[AI] 용어 정리
본 글에서는 A.I., Machine Learning 등에서 자주 쓰이는 용어 및 개념의 의미를 정리해두려고 한다. 보편적(다분히 주관적일 수 있음)으로 쓰인다 생각되는 용어들(특정 논문에서만 사용되는 개념이나 모델 등은 제외) 위주로 다루겠다. 간단히 설명할 수 있는 내용은 본 글에서 설명하고, 내용이 길어지는 것들은 따로 글을 분리해서 링크를 달도록 하겠다.
(생각나는 것이 있을 때마다, 추가할 예정)
Machine-learning? Deep-learning?
-
기계학습(Machine Learning)의 정의
기계 학습은 경험을 통해 자동으로 개선하는 컴퓨터 알고리즘의 연구이다. (중략)
기계 학습의 핵심은 표현(representation)과 일반화(generalization)에 있다. 표현이란 데이터의 평가이며, 일반화란 아직 알 수 없는 데이터에 대한 처리이다. (중략)
1959년, 아서 사무엘은 기계 학습을 "기계가 일일이 코드로 명시하지 않은 동작을 데이터로부터 학습하여 실행할 수 있도록 하는 알고리즘을 개발하는 연구 분야"라고 정의하였다.
wikipedia.org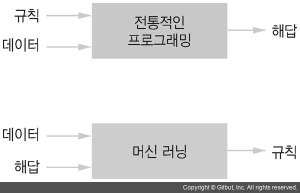
이미지 출처 : 텐서 플로우 블로그
-
딥러닝(Deep Learning)의 정의
심층 학습 또는 딥 러닝(deep structured learning, deep learning 또는 hierarchical learning)은 여러 비선형 변환기법의 조합을 통해 높은 수준의 추상화(abstractions, 다량의 데이터나 복잡한 자료들 속에서 핵심적인 내용 또는 기능을 요약하는 작업)를 시도하는 기계 학습 알고리즘의 집합으로 정의되며, (후략)
wikipedia.org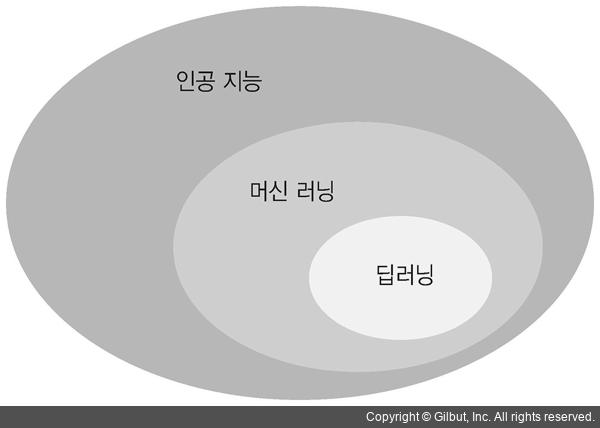
이미지 출처 : 텐서 플로우 블로그
-
아주 간단하게는 데이터와 해답으로 규칙을 찾아내는 알고리즘을 통틀어 기계 학습이라고 부르며, 각각의 기계학습 로직을 층층이 쌓은 것이 딥러닝이라고 할 수 있겠다.
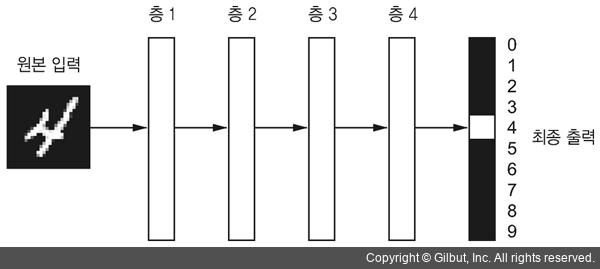
위 그림에서 층 하나에 해당하는 것이 기계학습, 전체 그림에 해당하는 것이 딥러닝이다. 물론, 딥러닝은 기계학습의 한 갈래이므로, 그 또한 기계학습이라고 표현할 수 있다. 하지만 층 하나가 딥러닝이 될 수는 없다.
이미지 출처 : 텐서 플로우 블로그 -
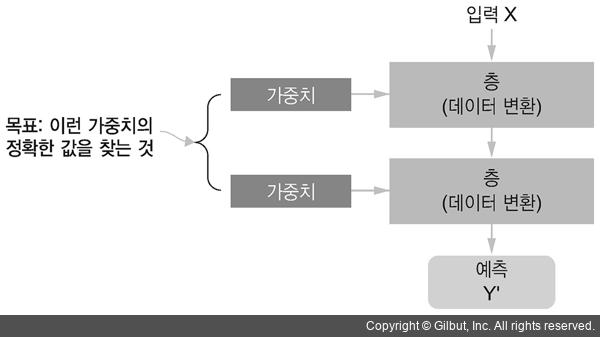
딥러닝이 수행하는 일은 입력과 예측 사이에 존재하는 함수의 가중치를 조정하는 일이다.
