안녕하세요, Sylen입니다. 오늘은 패스트캠퍼스 Upstage AI Lab 3기의 파이널 프로젝트에 대한 후기를 공유하고자 합니다. 이번 프로젝트는 과학 지식 질의 응답 시스템 구축이라는 주제로, 팀원들과 함께 4주간 열심히 달려왔습니다. 이 글에서는 프로젝트의 목표, 진행 과정, 사용한 기술, 그리고 얻은 인사이트에 대해 상세히 다루어보겠습니다.
프로젝트 소개
대회 개요
이번 프로젝트는 과학 지식 질의 응답 시스템 구축 대회로, 사용자로부터 입력된 질문과 대화 히스토리를 기반으로 적절한 답변을 생성하는 시스템을 개발하는 것이 목표였습니다. 이를 위해 검색 엔진에서 관련 문서를 추출하고, 그 문서를 활용하여 답변을 생성해야 했습니다.
- 데이터셋:
- 색인 대상 문서: 총 4,272개의 과학 및 교육 관련 문서
- 평가 데이터: 220개의 대화형 자연어 메시지
- 평가 방법: Mean Average Precision (MAP) 점수를 사용하여 검색 성능을 평가
- 프로젝트 기간: 2024년 10월 2일 ~ 2024년 10월 24일
