렌더링 이전..우리가 어떤 웹페이지에 접속하려면?
렌더링이 일어나기 전, 웹서비스는 전 세계에 퍼져있는 웹 서버에 접속해서 웹 서버에 있는 문서를 요청하여 받아온다.
이 때 “어느 서버에 어떤 문서인지” 위치를 나타내는 방법이 있어야 하는데, 이 방법이 바로 URL(Uniform Resource Location) 이다.
URL이란?
- 인터넷 상에서 특정 자원의 고유한 위치를 표현하는 방법
- URL의 구조
- 프로토콜 종류 + 서버주소 + 폴더 + 파일 이름으로 구성

HTTP 프로토콜 사용해서 웹 브라우저가 웹 서버에서 문서를 가져오는 법
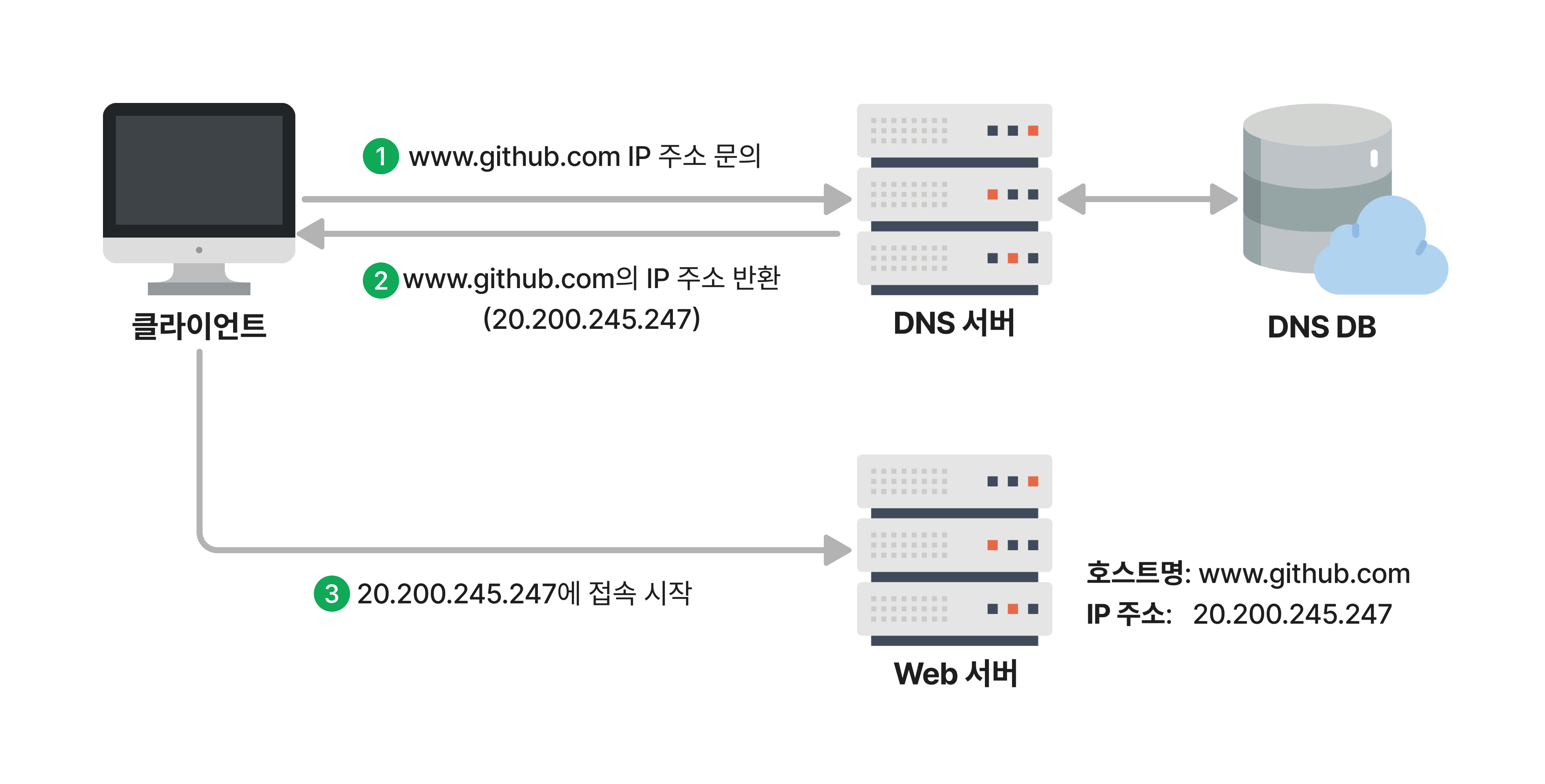
①,② 주소 변환
인터넷 서비스는 실제 프로토콜 레벨에서는 IP 주소를 사용하고, 사용자가 서비스를 이용할 때는 도메인명을 사용한다. 따라서 도메인 주소로부터 IP 주소로의 변환이 필요하다.
