어느덧, 천고마비의 계절이 돌아왔다. 그래서 그런지 시험준비를 해야하는 필자의 몸과 마음도 마비가 됐는지 도통 공부를 하기가 쉽지 않다. 각설하고 잘 움직이지 않는 몸을 움직여 이번 글도 적어나가도록 하겠다.
이전 시리즈에서는 Python 패키지를 활용해 시각화 코드를 작성하는 기본적인 방법에 대해서 다뤘다.
1편 - 시각화 코드 작성하기 by Python_pyplot
2편 - 시각화 코드 작성하기 by Python_seaborn
이번 글에서는 본격적인 EDA를 하기에 앞서 사용할 데이터셋을 전처리하는 과정에 대해서 다룬다. 우리는 아직도 본 게임은 시작도 못 하고 출발에 앞서 짐을 싸고 있는 상황이다. 백날천날 고심해서 짐을 싸도 여행지에 도착하면 왜 항상 빼놓은 짐이 있는가는 여전히 풀리지 않는 수수께끼다.
우리가 왜 데이터를 적당히 다듬은 후에야 분석을 진행해야 하는지를 아주 잘 설명한 격언이 있다. 쓰레기를 넣으면 쓰레기가 나온다(Garbage in, garbage out)인데, 이보다 더 데이터 전처리의 필요성을 강조할만한 문장은 없을 것 같다. 우리가 분석을 통해 얻고자 하는건 의미있는 인사이트지, 쓰레기가 아니므로 오래 걸리고 지루하며 반복적인 행위지만 전처리를 충실히 수행해야 한다.
먼저 간단하게 전처리 순서에 대해서 짚어보겠다. (누락된 과정이 있을 수 있으므로 현명하신 독자분들은 참고만 하시고 필요에 따라 추가적인 정보를 찾아보시기 바람)
- 데이터를 전체적으로 확인 및 이해
- 데이터의 타입 확인 및 변경
- 결측값, 이상값 확인 및 처리
1. 데이터를 전체적으로 확인 및 이해
세상에는 정말 다양한 데이터가 존재한다. 그 수만큼 데이터 셋의 구축 목적, 활용 등도 너무나 다양하기에 우리는 전처리를 하기에 앞서 해당 데이터셋을 파악하고 이해하려는 노력이 필요하다. 집 값에 관한 데이터처럼 어느정도 우리에게 친숙한 데이터들은 비교적 이해하기가 쉬운 편이다. 하지만 예를 들어 렌즈 생산 공정에 대한 데이터라고 했을 때, (관계자가 아니라면) 그 공정들에 대한 이해가 기반되지 않은 상태에서 분석한다는 것이 사실상 불가능하다. 또 데이터베이스를 직접 구축한 것이 아니라면, 날 것의 데이터베이스에서 변수명을 이해하는 것조차도 상당히 어려운 일이다. 우리가 앞으로 사용할 Kaggle 데이터셋의 경우에도 어느정도 가공된 상태의 데이터기에 앞 문장처럼 변수명을 이해하기 어려운 정도는 아니겠지만, 이러니 저러니 해도 가장 먼저 수행할 일은 데이터셋을 이해하려는 시도이다. 앞서 서술한 Kaggle 은 각 데이터셋마다 데이터를 설명하는 일종의 설명서들이 게시되어 있으니 해당 설명서를 읽어보며 데이터를 파악하면 된다. (혹여 필자처럼 데이터베이스에서 날 것의 데이터들을 가져와 분석하게 될 경우, 해당 데이터베이스 구축자 또는 관련 업무자와 끝없는 의사소통을 통해 파악해야 한다...)
독자분들의 이해를 돕기 위해 간단한 데이터셋을 사용하며 진행해보겠다. 이전에 사용했던 타이타닉 데이터셋을 다시 한번 이용해 볼텐데 이전과는 달리 Kaggle 데이터셋을 가져와 보도록 하겠다. 링크에서 train.csv 파일을 다운로드 하시고 이를 구글 드라이브에 업로드해서 Colab 에서 이용해보도록 하겠다. (업로드한 파일 이용하기)
import pandas as pd
import numpy as np이렇게 두 가지 패키지를 이용해서 진행해보겠다. 전처리는 scikit-learn 패키지를 이용해서도 많이 하지만 필자의 숙련도가 부족한 관계로 소개하지 않는 점 양해 바란다. 그리고 우리는 데이터셋의 전체적인 그림을 보기 원하므로 기존에 행과 열이 생략되는 것을 변경해주도록 하겠다.