팀 소개
저희 팀 "IR 2조 전지재능"은 총 5명의 팀원으로 구성되었습니다.
- 이윤재: Elasticsearch 설정 및 Reranker 모델 학습 담당
- 장은지: ColBERT 모델 개발 및 CrossEncoder 적용
- 이재명: 청킹(Chunking) 전략과 Faiss 활용
- 전백찬: 데이터 전처리 및 프롬프트 엔지니어링
- 최지미: 임베딩 생성 및 Standalone Query 개발
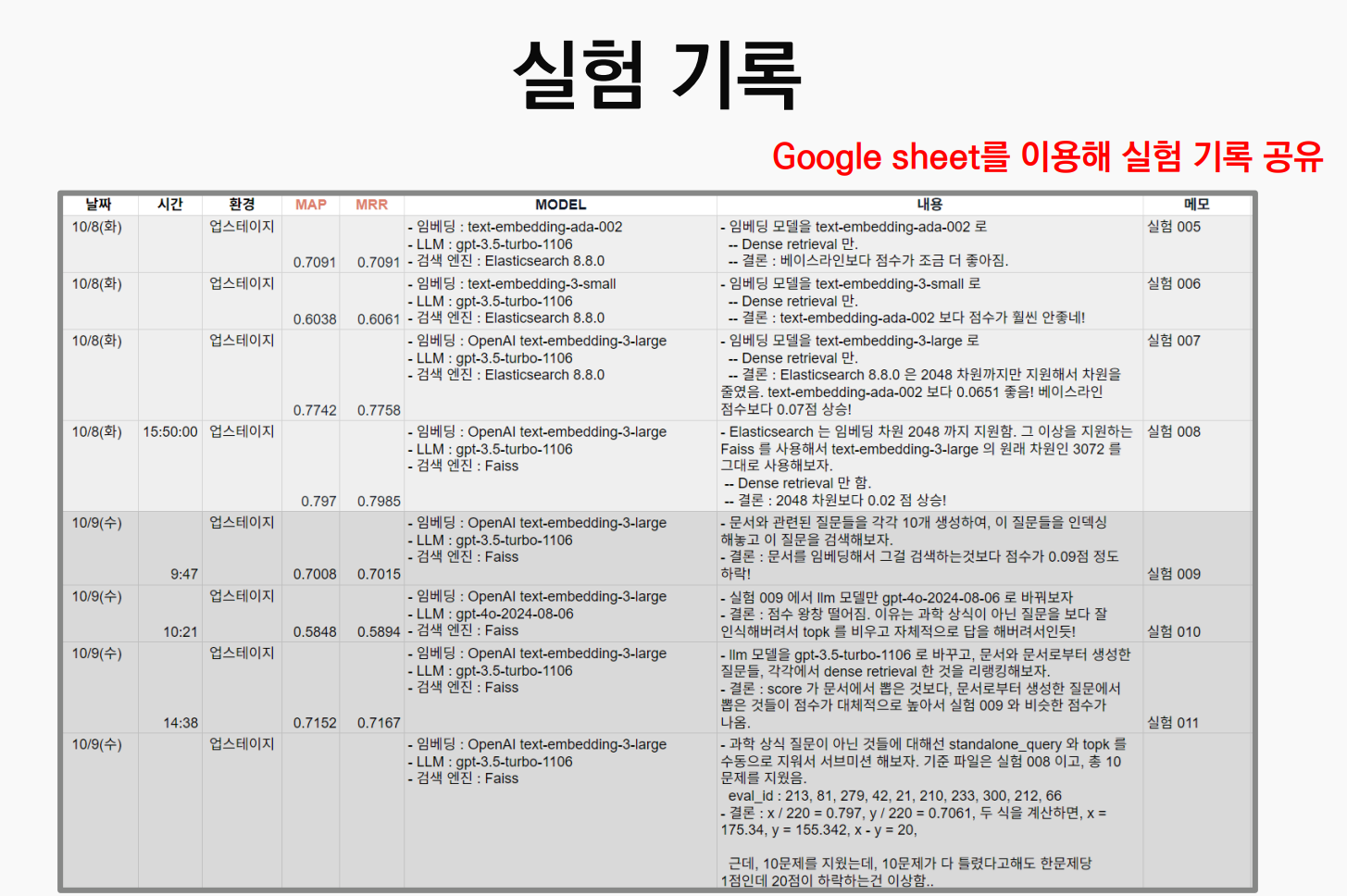
데이터 탐색 및 전처리
데이터 분석
문서 길이 분석:
- 문서의 글자 수가 최소 44자에서 최대 1,230자까지 다양했습니다.
- 평균 글자 수는 315자, 표준편차는 104자로 편차가 상당히 컸습니다.
- 문서 길이의 편차를 고려하여 문서를 청크로 분할하는 전략이 필요하다고 판단했습니다.
평가 데이터 분석:
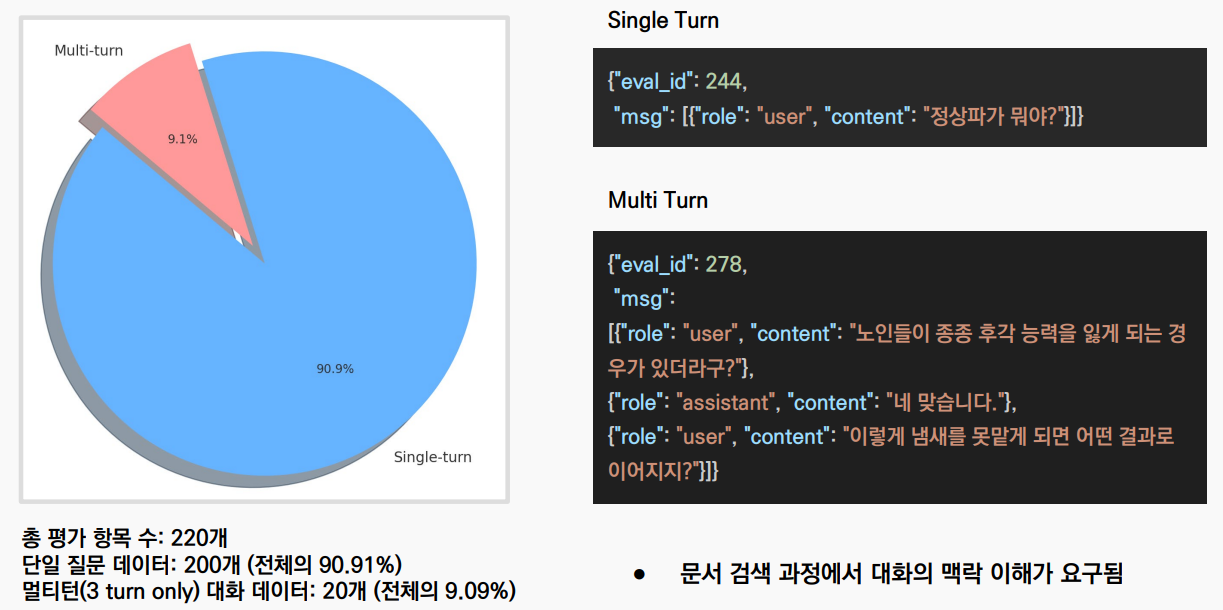
- 총 220개의 평가 항목 중 단일 턴 질문이 200개(90.91%)를 차지했습니다.
