의 배음이 존재할 수 있습니다.
-
저주파 대역의 중요성
- 음성 신호의 대부분의 에너지가 저주파 대역(1000Hz 이하)에 집중되어 있다는 것은, 이 대역이 음성 인식 및 처리에서 매우 중요하다는 것을 의미합니다. 대부분의 음성 인식 시스템은 이 대역에서 특징을 추출하여 사용합니다.
-
고주파 성분의 역할
- 고주파 성분은 발음의 명료성 및 세부적인 발음 차이를 구분하는 데 중요한 역할을 합니다. 하지만, 고주파 성분은 노이즈에 민감할 수 있으므로, 음성 처리 시 필터링이 필요할 수 있습니다.
이와 같은 푸리에 변환 결과는 음성 신호의 주파수 성분을 분석하여 음성 인식, 음성 합성, 화자 인식 등의 다양한 음성 처리 응용 분야에서 중요한 정보를 제공합니다. 이를 통해 음성 신호의 기본 특성을 이해하고, 더 나은 음성 인식 시스템을 설계하는 데 도움이 됩니다.
단시간 푸리에 변환하여 스펙트럼 생성하기
음성 신호의 시간에 따른 주파수 변화를 분석하기 위해 단시간 푸리에 변환(STFT)을 사용합니다.
# 단시간 푸리에 변환
D = librosa.stft(y)
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max)
# 스펙트로그램 시각화
plt.figure(figsize=(10, 4))
librosa.display.specshow(S_db, sr=sr, x_axis='time', y_axis='log')
plt.colorbar(format='%+2.0f dB')
plt.title('Spectrogram')
plt.show()STFT는 음성 신호를 짧은 시간 구간으로 나누어 각 구간에 대해 푸리에 변환을 수행하는 방법입니다. 이를 통해 시간에 따른 주파수 변화를 시각화한 스펙트로그램을 생성할 수 있습니다. librosa.stft 함수는 STFT를 수행하고, librosa.amplitude_to_db 함수는 진폭 값을 데시벨(dB) 스케일로 변환합니다.
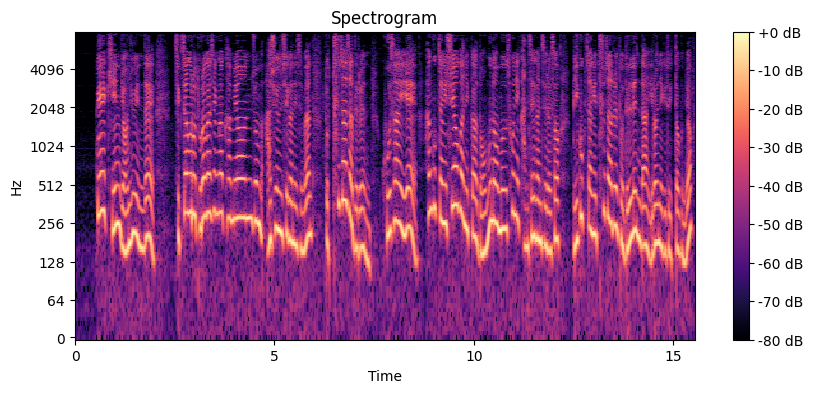
스펙트로그램 시각화 결과 해석
단시간 푸리에 변환(STFT, Short-Time Fourier Transform)을 통해 음성 신호의 시간에 따른 주파수 변화를 분석한 결과입니다. 스펙트로그램은 시간(Time)에 따른 주파수(Frequency) 성분의 변화를 색상으로 표현한 그래프입니다. 이 그래프는 음성 신호의 다양한 특징을 시각적으로 분석할 수 있게 해줍니다.
그래프 해석 및 인사이트
-
시간 축과 주파수 축
- 가로축(Time)은 시간의 흐름을 나타내며, 단위는 초(seconds)입니다.
- 세로축(Frequency)은 주파수를 나타내며, 단위는 헤르츠(Hz)입니다. 로그 스케일로 표현되어 있습니다.
-
색상 및 데시벨(dB) 값
- 색상은 각 주파수 성분의 에너지를 나타내며, 진폭을 데시벨(dB) 단위로 변환한 값입니다.
