COVID-19 유행과 함께 물러갔던 미세먼지가 북방 오랑캐들의 활동재개와 함께 귀신같이 돌아와버렸다. 공자도 영면에 듦으로써 착해졌다는 현인의 말씀이 생각나는 가을날이다. 본토의 전염병은 통제가능하며 감소추세라던 스폰지밥 애완 달팽이씨의 발표가 마냥 거짓이 아님을 확인할 수 있는 나날이다. 이런 발언이 불편하신 분들께는 심심한 사과의 말씀을 올린다. 하지만 쾌청한 가을 하늘을 볼 수 없다는 것은 정말 화나는 일이다. 각설하고 본론으로 들어가겠다.
우리는 지금까지 시각화 툴을 다뤄봤고, 본격적인 EDA에 앞서 전처리도 진행해봤다. 이제야 본격적으로 EDA를 진행할 때가 되었다. 사실 시리즈의 내용이 너무 미비하다 생각이 들어 추가할 내용이 무엇이 있을까 많이 고민해봤지만, 전처리까지 진행한 마당에 별 수 없이 본게임을 시작해야 된다고 판단했다. 이후에 부족함이 느껴지면 그때마다 새로이 배워 부족함을 채워보도록 하자. 무엇이 부족한지 알게 되는 것만으로도 충분히 유익할 것이다.
Done is better than perfect.
- Mark Zuckerberg -
지난 글까지도 계속 다뤘던 타이타닉 데이터를 이용해 EDA를 진행하고 인사이트를 도출해보도록 하겠다. 우선 전처리는 지난 글에서 다룬 것처럼 처리하면 된다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 열과 행 생략없이 보기 위한 설정
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
# 드라이브에 업로드 된 파일 경로를 읽어오기 위한 코드
from google.colab import drive
drive.mount('/content/gdrive')
base_dir = '/content/gdrive/My Drive/Colab Notebooks/'
titanic = pd.read_csv(base_dir+'train.csv')
titanic['Age'] = titanic['Age'].fillna(titanic['Age'].mean())
# 소수점은 보통 나이로 치지 않으므로 소수점 아래 버림
titanic['Age'] = np.trunc(titanic.Age).astype('Int64')
cabin_list = ['A', 'B', 'C', 'D', 'E', 'F', 'T', 'G', 'Unknown']
def search_substring(big_string, substring_list):
for substring in substring_list:
if substring in big_string:
return substring
return substring_list[-1]
titanic['Deck'] = titanic['Cabin'].map(lambda x: search_substring(str(x), cabin_list))
titanic.dropna(axis='rows', inplace=True, subset=['Embarked'])정규화는 따로 해주지 않는 선에서 전처리를 해주었다. 이제 데이터를 하나씩 뜯어보며 해석하면 된다. (끄덕) 그것이 E.D.A 이니까.
for col in titanic.columns:
if titanic[col].dtypes == 'object':
sns.countplot(x=col, data=titanic)
plt.xlabel(col)
plt.show()
else:
sns.boxplot(data=titanic[col])
plt.xlabel(col)
plt.show()위의 코드로 object 타입을 가지는 열 데이터는 막대 그래프로, 그 외 데이터들은 박스 플롯으로 분포를 확인할 수 있다. 나타나는 그래프의 모양이 이쁘지 않아 각 feature 들을 하나씩 살펴보기로 하자.