- 멀티 턴 대화(3턴)는 20개(9.09%)로, 대화의 맥락 이해가 요구되는 데이터도 포함되어 있었습니다.
Meta 정보 생성
LLM(대용량 언어 모델)을 활용하여 각 문서의 Meta 정보를 생성했습니다. 생성된 필드는 다음과 같습니다.
- title: 문서의 제목
- keywords: 관련 키워드 목록
- summary: 문서 요약
- categories: 연관 카테고리 (예: 물리학, 생물학)
이러한 Meta 정보는 검색 과정에서 추가적인 피처로 활용되었습니다.
청킹(Chunking) 전략
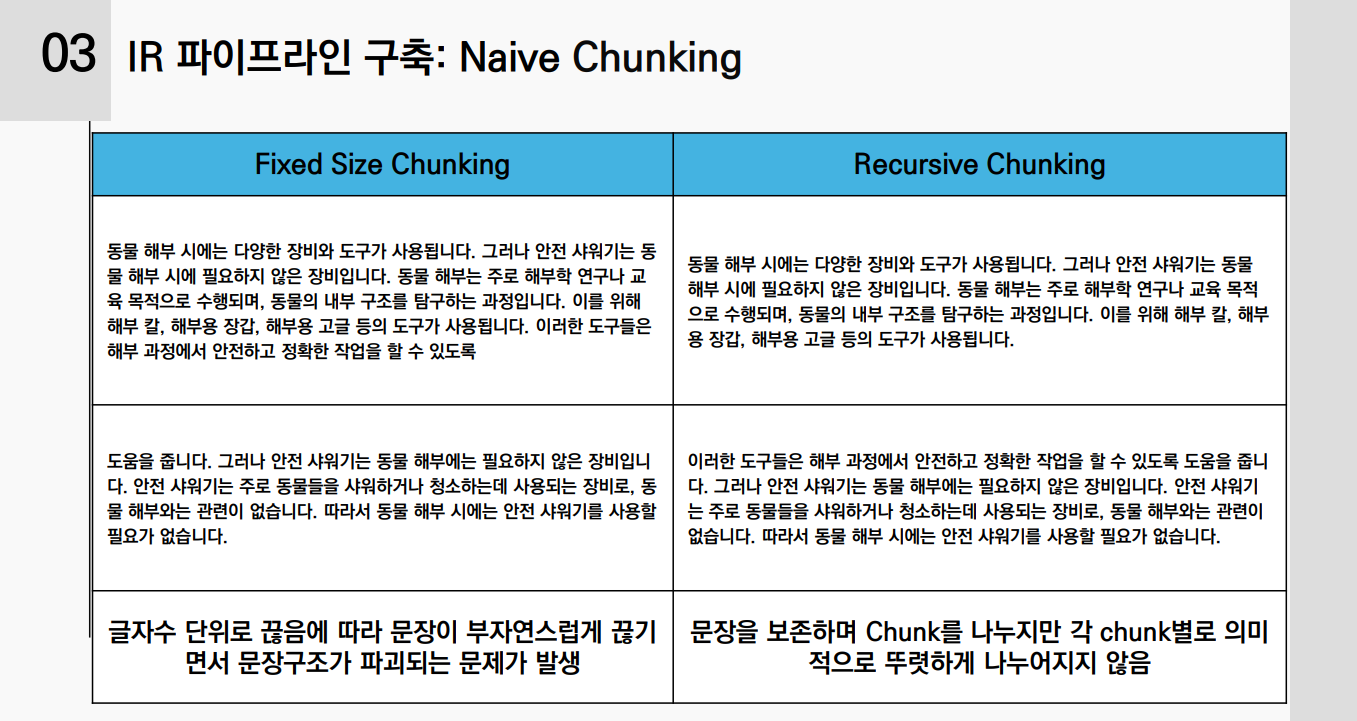
나이브 청킹:
- Fixed Size Chunking: 고정된 글자 수로 문서를 분할
- Recursive Chunking: 문장 단위로 분할하되, 각 청크의 크기가 일정 범위를 넘지 않도록 재귀적으로 분할
의미 기반 청킹(Semantic Chunking):
- 문장 간의 의미적 유사도를 계산하여 의미적으로 일관된 청크를 생성
- Sentence Transformer 모델을 사용하여 문장 임베딩을 생성하고, 코사인 유사도를 계산
- 유사도 임계값(0.7)에 따라 청크를 분할하고, 최대 청크 수를 제한하기 위해 K-Means 클러스터링을 적용
IR 파이프라인 구축
임베딩(Embedding) 생성
다양한 임베딩 모델을 테스트하여 최적의 모델을 선정했습니다.