DNS(Domain Name Server) 서버는 전화번호부처럼 모든 도메인명과 대응되는 IP 주소에 대한 데이터베이스를 갖고, 도메인으로부터 IP 주소를 변환해준다.
DNS (Domain Name Server)
- 인터넷 도메인명과 IP 주소를 대응시켜주는 대규모의 분산 시스템
nslookup google.com,dig any google.com,host google.com,ping google.com -c 1등의 명령어를 통해 도메인으로부터 IP 주소를 얻을 수 있다.
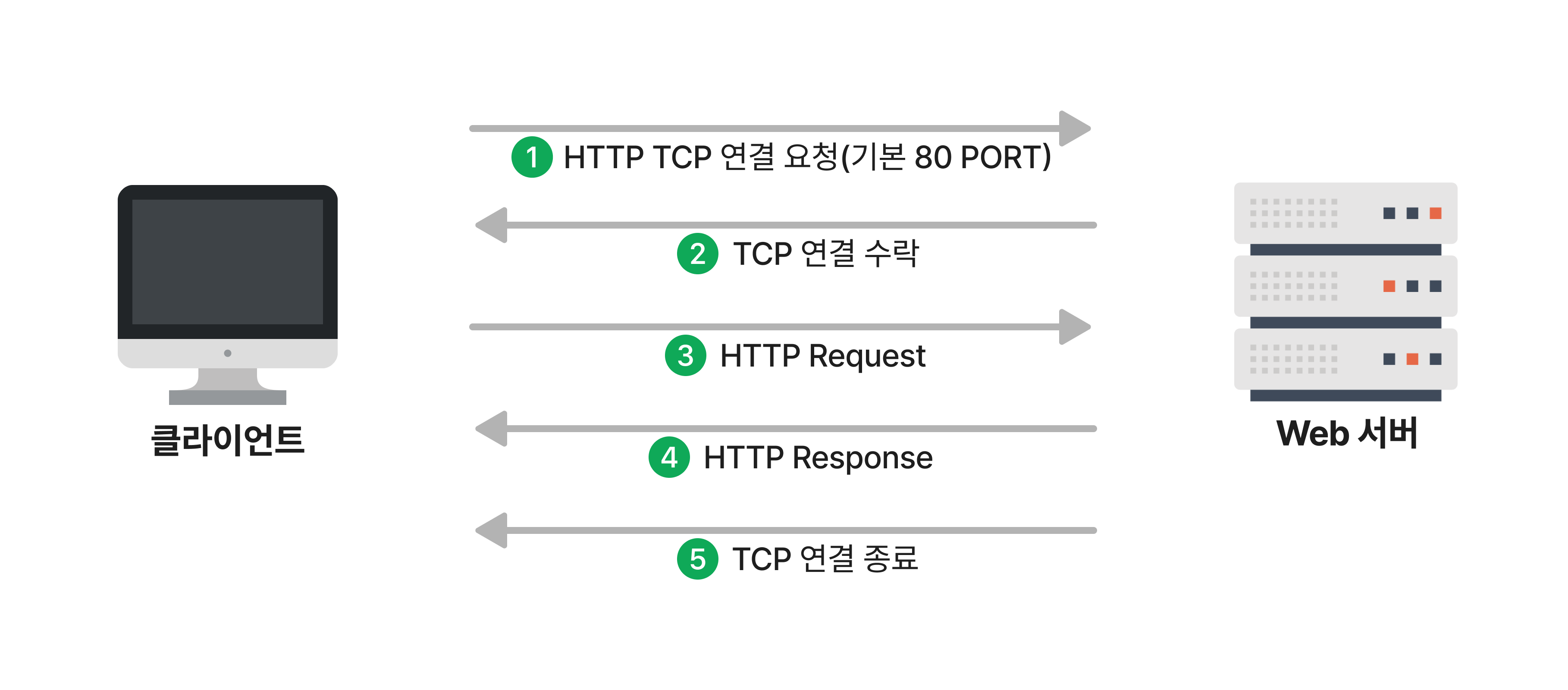
③ 실제 웹 문서 요청, 전송
-
웹 브라우저는 응답받은 IP 주소에 포트 80번(HTTP)으로 TCP 연결을 요청
-
TCP 연결 수락
-
클라이언트는 설정된 연결을 이용해 www.github.com 서버에 ‘/sasha1107/TIL/blob/main/README.md’를 요청(HTTP Request)
-
www.github.com 서버는 해당 README.md 파일을 클라이언트에게 전송(HTTP Response)\
-
TCP 연결을 해제 (사용하지 않을 땐 연결을 해제)
-
/sasha1107/TIL/blob/main/README.md를 수신한 웹브라우저는 이 문서의 내용을 브라우저 창에 보여줌(렌더링)
HTTP(HyperText Transfer Protocol) 프로토콜의 특징
- TCP 연결 방식을 사용한다
- 상태를 유지하지 않는 stateless 방식이다
- 요청했던 디바이스 전혀 기억, 기록하지 않는다.
- 누군지 구분 안하고 달라고하면 무조건 Response
❓ Stateless 접속이기 때문에 웹 서버는 내가 이전에 접속했었는지 아닌지를 모르는데 어떻게 로그인 상태를 유지할 수 있을까?
→ 🍪쿠키 & 세션
(stateless 환경을 state로 만들기 위한 도구)
렌더링 과정
파싱(Parsing)
HTML 파싱
-
토큰화된 코드를 구조화하는 과정
-
어휘분석기를 통해 토큰화된 코드가 생성