- 색상 막대(colorbar)는 에너지의 강도를 나타내며, 밝은 색일수록 에너지가 크고, 어두운 색일수록 에너지가 작음을 의미합니다.
-
시간에 따른 주파수 변화
- 스펙트로그램에서 주기적으로 반복되는 패턴을 관찰할 수 있습니다. 이는 음성 신호가 주기적인 성분을 포함하고 있음을 나타냅니다.
- 특정 주파수 대역에서 에너지가 집중된 부분은 음성의 포먼트(formants)라고 불리며, 이는 발음의 성질을 결정하는 중요한 주파수 성분입니다.
설명 및 인사이트
-
포먼트(Formants)
- 스펙트로그램에서 볼 수 있는 주파수 대역에서의 밝은 부분(높은 에너지 영역)은 포먼트라고 불립니다. 포먼트는 사람의 발음 구조를 결정짓는 중요한 요소로, 각 포먼트는 발음에 따라 특정 주파수 대역에 위치합니다.
- 첫 번째 포먼트(F1)는 대개 0Hz에서 1000Hz 사이에 위치하며, 두 번째 포먼트(F2)는 대개 1000Hz에서 3000Hz 사이에 위치합니다.
-
주파수 성분의 시간적 변화
- 스펙트로그램에서 특정 주파수 성분이 시간에 따라 변하는 모습을 관찰할 수 있습니다. 이는 음성 신호가 시간에 따라 변화하는 주파수 성분을 포함하고 있음을 나타냅니다.
- 이러한 시간적 변화를 통해 음성 신호의 동적 특징을 분석할 수 있습니다.
-
에너지 집중 영역
- 스펙트로그램에서 볼 수 있는 밝은 영역은 음성 신호의 에너지가 집중된 주파수 대역을 나타냅니다. 이러한 에너지 집중 영역은 음성 신호의 주요 특징을 분석하는 데 중요한 정보를 제공합니다.
-
로그 스케일 주파수
- 주파수 축이 로그 스케일로 표현되어 있어, 저주파수 대역에서의 세부적인 변화를 더 잘 관찰할 수 있습니다. 음성 신호의 대부분의 중요한 특징은 저주파수 대역에 집중되어 있기 때문에 로그 스케일은 음성 분석에 적합합니다.
결론
이 스펙트로그램 시각화 결과는 음성 신호의 시간에 따른 주파수 변화를 시각적으로 분석할 수 있게 해줍니다. 포먼트와 같은 주요 주파수 성분을 식별하고, 음성 신호의 동적 특성을 이해하는 데 중요한 정보를 제공합니다. 이러한 분석은 음성 인식, 화자 인식, 음성 합성 등 다양한 음성 처리 응용 분야에서 유용하게 사용될 수 있습니다.
로그 Mel Filter Bank 특징 시각화
음성 신호의 특징을 더 잘 나타내기 위해 로그 Mel 필터 뱅크를 사용합니다.
# Mel Filter Bank
mel_spectrogram = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=128)
mel_spectrogram_db = librosa.power_to_db(mel_spectrogram, ref=np.max)
# Mel Filter Bank 시각화
plt.figure(figsize=(10, 4))
librosa.display.specshow(mel_spectrogram_db, sr=sr, x_axis='time', y_axis='mel')
plt.colorbar(format='%+2.0f dB')
plt.title('Mel Spectrogram')
plt.show()Mel 필터 뱅크는 인간의 청각 인지와 유사한 주파수 축을 사용하는 필터입니다. librosa.feature.melspectrogram 함수는 Mel 필터 뱅크를 사용하여 스펙트로그램을 생성하고, librosa.power_to_db 함수는 이를 로그 스케일로 변환합니다.