# 열과 행 생략없이 보기 위한 설정
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)두번째 매개변수로 원하는 길이만큼의 숫자를 넣어주면 되는데 None 을 주면 길이 상관없이 모두 다 보겠다는 의미이다. 이 후에 데이터를 확인해보시면
# 드라이브에 업로드 된 파일 경로를 읽어오기 위한 코드
from google.colab import drive
drive.mount('/content/gdrive')
base_dir = '/content/gdrive/My Drive/Colab Notebooks/'
titanic = pd.read_csv(base_dir+'train.csv')titanic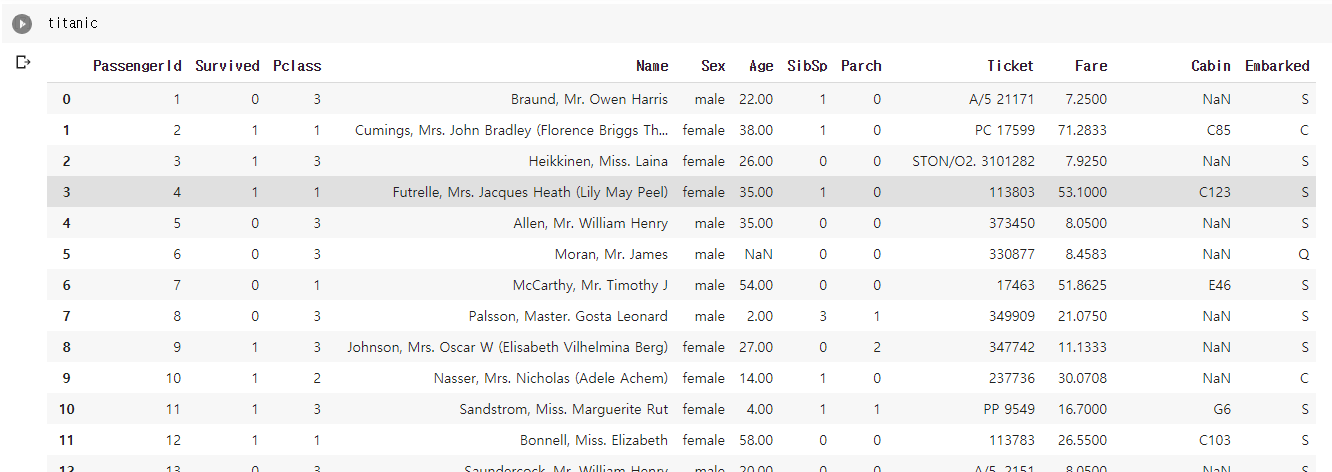
전체 데이터가 생략 없이 잘 나오는 것을 확인하실 수 있다. 지금 단계에서 우리가 할 일은 전체 데이터셋을 살펴보며 각 컬럼이 어떤 의미인지, 각 컬럼에 값이 어떤 식으로 들어가는지 등과 앞으로 우리가 어떤 방향으로 진행할지 등을 생각해보면 된다. Kaggle 데이터를 다운로드 받은 페이지에 보시면 각 변수의 의미, 어떤 값이 들어가는지 등이 잘 설명되어 있다. 앞서 말한 설명서가 바로 그것이다. 의미를 모르고 본다면 SibSp, Parch 와 같은 컬럼은 무슨 뜻인지 도통 알 길이 없다. 바로 그를 위해서 설명서를 읽거나 관계자에게 설명을 요청해야 하는 것이다.