→ 파서가 해석그렇다면 컴퓨터의 입장에서 HTML 문서를 파싱하는 과정을 들여다보자👀
3c21444f43545950452068746d6c3e0a3c68746d6c206c616e673d226b6f223e0a3c686561643e0a202020203c6d65746120636861727365743d225554462d38223e0a202020203c6d65746120687474702d65717569763d22582d55412d436f6d70617469626c652220636f6e74656e743d2249453d65646765223e0a202020203c6d657461206e616d653d2276696577706f72742220636f6e74656e743d2277696474683d6465766963652d77696474682c20696e697469616c2d7363616c653d312e30223e0a202020203c7469746c653e446f63756d656e743c2f7469746c653e0a3c2f686561643e0a3c626f64793e0a20202020202020203c68313eec8898ed9884ec9db4ec9d9820ebb894eba19ceab7b83c2f68313e0a20202020202020203c756c3e0a2020202020202020202020203c6c693e48544d4c3c2f6c693e0a2020202020202020202020203c6c693e4353533c2f6c693e0a20202020202020203c2f756c3e0a202020203c666f6f7465723e636f7079726967687420eca095ec8898ed98843c2f666f6f7465723e0a3c2f626f64793e0a3c2f68746d6c
다음과 같은 16진수 코드가 있다. 우리가 HTML 문서를 작성할 때 맨 위에 <meta charset="UTF-8"> 을 항상 적어줬던 것을 떠올려보자. UTF-8로 인코딩된 코드를 다시 디코딩하여 파싱해보도록 하자.