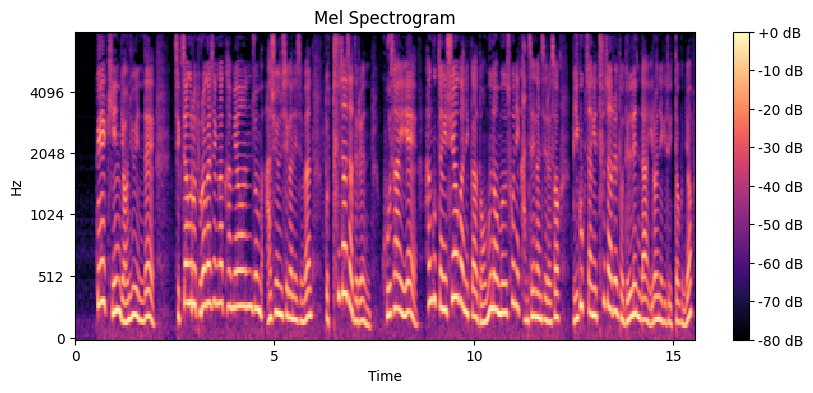
Mel Spectrogram 시각화 결과 해석
Mel 필터 뱅크를 사용하여 생성된 Mel 스펙트로그램은 음성 신호의 주파수 성분을 Mel 스케일로 변환하여 시각화한 것입니다. Mel 스케일은 인간의 청각 인지와 유사한 주파수 축을 사용하여, 음성 신호의 특징을 더 잘 나타냅니다. 이 그래프는 음성 신호의 시간에 따른 Mel 주파수 성분의 변화를 색상으로 표현한 것입니다.
그래프 해석 및 인사이트
-
시간 축과 Mel 주파수 축
- 가로축(Time)은 시간의 흐름을 나타내며, 단위는 초(seconds)입니다.
- 세로축(Frequency)은 Mel 스케일로 표현된 주파수입니다. Mel 스케일은 주파수를 로그 스케일로 변환하여 저주파수 대역에서의 변화를 더 잘 관찰할 수 있도록 합니다.
-
색상 및 데시벨(dB) 값
- 색상은 각 주파수 성분의 에너지를 나타내며, 진폭을 데시벨(dB) 단위로 변환한 값입니다.
- 색상 막대(colorbar)는 에너지의 강도를 나타내며, 밝은 색일수록 에너지가 크고, 어두운 색일수록 에너지가 작음을 의미합니다.
-
시간에 따른 주파수 변화
- Mel 스펙트로그램에서 주기적으로 반복되는 패턴을 관찰할 수 있습니다. 이는 음성 신호가 주기적인 성분을 포함하고 있음을 나타냅니다.
- 특정 Mel 주파수 대역에서 에너지가 집중된 부분은 음성의 포먼트(formants)라고 불리며, 이는 발음의 성질을 결정하는 중요한 주파수 성분입니다.
설명 및 인사이트
-
Mel 스케일
- Mel 스케일은 인간의 청각 시스템을 모델링한 주파수 스케일입니다. 인간은 저주파수 변화에 더 민감하게 반응하며, 고주파수 변화에 덜 민감합니다. Mel 스케일은 이러한 특성을 반영하여 저주파수 대역을 더 세밀하게 표현합니다.
-
포먼트(Formants)
- Mel 스펙트로그램에서 볼 수 있는 주파수 대역에서의 밝은 부분(높은 에너지 영역)은 포먼트라고 불립니다. 포먼트는 사람의 발음 구조를 결정짓는 중요한 요소로, 각 포먼트는 발음에 따라 특정 주파수 대역에 위치합니다.
- 첫 번째 포먼트(F1)는 대개 0Hz에서 1000Hz 사이에 위치하며, 두 번째 포먼트(F2)는 대개 1000Hz에서 3000Hz 사이에 위치합니다.
-
주파수 성분의 시간적 변화
- Mel 스펙트로그램에서 특정 주파수 성분이 시간에 따라 변하는 모습을 관찰할 수 있습니다. 이는 음성 신호가 시간에 따라 변화하는 주파수 성분을 포함하고 있음을 나타냅니다.
- 이러한 시간적 변화를 통해 음성 신호의 동적 특징을 분석할 수 있습니다.
-
에너지 집중 영역
- Mel 스펙트로그램에서 볼 수 있는 밝은 영역은 음성 신호의 에너지가 집중된 주파수 대역을 나타냅니다. 이러한 에너지 집중 영역은 음성 신호의 주요 특징을 분석하는 데 중요한 정보를 제공합니다.