- SentenceTransformer("snunlp/KR-SBERT-V40K-klueNLI-augSTS")를 최종적으로 선택했습니다.
- 한국어로 학습된 모델이 다국어 모델보다 우수한 성능을 보였습니다.
- 임베딩 차원이 높다고 항상 성능이 향상되는 것은 아니었습니다.
Standalone Query 생성
사용자 대화로부터 검색에 적합한 Standalone Query를 생성하기 위해 프롬프트 엔지니어링을 수행했습니다.
- LLM 모델: Gemma2(rtzr-ko-gemma-2-9b-it), OpenAI GPT-4, Anthropic Claude 등 다양한 모델을 활용
- 프롬프트 설계: 원하는 출력 형식을 명확하게 지시하고, 예시를 포함하여 일관된 출력이 나오도록 유도
예시 프롬프트:
당신은 과학 기술에 특화된 상식 RAG 시스템입니다.
사용자 대화 이력으로부터 검색에 적합한 쿼리를 생성해주세요.
응답은 반드시 JSON 형식으로 출력하세요.Elasticsearch 설정
유사도 알고리즘 및 파라미터 조정:
- LMJelinekMercer 유사도 알고리즘을 사용하고, 람다(lambda) 값을 조정하여 검색 성능을 향상시켰습니다.
- 람다 값은 코퍼스 전체 빈도와 문서 내 빈도의 가중치를 조절합니다.
Tokenizer 및 Analyzer 설정:
- 한국어 처리를 위해 nori analyzer를 사용했습니다.
- 사용자 정의 사전과 동의어 사전을 추가하여 인덱싱과 검색 시 언어적 특성을 반영했습니다.
검색 및 재순위화(Reranking)
하이브리드 검색(Hybrid Retrieval):
- 스파스 검색(BM25)과 밀집 벡터 검색(Dense Retrieval)을 결합하여 검색 성능을 향상시켰습니다.
ColBERT 모델 적용:
- ColBERT를 추가하여 문서의 세부적인 토큰 수준의 매칭을 강화했습니다.
- nbits 설정을 통해 인덱싱 효율성과 검색 성능 간의 균형을 맞췄습니다.
재순위화(Reranking):
- Cross-Encoder 모델을 활용하여 상위 문서에 대한 재순위화를 수행했습니다.
- bongsoo/klue-cross-encoder-v1 모델을 사용하고, 파인튜닝하여 성능을 향상시켰습니다.
LLM을 활용한 문서 선별