- 디코딩 과정
import codecs
string = "3c21444f43545950452068746d6c3e0a3c68746d6c206c616e673d226b6f223e0a3c686561643e0a202020203c6d65746120636861727365743d225554462d38223e0a202020203c6d65746120687474702d65717569763d22582d55412d436f6d70617469626c652220636f6e74656e743d2249453d65646765223e0a202020203c6d657461206e616d653d2276696577706f72742220636f6e74656e743d2277696474683d6465766963652d77696474682c20696e697469616c2d7363616c653d312e30223e0a202020203c7469746c653e446f63756d656e743c2f7469746c653e0a3c2f686561643e0a3c626f64793e0a20202020202020203c68313eec8898ed9884ec9db4ec9d9820ebb894eba19ceab7b83c2f68313e0a20202020202020203c756c3e0a2020202020202020202020203c6c693e48544d4c3c2f6c693e0a2020202020202020202020203c6c693e4353533c2f6c693e0a20202020202020203c2f756c3e0a202020203c666f6f7465723e636f7079726967687420eca095ec8898ed98843c2f666f6f7465723e0a3c2f626f64793e0a3c2f68746d6c3e"
binary_str = codecs.decode(string, "hex")
string = str(binary_str, 'utf-8');- 디코딩 결과
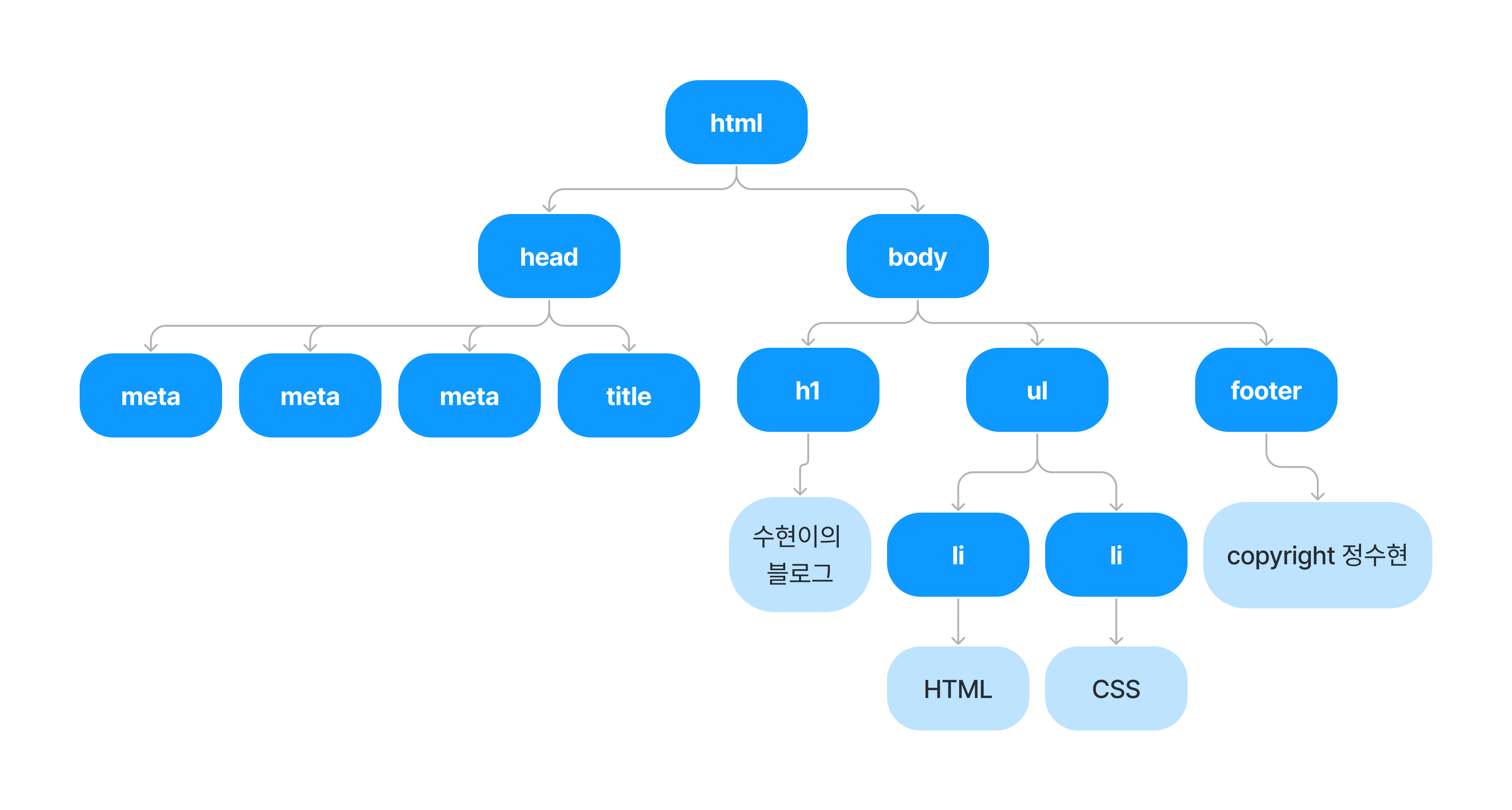
<!DOCTYPE html> <html lang="ko"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <h1>수현이의 블로그</h1> <ul> <li>HTML</li> <li>CSS</li> </ul> <footer>copyright 정수현</footer> </body> </html> - 파싱 맛보기
from html.parser import HTMLParser
import codecs
string = "3c21444f43545950452068746d6c3e0a3c68746d6c206c616e673d226b6f223e0a3c686561643e0a202020203c6d65746120636861727365743d225554462d38223e0a202020203c6d65746120687474702d65717569763d22582d55412d436f6d70617469626c652220636f6e74656e743d2249453d65646765223e0a202020203c6d657461206e616d653d2276696577706f72742220636f6e74656e743d2277696474683d6465766963652d77696474682c20696e697469616c2d7363616c653d312e30223e0a202020203c7469746c653e446f63756d656e743c2f7469746c653e0a3c2f686561643e0a3c626f64793e0a20202020202020203c68313eec8898ed9884ec9db4ec9d9820ebb894eba19ceab7b83c2f68313e0a20202020202020203c756c3e0a2020202020202020202020203c6c693e48544d4c3c2f6c693e0a2020202020202020202020203c6c693e4353533c2f6c693e0a20202020202020203c2f756c3e0a202020203c666f6f7465723e636f7079726967687420eca095ec8898ed98843c2f666f6f7465723e0a3c2f626f64793e0a3c2f68746d6c3e"