먼저 PassengerId 컬럼은 각 승객별 Id 이므로 굳이 살펴볼 필요는 없어 보인다.
sns.countplot(x = titanic['Survived'])
plt.show()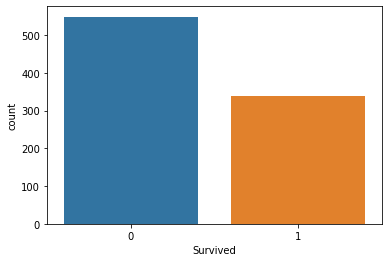
Survived 컬럼의 countplot 을 보아하니 이 비극의 여객선에서는 살아남은 사람보다 그렇지 못 한 사람들이 더 많다는 것을 알 수 있다.
sns.countplot(x = titanic['Pclass'])
plt.show()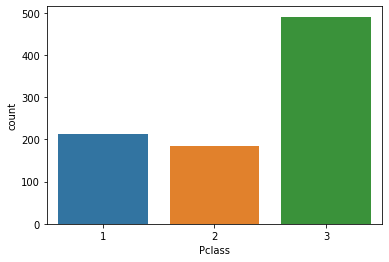
승객등급을 확인하니 3등급 승객이 가장 많은 것은 당연해 보이지만, 특이하게 1등급 승객이 2등급 승객보다 많음을 알 수 있다. 이 정보를 통해 호화여객선임을 고려할 때, 1등급 승객이 더 많았겠구나라는 추측을 할 수 있게 해준다. 이런 단편적인 정보들 하나하나는 그리 중요치 않지만 이러한 정보 여럿을 모아서 의미있는 직관을 제시하는 것이 우리가 할 일이다.
Name 컬럼 또한 살펴보기 용이치 않고 크게 의미있는 정보를 얻기 어려워 보이므로 건너뛰도록 하겠다.
sns.countplot(x = titanic['Sex'])
plt.show()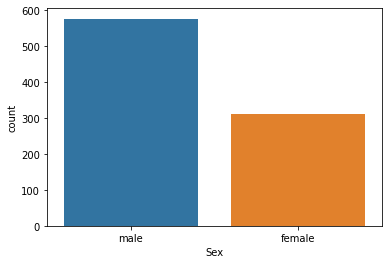
성비는 남성의 비율이 압도적으로 높다. 이렇다 해석할 여지가 당장 보이지는 않지만 어떻게 연계할 방법이 있을 수도 있으니 일단 머릿속에 담아두도록 하자.
sns.boxplot(data =titanic[['Age']])
plt.show()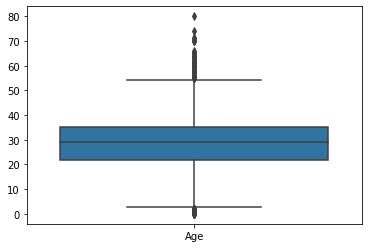
Age 컬럼은 boxplot으로 보았다. 익숙치 않은 분들을 위해 boxplot의 해석 방법을 링크 걸어두도록 하겠다. 대다수가 20~30대에 몰려있음을 알 수 있고 어린아이들과 50대까지의 인원이 다수 탑승했음을 알 수 있다. 5세가 채 안 되는 영아는 극소수이며, 생후 1년도 안 된 갓난아이도 있음으로 보여진다. 60세 이상의 노년도 많지 않고 탑승자 중 최고령자는 80대이었음을 알 수 있다. 단독으로 활용할 수도 있을테고 '나이에 따른 생존률'과 같이 활용하는 방법도 있겠다. 나이는 언제나 유용한 데이터다.
sns.boxplot(data =titanic[['SibSp', 'Parch']])
plt.show()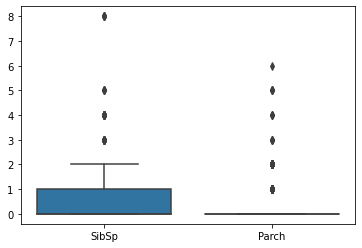
SibSp 컬럼과 Parch 컬럼은 데이터 스케일이 비슷하므로 함께 살펴보도록 하겠다.
SibSp 컬럼은 몇 명을 제외하면 2 이하임을 알 수 있다. 배우자와 형제의 수를 더한 컬럼이므로 큰 값이 들어갈 수 없음이 당연하다 여겨진다. 정말 놀랍게도 8명과 함께 탑승한 사람이 존재하는데 배가 침몰했음을 봤을 때, 집안의 큰 비극이지 않았을까 싶다.