2.데이터의 타입 확인 및 변경
# 각 컬럼의 타입과 입력된 데이터량 확인, verbose 옵션으로 생략 없이 모든 컬럼 확인
titanic.info(verbose=True)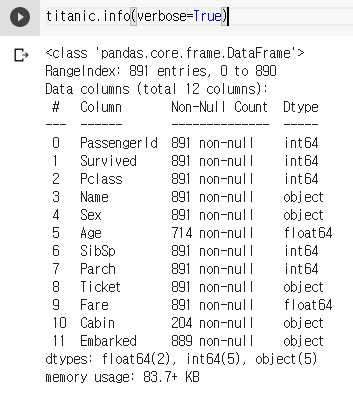
이렇게 .info() 메소드를 사용하면 각 컬럼의 타입과 결측된 값이 있는 행을 대략적으로 파악하는 등 큰 그림을 그려볼 수 있다. 해당 데이터셋에서는 사실 verbose 옵션을 주지 않아도 모든 컬럼이 출력된다. 하지만 데이터셋이 거대한 경우 (ex. 100개 이상의 컬럼) 에는 옵션을 주지 않을 경우 내용이 생략되니 참고하자.
해당 단계에서는 타입이 적당하지 않다고 생각되는 컬럼의 타입을 변경해주는 작업이 필요하다. 각 컬럼별로 한번 살펴보겠다. 먼저 PassengerId 컬럼은 정수형이다. 별 문제는 없겠지만 부여된 고유번호의 특성상 정수 연산이 필요하다거나 하는 경우는 없을 것이다. 또 각각의 Id가 유일하게 다뤄질 것으로 예상할 수 있기에 필자는 정수형보다 문자열 즉, object 형으로 다뤄지는 것이 낫다고 여겨진다.
titanic['PassengerId'] = titanic['PassengerId'].astype('object')이런 식으로 .astype() 메소드를 이용해 형변환을 해주면 된다.
이어서 보겠다. 다음 컬럼은 Survived 이다. 설명서를 보면 0=NO, 1=Yes 라고 되어있다. 이런 내용 또한 설명서를 읽지 않는다면 정확한 의미 파악이 어려울 수 있다. 이 컬럼도 정수형으로 그대로 다뤄도 크게 문제는 없겠지만, 0 또는 1 두 가지 값만 들어갈 것이고 컬럼의 의미를 따져봤을 때도 boolean 형으로 다루는 것이 나을거라 생각한다. 이런 필자의 판단이 정답이 아니므로 상황에 따라 취향에 따라 유연하게 적용하시기 바란다.
다음은 Pclass 컬럼이다. 어느 등급의 티켓을 가지고 탑승했는지를 나타내는 컬럼이다. 1,2,3등급으로 나누어져 있고 정수형이다. 해당 컬럼은 그대로 다뤄도 무방해 보인다.
Name 컬럼은 문자열로 다뤄야 할 것이다. object 자료형(=문자열)이므로 그대로 두자.
Sex 컬럼은 성별을 의미한다. 기존과 같이 문자열로 다뤄도 될 것이고 0과 1로 바꿔 정수형으로 다루어도 될 것이다 (머신러닝을 진행하는 경우 혹은 수치형으로 데이터를 이용해야 하는 경우에는 변환하는 것이 편함). 필자는 그대로 두고 진행하겠다.
Age 컬럼은 실수형으로 되어 있다. 나이에 소수점이 어디있느냐 정수로 다루면 되지 않느냐라고 생각하실 수도 있다. 설명서에는 1세 미만의 영아에 경우 소수점으로 표시한다고 설명되어 있다. 하지만 경우에 따라 나이를 범주형(ex. 10대, 20대 ...)으로 처리하는 경우도 있으니 이 또한 필요에 따라 취향에 따라 정수로 처리할지 범주를 두고 문자열로 처리할지 등을 결정하시면 된다. 필자는 마찬가지로 그대로 두고 진행하겠다.
SibSp 컬럼은 타이타닉에 탑승한 형제 및 배우자의 수를 의미한다. 이 또한 설명서에서 확인 가능하다. 어떤 형태로 쓰일지 가늠하기 어렵지만 정수형으로 두는 것이 마땅해 보인다.
Parch 컬럼은 타이타닉에 탑승한 부모 및 자녀의 수를 의미한다. 위와 같은 이유로 정수형으로 그대로 두겠다.