결론
이 Mel 스펙트로그램 시각화 결과는 음성 신호의 시간에 따른 Mel 주파수 성분의 변화를 시각적으로 분석할 수 있게 해줍니다. 포먼트와 같은 주요 주파수 성분을 식별하고, 음성 신호의 동적 특성을 이해하는 데 중요한 정보를 제공합니다. 이러한 분석은 음성 인식, 화자 인식, 음성 합성 등 다양한 음성 처리 응용 분야에서 유용하게 사용될 수 있습니다. Mel 스케일을 사용함으로써 인간의 청각 시스템과 유사한 방식으로 음성 신호를 분석할 수 있으며, 이는 음성 인식 시스템의 성능을 향상시키는 데 중요한 역할을 합니다.
MFCC (Mel Frequency Cepstral Coefficients) 시각화
MFCC는 음성 신호의 스펙트럼을 더 간결하게 표현한 특징입니다.
# MFCC
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)
# MFCC 시각화
plt.figure(figsize=(10, 4))
librosa.display.specshow(mfcc, sr=sr, x_axis='time')
plt.colorbar()
plt.title('MFCC')
plt.show()MFCC는 음성 인식에서 매우 중요한 특징으로, 인간의 청각 시스템을 모델링한 것입니다. librosa.feature.mfcc 함수는 MFCC를 계산합니다.
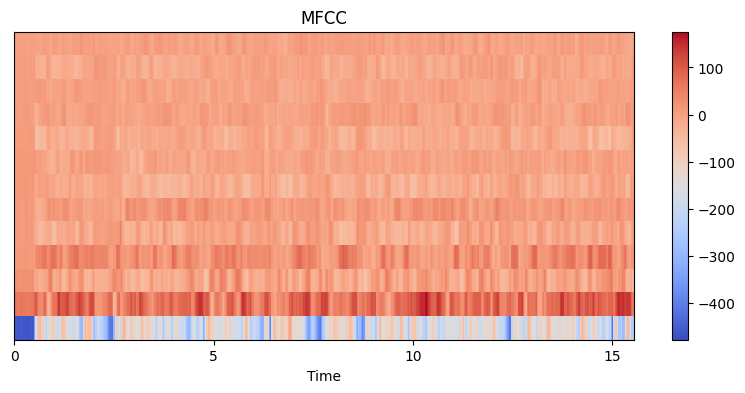
MFCC 시각화 결과 해석
MFCC (Mel-Frequency Cepstral Coefficients)는 음성 신호의 스펙트럼을 더 간결하게 표현한 특징으로, 음성 인식 시스템에서 널리 사용됩니다. MFCC는 인간의 청각 시스템을 모델링하여, 주파수 성분을 Mel 스케일로 변환한 후, 켑스트럼 분석을 통해 특징 벡터를 추출합니다.
그래프 해석 및 인사이트
-
시간 축과 MFCC 축
- 가로축(Time)은 시간의 흐름을 나타내며, 단위는 초(seconds)입니다.
- 세로축(MFCC Coefficients)은 MFCC 계수를 나타냅니다. 일반적으로 13개의 계수가 사용됩니다.
-
색상 및 MFCC 값
- 색상은 각 시간과 MFCC 계수의 값을 나타내며, 색상 막대(colorbar)는 값의 크기를 나타냅니다. 빨간색은 높은 값을, 파란색은 낮은 값을 의미합니다.
-
시간에 따른 MFCC 변화
- MFCC 그래프에서 볼 수 있듯이, 시간이 지남에 따라 MFCC 값이 변합니다. 이는 음성 신호의 특징이 시간에 따라 어떻게 변하는지를 보여줍니다.
설명 및 인사이트
-
MFCC의 중요성
- MFCC는 음성 인식에서 매우 중요한 특징으로, 음성 신호의 주파수 성분을 인간의 청각 시스템과 유사한 방식으로 표현합니다. 이를 통해 음성 신호의 중요한 정보를 효율적으로 추출할 수 있습니다.
-
시간에 따른 특징 분석
- MFCC 그래프에서 시간에 따른 MFCC 값의 변화를 관찰할 수 있습니다. 이는 음성 신호가 시간에 따라 어떻게 변하는지를 나타내며, 발음의 변화, 음색의 변화 등을 분석할 수 있습니다.