Parch 컬럼이 조금 의아하다. 극소수의 인원만이 부모 혹은 아이들과 함께 탑승했는데, 우리가 위에 살펴본 Age 컬럼에서는 20대 미만의 인원이 적지 않음을 알 수 있다. 이 정보를 조합했을 때, 나이가 어리지만 부모가 함께 탑승하지 않은 경우가 꽤 많다고 추측할 수 있겠다.
Ticket 컬럼은 입력된 데이터 포맷도 제각각이고 의미있는 해석이 불가해 보이므로 건너뛰도록 하겠다.
sns.boxplot(data =titanic[['Fare']])
plt.show()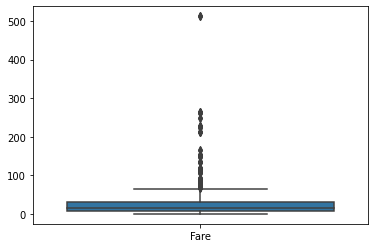
Fare 컬럼도 특이하다. 대다수가 50 근처 혹은 그 아래에 위치하고 대다수는 100이 채 되지 않는다. 그렇다면 1등실 승객도 100이 안 되는 가격에 탑승이 가능했음을 알 수 있다. 그럼에도 불구하고 몇몇 인원은 100을 넘기도 하고 심지어는 500을 넘게 지불하고 탑승한 인원도 있다. 무슨 이유였을지 파악은 어렵다.(나무위키에 따르면 1등실 위에 추가 요금을 징수하는 특별실이 있었다고 함) 분포가 다양한 것을 보아하니 정해진 요금표가 없던 것이 아닐까싶을만큼 제각각이다.
sns.countplot(x=titanic['Embarked'])
plt.xlabel('C = Cherbourg, Q = Queenstown, S = Southampton')
plt.show()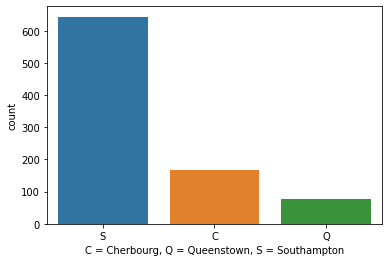
Embarked 컬럼을 countplot 으로 그리면 각 정박지에서 몇 명의 승객이 탑승했는지 확인이 가능하다.
가장 많은 승객이 탑승한 곳은 Southampton(사우샘프턴)으로 영국 남부의 도시이다. 영국의 배임을 봤을 때, 어찌보면 당연한 일이다.
다음 기항지인 Cherbourg(셰르부르)는 프랑스 북부의 도시이다.
미국으로 출발 전 마지막 기항지는 아일랜드 지역의 Queenstown(퀸스타운)이라는 곳이었지만, 현재는 명칭이 Cobh(코브)로 바뀌었다고 한다.
따라서 항로는 다음과 같다. 사실 데이터 분석과는 아무런 상관이 없는 정보이지만, 필자의 호기심으로 한번 첨부해보았다.
특정 지역에서 탑승하는 승객들의 평균적인 재력 등으로 조합해 볼 수 있겠다.
sns.countplot(x=titanic['Deck'])
plt.show()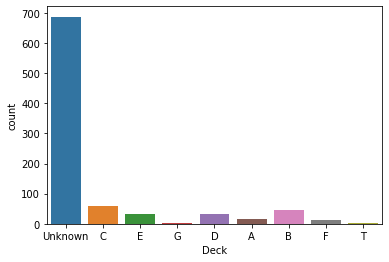
Cabin 컬럼을 활용해 직접 만들어준 Deck 컬럼의 countplot 이다. (나무위키 층별 구조 참고)
객실 위치 별로 생존율을 구해볼 수 있겠지만 객실 위치가 누락된 데이터가 너무 많기에 어려움이 있어보인다.