Ticket 컬럼은 티켓 번호를 의미하는데 각각의 티켓에게 부여된 고유번호 정도로 이해하면 될 것 같다. 데이터를 보면 아시겠지만 들어간 데이터들이 일관성이 없는 것으로 여겨진다. 판매처인지 뭔지 모를 문자열 뒤에 번호가 들어간 경우가 있고 덩그러니 번호만 있는 경우도 있다. 일단은 PassengerId 와 마찬가지로 고유번호는 object 자료형이 적합하다 생각되기에 형변환이 필요하지는 않겠다. 하지만 이후에 정확한 의미 파악이 된다면 적당한 방향으로 데이터들을 (일관성 있게) 수정해주면 되겠다.
Fare 컬럼은 화폐단위를 알 수 없지만 실수형 그대로 적당해 보인다.
Cabin 컬럼은 객실 번호로 보이는데 데이터를 잘 보시면 1등급 탑승객에게만 부여되었고 객실과 탑승객이 1:1 관계가 아닌 중복된 데이터가 있음을 확인할 수 있다. 그대로 object 로 다뤄야 함은 이견이 없지만 이후 결측치 처리 과정에서 어떻게 처리할지 고민해보아야 한다.
Embarked 컬럼은 탑승지를 의미하는 것으로 보인다. 세 곳의 탑승지가 있었고 각 탑승지의 첫글자만 입력된 것을 알 수 있다. Sex 컬럼과 마찬가지로 그대로 문자열로 두고 진행하겠지만 필요에 따라 수치형(ex. C=1,Q=2,S=3)으로 변경하는 것을 고려해 볼 만하다.
3. 결측값, 이상값 확인 및 처리
결측치의 경우는 앞 과정을 진행하면서 어느 정도 파악이 가능하다. 이상치의 경우는 좀 더 세부적인 확인 과정으로 검출해내야 한다.
방법론 소개에 앞서 타이타닉의 결측값을 확인해보겠다.
titanic.isna().sum()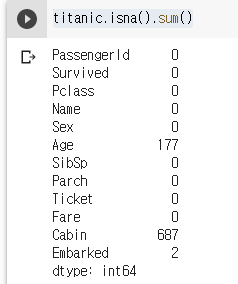
이 정도면 굉장히 깔끔한 데이터셋이 아닐 수 없다. 이렇게까지 결측값이 없을 수가 있다니... 이왜진;
3-1 결측값 처리
결측된 값은 크게 세 가지 방법 정도로 처리한다. 결측된 값이 포함된 레코드(=행)를 버리는 방법과 결측된 값을 다른 값으로 대체하여 채워 넣는 방법, 해당 과정에서는 처리하지 않고 추후 과정으로 넘겨 좀 더 상세히 살펴보는 방법이 그것이다. 그럼 각각의 경우를 살펴보겠다.
3-1-1 결측값 버리기
pandas 에서 .dropna() 메소드를 사용해 편리하게 수행할 수 있으며 다양한 옵션이 있으니 확인하고 사용하시기 바란다. 위 데이터에서는 전체 데이터가 891개 임을 감안할 때, Cabin 의 경우는 너무 차지하는 비율이 크기에 버리기 어렵고 Age 와 Embarked 가 결측된 데이터는 버리는 것을 고려할 수 있다. 이처럼 너무 비율이 크거나 쉽사리 버리기 어려운 경우 다른 전략을 세우는 것이 마땅하다.
3-1-2 결측값 대체하기
평균값(DataFrame.mean), 중위수(DataFrame.median)로 대체하는 것을 고려해볼 수 있고 경우에 따라 최빈값(DataFrame.mode)으로 변경하는 등 대체하는 방법은 아주 다양하다. 하지만 값을 대체하는 행위 자체가 분석 결과에 영향을 미치므로 아주 고심하여 결정해야 한다. 예를 들어 위와 같은 데이터에서 Cabin 의 최빈값으로 결측값을 대체하게 된다면 한 객실을 수백명의 사람이 사용하게 되는 재앙이 발생하는 것이다.