LLM을 활용하여 검색된 상위 문서 중에서 최종적으로 사용자 질문에 가장 적합한 문서를 선택했습니다.
- 프롬프트 엔지니어링을 통해 LLM이 원하는 출력 형식을 유지하도록 설계
- 예를 들어, 문서의 id 리스트만 반환하도록 지시하여 일관성을 확보
결과 및 성과
리더보드 성적
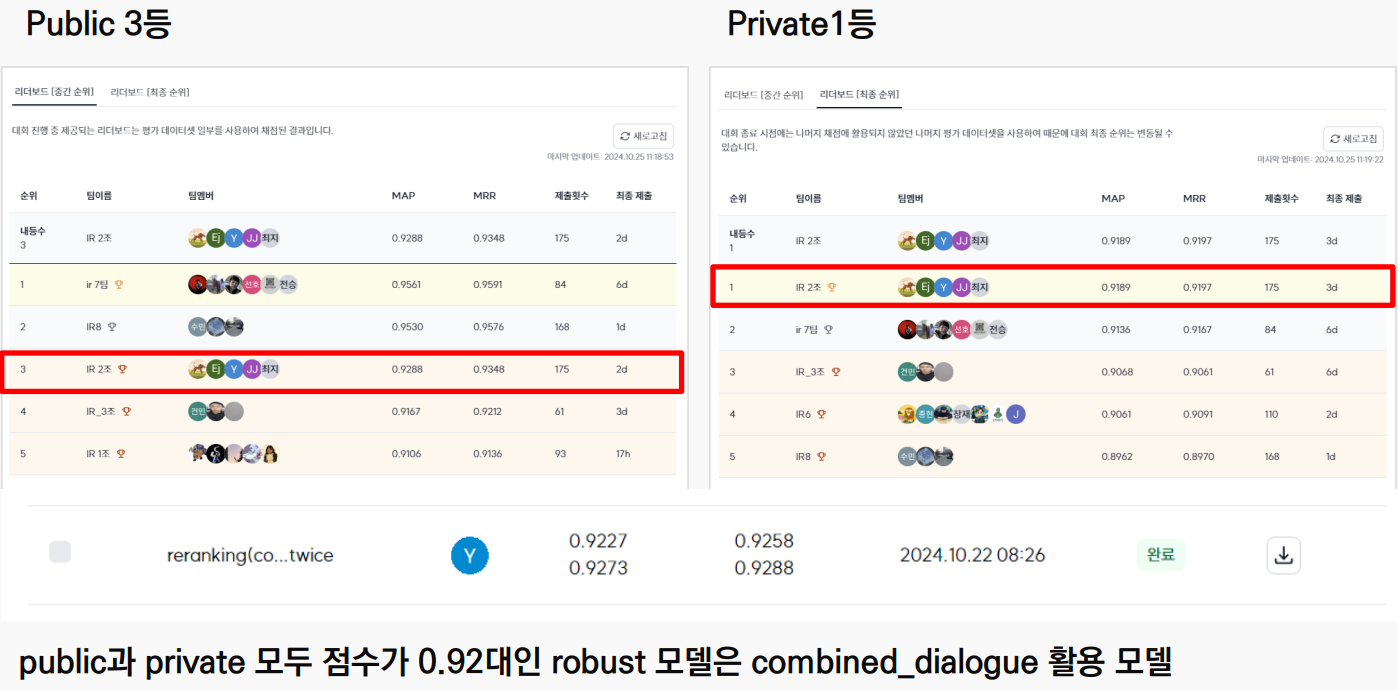
- Public 리더보드: 최종적으로 3위를 기록했습니다.
- Private 리더보드: 최종적으로 1위를 달성했습니다.
- 최종 MAP 점수: 0.9288
인사이트
- 다단계 접근법의 효과성: 데이터 전처리부터 검색, 재순위화, 그리고 LLM의 활용까지 이어지는 다단계 접근법이 전체적인 성능 향상에 크게 기여했습니다.
- 협업의 중요성: 팀원 간의 긴밀한 협업과 실험 결과의 공유를 통해 빠른 문제 해결과 성능 향상을 이룰 수 있었습니다.
- 현실적인 제약 사항 고려: 성능 향상을 위해 복잡도를 무작정 높이는 것보다는, 검색 시간과 시스템 자원 등 현실적인 제약 사항을 고려하여 효율적인 솔루션을 찾는 것이 중요했습니다.
회고
개인 소감
- 이윤재: Reranker의 우수한 성능에 놀랐으며, 프롬프트 엔지니어링의 중요성을 다시 한번 깨달았습니다.
- 장은지: 검색 성능과 검색 시간 사이의 균형을 맞추는 것이 어려웠지만, 다양한 실험을 통해 많은 것을 배웠습니다.
- 이재명: 챗봇을 어떻게 만들 수 있는지 조금 더 깊이 이해하게 되었습니다.
- 전백찬: 부트캠프의 시작과 끝을 RAG와 함께 보내서 의미 있었고, 팀원들과의 협업을 통해 성장할 수 있었습니다.
- 최지미: 서비스에 적용할 수 있는 기술을 직접 사용하고 학습할 수 있어서 좋았습니다.
마무리하며
이번 파이널 프로젝트를 통해 단순한 모델 개발을 넘어, 실제 서비스에 적용 가능한 시스템을 구축하는 경험을 할 수 있었습니다. 다양한 기술과 접근법을 시도하면서 얻은 인사이트는 앞으로의 커리어에도 큰 도움이 될 것이라 생각합니다. 함께 고생한 팀원들과, 도움을 주신 멘토님들께 감사의 말씀을 전합니다.
#패스트캠퍼스 #UpstageAILab #파이널프로젝트 #과학지식QA #정보검색 #RAG #팀프로젝트 #인공지능 #AI부트캠프