binary_str = codecs.decode(string, "hex")
string = str(binary_str, 'utf-8');
class MyHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
print("Encountered a start tag:", tag)
def handle_endtag(self, tag):
print("Encountered an end tag :", tag)
def handle_data(self, data):
print("Encountered some data :", data)
parser = MyHTMLParser()
parser.feed(string)- 파싱 결과
Encountered some data :
Encountered a start tag: html
Encountered some data :
Encountered a start tag: head
Encountered some data :
Encountered a start tag: meta
Encountered some data :
Encountered a start tag: meta
Encountered some data :
Encountered a start tag: meta
Encountered some data :
Encountered a start tag: title
Encountered some data : Document
Encountered an end tag : title
Encountered some data :
Encountered an end tag : head
Encountered some data :
Encountered a start tag: body
Encountered some data :
Encountered a start tag: h1
Encountered some data : 수현이의 블로그
Encountered an end tag : h1
Encountered some data :
Encountered a start tag: ul
Encountered some data :
Encountered a start tag: li
Encountered some data : HTML
Encountered an end tag : li
Encountered some data :
Encountered a start tag: li
Encountered some data : CSS
Encountered an end tag : li
Encountered some data :
Encountered an end tag : ul
Encountered some data :
Encountered a start tag: footer
Encountered some data : copyright 정수현
Encountered an end tag : footer
Encountered some data :
Encountered an end tag : body
Encountered some data :
Encountered an end tag : html-> 이런식으로 HTML 코드를 파싱하고 이를 바탕으로 DOM 트리를 생성한다.
HTML 파싱
<script>나<link>와 같은 외부 태그를 만나면 HTML 파싱을 즉시 중단- 스크립트 태그 안 자바스크립트 코드가 DOM 구조를 변환할 수 있기 때문이다.
- 파싱 중간에 외부 요인으로 인해 DOM이 추가, 변경, 삭제되는 경우 HTML은 파싱을 처음부터 재시작(Reentrant)
- DOM(Document Object Model) 트리 생성
- HTML 엘리먼트로 이루어진 트리
CSS 파싱(스타일 계산)
- HTML을 파싱하는 도중에 CSS 파싱이 시작됨
- 네트워크를 통해 먼저 받아온 코드부터 해석을 실행할 수 있는 HTML 파서와 달리, CSS 파서는 전체 파일을 다운로드 할 때까지 파싱을 시작할 수 없다.