타이타닉 데이터에서는 대체하는 방법을 선택하도록 하겠다. Age 는 평균값으로 Embarked 는 최빈값으로 채워넣겠다.
titanic['Age'] = titanic['Age'].fillna(titanic['Age'].mean())
titanic['Embarked'] = titanic['Embarked'].fillna(titanic['Embarked'].mode()).bfill()문자열 데이터의 경우 단순히 .fillna() 메소드만 사용하면 정상적으로 데이터가 들어가지 않으니 뒤에 .bfill() 메소드를 붙여주어야 한다. Cabin 컬럼은 조금 특이한 방법으로 변경하겠다. 전체 데이터를 기존 객실번호에서 객실이 존재하는 갑판으로 변경해주는 것이다.(ex. C37 -> C) 결측된 값은 unknown 이라는 문자열로 대체하겠다.
cabin_list = ['A', 'B', 'C', 'D', 'E', 'F', 'T', 'G', 'Unknown']
def search_substring(big_string, substring_list):
for substring in substring_list:
if substring in big_string:
return substring
return substring_list[-1]
titanic['Deck'] = titanic['Cabin'].map(lambda x: search_substring(str(x), cabin_list))3-1-3 다음 과정으로 넘기기
말 그대로 해당 과정에서 결측값을 처리하지 않고 다음 과정으로 넘기는 것이다. 이후 과정에서 필요에 따라 채워넣거나 하는 방식으로 해결하게 되는데, 이것도 일종의 대체하기가 될 수 있겠다. 다만 앞서 소개한 것처럼 일괄적으로 처리하는 것이 아닌 각각의 row 에 대해서 특징을 파악하고 처리한다는 점에서 다르다.
3-2 이상값 처리
이상값도 명백하게 틀린 값이 있는가하면 일반적인 값을 벗어나 특이한 값(outlier)을 가지는 경우가 있다. 틀린 값의 경우에는 결측값을 처리하는 방법론과 같다. 하지만 결측값처럼 검출해내기가 쉬운 일이 아니다. 우리가 다루고 있는 타이타닉 데이터셋의 경우 891개의 데이터 밖에 없으므로 마음 먹으면 모든 데이터를 살펴보는 것이 가능하겠지만 거대한 데이터는 불가능하다는 것을 알 수 있다. 그래서 .query() 메소드를 수행해서 특정 기준을 가지고 검출해낼 수도 있을 것이고 다른 방법도 있을 수 있겠다. 예를 들면 Sex 컬럼에 woman 이라는 데이터가 있다고 해보자. 이 경우에는 틀린 값으로 판단하고 female로 변경해주어야 할 것이다.
titanic.query('Sex != "male" and Sex != "female"')위와 같은 코드로 두가지 경우를 벗어나는 데이터를 검출하여 수정해줄 수 있다. 이는 예시이며 이에 해당하는 데이터는 없으므로 안심해도 되겠다. 어떻든 틀린 값을 찾아냈다면 결측값과 마찬가지로 버리거나, 대체하거나, 다음 과정으로 넘기는 선택을 할 수 있다.
틀린 값과 다르게 우리가 보통 이상값이라고 하는 것은 outlier 라 불리우는 일반적인 범위를 벗어나는 값이다.

예를 들면 Fare 컬럼의 경우 평균이 32 정도이고 웬만한 데이터들은 100 아래에 존재한다. 하지만 최대값의 경우 512나 되는데 이 경우에는 물론 정말 해당 금액을 주고 표를 샀을 수도 있고 잘못 입력되었을 가능성도 있다. 어떻게 되었든 보통의 범위를 벗어나는 이상한 값임에는 이견이 없을 것이다. 이러한 이상값들의 경우 우리가 분석을 하는 과정에서 예기치 못 한 영향을 주거나 분석 결과에 좋지 않은 영향을 미치는 등, 악영향을 끼치므로 처리해야할 필요성이 있다.
이상치를 처리하는 방법은 크게 두 가지로 볼 수 있다. 이상치를 포함한 데이터를 버리거나 정규화를 통해 이상치의 영향을 최소화하는 방법이다. 정규화로는 Min-Max, Standard, Robust 등의 방법론이 있다. 글의 도입부에서 scikit-learn 패키지를 사용하지 않겠다 했지만 본 과정의 예시 코드는 해당 패키지를 사용할테니 양해바란다. 코드로 직접 짜는 것은 매우 번거로운 일이므로 좋은 패키지가 있다면 사용하자!