이미지 출처 : 텐서 플로우 블로그
Back-propagation
- 다른 글에서 설명
Class
- Label의 종류를 표현(e.g., 개&고양이 분류기의 class = ['개','고양이'])
- 보통 지도학습(Supervised learning)에서 입력되는 데이터는 label을 가지며, 학습모델이 데이터의 특성(feature)으로 label을 예측하도록 training 한다.
Classification(분류)
- 모델에서 데이터를 입력받아 출력 class 중 하나를 선택해 label을 예측하는 것이다.
Convolution(합성곱)
- CNN(Convolution Neural Network)에서 이미지의 feature를 뽑기 위한 연산으로 주로 사용됨.
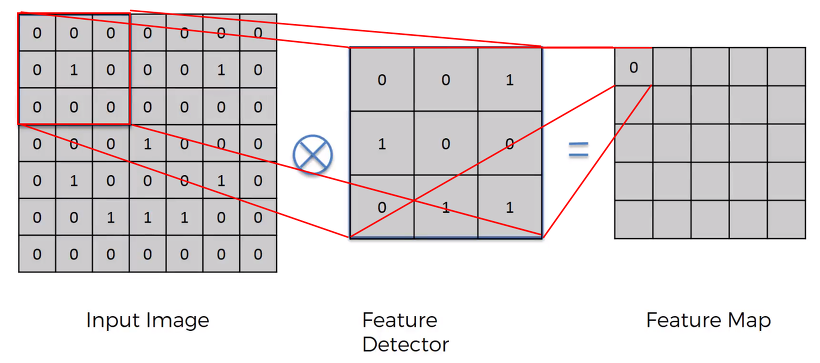
입력된 이미지에 필터(Feature Detector)를 합성곱하여 특성(Feature Map)을 추출하게 된다.
이미지 출처 : https://talkingaboutme.tistory.com/entry/DL-Convolution%EC%9D%98-%EC%A0%95%EC%9D%98
- 여러 단계의 Convolution을 거치면 원 이미지의 정보를 다수 소실하나(모든 픽셀이 다 중요한 것은 아니므로 크게 문제없음), 필터와의 합성곱으로 이미지가 가지던 특징은 보존된다. 정보가 소실되는 만큼 연산속도가 빨라진다는 장점도 존재한다.

위 그림과 같이 원이미지의 정보를 대다수 소실해도 윤곽 정보만으로 충분히 이미지를 식별할 수 있다.
이미지 출처 : https://talkingaboutme.tistory.com/entry/DL-Convolution%EC%9D%98-%EC%A0%95%EC%9D%98
- 상술한 바와 같이 Convolution Layer의 역할은 입력된 이미지에서 특성을 추출(때로는 강화)하는 것이다.
Cross-entropy
Dropout
Error
Feed-forward
- Feedback이 없거나, loop 연결을 가지지 않는 형태
Filter(=Kernel)
Fully-connected(=Dense)
-
앞서 본 다층 퍼셉트론은 은닉층과 출력층에 있는 모든 뉴런은 바로 이전 층의 모든 뉴런과 연결돼 있었습니다. 그와 같이 어떤 층의 모든 뉴런이 이전 층의 모든 뉴런과 연결돼 있는 층을 전결합층이라고 합니다. 줄여서 FC라고 부르기도 합니다.
즉, 앞서 본 다층 퍼셉트론의 모든 은닉층과 출력층은 전결합층입니다. 이와 동일한 의미로 밀집층(Dense layer)이라고 부르기도 하는데, 케라스에서는 밀집층을 구현할 때 Dense()를 사용합니다. 자세한 구현 방법은 뒤에서 배웁니다.
만약 전결합층만으로 구성된 피드 포워드 신경망이 있다면, 이를 전결합 피드 포워드 신경망(Fully-connected FFNN)이라고도 합니다.
-
feedforward라고 부르는 이유는, 학습의 정보의 흐름을 보시게 된다면 데이터 로 부터 시작되서, 함수 를 정의하고, 정의된 함수를 통해 output 인 를 산출하게 됩니다. 이 과정에서 feedback connection이 부제하게 됩니다. 이 feedback connection은 output이 모델에 스스로 feedback을 보내는 연결관계입니다. backpropagation과는 다른 의미입니다. 이는 후에 Recurrent Neural Net 에서 구현이 됩니다.