- CSS 파싱의 결과로 CSSOM(CSS Object Model) 트리가 구성됨
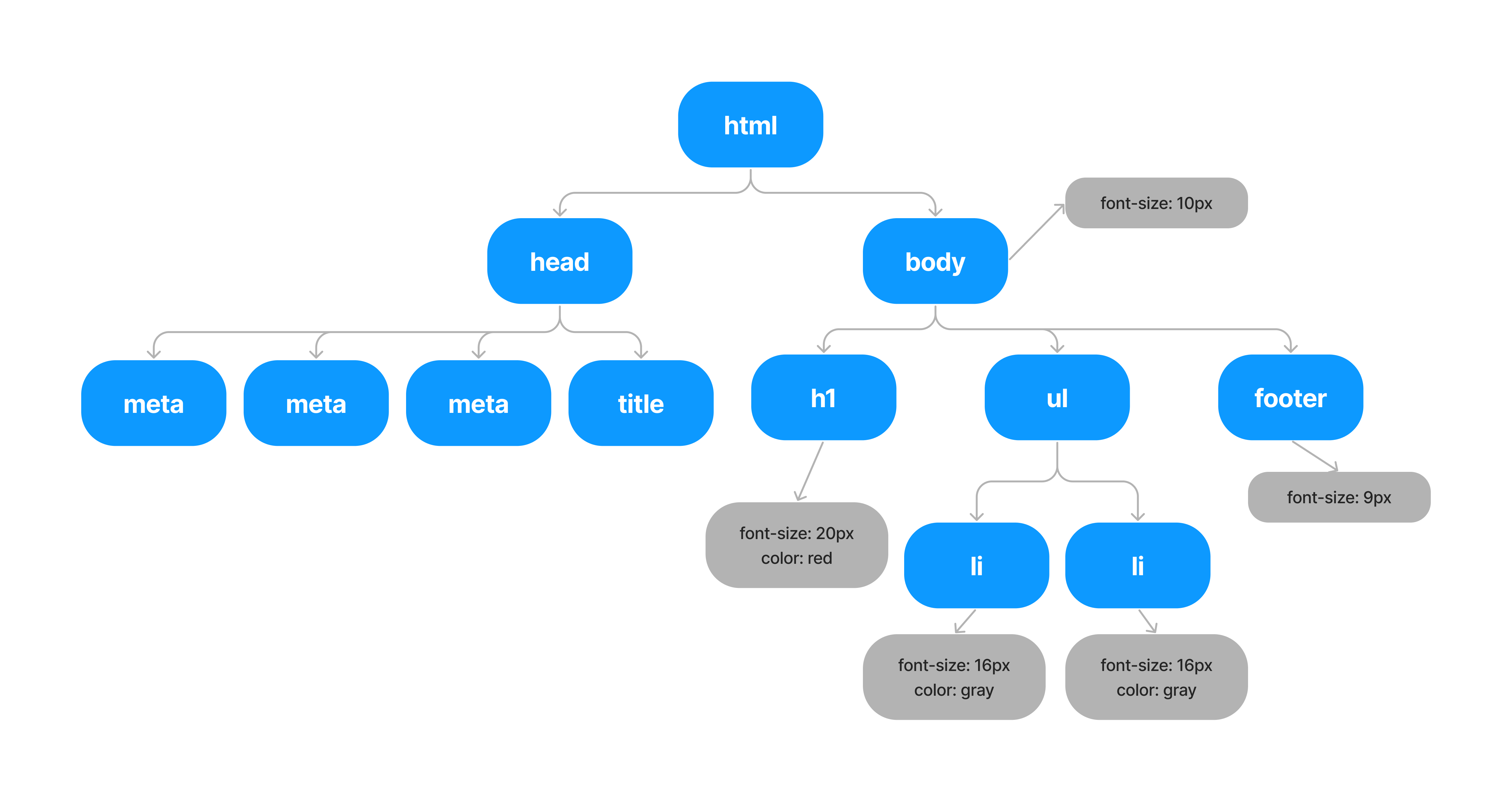
렌더트리 구성(Render Tree)
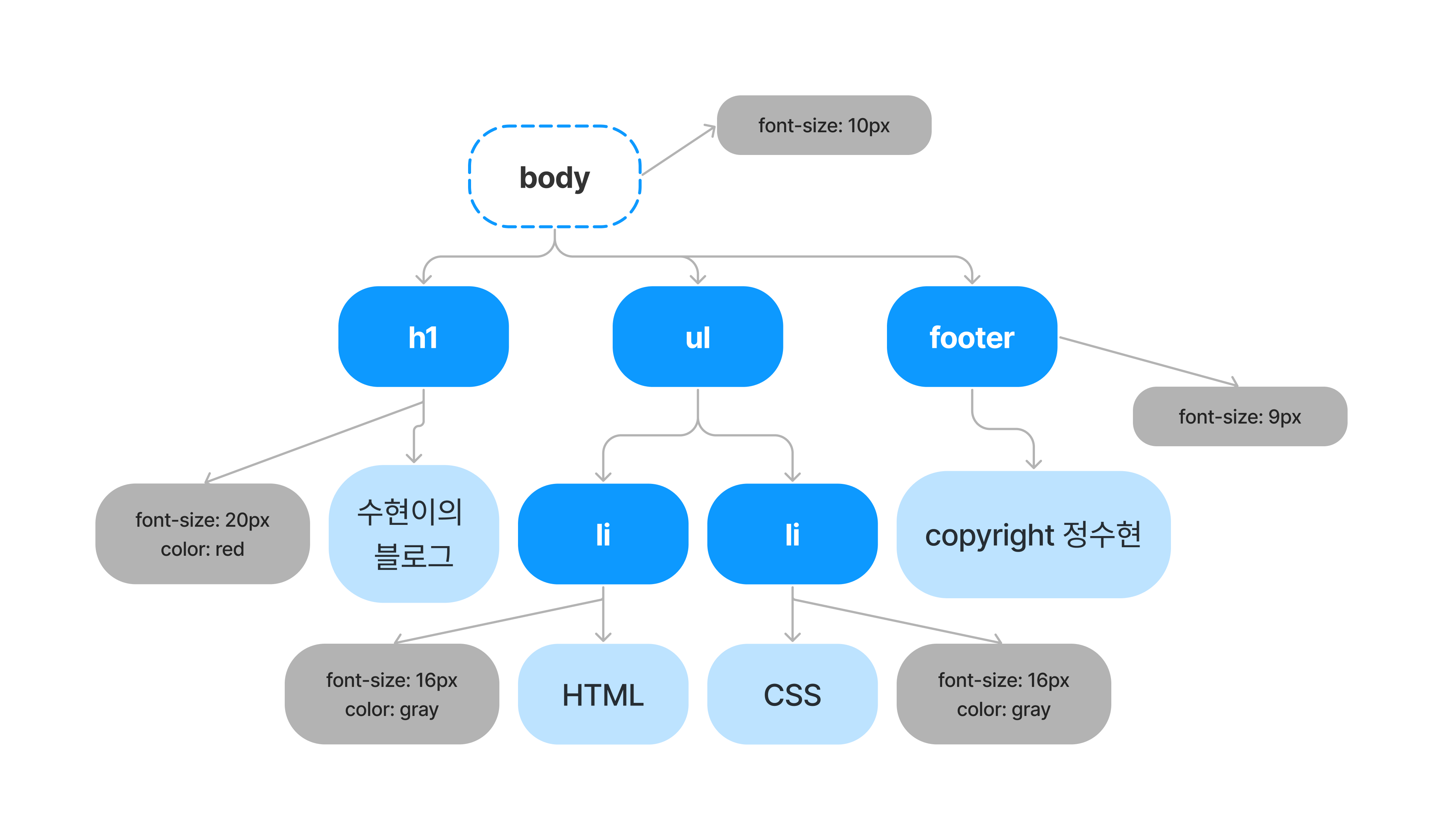
- 기본적으로 화면에 나타나는 요소들을 결정하는 트리
- DOM 트리 + CSSOM 트리
- CSS로 작성된 가상 요소 포함
- 화면에 그려지지 않는 요소들은 포함하지 않는다.
-<head>태그<script>태그display:none이 적용된 엘리먼트 등
레이아웃 또는 리플로우
- 렌더 트리에서 계산되지 않았던 노드들의 크기와 위치, 레이어 간 순서와 같은 정보를 계산하여 좌표에 나타냄
페인트
- 레이아웃 단계를 통해 화면에 배치된 엘리먼트들에게 색을 입히고 레이어의 위치를 결정하는 단계
- z-index가 낮은 순서대로 페인팅
- background-color
- background-image
- border
- children
- outline

렌더링 과정 헷갈렸는데 이 글 보고 이해됐어요! 시각자료가 넘 좋아요,,