Min-Max 정규화는 특정 범위 안으로 값의 범위를 한정시키는 것이다.(ex. 100점 만점의 시험 결과를 10점 만점으로 변환하는 경우) 간단하고 직관적이지만 아주 극단적인 방식이기에 데이터의 분포가 잘 반영되지 않고 이상치의 영향을 크게 받는다는 단점이 있다. 아래와 같은 방식으로 사용할 수 있다.
from sklearn import preprocessing as pc
titanic[['Fare']] = pc.MinMaxScaler((0,10)).fit_transform(titanic[['Fare']])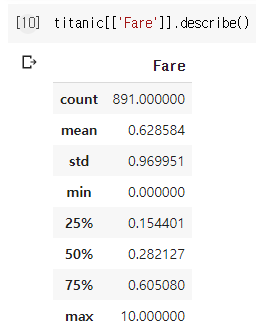
.MinMaxScaler() 메소드에 위와 같이 범위를 주게 되면 해당 범위 내로 정규화해준다.
Standard 정규화는 표준정규분포를 통해 어느정도 값의 분포가 반영되며 이상치의 영향도 비교적 덜 받게 된다. (위 코드에 이어서 쓰게 되면 기존 정규화된 값을 또 다시 정규화하는 꼴이니 런타임을 다시 시작하여 실행해보시길 권한다)
from sklearn import preprocessing as pc
titanic[['Fare']] = pc.StandardScaler(with_mean=False).fit_transform(titanic[['Fare']])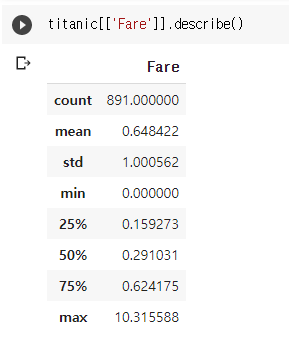
-1 부터 1 사이의 값으로 정규화되는 것을 막으려면 with_mean 옵션을 꺼주면 된다.
Robust 정규화는 IQR(Interquartile Range - 설명하는 글)값을 이용하는 정규화로 이상값에 꽤나 견고한 성질이 있다. (물론 이 또한 상대적으로 그렇다는 뜻이지 절대 완벽하다는 뜻은 아님) 이것도 위와 거의 유사한 코드로 처리할 수 있다.
from sklearn import preprocessing as pc
titanic[['Fare']] = pc.RobustScaler(with_centering=False).fit_transform(titanic[['Fare']])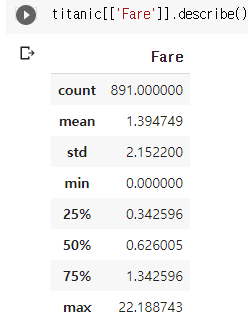
보시다시피 정규화 방식에 따라 데이터의 모양이 많이 다른 것을 확인할 수 있다. 역시 상황에 따라 정말 극단적인 이상값은 제거해주고 정규화를 이용한다면, 보다 쾌적한 데이터셋을 완성할 수 있을 것이다.
여기까지가 이번 글에서 다룰 내용이다. 본격적인 분석에 앞서 분석환경을 쾌적하게 만들어준 것이라 생각하면 될 것 같다. 시리즈의 3편이 되도록 준비과정만 다루고 있으니 이게 무슨 일인가 싶으시겠지만 EDA 라는게 정말 그렇다. 풍문으로는 데이터 수집과 전처리에만 80% 이상의 시간을 쏟는다고 하니 이해가 되시리라 믿는다. 사실 데이터 분석이라는 것에는 통계적 지식도 필요하고 데이터 관련 도메인 지식도 필요하다. 이렇게 야매로 진행하는 것이 많은 경우 불가능할 수도 있다. 하지만 모든 일에 처음은 있지 않겠는가. 분명 이근 대위도 근육 하나 없던 일반인 시절이 있었을 것이다.(태어날때부터 그런 근육 돼지였다면 너무 징그러울 것 같다) 그러니 부먹, 찍먹 고민 말고 쳐먹하도록 하자. 마지막으로 왜 데이터 설명서를 잘 읽어야 하는가를 필자보다 조리있게 설명해준 글이 있으니 첨부한다.