데이터를 각각 살펴보았으니 이제 조합해서 의미를 분석해야한다. 그냥 모든 경우의 수대로 조합하는 방식도 있겠지만, 비효율적이고 의미분석이 불가능한 경우의 수도 있다. 따라서 어느정도 가설을 세우고 해당 가설을 검증해보는 식으로 확인을 해보는 방법을 추천한다.
필자는 1등실 승객일수록 생존율이 높았을 것으로 예상해보았다. 객실의 위치도 쾌적한 곳에 위치하려면 아무래도 탈출에 용이한 위치였을 것이라 추측했고, 선원들이 1등실 승객들을 가장 먼저 케어했을 것으로 예상할 수 있기 때문이다. 그럼 확인해보도록 하자.
sns.countplot(x='Pclass', hue='Survived', data=titanic)
plt.show()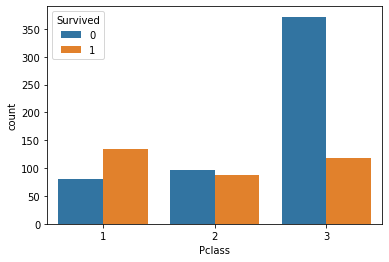
예상대로 1등실 승객이 가장 높은 생존율을 기록했고 2등실 3등실 순으로 생존율이 급락하는 것을 확인할 수 있다.
Pclass 와 Sex 컬럼을 연결해서 볼 수도 있을 것이다. 남성이 신체 조건이 유리하니 재난 상황에서 생존율이 더 높다 가설을 세우거나, 혹은 여성과 아이가 먼저 대피하도록 배려받은 상황이라면 여성의 생존율이 더 높다 가설을 세워볼 수도 있겠다. 그럼 한번 데이터를 확인해보자.
sns.countplot(x='Sex', hue='Survived', data=titanic)
plt.show()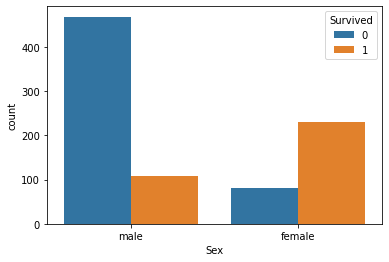
여성의 경우 생존자의 비율이 상당히 높은데, 남성은 압도적인 수치로 생존율이 낮음을 알 수 있다. 따라서 데이터로만 봤을 때는 여성의 대피가 먼저 이루어졌다고 짐작해 볼 수 있겠다.
EDA라 하기에는 다소 부족한 글이지만, 이만 줄이려고 한다. 이런식으로 진행할 수 있다 정도의 가이드를 진행한 것이라 생각해주시면 되겠다.
인사이트 도출은 꽤나 어려운 일이지만 특별한 방법론 따위는 없다고 보여진다. 그저 데이터를 계속해서 들여다보고 이해를 통해 인과관계 혹은 상관관계 등을 파악하고 주관을 섞어 합리적인 의견을 제시하기 위해 무던히 노력하는 수 말고 왕도가 없기에 많은 경험을 해보고 직관을 키우도록 하자.
이런 빈약한 지식만으로는 가이드라인 없이 홀로 EDA를 진행하기 어려워하실 분들도 있을 것이다. 하지만 모든 일이 그렇다. 어느 정도의 사전지식은 분명 필요한 것이지만 실전 경험이 없는 지식은 무용하다. 그렇기에 혹시라도 이 글을 읽으실 독자분들은 조금 부족하다 여겨져도 여러 데이터를 다뤄보며 본인만의 프로세스를 가다듬기 바란다. 마지막으로 필자보다 훨씬 고품질의 EDA를 진행한 노트북을 공유하며 마무리하겠다. 해당 링크는 EDA 후에 머신러닝까지 진행하는 내용이니 그 점은 참고하시길 바란다.