Gaussian 분포
Gradient Descent
- 다른 글에서 설명
Ground Truth(=Label)
- 데이터의 실제 값을 의미. 즉, 데이터 예측의 정답이 되는 정보
- 기상학에서 인공위성과 같이 지구에서 멀리 떨어져 지구를 관찰할 때의 모습과 실제 지면의 구조가 다른 데서 유래한 용어이다. 멀리서 관찰하면 넓은 시야를 가질 수는 있겠지만 빛이 구름이나 대기를 통과하면서 실제 모습이 왜곡된다. 이때 지상에서 직접 측정한 정보를 인공위성에서 참조한다면 보다 정확한 데이터를 얻을 수 있게 된다.
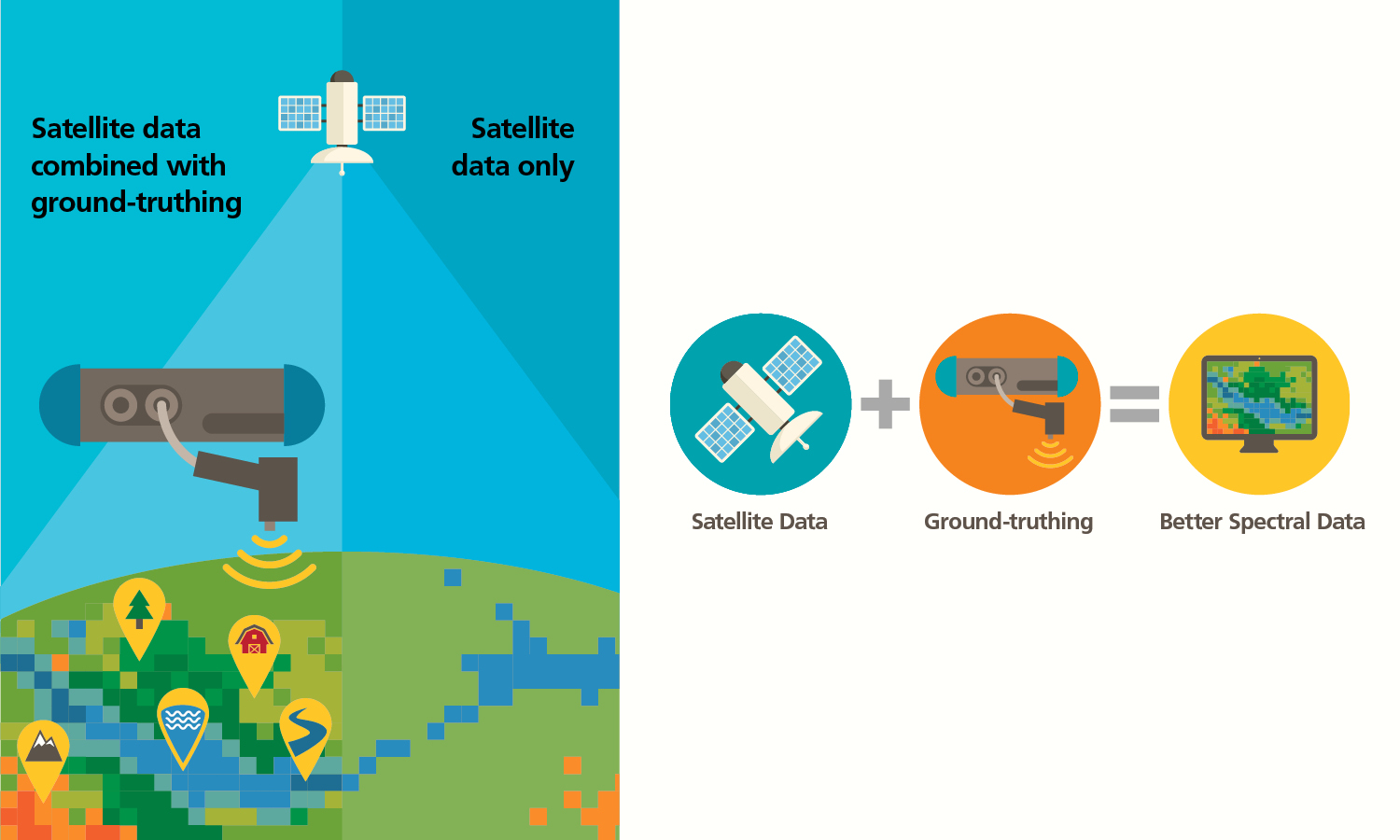
이미지 출처 : Malvern Panalytical
Layer
Loss
- 입력된 데이터가 머신러닝 모델을 거쳐 출력된 예측의 품질을 측정하는 척도이다. 이 점수를 피드백 신호로 사용하여, 손실 점수가 감소되는 방향으로 가중치 값을 조금씩 수정하게 된다.