-
저주파수 대역에서의 변동
- 일반적으로 첫 번째 몇 개의 MFCC 계수는 저주파수 대역의 특징을 나타내며, 음성 신호의 에너지 분포를 반영합니다. 이러한 계수들은 음성의 기본적인 특성을 결정짓는 중요한 요소입니다.
-
고주파수 대역에서의 변동
- 뒤쪽의 MFCC 계수들은 고주파수 대역의 특징을 나타내며, 음성의 세부적인 특징을 반영합니다. 이들은 음성의 섬세한 부분을 분석하는 데 유용합니다.
결론
이 MFCC 시각화 결과는 음성 신호의 시간에 따른 주파수 특징을 간결하게 표현한 것입니다. MFCC는 음성 인식 시스템에서 매우 중요한 역할을 하며, 음성 신호의 중요한 특징을 효율적으로 추출할 수 있습니다. 이러한 특징은 음성 인식, 화자 인식, 음성 합성 등 다양한 음성 처리 응용 분야에서 유용하게 사용될 수 있습니다. MFCC를 통해 음성 신호의 중요한 정보를 이해하고 분석하는 방법을 배울 수 있으며, 이를 통해 더 나은 음성 인식 시스템을 구축할 수 있습니다.
특징의 평균과 표준편차 계산 및 시각화
각 MFCC 계수의 평균과 표준편차를 계산하여 시각화합니다.
# 특징의 평균과 표준편차 계산
mfcc_mean = np.mean(mfcc, axis=1)
mfcc_std = np.std(mfcc, axis=1)
# 평균과 표준편차 시각화
plt.figure(figsize=(10, 4))
plt.errorbar(np.arange(len(mfcc_mean)), mfcc_mean, yerr=mfcc_std, fmt='o')
plt.title('MFCC Mean and Standard Deviation')
plt.xlabel('MFCC Coefficients')
plt.ylabel('Values')
plt.show()이 코드는 각 MFCC 계수의 평균과 표준편차를 계산하여 시각화합니다. 이를 통해 음성 신호의 특징 분포를 이해할 수 있습니다.
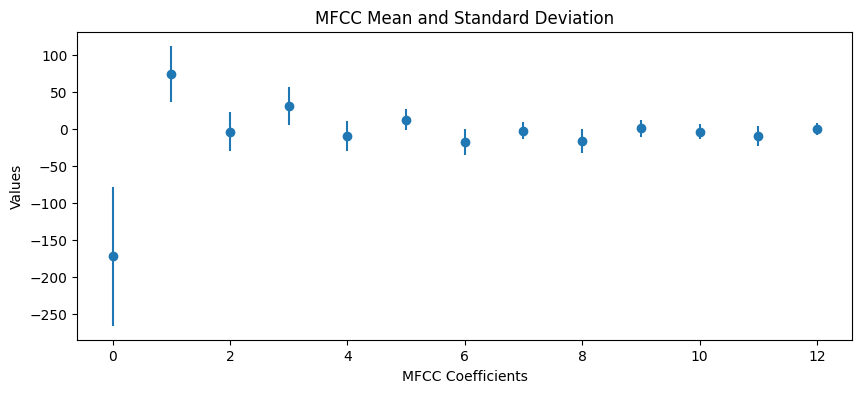
MFCC 평균과 표준편차 시각화 결과 해석
이 그래프는 MFCC(Mel-Frequency Cepstral Coefficients) 계수들의 평균과 표준편차를 나타냅니다. 각 MFCC 계수는 음성 신호의 주파수 성분을 나타내며, 평균과 표준편차를 통해 이들 계수의 분포를 분석할 수 있습니다.
그래프 해석 및 인사이트
-
가로축과 세로축
- 가로축은 MFCC 계수의 인덱스를 나타내며, 0번부터 12번까지 총 13개의 계수가 있습니다.
- 세로축은 각 MFCC 계수의 값(Value)을 나타냅니다.
-
오류 막대(Error Bars)
- 각 점은 해당 MFCC 계수의 평균 값을 나타내며, 오류 막대는 표준편차를 나타냅니다. 오류 막대가 클수록 해당 MFCC 계수의 값이 더 넓게 분포되어 있음을 의미합니다.