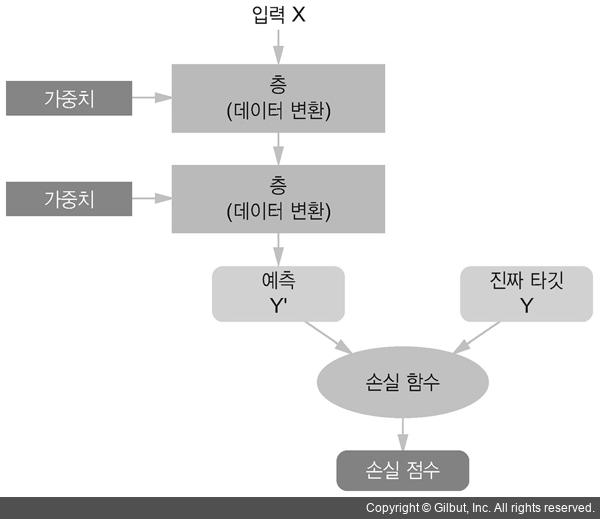
그림에서 손실 점수에 해당하는 것이 바로 Loss
이미지 출처 : 텐서 플로우 블로그
Loss Function
- 손실 점수(Loss)를 계산하는 함수이다. 예측된 label과 원 label을 입력으로 받아, 두 label 사이의 차이를 특정 공식을 통해 계산함으로써, 예측된 label의 성능(품질)을 측정하게 된다.
Cost Function
- Loss, Error, Cost 가 거의 비슷한 의미로 혼용되며, 사실상 같은 의미라고 생각해도 무방하다.
- 손실함수가 각각의 training case(단일 사례)에 대한 손실 점수를 계산하는 함수라면, 비용함수는 전체 training set에서의 비용을 계산하는 함수라는 정도의 느낌 차이만 가지면 된다.
종류
통계학적 모델은 일반적으로 회귀(regression)와 분류(classification) 두 가지 동류로 나뉜다. 이에 따라 비용 함수도 회귀에서 주로 쓰이는 것과 분류에서 주로 쓰이는 것, 두 가지로 나뉘게 된다.
회귀모델 비용함수
-
MAE(Mean Absolute Error, 평균 절대 오차)
-
MSE(Mean Squared Error, 평균 제곱 오차)★
-
RMSE(Root Mean Square Error, 평균 제곱근 오차)★
분류모델 비용함수
-
Binary Cross Entropy
-
Categorical Cross Entropy
Model
Network
- 일반적으로 서로 다른 함수들이 모여 모델을 표현하기 때문에 Network라는 표현이 사용된다. 이 모델은 일반적으로 directed acyclic graph로 표현이 됩니다. 예를 들면,이러한 체인 구조가 될 것입니다. 이러한 함수들이 depth를 가지고 존재하기 때문에 deep이라는 이름이 붙여지게 됩니다. 뉴럴넷을 학습시키면서 우리는 이 f(x)f(x)를 (x)에 근사시키고자 노력하게 됩니다.
Neuron
Overfitting
Parameter, Hyper Parameter
- 간단하게는 실험자가 직접 값을 조정할 수 없다면(e.g., hiddenlayer의 output) Parameter, 실험자가 직접 값을 조정할 수 있다면(e.g., learning rate) Hyper Parameter
- Parameter는 흔히 가중치(weight)와 같은 의미로 혼용되며(정확히는 딥러닝 모델의 어떤 층에서 발생하는 변환은 가중치값을 매개변수(=parameter)로 받는 함수의 표현이므로 parameter=가중치로 받아들여지는 것), 딥러닝에서 모델이 학습을 거듭하면서 최적화하는 대상임(e.g., CNN에서 filter(=kernel) matrix)
Pooling
- convolution을 거쳐서 나온 activation maps(=feature maps)이 있을 때, 이를 이루는 convolution layer를 resizing해서 새로운 layer를 얻는 것
- convolution이 행렬 연산에 의해 얻는 것이라면, pooling은 행렬 연산 없이 각 커널 맵에서 하나의 값을 뽑아내는 과정으로도 이해 가능
- overfitting을 방지하기 위함,