-
첫 번째 MFCC 계수
- 첫 번째 MFCC 계수는 주파수 성분의 에너지 분포를 나타내며, 일반적으로 음성 신호의 가장 큰 변화를 반영합니다. 그래프에서 볼 수 있듯이, 첫 번째 MFCC 계수의 평균이 가장 크고, 표준편차도 상대적으로 큽니다.
-
고주파수 MFCC 계수
- 뒤쪽의 MFCC 계수들은 고주파수 대역의 특징을 나타내며, 평균 값이 0에 가깝고, 표준편차도 비교적 작습니다. 이는 고주파수 대역의 특징이 저주파수 대역에 비해 상대적으로 덜 변동함을 의미합니다.
설명 및 인사이트
-
MFCC 평균
- MFCC 계수의 평균은 음성 신호의 전반적인 주파수 성분을 나타냅니다. 각 계수의 평균 값은 해당 주파수 대역의 에너지를 반영합니다.
- 첫 번째 MFCC 계수의 평균이 큰 것은 음성 신호의 에너지가 저주파수 대역에 집중되어 있음을 의미합니다.
-
MFCC 표준편차
- 표준편차는 MFCC 계수 값의 변동성을 나타냅니다. 표준편차가 클수록 해당 주파수 대역의 특징이 더 변동함을 의미합니다.
- 첫 번째 MFCC 계수의 표준편차가 큰 것은 저주파수 대역의 에너지 변동이 크다는 것을 나타냅니다.
-
고주파수 대역의 안정성
- 고주파수 대역의 MFCC 계수들은 평균 값이 0에 가깝고, 표준편차도 작습니다. 이는 고주파수 대역의 특징이 상대적으로 안정적임을 의미합니다.
- 이는 음성 신호의 대부분의 정보가 저주파수 대역에 집중되어 있다는 것을 시사합니다.
결론
이 MFCC 평균과 표준편차 시각화 결과는 음성 신호의 주파수 성분의 분포와 변동성을 분석하는 데 유용한 정보를 제공합니다. 첫 번째 MFCC 계수는 음성 신호의 에너지 분포를 나타내며, 고주파수 대역의 MFCC 계수들은 더 안정적인 특징을 나타냅니다. 이러한 분석은 음성 인식, 화자 인식, 음성 합성 등 다양한 음성 처리 응용 분야에서 유용하게 사용될 수 있습니다. MFCC 평균과 표준편차를 통해 음성 신호의 중요한 특징을 이해하고, 이를 기반으로 더 나은 음성 인식 시스템을 설계할 수 있습니다.
MFCC (Mel-Frequency Cepstral Coefficients) 설명
MFCC(Mel-Frequency Cepstral Coefficients)는 음성 신호의 주파수 성분을 분석하고 인간의 청각 인지와 유사하게 표현하는 방법입니다. 음성 인식 시스템에서 널리 사용되는 특징으로, 음성 신호의 중요한 정보를 간결하게 표현할 수 있습니다.
MFCC의 계산 과정
-
프레임 분할 (Framing)
- 음성 신호는 짧은 시간 프레임으로 나뉩니다. 일반적으로 20~40ms 길이의 프레임을 사용합니다. 각 프레임은 오버랩(overlap)되어, 정보 손실을 최소화합니다.
-
윈도우 적용 (Windowing)
- 각 프레임에 윈도우 함수를 적용합니다. 일반적으로 해밍 윈도우(Hamming window)를 사용하여 신호의 불연속성을 줄입니다.
-
푸리에 변환 (Fourier Transform)
- 각 프레임에 대해 푸리에 변환을 수행하여 주파수 도메인으로 변환합니다. 이를 통해 주파수 성분과 진폭을 얻을 수 있습니다.
-
Mel 필터 뱅크 적용 (Mel Filter Bank)
- 주파수 성분을 Mel 스케일로 변환합니다. Mel 스케일은 인간의 청각 인지에 기반한 주파수 스케일로, 저주파수에서 더 세밀한 변화를 감지할 수 있습니다. 여러 개의 삼각형 필터를 사용하여 주파수 성분을 합산합니다.
-
로그 스케일 (Logarithm)
- Mel 필터 뱅크의 출력을 로그 스케일로 변환합니다. 인간의 청각 인지는 로그 스케일로 반응하므로, 이를 통해 주파수 성분의 에너지를 더 잘 표현할 수 있습니다.
-
역 푸리에 변환 (Inverse Fourier Transform)
- 로그 스케일의 주파수 성분을 역 푸리에 변환하여 최종적으로 MFCC를 얻습니다. 이 과정은 켑스트럼(cepstrum) 분석으로도 불립니다.
MFCC의 의미
- 첫 번째 계수 (C0): 음성 신호의 전체적인 에너지를 나타냅니다.
- 나머지 계수들 (C1 ~ C12): 음성 신호의 세부적인 주파수 성분을 나타냅니다. 이들 계수는 음성의 음색(timbre)과 발음의 특징을 잘 반영합니다.
MFCC 시각화 해석과 활용 연관 설명
이제 앞서 시각화한 MFCC 평균과 표준편차 그래프를 다시 보면서, MFCC의 계산 과정과 의미를 연관 지어 설명하겠습니다.
MFCC 평균과 표준편차 시각화
# 평균과 표준편차 시각화
plt.figure(figsize=(10, 4))
plt.errorbar(np.arange(len(mfcc_mean)), mfcc_mean, yerr=mfcc_std, fmt='o')
plt.title('MFCC Mean and Standard Deviation')
plt.xlabel('MFCC Coefficients')
plt.ylabel('Values')
plt.show()이 그래프는 음성 신호에서 추출된 각 MFCC 계수의 평균값과 표준편차를 나타냅니다.
-
첫 번째 MFCC 계수 (C0)
- 해석: 평균값이 매우 낮고 표준편차가 큽니다. 이는 음성 신호의 전체 에너지가 높고, 발음에 따라 에너지 변동이 크다는 것을 의미합니다.
- 활용: 첫 번째 MFCC 계수는 음성 신호의 에너지를 나타내므로, 음성 인식 시스템에서 노이즈 제거 및 신호 정규화에 사용될 수 있습니다.
-
두 번째 MFCC 계수 (C1)
- 해석: 평균값이 높고 표준편차도 큽니다. 이는 음성 신호의 주요 주파수 성분이 변동이 크다는 것을 나타냅니다.
- 활용: 두 번째 MFCC 계수는 음성 신호의 저주파수 대역을 나타내며, 발음의 차이를 잘 반영합니다. 이를 통해 화자 인식 또는 감정 인식 모델에 활용할 수 있습니다.
-
다른 MFCC 계수들 (C2 ~ C12)
- 해석: 평균값이 0에 가깝고 표준편차가 작습니다. 이는 고주파수 대역의 주파수 성분이 상대적으로 안정적임을 의미합니다.
- 활용: 고주파수 대역의 MFCC 계수들은 음성 신호의 세부적인 특징을 나타냅니다. 발음의 명확성, 감정 상태 등의 분석에 사용될 수 있습니다.
예시: 음성 인식 모델링
-
데이터 준비
- 다양한 발음의 음성 데이터셋을 수집합니다. 각 음성 샘플에 대해 MFCC를 계산합니다.
-
특징 추출
- 각 음성 샘플에서 13개의 MFCC 계수를 추출합니다. 이를 통해 음성 신호의 중요한 주파수 성분을 간결하게 표현할 수 있습니다.
-
모델 학습
- 추출된 MFCC 계수들을 입력 특징으로 사용하여 음성 인식 모델을 학습시킵니다. 예를 들어, CNN 모델을 사용하여 스펙트로그램 기반의 음성 인식 모델을 구축할 수 있습니다.
- MFCC 계수들의 평균과 표준편차를 사용하여 데이터를 정규화하고, 변동성이 큰 계수들을 중요 특징으로 선택하여 모델의 성능을 향상시킬 수 있습니다.
-
모델 평가
- 테스트 데이터셋을 사용하여 모델의 성능을 평가합니다. MFCC를 통해 추출한 특징들이 모델의 정확도를 높이는 데 어떻게 기여하는지 분석합니다.
이와 같은 방식으로, MFCC의 계산 과정과 의미를 이해하고, 이를 바탕으로 음성 인식 모델을 설계하고 최적화할 수 있습니다. MFCC는 음성 신호의 중요한 특징을 효율적으로 추출하여 모델의 성능을 향상시키는 데 중요한 역할을 합니다.
